최적의 모델을 검색하기 위해 신경망 아키텍처 검색 작업을 실행하기 전에 프록시 태스크를 정의합니다. Stage1-search는 훨씬 더 작은 완전한 모델 학습 표현을 사용합니다. 이러한 학습은 일반적으로 2시간 이내에 완료됩니다. 이 표현은 프록시 태스크라고 부르며 검색 비용을 크게 줄여줍니다. 검색 중 각 시도는 프록시-태스크 설정을 사용하여 모델을 학습시킵니다.
다음 섹션에서는 프록시 태스크 설계 적용에 관련된 사항을 설명합니다.
- 프록시 태스크 생성 방법
- 올바른 프록시 태스크의 요구사항
- 3가지 프록시 태스크 설계 도구를 사용하여 최적의 프록시 태스크를 찾아 검색 비용을 낮추고 검색 품질을 유지하는 방법
프록시 태스크 생성 방법
프록시 태스크를 만드는 일반적인 방법에는 다음 세 가지가 있습니다.
- 더 적은 수의 학습 단계 사용
- 서브 샘플링 학습 데이터 세트 사용
- 축소 조정된 모델 사용
더 적은 수의 학습 단계 사용
프록시 태스크를 만드는 가장 간단한 방법은 트레이너의 학습 단계 수를 줄이고 이 부분 학습을 기반으로 컨트롤러에 점수를 다시 보고하는 것입니다.
서브 샘플링된 학습 데이터 세트 사용
이 섹션에서는 아키텍처 검색 및 증강 정책 검색 모두에 서브 샘플링된 학습 데이터 세트를 사용하는 방법을 설명합니다.
아키텍처 검색
아키텍처 검색 중에 서브 샘플링 학습 데이터 세트를 사용하여 프록시 태스크를 만들 수 있습니다. 하지만 서브 샘플링 시에는 다음 가이드라인을 따르세요.
- 샤드 간에 데이터를 무작위로 셔플링합니다.
- 학습 데이터가 불균형하면 서브 샘플링을 통해 균형을 조정합니다.
자동 증강을 사용한 증강 정책 검색
증강 전용 검색을 실행하지 않고 일반적인 아키텍처 검색만 실행하는 경우 이 섹션을 건너뜁니다. auto-augment를 사용하여 증강 정책을 검색합니다. 학습 단계 수를 줄이는 것보다 학습 데이터를 서브 샘플링하고 전체 학습을 실행하는 것이 좋습니다. 과도한 증강으로 전체 학습을 실행하면 점수가 안정적으로 유지됩니다. 또한 감소된 학습 데이터를 사용하여 검색 비용을 낮게 유지합니다.
축소 모델을 기반으로 하는 프록시 태스크
기준 모델에 비해 모델을 축소하여 프록시 태스크를 만들 수도 있습니다. 이 방법은 scaling-search에서 block-design-search를 분리하려는 경우에도 유용할 수 있습니다.
하지만 모델을 축소하고 지연 시간 제약조건을 사용하려면 축소된 모델에 대해 더 엄격한 지연 시간 제약조건을 사용해야 합니다. 힌트: 기준 모델을 축소하고 지연 시간을 측정하여 이 엄격한 지연 시간 제약조건을 설정할 수 있습니다.
축소 모델의 경우 원래 기준 모델과 비교하여 증강 및 정규화의 양을 줄일 수도 있습니다.
축소된 모델의 예시
이미지를 학습시키는 컴퓨터 비전 태스크의 경우 다음 3가지 일반적인 방법을 통해 모델을 축소합니다.
- 모델 너비 줄이기: 채널 수
- 모델 깊이 줄이기: 레이어 및 블록 반복 수
- 학습 이미지 크기를 약간 줄이거나(특성을 제거하지 않도록) 태스크에서 허용되는 경우 학습 이미지 자르기
추천 읽기: EfficientNet 자료는 컴퓨터 비전 태스크를 위한 모델 확장에 대한 유용한 정보를 제공합니다. 또한 3가지 확장 방법이 서로 어떻게 관련되는지 설명합니다.
Spinenet 검색은 신경망 아키텍처 검색에 사용되는 모델 확장의 또 다른 예시입니다. stage-1 검색의 경우 채널 수 및 이미지 크기를 축소합니다.
조합 기반의 프록시 태스크
이러한 접근 방식은 독립적으로 작동하며 서로 다른 정도로 결합하여 프록시 태스크를 만들 수 있습니다.
올바른 프록시 태스크의 요구사항
프록시 태스크가 컨트롤러에 안정적인 리워드를 제공하고 검색 품질을 유지하기 위해서는 특정 요구사항을 충족해야 합니다.
stage-1 검색 및 stage2 full-training 간의 순위 상관관계
신경망 아키텍처 검색을 위해 프록시 태스크를 사용할 때 성공적인 검색을 위한 주요 전제는 stage-1 프록시 태스크 학습 중에 모델 A가 모델 B보다 더 잘 수행하면 모델 A가 stage-2 전체 학습에 대해 모델 B보다 더 잘 수행한다는 것입니다. 이 가정을 검증하려면 검색 공간에서 최대 10~20개 모델에 대한 stage-1 검색 및 stage-2 전체 학습 리워드 간의 순위 상관관계를 평가해야 합니다. 이러한 모델을 correlation-candidate-models라고 합니다.
아래 그림은 상관관계가 낮은 경우(관련성-점수 = -0.03)로, 이 프록시 태스크가 검색에 적합하지 않은 예시입니다.
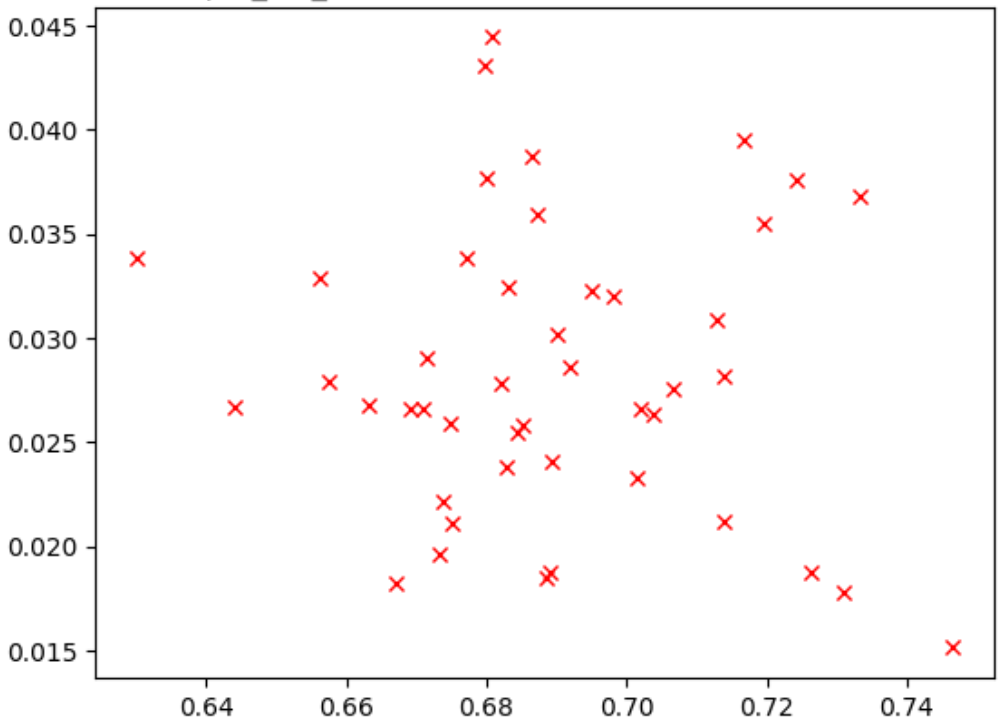
플롯의 각 지점은 correlation-candidate 모델을 나타냅니다.
x축은 모델의 stage-2 전체 학습 점수를 나타내고 y축은 동일한 모델의 stage-1 프록시 태스크 점수를 나타냅니다.
가장 높은 지점을 확인합니다. 이 모델은 프록시-태스크 점수(y축)가 가장 높았지만 stage-2 전체 학습(x축) 중에는 다른 모델에 비해 성능이 좋지 않습니다. 반면에 아래 그림은 이 프록시 태스크가 검색에 적합할 수 있는 적절한 상관관계(연관 점수 = 0.67)의 예시를 보여줍니다.
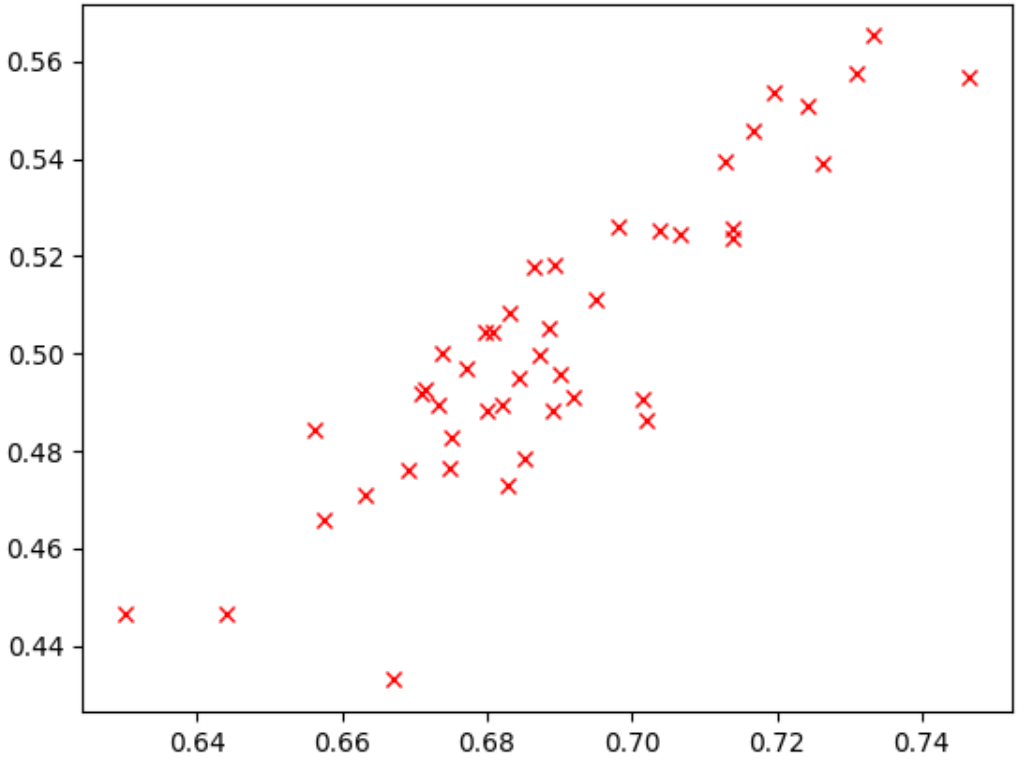
검색에 지연 시간 제약조건이 포함된 경우 지연 시간 값의 상관관계가 적절한지도 확인합니다.
correlation-candidate-models의 리워드에는 양호한 범위와 적절한 리워드 범위의 샘플링이 있어야 합니다. 그렇지 않으면 순위 상관관계를 평가할 수 없습니다. 예를 들어 모든 correlation-candidate models의 stage-1 리워드가 0.9 및 0.1의 두 가지 값에만 집중되면 샘플링 편차가 발생하지 않습니다.
