Cette page explique comment diffuser des requêtes de prédiction avec le serveur d'inférence NVIDIA Triton à l'aide de Vertex AI Prediction. Le serveur d'inférence Triton de NVIDIA est une solution Open Source de NVIDIA pour le déploiement d'inférences qui est optimisée pour les CPU et les GPU et qui simplifie le déploiement des inférences.
NVIDIA Triton sur Vertex AI Prediction
Vertex AI Prediction est compatible avec le déploiement de modèles sur le serveur d'inférence Triton exécuté sur un conteneur personnalisé publié par NVIDIA GPU Cloud (NGC) – Image de serveur d'inférence NVIDIA Triton. Les images Triton de NVIDIA disposent de tous les packages et configurations requis qui répondent aux exigences de Vertex AI concernant les images de conteneurs de diffusion personnalisés. L'image contient le serveur d'inférence Triton compatible avec les modèles TensorFlow, PyTorch, TensorRT, ONNX et OpenVINO. L'image inclut également un backend FIL (Forest Inference Library) compatible avec l'exécution de frameworks de ML tels que XGBoost, LightGBM et Scikit-Learn.
Triton charge les modèles et expose les points de terminaison REST d'inférence, d'état et de gestion de modèles qui utilisent des protocoles d'inférence standards. Lors du déploiement d'un modèle sur Vertex AI, Triton reconnaît les environnements Vertex AI et adopte le protocole Vertex AI Prediction pour les vérifications de l'état et les requêtes de prédiction.
La liste suivante présente les principales fonctionnalités et les cas d'utilisation du serveur d'inférence NVIDIA Triton :
- Compatibilité avec plusieurs frameworks de deep learning et de machine learning : Triton accepte le déploiement de plusieurs modèles et une combinaison de frameworks et de formats de modèles : TensorFlow (SavedModel et GraphDef), PyTorch (TorchScript), TensorRT, ONNX, OpenVINO et les backends FIL pour accepter des frameworks tels que XGBoost, LightGBM, Scikit-Learn et les formats de modèle Python ou C++ personnalisés.
- Exécution simultanée de plusieurs modèles : Triton permet à plusieurs modèles et/ou à plusieurs instances du même modèle de s'exécuter simultanément sur la même ressource de calcul avec zéro ou plusieurs GPU.
- Assemblage de modèles (via chaînage ou pipeline) : l'ensemble Triton accepte les cas d'utilisation où plusieurs modèles sont composés en tant que pipeline (ou DAG, graphe orienté acyclique) avec des Tensors d'entrée et de sortie connectés entre eux. Avec un backend Python Triton, vous pouvez également inclure toute logique de prétraitement, de post-traitement ou de flux de contrôle définie par le script BLS (Business Logic Scripting).
- Exécution sur les backends de processeur et de GPU : Triton accepte l'inférence pour les modèles déployés sur des nœuds dotés de processeurs et de GPU.
- Traitement par lots dynamique des requêtes de prédiction : pour les modèles compatibles avec le traitement par lot, Triton dispose d'algorithmes de planification et de traitement par lot intégrés. Ces algorithmes combinent de manière dynamique des requêtes d'inférence individuelles en lots côté serveur afin d'améliorer le débit d'inférence et d'augmenter l'utilisation des GPU.
Pour en savoir plus sur le serveur d'inférence NVIDIA Triton, consultez la documentation sur Triton.
Images de conteneurs NVIDIA Triton disponibles
Le tableau suivant présente les images Docker Triton disponibles dans le catalogue NGC NVIDIA. Choisissez une image en fonction du framework de modèle, du backend et de la taille de l'image de conteneur que vous utilisez.
xx et yy font respectivement référence aux versions majeures et mineures de Triton.
