Cuando usas un conjunto de datos para entrenar un modelo de AutoML, tus datos se dividen en tres divisiones: una división de entrenamiento, una división de validación y una división de prueba. El objetivo clave cuando se crean divisiones de datos es garantizar que el conjunto de prueba represente con exactitud los datos de producción. Esto garantiza que las métricas de evaluación proporcionen una señal precisa sobre el rendimiento del modelo en datos del mundo real.
En esta página, se describe cómo Vertex AI usa los conjuntos de entrenamiento, validación y prueba de tus datos para entrenar un modelo de AutoML, y cómo puedes controlar la forma en que se dividen tus datos entre estos tres conjuntos. Los algoritmos de división de datos para la clasificación y la regresión son diferentes de los algoritmos de división de datos para la previsión.
Divisiones de datos para la clasificación y la regresión
Cómo se usan las divisiones de datos
Las divisiones de datos se usan en el proceso de entrenamiento de la siguiente manera:
Pruebas de modelos
El conjunto de entrenamiento se usa para entrenar modelos con diferentes combinaciones de opciones de procesamiento previo, de arquitectura y de hiperparámetro. Estos modelos se evalúan en el conjunto de validación para garantizar la calidad, lo que guía la exploración de combinaciones de opciones adicionales. El conjunto de validación también se usa para seleccionar el mejor punto de control de la evaluación periódica durante el entrenamiento. Los mejores parámetros y arquitecturas determinados en la fase de ajuste en paralelo se usan para entrenar dos modelos de ensamble como se describe a continuación.
Evaluación del modelo
Vertex AI entrena un modelo de evaluación mediante el uso de conjuntos de entrenamiento y validación como datos de entrenamiento. Vertex AI genera las métricas de la evaluación final del modelo en este modelo mediante el uso del conjunto de prueba. Esta es la primera vez en el proceso que se usa el conjunto de prueba. Este enfoque garantiza que las métricas finales de evaluación sean un reflejo imparcial de lo bien que funcionará el modelo final entrenado en la producción.
Modelo de entrega
Un modelo se entrena con los conjuntos de entrenamiento, validación y prueba para maximizar la cantidad de datos de entrenamiento. Este modelo es el que usas para solicitar predicciones en línea o predicciones por lotes.
División de datos predeterminada
De forma predeterminada, Vertex AI usa un algoritmo de división aleatoria para separar los datos en las tres divisiones de datos. Vertex AI selecciona de forma aleatoria el 80% de tus filas de datos para el conjunto de entrenamiento, el 10% para el conjunto de validación y el 10% para el conjunto de prueba. Recomendamos la división predeterminada para los conjuntos de datos que tienen las siguientes características:
- No cambian con el tiempo.
- Son relativamente equilibrados.
- Se distribuyen como los datos que se usan para las predicciones en producción.
Para usar la división de datos predeterminada, acepta el valor predeterminado en la consola de Google Cloud o deja el campo División vacío para la API.
Opciones para controlar las divisiones de datos
Puedes controlar qué filas se seleccionan para cada división mediante uno de los siguientes enfoques:
- División aleatoria: establece los porcentajes de división y asigna las filas de datos de forma aleatoria.
- División manual: Selecciona filas específicas para usar en el entrenamiento, la validación y las pruebas en la columna de división de datos.
- División cronológica: Divide tus datos por tiempo en la columna de tiempo.
Elige solo una de estas opciones; haces la elección cuando entrenas el modelo. Algunas de estas opciones requieren que se realicen cambios en los datos de entrenamiento (por ejemplo, la columna de división de datos o la columna de tiempo). Incluir datos para las opciones de división de datos no requiere el uso de estas opciones. Aún puedes elegir otra opción cuando entrenas tu modelo.
La división predeterminada no es la mejor opción si se cumplen estas condiciones:
Si no estás entrenando un modelo de previsión, pero tus datos son urgentes.
En este caso, debes usar una división cronológica o una división manual que genere el uso de los datos más recientes como el conjunto de prueba.
Si los datos de prueba incluyen datos de poblaciones que no se representarán en la producción.
Por ejemplo, supongamos que estás entrenando un modelo con datos de compras de varias tiendas. Sin embargo, sabes que el modelo se usará principalmente con el fin de hacer predicciones para tiendas que no están en los datos de entrenamiento. Para asegurarte de que el modelo se pueda generalizar a las tiendas que no se ven, debes segregar tus conjuntos de datos por tiendas. En otras palabras, tu conjunto de prueba solo debe incluir tiendas distintas del conjunto de validación, y el conjunto de validación debe incluir solo tiendas diferentes del conjunto de entrenamiento.
