このドキュメントでは、エンドツーエンド AutoML のパイプラインとコンポーネントの概要について説明します。エンドツーエンド AutoML でモデルをトレーニングする方法については、エンドツーエンド AutoML でモデルをトレーニングするをご覧ください。
エンドツーエンドの AutoML の表形式ワークフローは、分類タスクと回帰タスクの完全な AutoML パイプラインです。AutoML API に似ていますが、制御する対象と自動化する対象を選択できます。パイプライン全体を管理するのではなく、パイプライン内のすべてのステップをコントロールします。パイプラインについて、次のようなコントロールを行えます。
- データの分割
- 特徴量エンジニアリング
- アーキテクチャの検索
- モデルのトレーニング
- モデルのアンサンブル
- モデルの抽出
利点
エンドツーエンド AutoML の表形式ワークフローの利点の一部を以下に示します。
- 数 TB のサイズ、最大 1,000 列の大規模なデータセットをサポートします。
- アーキテクチャ タイプの検索スペースを制限するか、アーキテクチャ検索をスキップすることで、安定性を向上させ、トレーニング時間を短縮できます。
- トレーニングとアーキテクチャ検索に使用するハードウェアを手動で選択して、トレーニングの速度を向上できます。
- 抽出またはアンサンブル サイズの変更により、モデルサイズを縮小し、レイテンシを改善できます。
- 各 AutoML コンポーネントは、強力なパイプライン グラフ インターフェースで検査でき、変換されたデータテーブル、評価済みのモデル アーキテクチャなど多くの詳細を確認できます。
- パラメータやハードウェアのカスタマイズ、プロセス ステータスやログの表示など、各 AutoML コンポーネントの柔軟性と透明性が拡大されています。
Vertex AI Pipelines 上のエンドツーエンドの AutoML
エンドツーエンドの AutoML の表形式ワークフローは、Vertex AI Pipelines のマネージド インスタンスです。
Vertex AI Pipelines は、Kubeflow Pipelines を実行するサーバーレス サービスです。パイプラインを使用して、ML とデータ準備タスクを自動化し、モニタリングできます。パイプラインの各ステップは、パイプラインのワークフローの一部として実行されます。たとえば、パイプラインにはデータの分割、データタイプの変換、モデルのトレーニングなどのステップを含めることができます。ステップはパイプライン コンポーネントのインスタンスで、入力、出力、コンテナ イメージが含まれます。ステップの入力は、パイプラインの入力から設定することも、このパイプライン内の他のステップの出力に応じて設定することもできます。これらの依存関係は、パイプラインのワークフローを有向非巡回グラフとして定義します。
パイプラインとコンポーネントの概要
次の図は、エンドツーエンド AutoML の表形式ワークフローのモデリング パイプラインを示しています。

パイプラインは、次のコンポーネントで構成されます。
- feature-transform-engine: 特徴量エンジニアリングを実行します。詳細については、特徴量変換エンジンをご覧ください。
- split-materialized-data: 実体化されたデータをトレーニング セット、評価セット、テストセットに分割します。
入力:
- 実体化されたデータ:
materialized_data
出力:
- 実体化されたトレーニング分割:
materialized_train_split - 実体化された評価分割:
materialized_eval_split - 実体化されたテストセット:
materialized_test_split
- 実体化されたデータ:
- merge-materialized-splits - 実体化された評価分割と実体化されたトレイン分割を結合します。
automl-tabular-stage-1-tuner - モデル アーキテクチャの検索を実行し、ハイパーパラメータを調整します。
- アーキテクチャは、ハイパーパラメータの組によって定義されます。
- これらのハイパーパラメータには、モデルタイプとモデル パラメータが含まれます。
- 考慮されるモデルタイプは、ニューラル ネットワークとブーストツリーです。
- システムは、考慮される各アーキテクチャごとにモデルをトレーニングします。
automl-tabular-cv-trainer - 入力データのさまざまなフォールドでモデルをトレーニングすることでアーキテクチャを交差検証します。
- 考慮するアーキテクチャは、前のステップで最適な結果をもたらしたアーキテクチャです。
- システムは、最適なアーキテクチャを約 10 個選択します。正確な数はトレーニングの予算で定義されます。
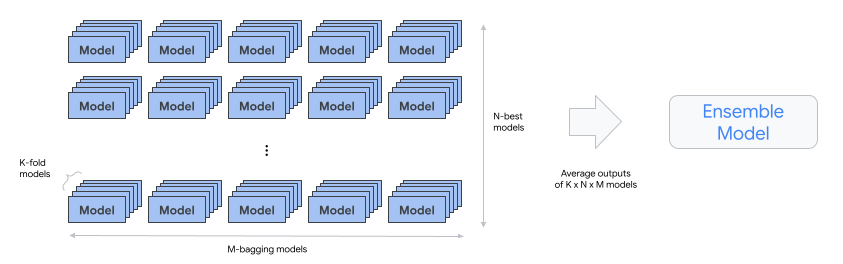
automl-tabular-ensemble - 最終モデルを生成する最適なアーキテクチャをアンサンブルします。
- 次の図は、バギングを使用した K-fold 交差検証を示しています。
condition-is-distill - 省略可。アンサンブル モデルの小さいバージョンが作成されます。
- モデルが小さいほど、推論のレイテンシと費用が削減されます。
automl-tabular-infra-validator - トレーニング済みモデルが有効なモデルかどうかを検証します。
model-upload - モデルをアップロードします。
condition-is-evaluation - 省略可。テストセットを使用して評価指標を計算します。