| Image NVIDIA Triton | Services d'assistance |
|---|---|
xx.yy-py3 |
Conteneur complet compatible avec les modèles TensorFlow, PyTorch, TensorRT, ONNX et OpenVINO |
xx.yy-pyt-python-py3 |
Backends PyTorch et Python uniquement |
xx.yy-tf2-python-py3 |
Backends TensorFlow 2.x et Python uniquement |
xx.yy-py3-min |
Personnaliser le conteneur Triton selon les besoins |
Premiers pas : Livrer des prédictions avec NVIDIA Triton
La figure suivante montre l'architecture de haut niveau de Triton sur Vertex AI Prediction :
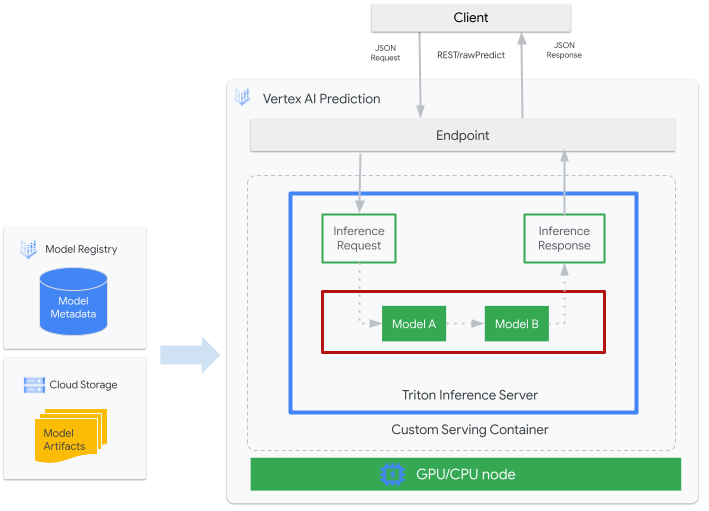
- Un modèle de ML à diffuser par Triton est enregistré auprès de Vertex AI Model Registry. Les métadonnées du modèle font référence à un emplacement d'artefacts de modèle dans Cloud Storage, au conteneur de diffusion personnalisé et à sa configuration.
- Le modèle de Vertex AI Model Registry est déployé sur un point de terminaison Vertex AI Prediction qui exécute un serveur d'inférence Triton en tant que conteneur personnalisé sur les nœuds de calcul disposant de processeurs et de GPU.
- Les requêtes d'inférence arrivent au serveur d'inférence Triton via un point de terminaison Vertex AI Prediction et sont acheminées vers le programmeur approprié.
- Le backend effectue une inférence à l'aide des entrées fournies dans les requêtes par lot et renvoie une réponse.
- Triton fournit des points de terminaison d'état de préparation et d'intégrité d'activité qui permettent l'intégration de Triton à des environnements de déploiement tels que Vertex AI Prediction.
Ce tutoriel explique comment utiliser un conteneur personnalisé exécutant le serveur d'inférence NVIDIA Triton pour déployer un modèle de machine learning (ML) sur Vertex AI Prediction, qui diffuse des prédictions en ligne. Vous déployez un conteneur qui exécute Triton pour diffuser des prédictions à partir d'un modèle de détection d'objets issu de TensorFlow Hub pré-entraîné sur le fichier Ensemble de données COCO 2017 Vous pouvez ensuite utiliser Vertex AI Prediction pour détecter les objets d'une image.
Vous pouvez également exécuter le tutoriel sur Vertex AI Workbench en suivant ce notebook Jupyter.
Avant de commencer
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API and Artifact Registry API APIs.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API and Artifact Registry API APIs.
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Tout au long de ce tutoriel, nous vous recommandons d'utiliser Cloud Shell pour interagir avec Google Cloud. Si vous souhaitez utiliser un autre shell Bash au lieu de Cloud Shell, exécutez la configuration supplémentaire suivante :
-
Install the Google Cloud CLI.
-
If you're using an external identity provider (IdP), you must first sign in to the gcloud CLI with your federated identity.
-
To initialize the gcloud CLI, run the following command:
gcloud init - Consultez la documentation de Artifact Registry pour installer Docker.
Créer et transférer l'image de conteneur
Pour utiliser un conteneur personnalisé, vous devez spécifier une image de conteneur Docker répondant aux exigences de conteneur personnalisé. Cette section explique comment créer l'image de conteneur et la transférer dans Artifact Registry.