편차 확인
프록시 태스크의 또 다른 요구사항은 동일한 모델에 대해 변경 없이 여러 번 반복될 경우 정확도 또는 지연 시간 점수가 크게 달라지지 않아야 한다는 것입니다. 이 경우 컨트롤러에 노이즈 신호가 다시 발생합니다. 이 편차를 측정하는 도구가 제공됩니다.
학습 중 큰 편차를 완화하기 위한 예시가 제공됩니다. 한 가지 방법은 cosine decay를 학습률 일정으로 사용하는 것입니다. 다음 플롯은 세 가지 학습률 전략을 비교합니다.
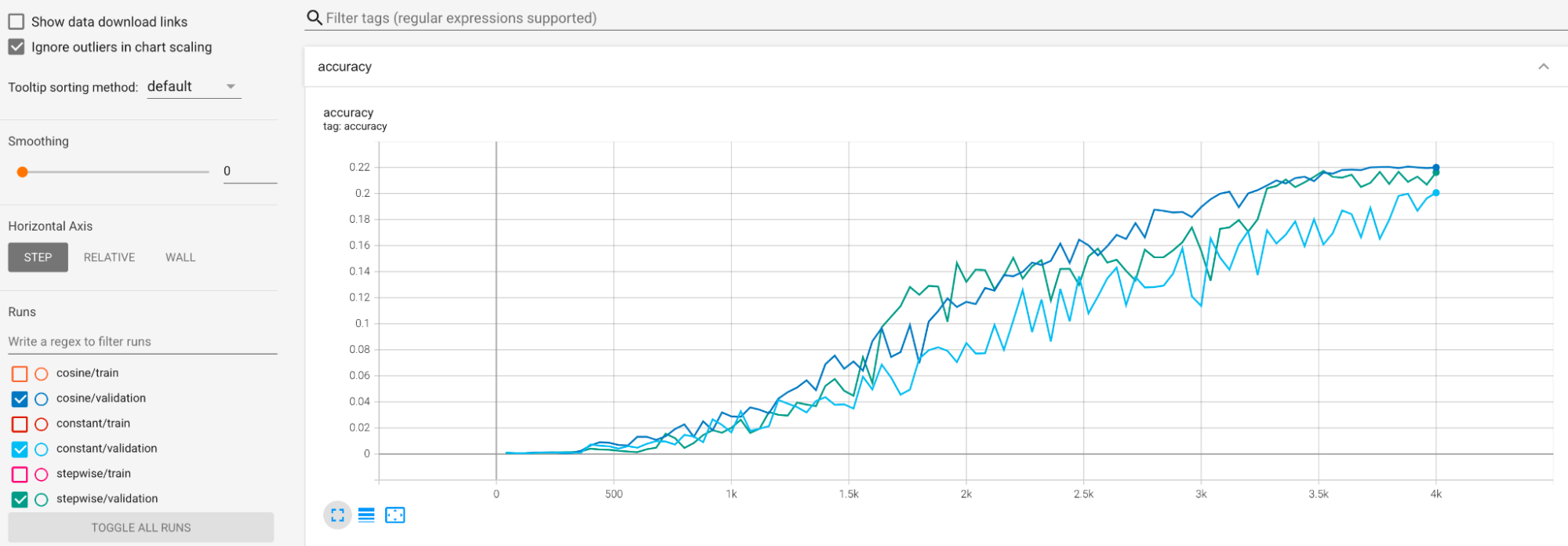
최저 플롯은 일정한 학습률에 해당합니다. 학습이 끝날 때 점수가 점프하는 경우 감소된 학습 단계 수에 따라 약간 변경되면 최종 프록시 태스크 리워드가 크게 변경될 수 있습니다. 프록시 태스크 리워드의 안정성을 높이려면 최상위 플롯에서 해당 검증 점수에 표시된 것처럼 코사인 학습률 감소를 사용하는 것이 좋습니다. 학습이 끝나가면서 맨 위의 플롯이 어떻게 매끄러워지는지 확인하십시오. 중간 플롯은 단계별 학습률 감소에 해당하는 점수를 보여줍니다. 일정한 속도보다 낫지만 코사인 감소만큼 매끄럽지 않으며 수동 조정이 필요합니다.
학습률 일정은 아래에 표시되어 있습니다.
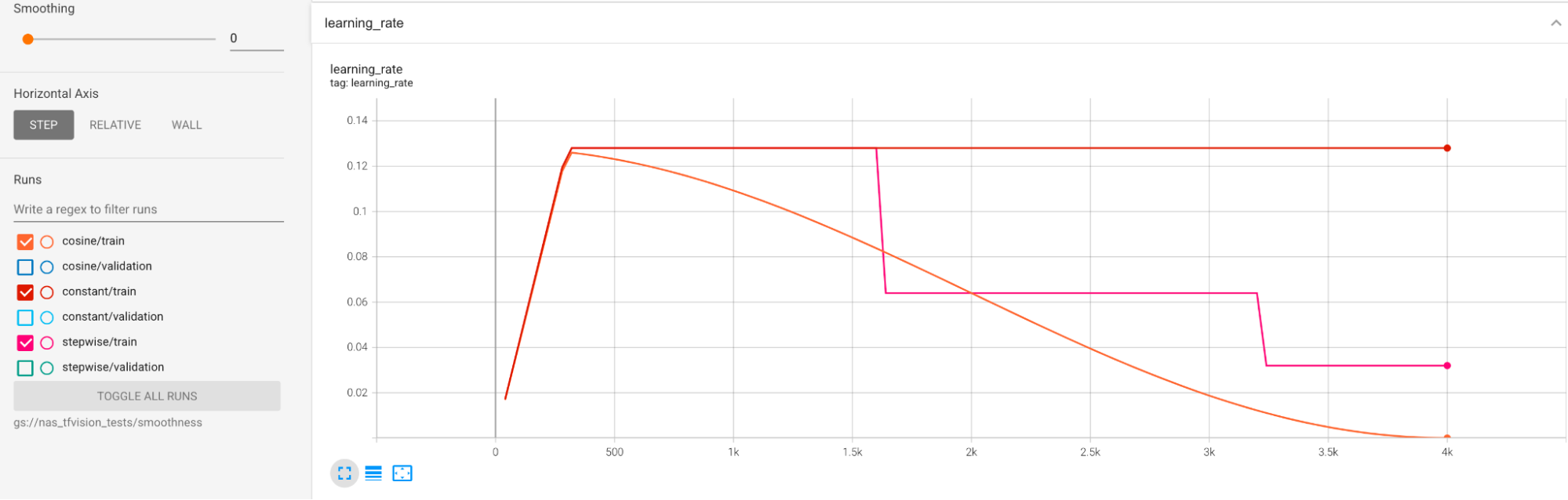
추가 평활화
과도한 증강을 사용하는 경우 코사인 감소로 검증 곡선이 매끄럽게 변하지 않을 수 있습니다. 과도한 증강을 사용하는 것은 학습 데이터가 부족함을 나타냅니다. 이 경우 신경망 아키텍처 검색은 사용하지 않는 것이 좋으며 대신 augmentation-search를 사용하는 것이 좋습니다.
과도한 증강이 원인이 아니고 이미 코사인 감소를 시도했지만 여전히 더 매끄럽게 수행하기를 원하는 경우, TensorFlow-2에 대해 exponential-moving-average를 사용하거나 PyTorch에 대해 stochastic-weighted-averaging을 사용합니다. TensorFlow 2와 함께 지수 이동 평균 최적화 프로그램을 사용하는 예시는 이 코드 포인터와 PyTorch에 대한 확률 가중치 평균화 예시를 참조하세요.