Tus clases están desequilibradas.
Si tienes más de una clase que otra en tus datos de entrenamiento, es posible que debas incluir de forma manual más ejemplos de la clase minoritaria en tus datos de prueba. AutoML Tables no realiza muestras estratificadas, por lo que el conjunto de pruebas podría incluir muy pocos ejemplos de la clase minoritaria o incluso ninguno.
División aleatoria
La división aleatoria también se conoce como "división matemática" o "división de fracción".
Según la configuración predeterminada, los porcentajes de datos de entrenamiento usados para los conjuntos de entrenamiento, validación y prueba son 80, 10 y 10, respectivamente. Si usas la consola de Google Cloud, puedes cambiar los porcentajes a cualquier valor que sume hasta 100. Si usas la API de Vertex AI, debes usar fracciones que sumen hasta 1.0.
Para cambiar los porcentajes (fracciones), usa el objeto FractionSplit a fin de definir tus fracciones.
Las filas se seleccionan para una división de datos de forma aleatoria, pero determinista. Si no estás satisfecho con la composición de las divisiones de datos generadas, debes usar una división manual o cambiar los datos de entrenamiento. Entrenar un modelo nuevo con los mismos datos de entrenamiento da como resultado la misma división de datos.
División manual
La división manual también se conoce como "división predefinida".
Una columna de división de datos te permite seleccionar filas específicas para el entrenamiento, la validación y la prueba. Cuando creas tus datos de entrenamiento, agregas una columna que puede contener uno de los siguientes valores (con distinción entre mayúsculas y minúsculas):
TRAINVALIDATETESTUNASSIGNED
Los valores de esta columna deben ser una de las dos combinaciones siguientes:
- Todos los
TRAIN,VALIDATEyTEST - Solo
TESTyUNASSIGNED
Cada fila debe tener un valor para esta columna; no puede ser la string vacía.
El siguiente es un ejemplo con todos los conjuntos especificados:
"TRAIN","John","Doe","555-55-5555" "TEST","Jane","Doe","444-44-4444" "TRAIN","Roger","Rogers","123-45-6789" "VALIDATE","Sarah","Smith","333-33-3333"
Este es un ejemplo solo con el conjunto de prueba especificado:
"UNASSIGNED","John","Doe","555-55-5555" "TEST","Jane","Doe","444-44-4444" "UNASSIGNED","Roger","Rogers","123-45-6789" "UNASSIGNED","Sarah","Smith","333-33-3333"
La columna de división de datos puede tener cualquier nombre de columna válido. Su tipo de transformación puede ser categórica, de texto o automática.
Si el valor de la columna de división de datos es UNASSIGNED, Vertex AI asigna de manera automática esa fila al conjunto de entrenamiento o validación.
Designa una columna como columna de división de datos durante el entrenamiento de modelos.
División cronológica
La división cronológica también se conoce como "división de marca de tiempo".
Si tus datos dependen del tiempo, puedes designar una columna como una columna de tiempo. Vertex AI usa la columna de tiempo con el fin de dividir tus datos, con las filas más antiguas para el entrenamiento, las filas siguientes para la validación y las filas más recientes para la prueba.
Vertex AI trata cada fila como un ejemplo independiente e idénticamente distribuido; cuando se configura la columna de tiempo, esto no cambia. La columna de tiempo solo se usa para dividir el conjunto de datos.
Si especificas una columna de tiempo, debes incluir un valor para la columna de tiempo de cada fila en tu conjunto de datos. Asegúrate de que la columna de tiempo tenga suficientes valores distintos, de modo que los conjuntos de validación y prueba no estén vacíos. Por lo general, tener al menos 20 valores distintos debería ser suficiente.
Los datos en la columna de tiempo deben cumplir con uno de los formatos compatibles con la transformación de marca de tiempo. Sin embargo, la columna de tiempo puede tener cualquier transformación compatible, ya que la transformación solo afecta la forma en que se usa esa columna en el entrenamiento. Las transformaciones no afectan la división de datos.
También puedes especificar los porcentajes de los datos de entrenamiento que se asignan a cada conjunto.
Designa una columna como columna de tiempo durante el entrenamiento de modelos.
