表形式ワークフローは、表形式のデータによるエンドツーエンドの ML を実現するスケーラブルな統合フルマネージドのパイプラインのセットです。モデル開発に Google のテクノロジーを使用し、ニーズに合わせたカスタマイズ オプションを提供します。
利点
- フルマネージド: アップデート、依存関係、競合を心配する必要がありません。
- スケーリングが簡単: データセットの増加に合わせてインフラストラクチャを再構築する必要がありません。
- パフォーマンスの最適化: ワークフローの要件に合わせて適切なハードウェアが自動的に構成されます。
- 高度な統合: Vertex AI Pipelines や Vertex AI Experiments など、Vertex AI MLOps スイートのプロダクトと互換性があるため、短時間で多くのテストを実行できます。
技術概要
各ワークフローは、Vertex AI Pipelines のマネージド インスタンスです。
Vertex AI Pipelines は、Kubeflow Pipelines を実行するサーバーレス サービスです。パイプラインを使用して、ML とデータ準備タスクを自動化し、モニタリングできます。パイプラインの各ステップは、パイプラインのワークフローの一部として実行されます。たとえば、パイプラインにはデータの分割、データタイプの変換、モデルのトレーニングなどのステップを含めることができます。ステップはパイプライン コンポーネントのインスタンスで、入力、出力、コンテナ イメージが含まれます。ステップの入力は、パイプラインの入力から設定することも、このパイプライン内の他のステップの出力に応じて設定することもできます。これらの依存関係は、パイプラインのワークフローを有向非巡回グラフとして定義します。
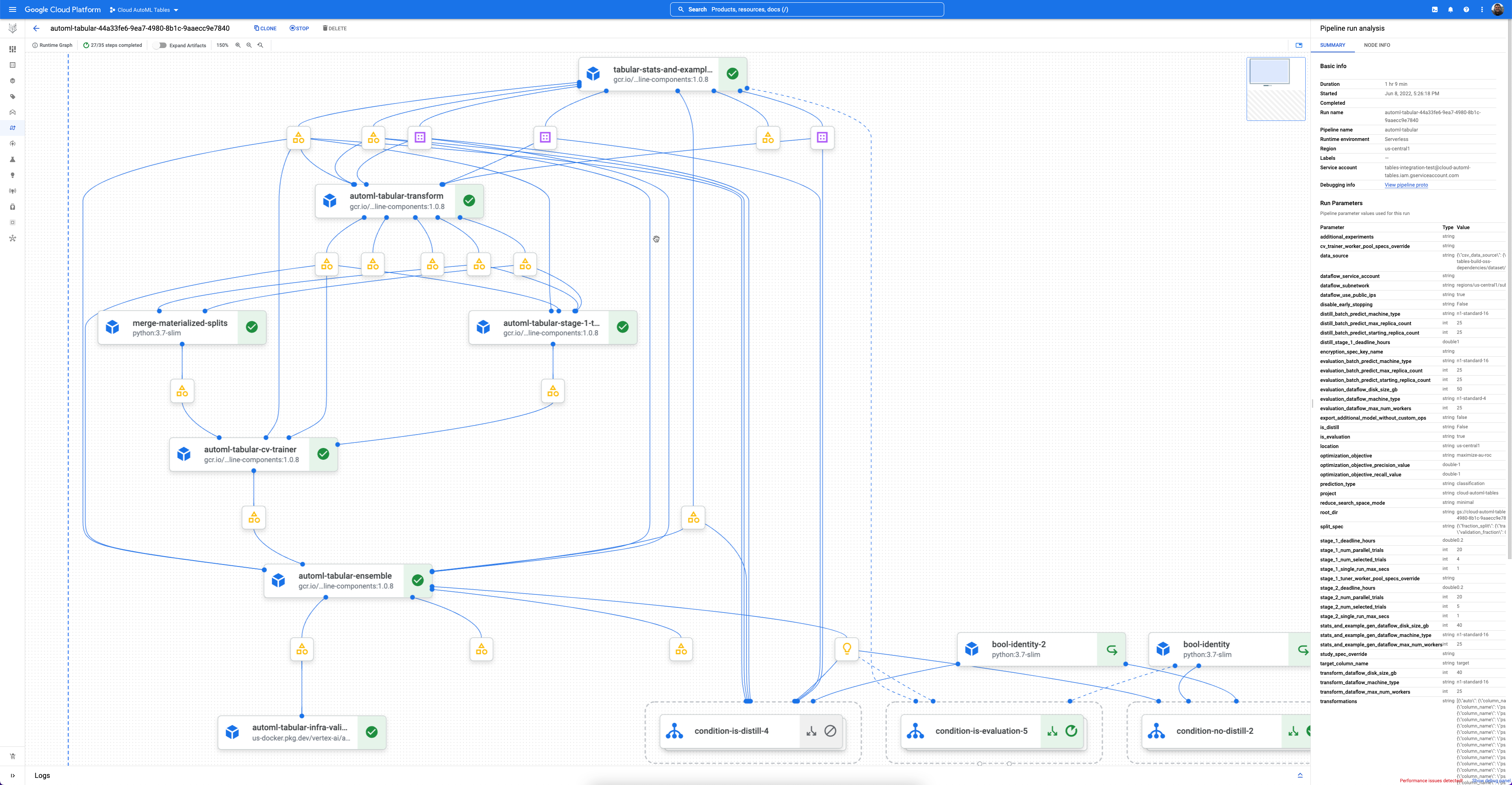
使ってみる
ほとんどの場合、Google Cloud Pipeline Components SDK を使用して、パイプラインを定義して実行します。次のサンプルコードにこのプロセスを示します。実際のコードの実装は、これとは異なる場合があります。
// Define the pipeline and the parameters
template_path, parameter_values = tabular_utils.get_default_pipeline_and_parameters(
…
optimization_objective=optimization_objective,
data_source=data_source,
target_column_name=target_column_name
…)
// Run the pipeline
job = pipeline_jobs.PipelineJob(..., template_path=template_path, parameter_values=parameter_values)
job.run(...)
サンプルの Colab やノートブックについては、営業担当者にお問い合わせいただくか、リクエスト フォームをご利用ください。
バージョニングとメンテナンス
表形式のワークフローには、アプリケーションに変更を加えることなく、継続的な更新と改善を可能にする効果的なバージョニング システムが用意されています。
各ワークフローは、Google Cloud Pipeline Components SDK の一部としてリリースおよび更新されます。ワークフローに対する更新と変更は、そのワークフローの新しいバージョンとしてリリースされます。ワークフローの以前のバージョンは、以前のバージョンの SDK でいつでも利用できます。SDK のバージョンが固定されている場合、ワークフローも固定されます。
利用可能なワークフロー