시도의 정확성/에포크 그래프가 다음과 같은 경우:
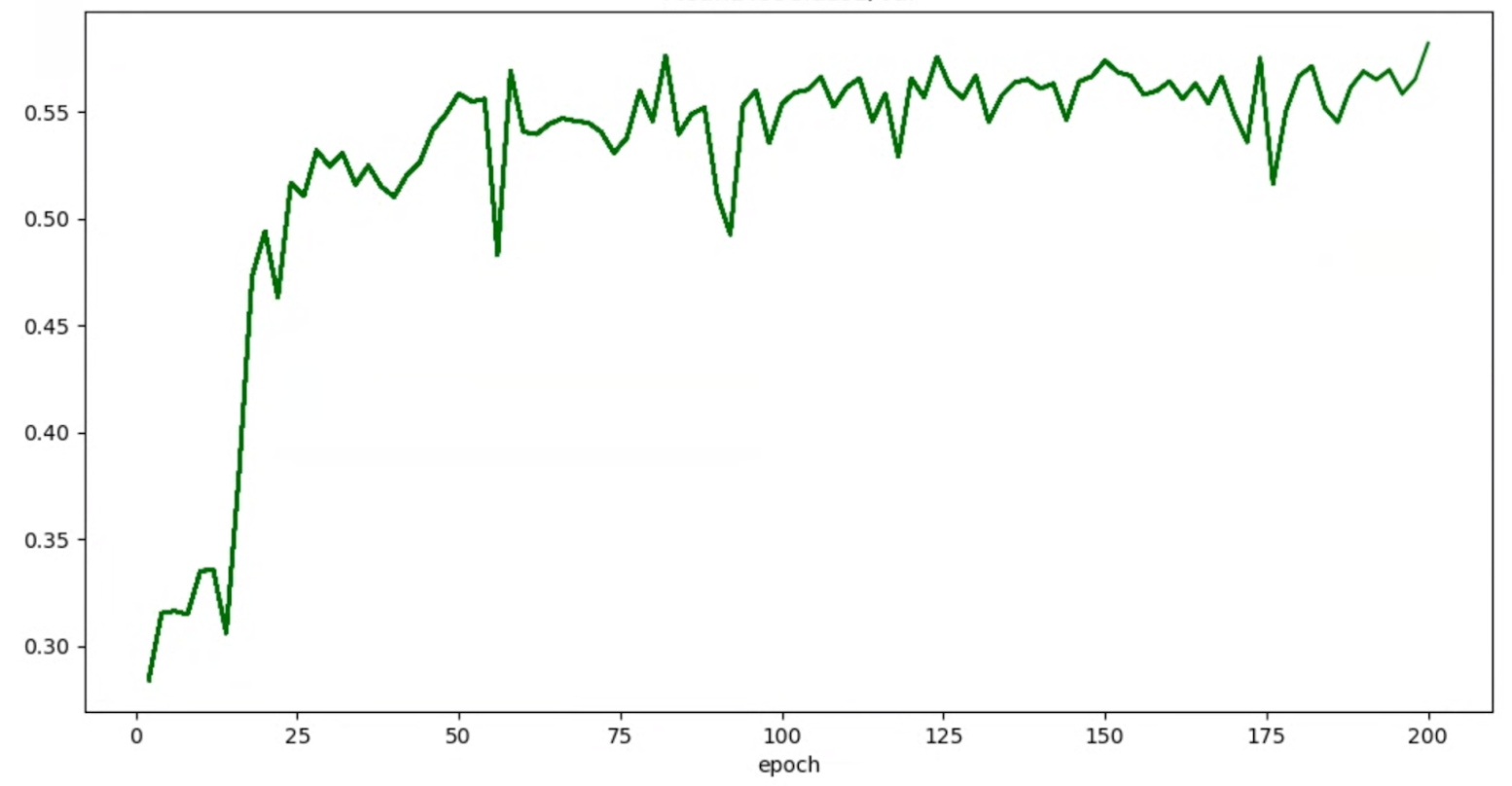
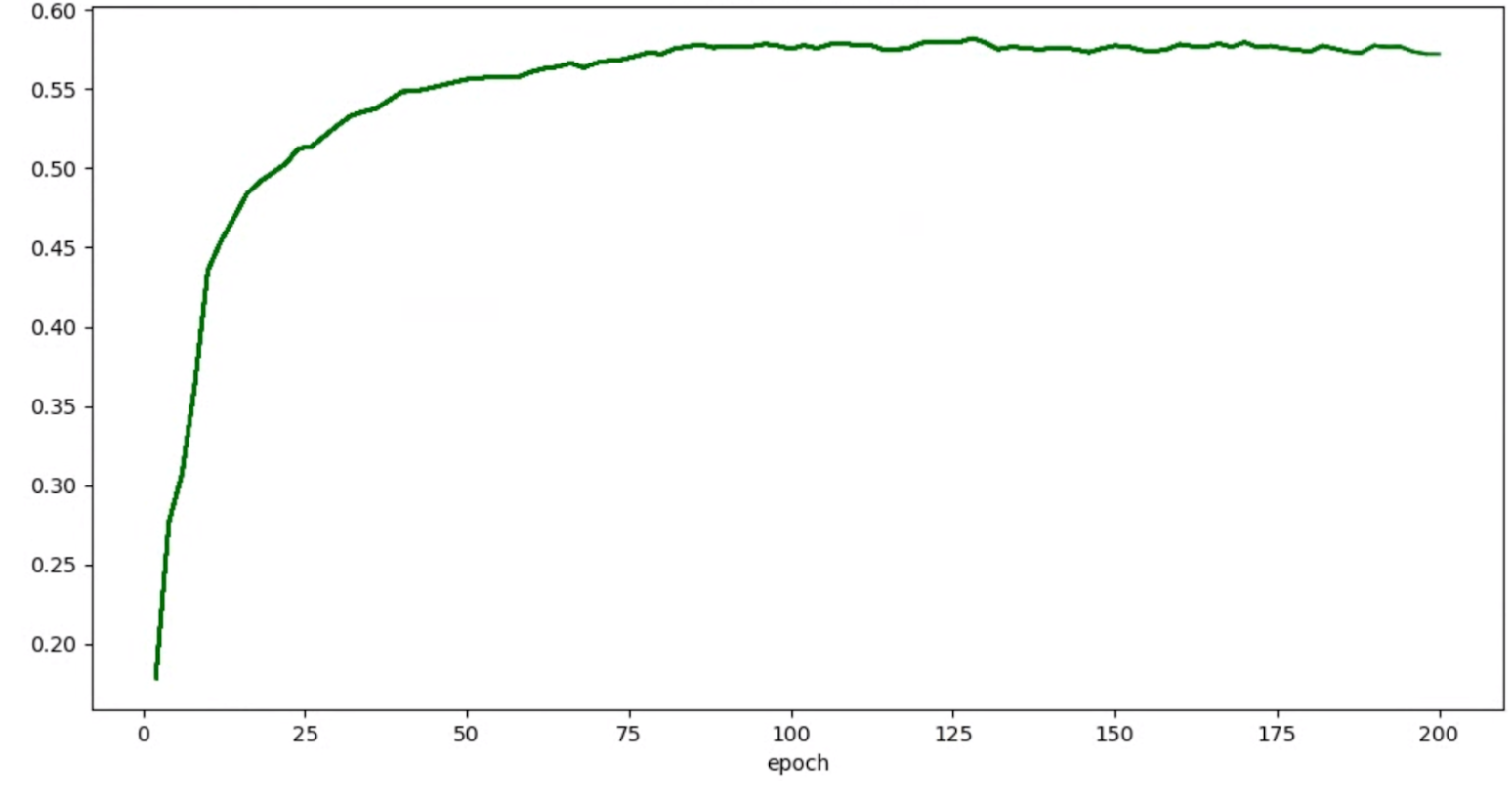
위에서 언급한 평활화 기법(예: 확률적 가중치 평균 또는 지수 이동 평균 사용)을 적용하여 다음과 같이 보다 일관성 있는 그래프를 얻을 수 있습니다.
메모리 부족(OOM) 및 학습률 관련 오류
아키텍처 검색 공간은 기준보다 훨씬 크게 모델을 생성할 수 있습니다. 기준 모델의 배치 크기를 조정했을 수 있지만 검색 중 더 큰 모델이 샘플링되어 OOM 오류가 발생할 때는 이 설정이 실패할 수 있습니다. 이 경우에는 배치 크기를 줄여야 합니다.
표시되는 다른 종류의 오류는 NaN(숫자가 아님) 오류입니다. 초기 학습률을 줄이거나 경사 제한을 추가해야 합니다.
tutorial-2에서 설명한 것처럼 검색 공간 모델이 20% 넘게 잘못된 점수를 반환하는 경우 전체 검색을 실행하지 않습니다. Google의 프록시 태스크 설계 도구는 실패율을 평가하는 방법을 제공합니다.
프록시 태스크 설계 도구
이전 섹션에서는 프록시 태스크 설계의 원칙을 설명했습니다. 이 섹션에서는 다양한 설계 방식 및 모든 요구사항을 충족하는 최적의 프록시 태스크를 자동으로 찾는 세 가지 프록시 태스크 설계 도구를 제공합니다.
필수 코드 변경
반복 프로세스 중 프록시 태스크 설계 도구와 상호작용할 수 있도록 먼저 트레이너 코드를 일부 수정해야 합니다.
tf_vision/train_lib.py는 예시를 보여줍니다. 먼저 라이브러리를 가져와야 합니다.
from google.cloud.visionsolutions.nas.proxy_task import proxy_task_utils
학습 루프에서 학습 주기가 시작되기 전에 프록시 태스크 설계 도구에서 Google 라이브러리를 사용하도록 하기 때문에 학습을 조기에 중지해야 하는지 확인합니다.
if proxy_task_utils.get_stop_training(
model_dir,
end_training_cycle_step=<last-training-step-idx done so far>,
total_training_steps=<total-training-steps>):
break
학습 루프의 각 학습 주기가 완료되면 새 정확성 점수, 학습 주기 시작 및 종료 단계, 학습 주기 시간(초), 총 학습 단계가 업데이트됩니다.
proxy_task_utils.update_trial_training_accuracy_metric(
model_dir=model_dir,
accuracy=<latest accuracy value>,
begin_training_cycle_step=<beginning training step for this cycle>,
end_training_cycle_step=<end training step for this cycle>,
training_cycle_time_in_secs=<training cycle time (excluding validation)>,
total_training_steps=<total-training-steps>)
학습 주기 시간에는 검증 점수 평가를 위한 시간이 포함되지 않습니다. 유효성 검사 곡선에 샘플링이 충분하도록 트레이너가 자주 평가 점수(평가 빈도)를 계산해야 합니다. 지연 시간 제약조건을 사용하는 경우 지연 시간을 계산한 후 지연시간 측정항목을 업데이트합니다.
proxy_task_utils.update_trial_training_latency_metric(
model_dir=model_dir,
latency=<measured_latency>)
모델 선택 도구는 반복 작업을 계속 수행하기 위해 이전 체크포인트를 로드해야 합니다.
이전 체크포인트를 재사용하도록 설정하려면 tf_vision/cloud_search_main.py에 표시된 대로 트레이너에 플래그를 추가합니다.
parser.add_argument(
"--retrain_use_search_job_checkpoint",
type=cloud_nas_utils.str_2_bool,
default=False,
help="True to use previous NAS search job checkpoint."
