Neste guia, mostramos como executar um job de pesquisa de arquitetura neural da Vertex AI usando os espaços de pesquisa pré-criados do Google e o código do treinador pré-criado com base no TF-vision do MnasNet e do SpineNet. Consulte o notebook de classificação do MnasNet e o notebook de detecção de objetos do Spinnaker para ver exemplos completos.
Preparação de dados para um treinador pré-compilado
O treinador pré-criado da pesquisa de arquitetura neural exige que os dados estejam no formato TFRecord, contendo tf.train.Examples. Os tf.train.Examples precisam incluir os seguintes campos:
'image/encoded': tf.FixedLenFeature(tf.string)
'image/height': tf.FixedLenFeature(tf.int64)
'image/width': tf.FixedLenFeature(tf.int64)
# For image classification only.
'image/class/label': tf.FixedLenFeature(tf.int64)
# For object detection only.
'image/object/bbox/xmin': tf.VarLenFeature(tf.float32)
'image/object/bbox/xmax': tf.VarLenFeature(tf.float32)
'image/object/bbox/ymin': tf.VarLenFeature(tf.float32)
'image/object/bbox/ymax': tf.VarLenFeature(tf.float32)
'image/object/class/label': tf.VarLenFeature(tf.int64)
Siga estas instruções de preparação do ImageNet.
Para converter seus dados, use o script de análise incluído no exemplo de código e utilitários que você baixou. Para personalizar a análise de dados, modifique os arquivos tf_vision/dataLoaders/*_input.py.
Saiba mais sobre o TFRecord e o tf.train.Example.
Definir as variáveis de ambiente do experimento
Antes de realizar os experimentos, você precisará definir várias variáveis de ambiente, incluindo:
- TRAINER_DOCKER_ID:
${USER}_nas_experiment(formato recomendado) Locais do Cloud Storage dos conjuntos de dados de treinamento e validação que o experimento usará. Por exemplo (CoCo para detecção):
gs://cloud-samples-data/ai-platform/built-in/image/coco/train*gs://cloud-samples-data/ai-platform/built-in/image/coco/val*
Local do Cloud Storage na saída do experimento. Formato recomendado:
gs://${USER}_nas_experiment
REGION: uma região que precisa ser igual à região do bucket de saída do experimento. Por exemplo,
us-central1.PARAM_OVERRIDE: um arquivo .yaml que substitui os parâmetros do treinador pré-compilado A pesquisa de arquitetura neural fornece algumas configurações padrão que podem ser usadas:
PROJECT_ID=PROJECT_ID
TRAINER_DOCKER_ID=TRAINER_DOCKER_ID
LATENCY_CALCULATOR_DOCKER_ID=LATENCY_CALCULATOR_DOCKER_ID
GCS_ROOT_DIR=OUTPUT_DIR
REGION=REGION
PARAM_OVERRIDE=tf_vision/configs/experiments/spinenet_search_gpu.yaml
TRAINING_DATA_PATH=gs://PATH_TO_TRAINING_DATA
VALIDATION_DATA_PATH=gs://PATH_TO_VALIDATION_DATA
É possível selecionar e/ou modificar o arquivo de modificação que corresponde aos seus requisitos de treinamento. Considere o seguinte:
- É possível definir
--accelerator_typepara escolher entre GPU ou CPU. Para executar apenas alguns períodos para testes rápidos usando a CPU, defina a sinalização--accelerator_type=""e use o arquivo de configuraçãotf_vision/test_files/fast_nas_detection_spinenet_search_for_testing.yaml. - Número de períodos
- Tempo de execução do treinamento
- Hiperparâmetros, como taxa de aprendizado
Para ver uma lista de todos os parâmetros para controlar os jobs de treinamento, consulte tf_vision/configs/. Veja os principais parâmetros:
task:
train_data:
global_batch_size: 80
validation_data:
global_batch_size: 16
init_checkpoint: null
trainer:
train_steps: 16634
steps_per_loop: 1386
optimizer_config:
learning_rate:
cosine:
initial_learning_rate: 0.16
decay_steps: 16634
type: 'cosine'
warmup:
type: 'linear'
linear:
warmup_learning_rate: 0.0067
warmup_steps: 1386
Crie um bucket do Cloud Storage para pesquisa de arquitetura neural para armazenar as saídas dos jobs (ou seja, checkpoints):
gcloud storage buckets create $GCS_ROOT_DIR
Criar um contêiner de treinador e um contêiner de calculadora de latência
O comando a seguir vai criar uma imagem de treinador em Google Cloud com o seguinte URI:
gcr.io/PROJECT_ID/TRAINER_DOCKER_ID, que será usado no job de pesquisa de arquitetura neural na próxima etapa.
