Questo documento fornisce una panoramica della pipeline e dei componenti di AutoML end-to-end. Per scoprire come addestrare un modello con AutoML end-to-end, consulta Addestrare un modello con AutoML end-to-end.
Il flusso di lavoro tabulare per AutoML end-to-end è una pipeline AutoML completa per le attività di classificazione e regressione. È simile all'API AutoML, ma ti consente di scegliere cosa controllare e cosa automatizzare. Anziché avere controlli per l'intera pipeline, hai controlli per ogni passaggio della pipeline. Questi controlli della pipeline includono:
- Suddivisione dei dati
- Feature engineering
- Ricerca dell'architettura
- Addestramento del modello
- Combinazione di modelli
- Distillazione del modello
Vantaggi
Di seguito sono elencati alcuni dei vantaggi del flusso di lavoro tabulare per AutoML end-to-end:
- Supporta set di dati di grandi dimensioni di più TB e fino a 1000 colonne.
- Consente di migliorare la stabilità e ridurre i tempi di addestramento limitando lo spazio di ricerca dei tipi di architettura o saltando la ricerca dell'architettura.
- Consente di migliorare la velocità di addestramento selezionando manualmente l'hardware utilizzato per l'addestramento e la ricerca dell'architettura.
- Consente di ridurre le dimensioni del modello e migliorare la latenza con la distillazione o modificando le dimensioni dell'ensemble.
- Ogni componente AutoML può essere esaminato in una potente interfaccia grafica delle pipeline che consente di visualizzare le tabelle di dati trasformate, le architetture dei modelli valutate e molti altri dettagli.
- Ogni componente AutoML offre maggiore flessibilità e trasparenza, ad esempio la possibilità di personalizzare parametri, hardware, visualizzare lo stato del processo, i log e altro ancora.
AutoML end-to-end su Vertex AI Pipelines
Il flusso di lavoro tabulare per AutoML end-to-end è un'istanza gestita di Vertex AI Pipelines.
Vertex AI Pipelines è un servizio serverless che esegue pipeline Kubeflow. Puoi utilizzare le pipeline per automatizzare e monitorare le attività di machine learning e preparazione dei dati. Ogni passaggio di una pipeline esegue una parte del flusso di lavoro della pipeline. Ad esempio, una pipeline può includere passaggi per dividere i dati, trasformare i tipi di dati e addestrare un modello. Poiché i passaggi sono istanze di componenti della pipeline, hanno input, output e un'immagine container. Gli input dei passaggi possono essere impostati dagli input della pipeline o possono dipendere dall'output di altri passaggi all'interno di questa pipeline. Queste dipendenze definiscono il flusso di lavoro della pipeline come un grafo diretto aciclico.
Panoramica della pipeline e dei componenti
Il seguente diagramma mostra la pipeline di modellazione per Tabular Workflow for End-to-End AutoML :

I componenti della pipeline sono:
- feature-transform-engine: esegue il feature engineering. Per maggiori dettagli, vedi Feature Transform Engine.
- split-materialized-data:
Suddivide i dati materializzati in un set di addestramento, un set di valutazione e un set di test.
Input:
- Dati materializzati
materialized_data.
Output:
- Divisione dell'addestramento materializzato
materialized_train_split. - Suddivisione della valutazione materializzata
materialized_eval_split. - Set di test materializzato
materialized_test_split.
- Dati materializzati
- merge-materialized-splits: unisce la suddivisione di valutazione materializzata e la suddivisione di addestramento materializzata.
automl-tabular-stage-1-tuner: esegue la ricerca dell'architettura del modello e ottimizza gli iperparametri.
- Un'architettura è definita da un insieme di iperparametri.
- Gli iperparametri includono il tipo di modello e i parametri del modello.
- I tipi di modelli presi in considerazione sono le reti neurali e gli alberi potenziati.
- Il sistema addestra un modello per ogni architettura considerata.
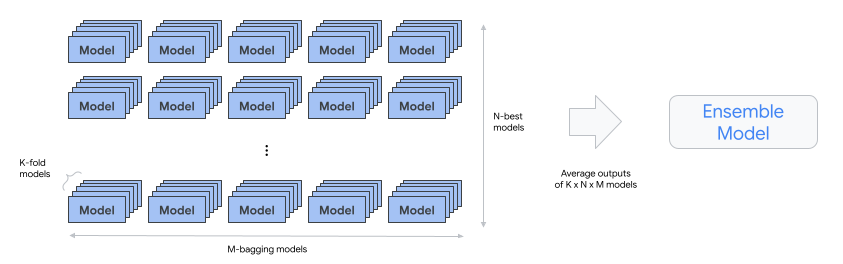
automl-tabular-cv-trainer: esegue la convalida incrociata delle architetture addestrando i modelli su diverse suddivisioni dei dati di input.
- Le architetture prese in considerazione sono quelle che hanno dato i migliori risultati nel passaggio precedente.
- Il sistema seleziona circa dieci architetture migliori. Il numero esatto è definito dal budget di addestramento.
automl-tabular-ensemble: combina le migliori architetture per produrre un modello finale.
- Il seguente diagramma illustra la convalida incrociata K-fold con bagging:
condition-is-distill - facoltativo. Crea una versione più piccola del modello di ensemble.
- Un modello più piccolo riduce la latenza e il costo dell'inferenza.
automl-tabular-infra-validator: convalida se il modello addestrato è valido.
model-upload: carica il modello.
condition-is-evaluation - Facoltativo. Utilizza il set di test per calcolare le metriche di valutazione.