)
모델을 학습하기 전에 이 체크포인트를 로드합니다.
if FLAGS.retrain_use_search_job_checkpoint:
prev_checkpoint_dir = cloud_nas_utils.get_retrain_search_job_model_dir(
retrain_search_job_trials=FLAGS.retrain_search_job_trials,
retrain_search_job_dir=FLAGS.retrain_search_job_dir)
logging.info("Setting checkpoint to %s.", prev_checkpoint_dir)
# Now set your checkpoint using 'prev_checkpoint_dir'.
또한 트레이너가 보고한 정확성 및 지연 시간 값에 해당하는 metric-id가 필요합니다. 트레이너 리워드(정확성과 지연 시간의 조합인 경우도 있음)가 정확성과 다른 경우 트레이너에서 other_metrics를 사용하여 정확성 전용 측정항목도 보고해야 합니다.
예를 들어 다음 예시는 사전 빌드된 트레이너에서 보고되는 정확성 전용 및 지연 시간 측정항목을 보여줍니다.
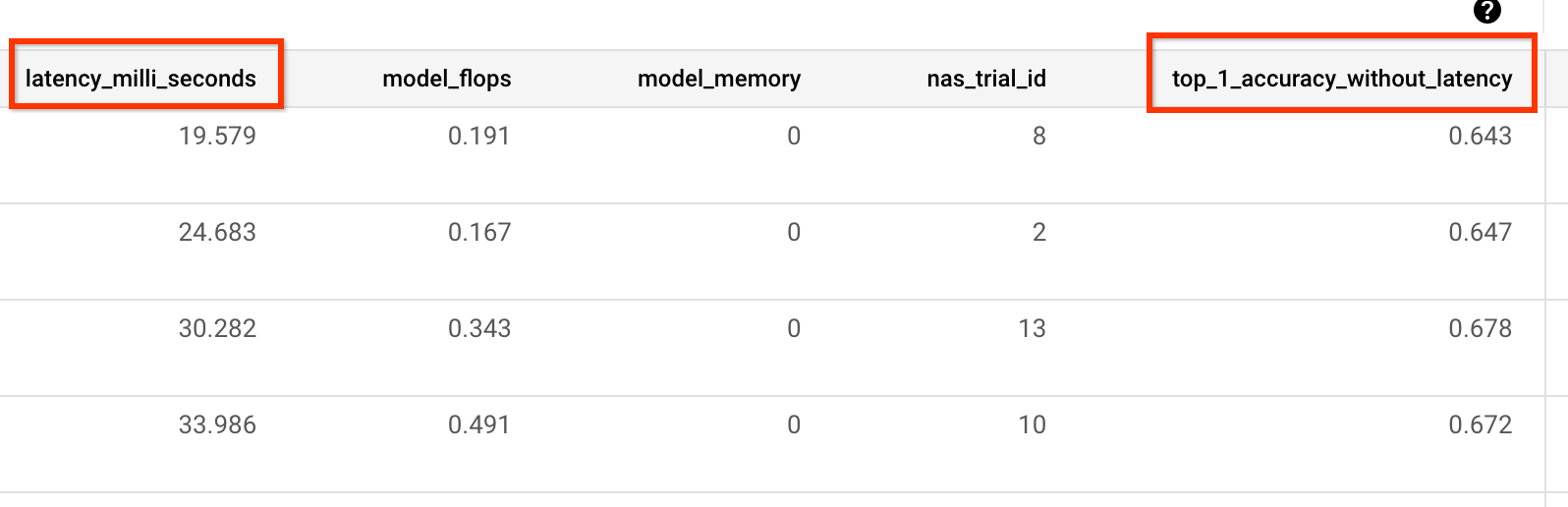
편차 측정
트레이너 코드를 수정한 후 첫 번째 단계는 트레이너의 편차를 측정하는 것입니다. 편차 측정의 경우 기준 학습 구성을 다음과 같이 수정합니다.
- GPU를 한두 개만 사용하여 학습 시간을 약 1시간 동안만 실행합니다. 전체 학습의 일부 샘플이 필요합니다.
- 코사인 감소 학습률을 사용하고 이러한 감소된 단계와 동일하게 단계를 설정하여 마지막에는 학습률이 거의 0이 되도록 합니다.
편차 측정 도구는 검색 공간에서 하나의 모델을 샘플링하고 OOM 또는 NAN 오류를 일으키지 않고도 이 모델이 학습을 시작할 수 있도록 하고, 약 1시간 동안 사용자의 설정으로 5개의 모델 사본을 실행합니다. 그런 다음 학습 점수 편차와 매끄러움을 보고합니다. 이 도구를 실행하는 총 비용은 약 1시간 동안 해당 설정으로 5개 모델을 실행하는 것과 대략적으로 동일합니다.
다음 명령어를 실행하여 편차 측정 작업을 시작합니다(서비스 계정 필요).
DATE="$(date '+%Y%m%d_%H%M%S')"
project_id=<your project-id>
# You can choose any unique docker id below.
trainer_docker_id=${USER}_trainer_${DATE}
trainer_docker_file=<path to your trainer dockerfile>
region=<your job region such as 'us-central1'>
search_space_module=<path to your search space module>
accelerator_type="NVIDIA_TESLA_V100"
num_gpus=2
# Your bucket should be for your project and in the same region as the job.
root_output_dir=<gs://your-bucket>
####### Variance measurement related parameters ######
proxy_task_variance_measurement_docker_id=${USER}_variance_measurement_${DATE}
# Use the service account that you set-up for your project.
service_account=<your service account>
job_name=<your job name>
############################################################
python3 vertex_nas_cli.py build \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--trainer_docker_file=${trainer_docker_file} \
--proxy_task_variance_measurement_docker_id=${proxy_task_variance_measurement_docker_id}
# The command below passes 'dummy' arguments for the training docker.
# You need to modify them for your own docker.
python3 vertex_nas_cli.py measure_proxy_task_variance \
--proxy_task_variance_measurement_docker_id=${proxy_task_variance_measurement_docker_id} \
--project_id=${project_id} \
--service_account=${service_account} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--job_name=${job_name} \
--search_space_module=${search_space_module} \
--accelerator_type=${accelerator_type} \
--num_gpus=${num_gpus} \
--root_output_dir=${root_output_dir} \
--search_docker_flags \
dummy_trainer_flag1="dummy_trainer_val"
이 편차 측정 작업을 실행하면 작업 링크가 제공됩니다. 작업 이름은 프리픽스 Variance_Measurement로 시작해야 합니다. 예시 작업 UI는 다음과 같습니다.
variance_measurement_dir에는 모든 출력이 포함되며, 로그 보기 링크를 클릭하여 로그를 확인할 수 있습니다.
이 작업은 기본적으로 클라우드에서 하나의 CPU를 사용하여 커스텀 작업으로 백그라운드에서 실행한 다음 하위 NAS 작업을 시작하고 관리합니다.
NAS 작업에 Find_workable_model_<your job name>이라는 작업이 표시됩니다. 이 작업은 검색 공간을 샘플링하여 오류를 생성하지 않는 하나의 모델을 찾습니다. 이러한 모델이 발견되면 분산 측정 작업이 다른 NAS 작업 <your job name>을 실행합니다. 이 작업은 이전에 설정한 학습 단계 수에 따라 이 모델의 복제본 5개를 실행합니다. 이러한 모델에 대한 학습이 완료되면 분산 측정 작업은 점수 분산 및 평활화를 측정하고 로그에 보고합니다.
편차가 크면 여기에 나열된 기법을 탐색할 수 있습니다.
모델 선택
트레이너에 편차가 크지 않음을 확인한 후 다음 단계는 다음과 같습니다.
- 최대 10개까지 correlation-candidate-models를 찾습니다.
- 나중에 다른 프록시 태스크 옵션에 대한 프록시-태스크 상관관계 점수를 계산할 때 참조로 작동할 전체 학습 점수를 계산합니다.
Google 도구는 자동 및 효율적으로 이러한 correlation-candidate 모델을 찾고 정확성과 지연 시간 측면에서 양호한 점수 분포를 확보하여 향후 상관관계 계산이 좋은 기반을 갖도록 합니다. 이를 위해 이 도구는 다음을 수행합니다.
- 검색 공간에서
N_begin모델을 무작위로 샘플링합니다. 이 예시에서는N_begin = 30을 가정합니다. 이 도구는 전체 학습의 30분의 1에 해당하는 시간을 학습합니다. - 정확성과 지연 시간의 분포에 영향을 주지 않는 30개의 모델 중 5개를 제외합니다. 다음 그림은 이를 예시로 보여줍니다. 제외된 모델은 빨간색 점으로 표시됩니다.
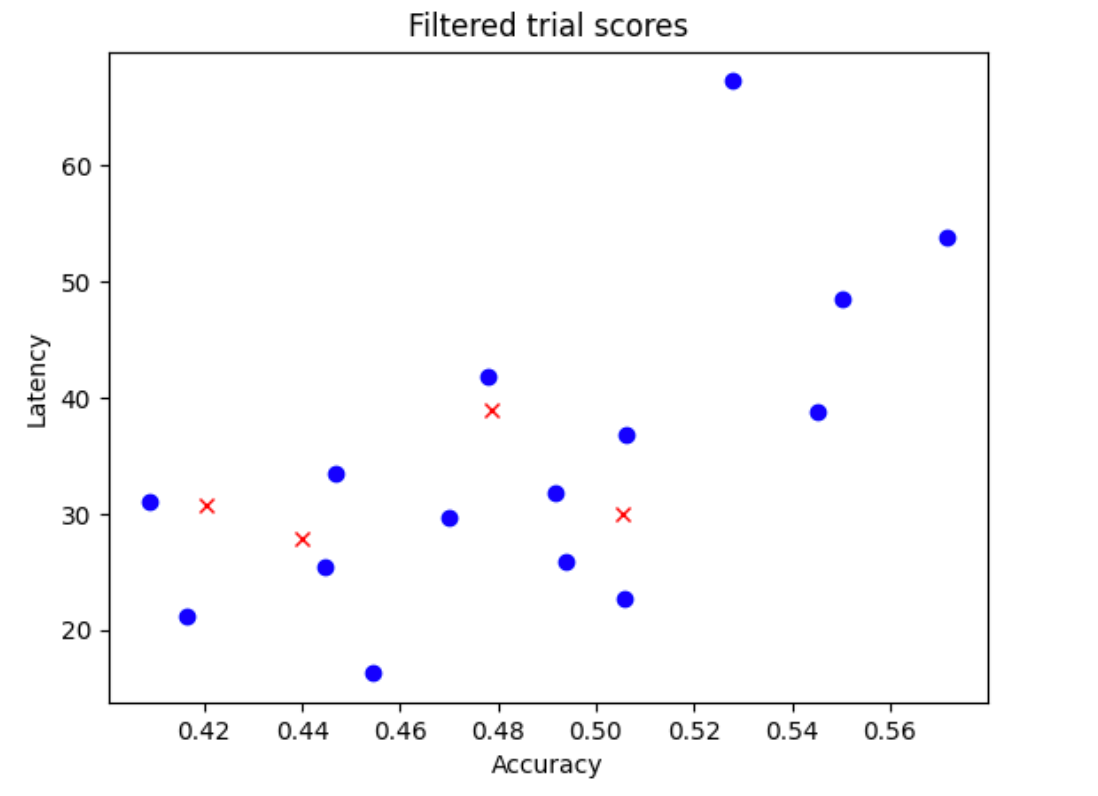
- 선택한 모델 25개를 전체 학습 시간의 1/25 동안 학습시킨 후 지금까지 점수를 기준으로 모델 5개를 더 제외합니다. 25개의 모델 학습이 이전 체크포인트에서 계속됩니다.