python3 vertex_nas_cli.py build \
--project_id=PROJECT_ID \
--trainer_docker_id=TRAINER_DOCKER_ID \
--latency_calculator_docker_id=LATENCY_CALCULATOR_DOCKER_ID \
--trainer_docker_file=tf_vision/nas_multi_trial.Dockerfile \
--latency_calculator_docker_file=tf_vision/latency_computation_using_saved_model.Dockerfile
Para alterar o espaço de pesquisa e recompensar, atualize-os no arquivo Python e, em seguida, recrie a imagem do Docker.
Testar o treinador localmente
Como o lançamento de um job no serviço do Google Cloud leva vários minutos, pode ser mais
conveniente testar o Docker do treinador localmente. Por exemplo, validar o formato
TFRecord. Use o espaço de pesquisa spinenet como exemplo. Execute o job de pesquisa localmente (o modelo será amostrado aleatoriamente):
# Define the local job output dir.
JOB_DIR="/tmp/iod_${search_space}"
python3 vertex_nas_cli.py search_in_local \
--project_id=PROJECT_ID \
--trainer_docker_id=TRAINER_DOCKER_ID \
--prebuilt_search_space=spinenet \
--use_prebuilt_trainer=True \
--local_output_dir=${JOB_DIR} \
--search_docker_flags \
params_override="tf_vision/test_files/fast_nas_detection_spinenet_search_for_testing.yaml" \
training_data_path=TEST_COCO_TF_RECORD \
validation_data_path=TEST_COCO_TF_RECORD \
model=retinanet
training_data_path e validation_data_path são os
caminhos para seus TFRecords.
Iniciar uma pesquisa de estágio 1 seguida de um job de treinamento de estágio 2 em Google Cloud
Consulte o bloco de notas de classificação do MnasNet e o notebook de detecção de objetos do SpineNet para ver exemplos completos.
É possível definir a sinalização
--max_parallel_nas_triale--max_nas_trialpara personalizar. A pesquisa de arquitetura neural iniciarámax_parallel_nas_trialtestes em paralelo e será concluída apósmax_nas_trialtestes.Se a sinalização
--target_device_latency_msestiver definida, um job separadolatency calculatorserá iniciado com o acelerador especificado pela sinalização--target_device_type.O controlador de pesquisa de arquitetura neural fornecerá a cada teste uma sugestão de novo candidato a arquitetura por meio do FLAG
--nas_params_str.Cada avaliação criará um gráfico com base no valor da FLAG
nas_params_stre iniciará um job de treinamento. Cada avaliação também salva o valor dela em um arquivo json (emos.path.join(nas_job_dir, str(trial_id), "nas_params_str.json")).
Recompensar com uma restrição de latência
O notebook de classificação do MnasNet mostra um exemplo de pesquisa restrita por latência baseada em dispositivo com cloud-cpu.
Para pesquisar modelos com restrição de latência, o treinador pode informar o prêmio como uma função de precisão e latência.
No código-fonte compartilhado, o prêmio é calculado da seguinte maneira:
def compute_reward(target_latency, accuracy, inference_latency, weight=0.07):
"""Compute reward from accuracy and latency."""
speed_ratio = target_latency / inference_latency
return accuracy * (speed_ratio**weight)
Você pode usar outras variantes do cálculo reward na página 3
do artigo do mnasnet.
target_device_typeespecifica o tipo de dispositivo de destino compatível com Google Cloud, comoNVIDIA_TESLA_P100.use_prebuilt_latency_calculatorusa nossa calculadora de latência pré-criadatf_vision/latency_computation_using_saved_model.py.target_device_latency_msespecifica a latência do dispositivo de destino.