Vertex AI では、次の表形式のワークフローを利用できます。
| 名前 | 型 | サービス提供状況 |
|---|---|---|
| 特徴変換エンジン | 特徴量エンジニアリング | 公開プレビュー版 |
| エンドツーエンドの AutoML | 分類と回帰 | 一般提供 |
| TabNet | 分類と回帰 | 公開プレビュー版 |
| ワイド&ディープ | 分類と回帰 | 公開プレビュー版 |
| 予測 | 予測 | 公開プレビュー版 |
詳細情報とサンプル ノートブックについては、営業担当者にご連絡いただくか、リクエスト フォームをご利用ください。
特徴変換エンジン
特徴変換エンジンは、特徴選択と特徴変換を実行します。特徴選択が有効になっている場合、特徴変換エンジンはランク付けされた重要な特徴のセットを作成します。特徴変換が有効になっている場合、特徴変換エンジンは特徴を処理して、モデルのトレーニングとモデルの提供の入力が一貫性を持つようにします。特徴変換エンジンは単独で使用することも、表形式のトレーニング ワークフローと組み合わせて使用することもできます。TensorFlow と TensorFlow 以外のフレームワークの両方をサポートしています。
詳細については、特徴量エンジニアリングをご覧ください。
分類と回帰の表形式ワークフロー
エンドツーエンドの AutoML の表形式ワークフロー
エンドツーエンドの AutoML の表形式ワークフローは、分類タスクと回帰タスクの完全な AutoML パイプラインです。AutoML API に似ていますが、制御する対象と自動化する対象を選択できます。パイプライン全体を管理するのではなく、パイプライン内のすべてのステップをコントロールします。パイプラインについて、次のようなコントロールを行えます。
- データの分割
- 特徴量エンジニアリング
- アーキテクチャの検索
- モデルのトレーニング
- モデルのアンサンブル
- モデルの抽出
利点
- 数 TB のサイズ、最大 1,000 列の大規模なデータセットをサポートします。
- アーキテクチャ タイプの検索スペースを制限するか、アーキテクチャ検索をスキップすることで、安定性を向上させ、トレーニング時間を短縮できます。
- トレーニングとアーキテクチャ検索に使用するハードウェアを手動で選択して、トレーニングの速度を向上できます。
- 抽出またはアンサンブル サイズの変更により、モデルサイズを縮小し、レイテンシを改善できます。
- 各 AutoML コンポーネントは、強力なパイプライン グラフ インターフェースで検査でき、変換されたデータテーブル、評価済みのモデル アーキテクチャなど多くの詳細を確認できます。
- パラメータやハードウェアのカスタマイズ、プロセス ステータスやログの表示など、各 AutoML コンポーネントの柔軟性と透明性が拡大されています。
入出と出力
- Cloud Storage から BigQuery テーブルまたは CSV ファイルを入力として受け取ります。
- Vertex AI モデルを出力として生成します。
- 中間出力には、データセットの統計情報とデータセット分割が含まれます。
詳細については、エンドツーエンドの AutoML の表形式ワークフローをご覧ください。
TabNet の表形式ワークフロー
TabNet 用の表形式ワークフローは、分類モデルや回帰モデルのトレーニングに使用できるパイプラインです。TabNet は、シーケンシャル アテンションを使用して、各決定ステップで推論の対象とする特徴を選択します。これにより、学習能力が最も顕著な特徴に使用されるため、解釈可能性と学習効率が向上します。
利点
- データセットのサイズ、推論タイプ、トレーニングの予算に基づいて、適切なハイパーパラメータ検索空間を自動的に選択します。