- 균형적인 분포의
N개 모델만 남을 때까지 이 프로세스를 반복합니다. - 완료될 때까지 이 마지막
N모델을 학습시킵니다.
N_begin의 기본 설정은 30이며 proxy_task/proxy_task_model_selection_lib_constants.py 파일에서 START_NUM_MODELS로 찾을 수 있습니다.
N의 기본 설정은 10이며 proxy_task/proxy_task_model_selection_lib_constants.py 파일에서 FINAL_NUM_MODELS로 찾을 수 있습니다.
이 모델 선택 프로세스의 추가 비용은 다음과 같이 계산됩니다.
= (30*1/30 + 25*1/25 + 20*1/20 + 15*1/15 + 10*(remaining-training-time-fraction)) * full-training-time
= (4 + 10*(0.81)) * full-training-time
~= 12 * full-training-time
하지만 N=10 설정 이상으로 유지하세요. 프록시 태스크 검색 도구는 나중에 이러한 N 모델을 병렬로 실행합니다. 따라서 이를 위해 GPU 할당량이 충분한지 확인해야 합니다. 예를 들어 프록시 태스크에서 하나의 모델에 2개의 GPU가 사용될 경우에는 GPU 할당량이 적어도 2*N개 이상이어야 합니다.
모델 선택 작업의 경우 stage-2 전체 학습 작업과 동일한 데이터 세트 파티션을 사용하고 기준 전체 학습에 동일한 트레이너 구성을 사용합니다.
이제 다음 명령어를 실행하여 모델 선택 작업을 실행할 수 있습니다(서비스 계정 필요).
DATE="$(date '+%Y%m%d_%H%M%S')"
project_id=<your project-id>
# You can choose any unique docker id below.
trainer_docker_id=${USER}_trainer_${DATE}
trainer_docker_file=<path to your trainer dockerfile>
latency_calculator_docker_id=${USER}_model_selection_${DATE}
latency_calculator_docker_file=${USER}_latency_${DATE}
region=<your job region such as 'us-central1'>
search_space_module=<path to your search space module>
accelerator_type="NVIDIA_TESLA_V100"
num_gpus=2
# Your bucket should be for your project and in the same region as the job.
root_output_dir=<gs://your-bucket>
# Your latency computation device.
target_device_type="CPU"
####### Proxy task model-selection related parameters ######
proxy_task_model_selection_docker_id=${USER}_model_selection_${DATE}
# Use the service account that you set-up for your project.
service_account=<your service account>
job_name=<your job name>
# The value below depends on your accelerator quota. By default
# the model-selection job runs 30 trials. However, depending on
# your quota, you can choose to only run 10 trials in parallel at a time.
# However, lowering this number can increase the overall runtime for the job.
max_parallel_nas_trial=<num parallel trials>
# The value below is the 'metric-id' corresponding to the accuracy ONLY
# metric reported by your trainer. Note that this metric may
# be different from the 'reward'.
accuracy_metric_id=<set accuracy metric id used by your trainer>
latency_metric_id=<set latency metric id used by your trainer>
############################################################
python3 vertex_nas_cli.py build \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--trainer_docker_file=${trainer_docker_file} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_calculator_docker_file=${latency_calculator_docker_file} \
--proxy_task_model_selection_docker_id=${proxy_task_model_selection_docker_id}
# The command below passes 'dummy' arguments for trainer-docker
# and latency-docker. You need to modify them for your own docker.
python3 vertex_nas_cli.py select_proxy_task_models \
--service_account=${service_account} \
--proxy_task_model_selection_docker_id=${proxy_task_model_selection_docker_id} \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--job_name=${job_name} \
--max_parallel_nas_trial=${max_parallel_nas_trial} \
--accuracy_metric_id=${accuracy_metric_id} \
--latency_metric_id=${latency_metric_id} \
--search_space_module=${search_space_module} \
--accelerator_type=${accelerator_type} \
--num_gpus=${num_gpus} \
--root_output_dir=${root_output_dir} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_docker_flags \
dummy_latency_flag1="dummy_latency_val" \
--target_device_type=${target_device_type} \
--search_docker_flags \
dummy_trainer_flag1="dummy_trainer_val"
이 모델 선택 컨트롤러 작업을 시작하면 작업 링크가 수신됩니다. 작업 이름은 프리픽스 Model_Selection_으로 시작합니다. 예시 작업 UI는 다음과 같습니다.
model_selection_dir에는 모든 출력이 포함됩니다. View logs 링크를 클릭하여 로그를 확인합니다.
이 모델 선택 컨트롤러 작업은 기본적으로 Google Cloud 에서 하나의 CPU를 사용하여 백그라운드에서 커스텀 작업으로 실행되며, 이후 모델 선택을 반복할 때마다 하위 NAS 작업을 시작하고 관리합니다.
각 하위 NAS 작업의 이름은 <your_job_name>_iter_3과 같습니다(반복 0 제외). 한 번에 반복 1회만 실행됩니다. 반복할 때마다 모델 수(시도 횟수)가 줄어들고 학습 기간이 증가합니다. 반복 작업이 끝날 때마다 각 NAS 작업은 이 반복에서 제외된 모델을 시각적으로 보여주는 gs://<job-output-dir>/search/filtered_trial_scores.png 파일을 저장합니다.
다음 명령어를 실행할 수도 있습니다.
gcloud storage cat gs://<path to 'model_selection_dir'>/MODEL_SELECTION_STATE.json
모델 선택 컨트롤러 작업의 반복 및 현재 상태, 작업 이름, 각 반복의 링크를 요약해서 보여줍니다.
{
"start_num_models": 30,
"final_num_models": 10,
"num_models_to_remove_per_iter": 5,
"accuracy_metric_id": "top_1_accuracy_without_latency",
"latency_metric_id": "latency_milli_seconds",
"iterations": [
{
"num_trials": 30,
"trials_to_retrain": [
"27",
"16",
...,
"14"
],
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/2111217356469436416",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/2111217356469436416/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/6909239809479278592",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/6909239809479278592/cpu?project=my-project",
"desired_training_step_pct": 2.0
},
...,
{
"num_trials": 15,
"trials_to_retrain": [
"14",
...,
"5"
],
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/7045544066951413760",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/7045544066951413760/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/2790768318993137664",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/2790768318993137664/cpu?project=my-project",
"desired_training_step_pct": 28.57936507936508
},
{
"num_trials": 10,
"trials_to_retrain": [],
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/2742864796394192896",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/2742864796394192896/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/1490864099985195008",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/1490864099985195008/cpu?project=my-project",
"desired_training_step_pct": 101.0
}
]
}
마지막 반복에는 점수 분포가 양호한 참조 모델의 최종 개수가 있습니다. 이러한 모델과 해당 점수는 다음 단계에서 프록시 태스크 검색을 위해 사용됩니다. 참조 모델에 대한 최종 정확도 및 지연 시간 점수 범위가 기존 기준 모델에 더 잘 보이거나 가까우면 검색 공간을 파악하는 데 도움이 됩니다. 최종 정확도 및 지연 시간의 점수 범위가 기준보다 훨씬 나쁘면 검색 공간을 다시 조정해야 합니다.
첫 번째 반복에서 시도의 20%를 초과하여 실패하면 모델 선택 작업을 취소하고 실패의 근본 원인을 식별합니다. 검색 공간 또는 배치 크기와 학습률 설정에 문제가 있을 수 있습니다.
모델 선택에 온프레미스 지연 시간 기기 사용
모델 선택에 온프레미스 지연 시간 기기를 사용하려면 Google Cloud에서 지연 시간 docker를 실행하지 않으려는 것이므로 지연 시간 Docker 및 지연 시간 Docker 플래그 없이 select_proxy_task_models 명령어를 실행합니다. 다음으로 튜토리얼 4에 설명된 run_latency_calculator_local 명령어를 사용하여 온프레미스 지연 시간 계산기 작업을 실행합니다. --search_job_id 플래그를 전달하는 대신 select_proxy_task_models 명령어를 실행한 후 가져온 숫자 model-selection job-id로 --controller_job_id 플래그를 전달합니다.
모델 선택 컨트롤러 작업 재개
다음 상황에서는 모델 선택 컨트롤러 작업을 재개해야 합니다.
- 상위 모델 선택 컨트롤러 작업이 종료되는 경우(드문 경우)
- 모델 선택 컨트롤러 작업을 실수로 취소한 경우
먼저 하위 NAS 반복 작업(NAS 탭)이 실행 중이면 이를 취소하지 않습니다. 그런 다음 상위 모델 선택 컨트롤러 작업을 재개하려면 이전과 같이 select_proxy_task_models 명령어를 실행하지만, 이번에는 --previous_model_selection_dir 플래그를 전달하고 이전 모델 선택 컨트롤러 작업의 출력 디렉터리로 설정합니다. 재개된 모델 선택 컨트롤러 작업이 디렉터리에서 이전 상태를 로드하고 이전처럼 계속 작동합니다.