Télécharger des artefacts de modèle
Les artefacts de modèle sont des fichiers créés par l'entraînement de ML que vous pouvez utiliser pour diffuser des prédictions. Ils contiennent, au minimum, la structure et les pondérations de votre modèle de ML entraîné. Le format des artefacts de modèle dépend du framework de ML que vous utilisez pour l'entraînement.
Pour ce tutoriel, au lieu d'entraîner un modèle à partir de zéro, téléchargez le modèle de détection d'objets à partir de TensorFlow Hub, entraîné sur l'ensemble de données COCO 2017.
Triton s'attend à ce que le dépôt de modèle soit organisé selon la structure suivante pour diffuser le format TensorFlow SavedModel :
└── model-repository-path
└── model_name
├── config.pbtxt
└── 1
└── model.savedmodel
└── <saved-model-files>
Le fichier config.pbtxt décrit la configuration du modèle. Par défaut, le fichier de configuration du modèle contenant les paramètres requis doit être fourni. Toutefois, si Triton est démarré avec l'option --strict-model-config=false, dans certains cas, la configuration du modèle peut être générée automatiquement par Triton et n'a pas besoin d'être fournie explicitement.
Plus précisément, les modèles TensorRT, TensorFlow SavedModel et ONNX ne nécessitent pas de fichier de configuration de modèle, car Triton peut déduire automatiquement tous les paramètres requis. Tous les autres types de modèles doivent fournir un fichier de configuration de modèle.
# Download and organize model artifacts according to the Triton model repository spec
mkdir -p models/object_detector/1/model.savedmodel/
curl -L "https://tfhub.dev/tensorflow/faster_rcnn/resnet101_v1_640x640/1?tf-hub-format=compressed" | \
tar -zxvC ./models/object_detector/1/model.savedmodel/
ls -ltr ./models/object_detector/1/model.savedmodel/
Après avoir téléchargé le modèle localement, le dépôt du modèle sera organisé comme suit :
./models
└── object_detector
└── 1
└── model.savedmodel
├── saved_model.pb
└── variables
├── variables.data-00000-of-00001
└── variables.index
Copier des artefacts de modèle dans un bucket Cloud Storage
Les artefacts de modèle téléchargés, y compris le fichier de configuration de modèle, sont transférés vers un bucket Cloud Storage spécifié par MODEL_ARTIFACTS_REPOSITORY, qui peut être utilisé lors de la création de la ressource de modèle Vertex AI.
gcloud storage cp ./models/object_detector MODEL_ARTIFACTS_REPOSITORY/ --recursive
Créer un dépôt Artifact Registry
Créez un dépôt Artifact Registry pour stocker l'image de conteneur que vous allez créer dans la section suivante.
Activez le service de l'API Artifact Registry pour votre projet.
gcloud services enable artifactregistry.googleapis.com
Exécutez la commande suivante dans votre shell pour créer le dépôt Artifact Registry :
gcloud artifacts repositories create getting-started-nvidia-triton \
--repository-format=docker \
--location=LOCATION_ID \
--description="NVIDIA Triton Docker repository"
Remplacez LOCATION_ID par la région où Artifact Registry stocke votre image de conteneur. Vous devez ensuite créer une ressource de modèle Vertex AI sur un point de terminaison régional correspondant à cette région. Par conséquent, choisissez une région dans laquelle Vertex AI dispose d'un point de terminaison régional. Par exemple, us-central1.
Une fois l'opération terminée, la commande affiche le résultat suivant :
Created repository [getting-started-nvidia-triton].
Créer l'image de conteneur
NVIDIA fournit des images Docker permettant de créer une image de conteneur qui exécute Triton et respecte les exigences concernant l'utilisation de conteneurs personnalisés de Vertex AI pour la diffusion. Vous pouvez extraire l'image à l'aide de docker et ajouter un tag au chemin d'accès Artifact Registry vers lequel l'image sera transférée.
NGC_TRITON_IMAGE_URI="nvcr.io/nvidia/tritonserver:22.01-py3"
docker pull $NGC_TRITON_IMAGE_URI
docker tag $NGC_TRITON_IMAGE_URI LOCATION_ID-docker.pkg.dev/PROJECT_ID/getting-started-nvidia-triton/vertex-triton-inference
Remplacez les éléments suivants :
- LOCATION_ID : région de votre dépôt Artifact Registry, comme indiqué dans une section précédente
- PROJECT_ID : ID de votre projet Google Cloud.