Divisiones de datos para previsiones
De forma predeterminada, Vertex AI usa un algoritmo de división cronológica para separar los datos de previsión en las tres divisiones de datos. Recomendamos usar la división predeterminada. Sin embargo, si deseas controlar qué filas de datos de entrenamiento se usan para cada división, usa una división manual.
Cómo se usan las divisiones de datos
Las divisiones de datos se usan en el proceso de entrenamiento de la siguiente manera:
Pruebas de modelos
El conjunto de entrenamiento se usa para entrenar modelos con diferentes combinaciones de opciones de procesamiento previo, de arquitectura y de hiperparámetro. Estos modelos se evalúan en el conjunto de validación para garantizar la calidad, lo que guía la exploración de combinaciones de opciones adicionales. El conjunto de validación también se usa para seleccionar el mejor punto de control de la evaluación periódica durante el entrenamiento. Los mejores parámetros y arquitecturas determinados en la fase de ajuste en paralelo se usan para entrenar dos modelos de ensamble como se describe a continuación.
Evaluación del modelo
Vertex AI entrena un modelo de evaluación mediante el uso de conjuntos de entrenamiento y validación como datos de entrenamiento. Vertex AI genera las métricas de la evaluación final del modelo en este modelo mediante el uso del conjunto de prueba. Esta es la primera vez en el proceso que se usa el conjunto de prueba. Este enfoque garantiza que las métricas finales de evaluación sean un reflejo imparcial de lo bien que funcionará el modelo final entrenado en la producción.
Modelo de entrega
Un modelo se entrena con el conjunto de entrenamiento y validación. Se valida (para seleccionar el mejor punto de control) a través del conjunto de prueba. El conjunto de prueba nunca se entrena en el sentido de que la pérdida se calcula a partir de este. Este modelo es el que usas para solicitar predicciones.
División predeterminada
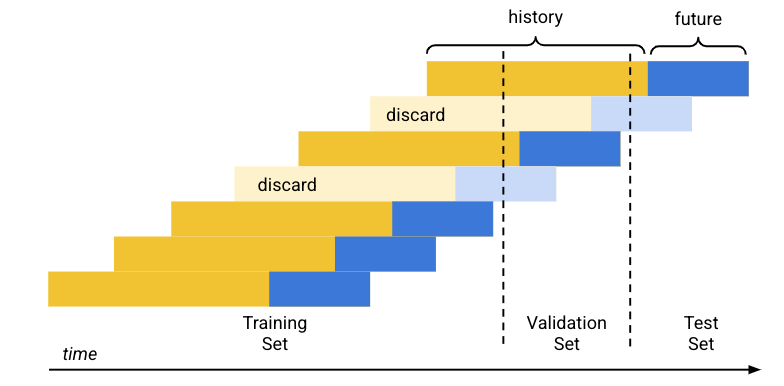
La división de datos predeterminada (cronológica) funciona de la siguiente manera:
- Los datos de entrenamiento se ordenan por fecha.
- Con los porcentajes de conjuntos predeterminados (80/10/10), el período abarcado por los datos de entrenamiento se separa en tres bloques, uno para cada conjunto de entrenamiento.
- Las filas vacías se agregan al comienzo de cada serie temporal para permitir que el modelo aprenda de las filas que no tienen suficiente historial (ventana de contexto). La cantidad de filas agregadas es el tamaño de la ventana de contexto establecida en el momento del entrenamiento.
Con el tamaño del horizonte de previsión como se establece en el momento del entrenamiento, cada fila cuyos datos futuros (horizonte previsto) se incluyen por completo en uno de los conjuntos de datos se usan para ese conjunto. (Las filas cuyo horizonte de previsión abarca dos conjuntos se descartan para evitar la filtración de datos).
División manual
Una columna de división de datos te permite seleccionar filas específicas para el entrenamiento, la validación y la prueba. Cuando creas tus datos de entrenamiento, agregas una columna que puede contener uno de los siguientes valores (con distinción entre mayúsculas y minúsculas):
TRAINVALIDATETEST
Cada fila debe tener un valor para esta columna; no puede ser la string vacía.
Por ejemplo:
"TRAIN","sku_id_1","2020-09-21","10" "TEST","sku_id_1","2020-09-22","23" "TRAIN","sku_id_2","2020-09-22","3" "VALIDATE","sku_id_2","2020-09-23","45"
La columna de división de datos puede tener cualquier nombre de columna válido. Su tipo de transformación puede ser categórica, de texto o automática.
Designa una columna como columna de división de datos durante el entrenamiento de modelos.
Asegúrate de evitar la filtración de datos entre tus series temporales.