프록시 태스크 검색
correlation-candidate 모델 및 전체 학습 점수를 찾은 후 다음 단계는 이 모델을 사용하여 다양한 프록시 태스크 선택에 대한 상관 점수를 평가하고 최적의 프록시 태스크를 설정하는 것입니다. 프록시 태스크 검색 도구는 다음을 제공하는 프록시 태스크를 자동으로 찾을 수 있습니다.
- 최저 NAS 검색 비용
- 프록시 태스크 검색 공간 정의를 제공한 후 최소 상관관계 요구사항 기준점을 충족합니다.
최적의 프록시 태스크를 찾기 위한 세 가지 일반적인 측정기준은 다음과 같습니다.
- 감소한 학습 단계 수
- 감소한 학습 데이터 양
- 감소한 모델 규모
다음과 같이 이러한 측정기준을 샘플링하여 이산적인 프록시 태스크 검색 공간을 만들 수 있습니다.
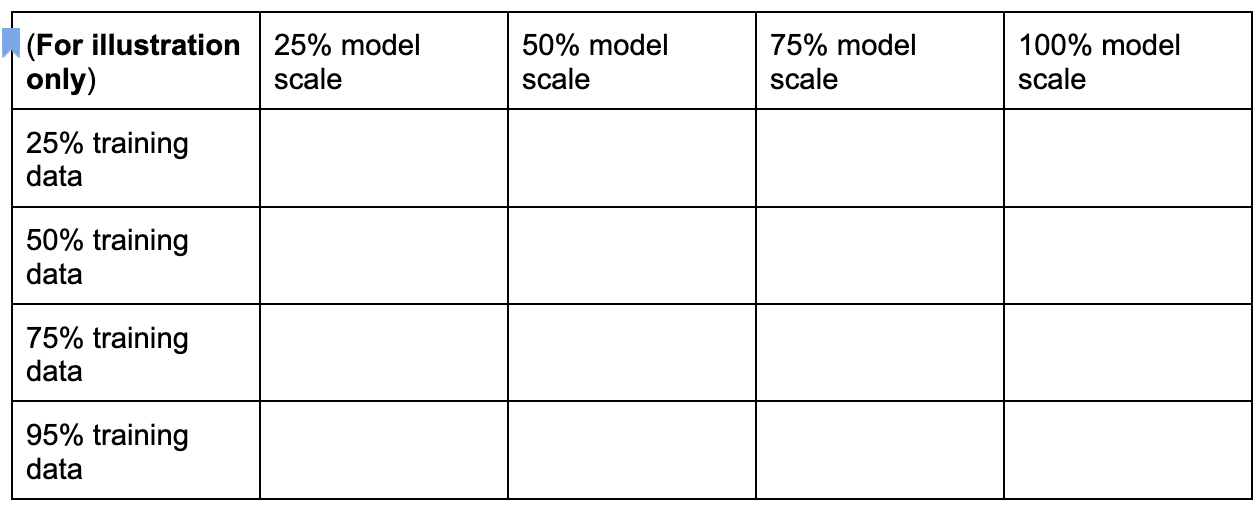
위의 백분율 수치는 대략적인 제안 및 예시로만 설정됩니다. 실제로는 원하는 대로 선택할 수 있습니다.
위 검색 공간에 학습 단계 측정기준은 포함되지 않았습니다. 이는 프록시 태스크 검색 도구가 프록시 태스크 선택에 따라 최적의 학습 단계를 파악하기 때문입니다.
[50% training data, 25% model scale]의 프록시 태스크 옵션을 고려하세요. 학습 단계 수를 전체 기준 학습과 동일한 크기로 설정하세요.
이 프록시 태스크를 평가할 때 프록시 태스크 검색 도구는 correlation-candidate 모델에 대한 학습을 시작하고, 현재 정확도 점수를 모니터링하고, 순위 상관관계 점수를 지속적으로 계산합니다(참조 모델에 대한 과거 전체 학습 점수 사용).
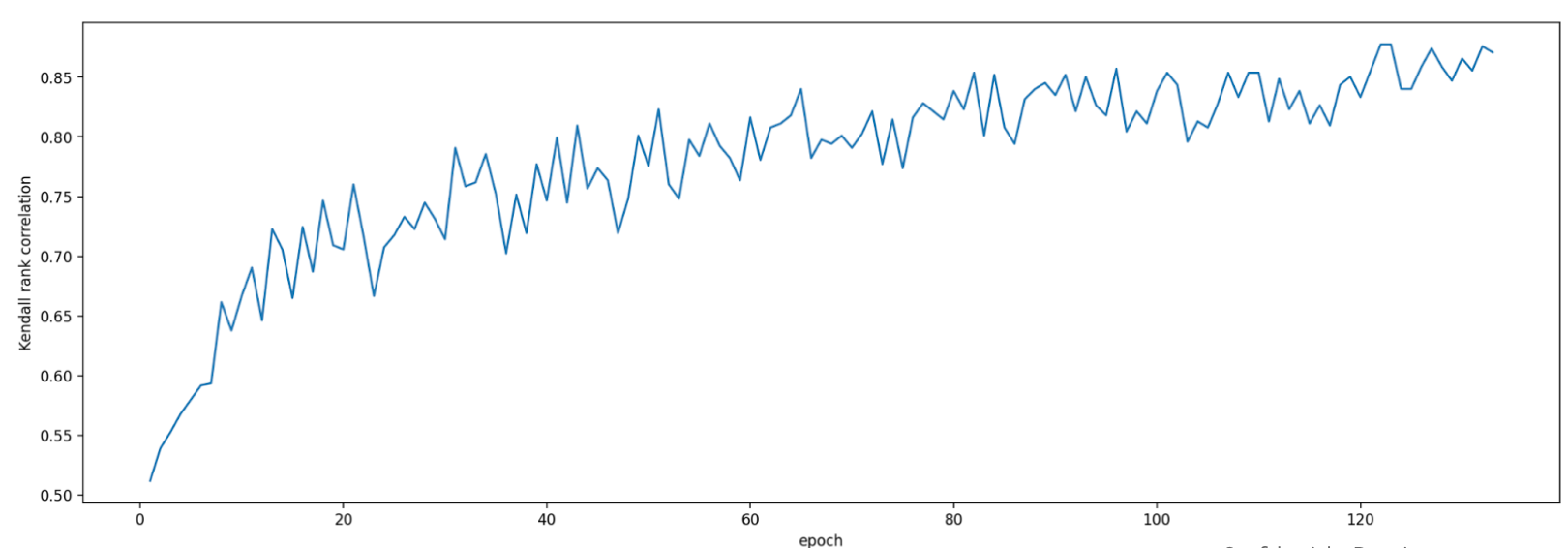
따라서 프록시 태스크 검색 도구는 원하는 상관관계(예: 0.65)가 확보되면 프록시 태스크 학습을 중지하거나 검색 비용 할당량(예: 프록시 태스크당 3시간)을 초과하는 경우에도 조기에 중지할 수 있습니다. 따라서 학습 단계를 명시적으로 검색할 필요가 없습니다. 프록시 태스크 검색 도구는 개별 검색 공간의 각 프록시 태스크를 그리드 검색으로 평가하여 최적의 옵션을 제공합니다.
다음은 proxy_task/proxy_task_search_spaces.py 파일에 정의된 MnasNet 프록시 태스크 검색 공간 정의의 예시 mnasnet_proxy_task_config_generator로, 자체 검색 공간을 정의하는 방법을 보여줍니다.
# MNasnet training-data size choices.
MNASNET_TRAINING_DATA_PCT_LIST = [25, 50, 75, 95]
# Training data path regex pattern.
_TRAINING_DATA_PATH_REGEX = r"gs://.*/.*"
def update_mnasnet_proxy_training_data(
baseline_docker_args_map: Dict[str, Any],
training_data_pct: int) -> Optional[Dict[str, Any]]:
"""Updates MNasnet baseline docker to use a certain training_data_pct."""
proxy_task_docker_args_map = copy.deepcopy(baseline_docker_args_map)
# Imagenet training data path looks like:
# gs://<path to imagenet data>/train-00[0-7]??-of-01024.
if not re.match(_TRAINING_DATA_PATH_REGEX,
baseline_docker_args_map["training_data_path"]):
raise ValueError(
"Training data path %s does not match the desired pattern." %
baseline_docker_args_map["training_data_path"])
root_path, _ = baseline_docker_args_map["training_data_path"].rsplit("/", 1)
if training_data_% == 25:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-1][0-4]?-of-01024*")
elif training_data_% == 50:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-4]??-of-01024*")
elif training_data_% == 75:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-6][0-4]?-of-01024*")
elif training_data_% == 95:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-8][0-4]?-of-01024*")
else:
logging.warning("Mnasnet training_data_% %d is not supported.",
training_data_pct)
return None
proxy_task_docker_args_map["validation_data_path"] = os.path.join(
root_path, "train-009[0-4]?-of-01024")
return proxy_task_docker_args_map
def mnasnet_proxy_task_config_generator(
baseline_docker_args_map: Dict[str, Any]
) -> List[proxy_task_utils.ProxyTaskConfig]:
"""Returns a list of proxy-task configs to be evaluated for MNasnet.
Args:
baseline_docker_args_map: A set of baseline training-docker arguments in
the form of a dictionary of {'key', val}. The different proxy-task
configs to try can be built by modifying this baseline.
Returns:
A list of proxy-task configs to be evaluated for this
proxy-task search space.
"""
proxy_task_config_list = []
# NOTE: Will not search over model-scale for MNasnet.
for training_data_% in MNASNET_TRAINING_DATA_PCT_LIST:
proxy_task_docker_args_map = update_mnasnet_proxy_training_data(
baseline_docker_args_map=baseline_docker_args_map,
training_data_pct=training_data_pct)
if not proxy_task_docker_args_map:
continue
proxy_task_name = "mnasnet_proxy_training_data_pct_{}".format(
training_data_pct)
proxy_task_config_list.append(
proxy_task_utils.ProxyTaskConfig(
name=proxy_task_name, docker_args_map=proxy_task_docker_args_map))
return proxy_task_config_list
이 예시에서는 training-data-percent 25, 50, 75, 95에 대한 간단한 검색 공간을 만듭니다(학습 데이터 100%는 stage1-search에서 사용되지 않음).
mnasnet_proxy_task_config_generator 함수는 학습 docker 인수의 일반 기준 템플릿을 가져와서 원하는 프록시 태스크 학습 데이터 크기에 따라 이러한 인수를 수정합니다. 그런 다음 프록시 태스크 검색 도구가 나중에 동일한 순서로 하나씩 처리하는 proxy-task-config 목록을 반환합니다. 각 프록시 태스크 구성에는 proxy-task docker 인수의 키-값 맵인 name 및 docker_args_map이 포함됩니다.