- Vertex AI との統合。トレーニング済みモデルは Vertex AI モデルです。バッチ推論を実行することや、オンライン推論のモデルをすぐにデプロイすることが可能です。
- モデル固有の解釈可能性を提供。TabNet が判断に使用した特徴の分析情報が得られます。
- GPU トレーニングをサポート。
入出と出力
Cloud Storage から BigQuery テーブルまたは CSV ファイルを入力として受け取り、Vertex AI モデルを出力として生成します。
詳細については、TabNet の表形式ワークフローをご覧ください。
ワイド & ディープの表形式ワークフロー
ワイド&ディープ用の表形式ワークフローは、分類モデルや回帰モデルのトレーニングに使用できるパイプラインです。ワイド&ディープでは、ワイド線形モデルとディープ ニューラル ネットワークを一緒にトレーニングします。記憶化と一般化の利点が組み合わされています。いくつかのオンライン テストでは、ワイド&ディープは、ワイドのみのモデルやディープのみのモデルに比べ、Google ストア アプリケーションの獲得数を大幅に増加させるという結果が得られています。
利点
- Vertex AI との統合。トレーニング済みモデルは Vertex AI モデルです。バッチ推論を実行することや、オンライン推論のモデルをすぐにデプロイすることが可能です。
入出と出力
Cloud Storage から BigQuery テーブルまたは CSV ファイルを入力として受け取り、Vertex AI モデルを出力として生成します。
詳細については、ワイド &ディープの表形式ワークフローをご覧ください。
予測用の表形式ワークフロー
予測用の表形式ワークフロー
予測用の表形式ワークフローは、予測タスクの完全なパイプラインです。AutoML API に似ていますが、制御する対象と自動化する対象を選択できます。パイプライン全体を管理するのではなく、パイプライン内のすべてのステップをコントロールします。パイプラインについて、次のようなコントロールを行えます。
- データの分割
- 特徴量エンジニアリング
- アーキテクチャの検索
- モデルのトレーニング
- モデルのアンサンブル
利点
- 最大 1 TB のサイズで、最大 200 列までの大規模なデータセットをサポートします。
- アーキテクチャ タイプの検索スペースを制限するか、アーキテクチャ検索をスキップすることで、安定性を向上させ、トレーニング時間を短縮できます。
- トレーニングとアーキテクチャ検索に使用するハードウェアを手動で選択して、トレーニングの速度を向上できます。
- アンサンブル サイズを変更することで、モデルサイズを縮小し、レイテンシを改善できます。
- 強力なパイプライン グラフ インターフェースで各コンポーネントを検査でき、変換されたデータテーブル、評価されたモデル アーキテクチャなど多くの詳細を確認できます。
- パラメータやハードウェアのカスタマイズ、プロセス ステータスやログの表示など、各コンポーネントの柔軟性と透明性が拡大されています。
入出と出力
- Cloud Storage から BigQuery テーブルまたは CSV ファイルを入力として受け取ります。
- Vertex AI モデルを出力として生成します。
- 中間出力には、データセットの統計情報とデータセット分割が含まれます。
詳細については、予測用の表形式ワークフローをご覧ください。
次のステップ
- エンドツーエンドの AutoML の表形式ワークフローについて確認する。
- TabNet の表形式ワークフローについて確認する。
- ワイド & ディープの表形式ワークフローについて確認する。
- 予測用の表形式ワークフローについて確認する。
- 特徴量エンジニアリングについて確認する。
- 表形式のワークフローの料金について確認する。