La commande peut s'exécuter pendant plusieurs minutes.
Préparer le fichier de charge utile pour tester les requêtes de prédiction
Pour envoyer une requête de prédiction au serveur du conteneur, préparez la charge utile avec un exemple de fichier image qui utilise Python. Exécutez le script Python suivant pour générer le fichier de charge utile :
import json
import requests
# install required packages before running
# pip install pillow numpy --upgrade
from PIL import Image
import numpy as np
# method to generate payload from image url
def generate_payload(image_url):
# download image from url and resize
image_inputs = Image.open(requests.get(image_url, stream=True).raw)
image_inputs = image_inputs.resize((200, 200))
# convert image to numpy array
image_tensor = np.asarray(image_inputs)
# derive image shape
image_shape = [1] + list(image_tensor.shape)
# create payload request
payload = {
"id": "0",
"inputs": [
{
"name": "input_tensor",
"shape": image_shape,
"datatype": "UINT8",
"parameters": {},
"data": image_tensor.tolist(),
}
],
}
# save payload as json file
payload_file = "instances.json"
with open(payload_file, "w") as f:
json.dump(payload, f)
print(f"Payload generated at {payload_file}")
return payload_file
if __name__ == '__main__':
image_url = "https://github.com/tensorflow/models/raw/master/research/object_detection/test_images/image2.jpg"
payload_file = generate_payload(image_url)
Le script Python génère la charge utile et affiche la réponse suivante :
Payload generated at instances.json
Exécuter le conteneur localement (facultatif)
Avant de transférer votre image de conteneur vers Artifact Registry afin de l'utiliser avec Vertex AI Prediction, vous pouvez l'exécuter en tant que conteneur dans votre environnement local pour vérifier que le serveur fonctionne comme prévu :
Pour exécuter l'image de conteneur localement, exécutez la commande suivante dans votre shell :
docker run -t -d -p 8000:8000 --rm \ --name=local_object_detector \ -e AIP_MODE=True \ LOCATION_ID-docker.pkg.dev/PROJECT_ID/getting-started-nvidia-triton/vertex-triton-inference \ --model-repository MODEL_ARTIFACTS_REPOSITORY \ --strict-model-config=falseRemplacez les éléments suivants, comme vous l'avez fait dans la section précédente :
- LOCATION_ID : région de votre dépôt Artifact Registry, comme indiqué dans une section précédente
- PROJECT_ID : ID de votre projet Google Cloud
- MODEL_ARTIFACTS_REPOSITORY : chemin d'accès Cloud Storage où se trouvent les artefacts de modèle
Cette commande exécute un conteneur en mode dissocié, en mappant le port
8000du conteneur avec le port8000de l'environnement local. L'image Triton de NGC configure Triton de sorte qu'il utilise le port8000.Pour envoyer une vérification d'état au serveur du conteneur, exécutez la commande suivante dans votre shell :
curl -s -o /dev/null -w "%{http_code}" http://localhost:8000/v2/health/readySi l'opération aboutit, le serveur renvoie le code d'état
200.Exécutez la commande suivante pour envoyer une requête de prédiction au serveur du conteneur à l'aide de la charge utile générée précédemment et obtenir des réponses de prédiction :
curl -X POST \ -H "Content-Type: application/json" \ -d @instances.json \ localhost:8000/v2/models/object_detector/infer | jq -c '.outputs[] | select(.name == "detection_classes")'Cette requête utilise l'une des images de test incluses dans l'exemple de détection d'objets TensorFlow.
Si l'opération réussit, le serveur affiche la prédiction suivante :
{"name":"detection_classes","datatype":"FP32","shape":[1,300],"data":[38,1,...,44]}Pour arrêter le conteneur, exécutez la commande suivante dans votre interface système :
docker stop local_object_detector
{kind=link}
Transférer l'image de conteneur vers Artifact Registry
Configurer Docker pour accéder à Artifact Registry Transférez ensuite votre image de conteneur vers votre dépôt Artifact Registry.