자체 요구사항에 따라 자체 검색 공간 정의를 구현할 수 있으며, 학습 데이터 축소 또는 모델 규모 축소의 두 개 이상의 측정기준에 대해서도 자체 프록시 태스크 검색 공간을 설계할 수 있습니다. 하지만 쓸모없는 반복적인 계산이 될 수 있으므로 학습 단계를 명시적으로 검색하는 것은 바람직하지 않습니다. 프록시 태스크 검색 도구가 이 측정기준을 자동으로 처리하도록 합니다.
첫 번째 프록시 태스크 검색의 경우 MnasNet 예시와 같이 학습 데이터만 줄이고 모델 확장 시 image-size, num-filters, num-blocks에 관한 여러 매개변수가 연관될 수 있기 때문에 축소된 모델 규모를 건너뛸 수 있습니다.
대부분의 경우 감소된 학습 데이터(및 축소된 학습 단계에 대한 암시적 검색)로도 충분한 프록시 태스크를 찾을 수 있습니다.
학습 단계 수를 전체 기준 학습에 사용된 숫자로 설정합니다.
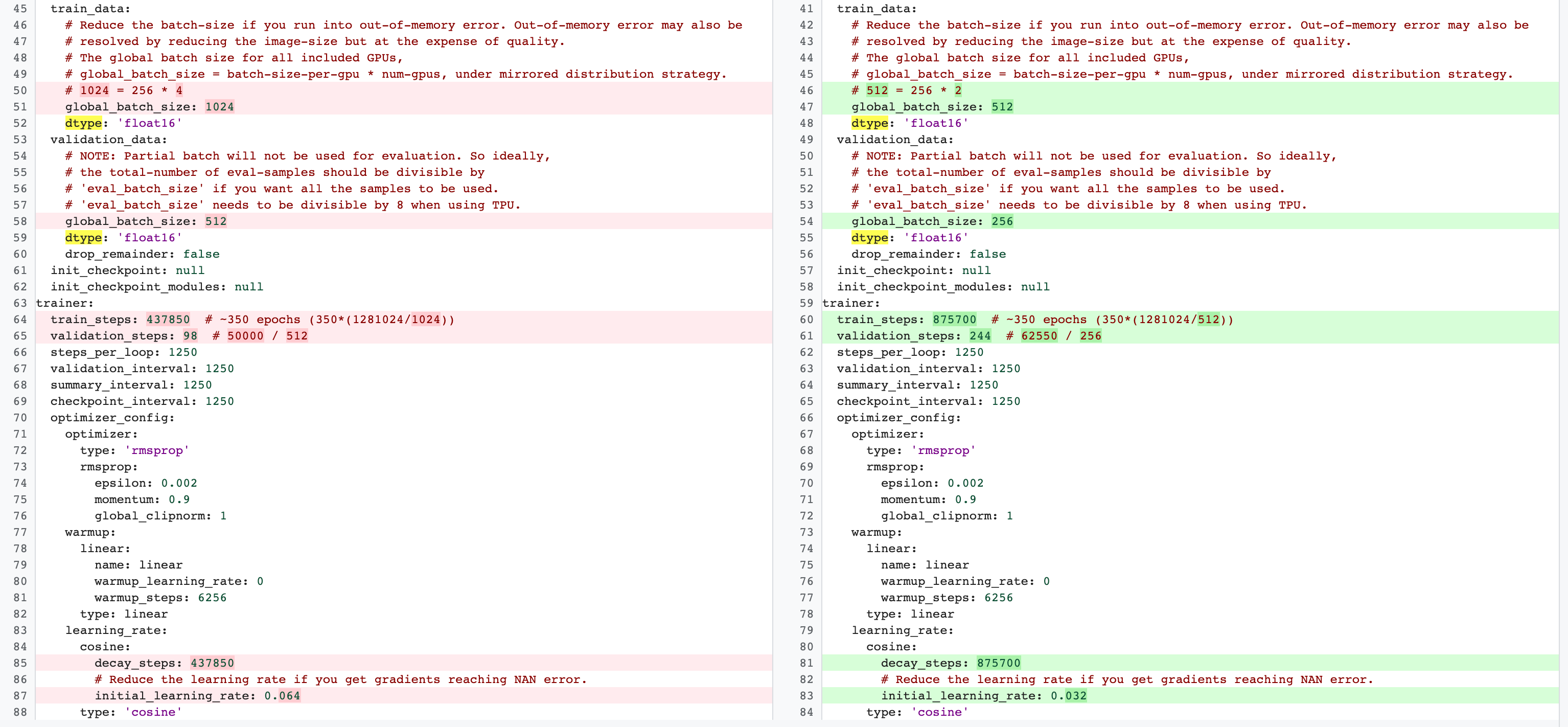
stage-2 전체 학습과 stage-1 프록시 태스크 구성 사이에는 차이가 있습니다. 프록시 태스크의 경우 전체 기준 학습 구성에 비해 GPU를 2개 또는 4개만 사용하도록 batch-size를 줄여야 합니다.
일반적으로 전체 학습은 GPU 4개, GPU 8개 이상을 사용하지만 프록시 태스크는 GPU 2개 또는 GPU4개만 사용합니다.
또 다른 차이는 학습 및 검증 분할입니다.
다음은 MnasNet 구성이 2단계 전체 학습을 위해 4개의 GPU에서 2개의 GPU로 변경되고 프록시 태스크 검색을 위해 다른 유효성 검사 분할로 변경된 예시입니다.
다음 명령어를 실행하여 프록시 태스크 검색 컨트롤러 작업을 실행합니다(서비스 계정 필요).
DATE="$(date '+%Y%m%d_%H%M%S')"
project_id=<your project-id>
# You can choose any unique docker id below.
trainer_docker_id=${USER}_trainer_${DATE}
trainer_docker_file=<path to your trainer dockerfile>
latency_calculator_docker_id=${USER}_model_selection_${DATE}
latency_calculator_docker_file=${USER}_latency_${DATE}
region=<your job region such as 'us-central1'>
search_space_module=<path to your NAS job search space module>
accelerator_type="NVIDIA_TESLA_V100"
num_gpus=2
# Your bucket should be for your project and in the same region as the job.
root_output_dir=<gs://your-bucket>
# Your latency computation device.
target_device_type="CPU"
####### Proxy task search related parameters ######
proxy_task_search_controller_docker_id=${USER}_proxy_task_search_${DATE}
job_name=<your job name>
# Path to your proxy task search space definition. For ex:
# 'proxy_task.proxy_task_search_spaces.mnasnet_proxy_task_config_generator'
proxy_task_config_generator_module=<path to your proxy task config generator module>
# The previous model-slection job provides the candidate-correlation-models
# and their scores.
proxy_task_model_selection_job_id=<Numeric job id of your previous model-selection>
# During proxy-task search, the proxy-task training is stopped
# when the following correlation score is achieved.
desired_accuracy_correlation=0.65
# During proxy-task search, the proxy-task training is stopped
# if the runtime exceeds this limit: 4 hrs.
training_time_hrs_limit=4
# The proxy-task is marked a good candidate only if the latency
# correlation is also above the required threshold.
# Note: This won't be used if you do not have a latency job.
desired_latency_correlation=0.65
# Early stop a proxy-task evaluation if you already have a better candidate.
# If False, evaluate all proxy-taask candidates.
early_stop_proxy_task_if_not_best=False
# Use the service account that you set-up for your project.
service_account=<your service account>
###################################################
python3 vertex_nas_cli.py build \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--trainer_docker_file=${trainer_docker_file} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_calculator_docker_file=${latency_calculator_docker_file} \
--proxy_task_search_controller_docker_id=${proxy_task_search_controller_docker_id}
# The command below passes 'dummy' arguments for trainer-docker
# and latency-docker. You need to modify them for your own docker.
python3 vertex_nas_cli.py search_proxy_task \
--service_account=${service_account} \
--proxy_task_search_controller_docker_id=${proxy_task_search_controller_docker_id} \
--proxy_task_config_generator_module=${proxy_task_config_generator_module} \
--proxy_task_model_selection_job_id=${proxy_task_model_selection_job_id} \
--proxy_task_model_selection_job_region=${region} \
--desired_accuracy_correlation={$desired_accuracy_correlation}\
--training_time_hrs_limit=${training_time_hrs_limit} \
--desired_latency_correlation=${desired_latency_correlation} \
--early_stop_proxy_task_if_not_best=${early_stop_proxy_task_if_not_best} \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--job_name=${job_name} \
--search_space_module=${search_space_module} \
--accelerator_type=${accelerator_type} \
--num_gpus=${num_gpus} \
--root_output_dir=${root_output_dir} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_docker_flags \
dummy_latency_flag1="dummy_latency_val" \
--target_device_type=${target_device_type} \
--search_docker_flags \
dummy_trainer_flag1="dummy_trainer_val"
이 프록시 태스크 검색 컨트롤러 작업을 시작하면 작업 링크가 수신됩니다. 작업 이름은 프리픽스 Search_controller_로 시작합니다. 예시 작업 UI는 다음과 같습니다.
search_controller_dir에는 모든 출력이 포함되며 View logs 링크를 클릭하여 로그를 확인할 수 있습니다.
이 작업은 기본적으로 클라우드에서 하나의 CPU를 사용하여 커스텀 작업으로 백그라운드에서 실행한 다음 프록시 태스크 평가에 대해 하위 NAS 작업을 시작하고 관리합니다.
각 프록시 태스크 NAS 작업 이름은 ProxyTask_<your-job-name>_<proxy-task-name>과 같습니다. 여기서 <proxy-task-name>은 각 프록시 태스크에 대해 프록시 태스크 구성 생성기 모듈이 제공하는 이름입니다. 프록시 태스크 평가는 한 번에 하나만 실행됩니다.