Para informações sobre como personalizar a função de cálculo de latência,
consulte tf_vision/latency_computation_using_saved_model.py.
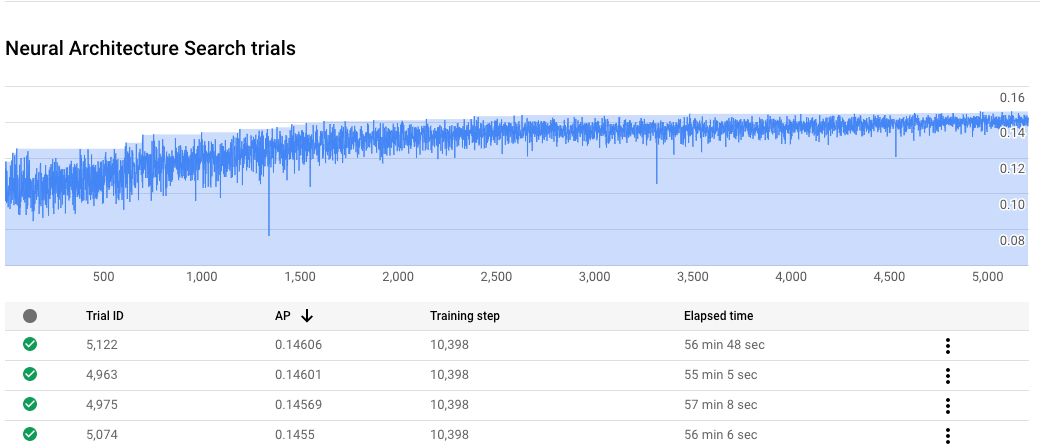
Monitorar o progresso do job de pesquisa de arquitetura neural
No Google Cloud console, na página do job, o gráfico mostra o reward vs. trial number,
enquanto a tabela mostra os prêmios de cada teste. Encontre as melhores avaliações
com a maior recompensa.
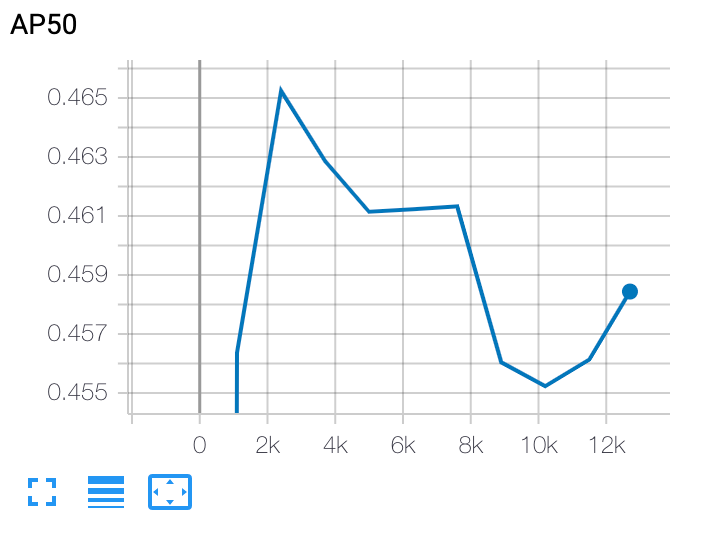
Fazer o gráfico de uma curva de treinamento de estágio 2
Após o treinamento da segunda etapa, use o Cloud Shell ou o Google Cloud
TensorBoard para plotar
a curva de treinamento, apontando-o para o diretório do job:
Implantar um modelo selecionado
Para criar um SavedModel, use o script export_saved_model.py com params_override=${GCS_ROOT_DIR}/${TRIAL_ID}/params.yaml.