Pour autoriser votre installation Docker locale à transférer vers Artifact Registry dans la région choisie, exécutez la commande suivante dans votre interface système :
gcloud auth configure-docker LOCATION_ID-docker.pkg.dev- Remplacez LOCATION_ID par la région dans laquelle vous avez créé votre dépôt dans une section précédente.
Pour transférer l'image de conteneur que vous venez de créer vers Artifact Registry, exécutez la commande suivante dans votre shell :
docker push LOCATION_ID-docker.pkg.dev/PROJECT_ID/getting-started-nvidia-triton/vertex-triton-inferenceRemplacez les éléments suivants, comme vous l'avez fait dans la section précédente :
- LOCATION_ID : région de votre dépôt Artifact Registry, comme indiqué dans une section précédente
- PROJECT_ID : ID de votre projet Google Cloud.
Déployer le modèle
Créer un modèle
Pour créer une ressource Model utilisant un conteneur personnalisé exécutant Triton, exécutez la commande gcloud ai models upload suivante :
gcloud ai models upload \
--region=LOCATION_ID \
--display-name=DEPLOYED_MODEL_NAME \
--container-image-uri=LOCATION_ID-docker.pkg.dev/PROJECT_ID/getting-started-nvidia-triton/vertex-triton-inference \
--artifact-uri=MODEL_ARTIFACTS_REPOSITORY \
--container-args='--strict-model-config=false'
- LOCATION_ID : région dans laquelle vous utilisez Vertex AI.
- PROJECT_ID : ID de votre projet Google Cloud
-
DEPLOYED_MODEL_NAME : nom de l'élément
DeployedModel. Vous pouvez également utiliser le nom à afficher duModelpour leDeployedModel.
L'argument --container-args='--strict-model-config=false' permet à Triton de générer automatiquement la configuration du modèle.
Créer un point de terminaison
Vous devez déployer le modèle sur un point de terminaison avant de pouvoir l'utiliser pour diffuser des prédictions en ligne. Si vous déployez un modèle sur un point de terminaison existant, vous pouvez ignorer cette étape. L'exemple suivant utilise la commande gcloud ai endpoints create :
gcloud ai endpoints create \
--region=LOCATION_ID \
--display-name=ENDPOINT_NAME
Remplacez les éléments suivants :
- LOCATION_ID : région dans laquelle vous utilisez l'IA Vertex.
- ENDPOINT_NAME : nom du point de terminaison à afficher.
La création du point de terminaison par l'outil Google Cloud CLI peut prendre quelques secondes.
Déployer le modèle sur le point de terminaison
Une fois le point de terminaison prêt, déployez le modèle sur ce point de terminaison. Lorsque vous déployez un modèle sur un point de terminaison, le service associe des ressources physiques au modèle exécutant Triton pour livrer des prédictions en ligne.
L'exemple suivant utilise la commande gcloud ai endpoints deploy-model pour déployer les Model sur un endpoint exécutant Triton sur des GPU pour accélérer la diffusion des prédictions et sans fractionner le trafic entre plusieurs ressources DeployedModel :
ENDPOINT_ID=$(gcloud ai endpoints list \ --region=LOCATION_ID\ --filter=display_name=ENDPOINT_NAME\ --format="value(name)") MODEL_ID=$(gcloud ai models list \ --region=LOCATION_ID\ --filter=display_name=DEPLOYED_MODEL_NAME\ --format="value(name)") gcloud ai endpoints deploy-model $ENDPOINT_ID \ --region=LOCATION_ID\ --model=$MODEL_ID \ --display-name=DEPLOYED_MODEL_NAME\ --machine-type=MACHINE_TYPE\ --min-replica-count=MIN_REPLICA_COUNT\ --max-replica-count=MAX_REPLICA_COUNT\ --accelerator=count=ACCELERATOR_COUNT,type=ACCELERATOR_TYPE\ --traffic-split=0=100
Remplacez les éléments suivants :
- LOCATION_ID : région dans laquelle vous utilisez l'IA Vertex.