다음 명령어를 실행할 수도 있습니다.
gcloud storage cat gs://<path to 'search_controller_dir'>/SEARCH_CONTROLLER_STATE.json
이 명령어는 모든 프록시 태스크 평가 및 검색 컨트롤러 작업의 현재 상태, 작업 이름, 각 평가의 링크를 요약해서 보여줍니다.
{
"proxy_tasks_map": {
"mnasnet_proxy_training_data_pct_25": {
"proxy_task_stats": {
"training_steps": [
1249,
2499,
...,
18749
],
"accuracy_correlation_over_step": [
-0.06666666666666667,
-0.6,
...,
0.7857142857142856
],
"accuracy_correlation_p_value_over_step": [
0.8618005952380953,
0.016666115520282188,
...,
0.005505952380952381
],
"median_accuracy_over_step": [
0.011478611268103123,
0.04956454783678055,
...,
0.32932570576667786
],
"median_training_time_hrs_over_step": [
0.11611097933475001,
0.22913257125276987,
...,
1.6682701704073444
],
"latency_correlation": 0.9555555555555554,
"latency_correlation_p_value": 5.5114638447971785e-06,
"stopping_state": "Met desired correlation",
"posted_stop_trials_message": true,
"final_training_time_in_hours": 1.6675102778428197,
"final_training_steps": 18512
},
"proxy_task_name": "mnasnet_proxy_training_data_pct_25",
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/4173661476642357248",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/4173661476642357248/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/8785347495069745152",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/8785347495069745152/cpu?project=my-project"
},
...,
"mnasnet_proxy_training_data_pct_95": {
"proxy_task_stats": {
"training_steps": [
1249,
...,
18749
],
"accuracy_correlation_over_step": [
-0.3333333333333333,
...,
0.7857142857142856,
-5.0
],
"accuracy_correlation_p_value_over_step": [
0.21637345679012346,
...,
0.005505952380952381,
-5.0
],
"median_accuracy_over_step": [
0.01120645459741354,
...,
0.38238024711608887,
-1.0
],
"median_training_time_hrs_over_step": [
0.11385884770307843,
...,
1.5466042930547819,
-1.0
],
"latency_correlation": 0.9555555555555554,
"latency_correlation_p_value": 5.5114638447971785e-06,
"stopping_state": "Met desired correlation",
"posted_stop_trials_message": true,
"final_training_time_in_hours": 1.533235285929564,
"final_training_steps": 17108
},
"proxy_task_name": "mnasnet_proxy_training_data_pct_95",
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/2341822328209408000",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/2341822328209408000/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/7575005095213924352",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/7575005095213924352/cpu?project=my-project"
}
},
"best_proxy_task_name": "mnasnet_proxy_training_data_pct_75"
}
proxy_tasks_map은 각 프록시 태스크 평가의 출력을 저장하고 best_proxy_task_name은 검색을 위한 최상의 프록시 태스크를 기록합니다. 각 프록시 태스크 항목에는 정확성 상관관계의 진행률, p-값, 중앙값 정확도, 학습 단계 중 중앙 학습 시간을 기록하는 proxy_task_stats와 같은 추가 데이터가 있습니다. 또한 해당되는 경우 지연 시간 관련 상관관계를 기록하고 이 작업을 중지한 이유(예: 학습 시간 제한 초과) 및 작업이 중지된 학습 단계를 기록합니다. 다음 명령어를 실행하여 search_controller_dir의 콘텐츠를 로컬 폴더에 복사하여 이러한 통계를 플롯으로 볼 수도 있습니다.
gcloud storage cp gs://<path to 'search_controller_dir'>/* /your/local/dir
플롯 이미지를 검사합니다. 예를 들어 다음 플롯은 최적의 프록시 태스크에 대한 정확도 상관관계와 학습 시간을 보여줍니다.
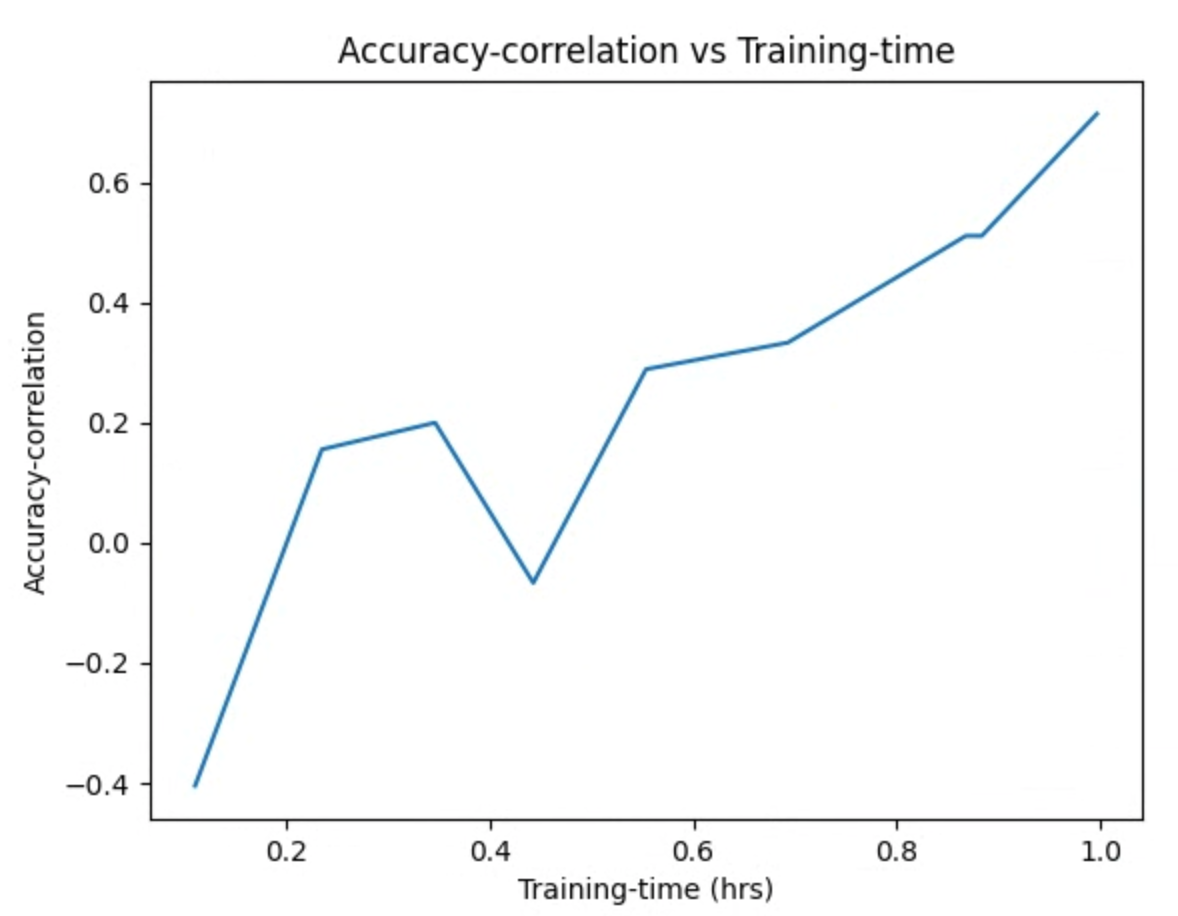
검색이 완료되고 최적의 프록시 태스크 구성을 찾았으면 다음을 수행해야 합니다.
- 학습 단계 수를 우승자 프록시 태스크의
final_training_steps로 설정합니다. - 코사인 감소 단계를
final_training_steps와 동일하게 설정하여 마지막에는 학습률이 거의 0이 되도록 합니다. - [선택사항] 학습 종료 시 검증 점수 평가를 한 번 수행하여 여러 번에 걸친 평가 비용을 절약합니다.
프록시 태스크 검색을 위한 온프레미스 지연 시간 기기 사용
프록시 태스크 검색에 온프레미스 지연 시간 기기를 사용하려면 Google Cloud에서 지연 시간 docker를 실행하지 않으려는 것이므로 지연 시간 Docker 및 지연 시간 Docker 플래그가 없는 search_proxy_task 명령어를 실행합니다. 다음으로 튜토리얼 4에 설명된 run_latency_calculator_local 명령어를 사용하여 온프레미스 지연 시간 계산기 작업을 실행합니다. --search_job_id 플래그를 전달하는 대신 search_proxy_task 명령어를 실행한 후 가져온 숫자 proxy-task-search job-id로 --controller_job_id 플래그를 전달합니다.
프록시 태스크 검색 컨트롤러 작업 재개
다음 상황에서는 프록시 태스크 검색 컨트롤러 작업을 재개해야 합니다.
- 상위 프록시 태스크 검색 컨트롤러 작업이 종료된 경우(드문 경우)
- 프록시 태스크 검색 컨트롤러 작업을 실수로 취소한 경우
- 나중에(태스크 며칠 후에도) 프록시 태스크 검색 공간을 확장하려는 경우
먼저 하위 NAS 반복 작업(NAS 탭)이 실행 중이면 이를 취소하지 않습니다. 그런 다음 상위 프록시 태스크 검색 컨트롤러 작업을 다시 시작하려면 이전과 같이 search_proxy_task 명령어를 실행하지만 이번에는--previous_proxy_task_search_dir 플래그를 전달하고 이전 프록시 태스크 검색 컨트롤러 작업의 출력 디렉터리로 설정합니다. 재개된 프록시 태스크 검색 컨트롤러 작업은 디렉터리에서 이전 상태를 로드하고 이전과 같이 계속 작동합니다.
최종 점검사항
프록시 태스크에 대한 두 가지 최종 검사에는 리워드 범위 및 검색 후 분석을 위한 데이터 저장이 포함됩니다.
리워드 범위
컨트롤러에 보고된 리워드는 [1e-3, 10] 범위에 있어야 합니다. 그렇지 않으면 이 목표가 달성되도록 리워드를 인공적으로 조정할 수 있습니다.
검색 후 분석을 위해 데이터 저장
프록시 태스크 코드는 나중에 검색 공간을 분석하는 데 도움이 될 수 있는 추가 측정항목 및 데이터를 Cloud Storage 위치에 저장해야 합니다. 신경망 아키텍처 검색 플랫폼은 기록할 other_metrics를 최대 5개만 지원합니다.
모든 추가 측정항목은 나중에 분석할 수 있도록 Cloud Storage 위치에 저장해야 합니다.