- ENDPOINT_NAME : nom à afficher du point de terminaison.
-
DEPLOYED_MODEL_NAME : nom de l'élément
DeployedModel. Vous pouvez également utiliser le nom à afficher duModelpour leDeployedModel. -
MACHINE_TYPE : facultatif. Ressources machine utilisées pour chaque nœud de ce déploiement. Le paramètre par défaut est
n1-standard-2. En savoir plus sur les types de machines. - MIN_REPLICA_COUNT : nombre minimal de nœuds pour ce déploiement. Le nombre de nœuds peut être augmenté ou réduit selon les besoins de la charge de prédiction, dans la limite du nombre maximal de nœuds et jamais moins que ce nombre de nœuds.
- MAX_REPLICA_COUNT : nombre maximal de nœuds pour ce déploiement. Le nombre de nœuds peut être augmenté ou réduit selon les besoins de la charge de prédiction, dans la limite de ce nombre de nœuds et jamais moins que le nombre minimal de nœuds.
ACCELERATOR_COUNT : nombre d'accélérateurs à associer à chaque machine exécutant la tâche. Cette valeur est généralement définie sur 1. Si aucune valeur n'est spécifiée, la valeur par défaut est 1.
ACCELERATOR_TYPE : gère la configuration de l'accélérateur pour la diffusion de GPU. Lors du déploiement d'un modèle avec des types de machines Compute Engine, un accélérateur GPU peut également être sélectionné, et le type doit être spécifié. Les options sont
nvidia-tesla-a100,nvidia-tesla-p100,nvidia-tesla-p4,nvidia-tesla-t4etnvidia-tesla-v100.
Google Cloud CLI peut prendre quelques secondes pour déployer le modèle sur le point de terminaison. Une fois le modèle déployé, cette commande affiche le résultat suivant :
Deployed a model to the endpoint xxxxx. Id of the deployed model: xxxxx.
Obtenir des prédictions en ligne à partir du modèle déployé
Pour appeler le modèle via le point de terminaison Vertex AI Prediction, formatez la requête de prédiction à l'aide d'une commande Objet JSON de requête d'inférence standard
ou Objet JSON de requête d'inférence avec une extension binaire
et envoyez une requête au point de terminaison rawPredict REST Vertex AI Prediction.
L'exemple suivant utilise la commande gcloud ai endpoints raw-predict :
ENDPOINT_ID=$(gcloud ai endpoints list \
--region=LOCATION_ID \
--filter=display_name=ENDPOINT_NAME \
--format="value(name)")
gcloud ai endpoints raw-predict $ENDPOINT_ID \
--region=LOCATION_ID \
--http-headers=Content-Type=application/json \
--request=@instances.json
Remplacez l'élément suivant :
- LOCATION_ID : région dans laquelle vous utilisez l'IA Vertex.
- ENDPOINT_NAME : nom à afficher du point de terminaison.
Le point de terminaison renvoie la réponse suivante pour une requête valide :
{
"id": "0",
"model_name": "object_detector",
"model_version": "1",
"outputs": [{
"name": "detection_anchor_indices",
"datatype": "FP32",
"shape": [1, 300],
"data": [2.0, 1.0, 0.0, 3.0, 26.0, 11.0, 6.0, 92.0, 76.0, 17.0, 58.0, ...]
}]
}
Effectuer un nettoyage
Pour éviter que des frais liés à Vertex AI et des frais liés à Artifact Registry supplémentaires vous soient facturés, supprimez les ressources Google Cloud que vous avez créées au cours de ce tutoriel :
Pour annuler le déploiement du modèle sur le point de terminaison et supprimer le point de terminaison, exécutez la commande suivante dans votre shell :
ENDPOINT_ID=$(gcloud ai endpoints list \ --region=LOCATION_ID \ --filter=display_name=ENDPOINT_NAME \ --format="value(name)") DEPLOYED_MODEL_ID=$(gcloud ai endpoints describe $ENDPOINT_ID \ --region=LOCATION_ID \ --format="value(deployedModels.id)") gcloud ai endpoints undeploy-model $ENDPOINT_ID \ --region=LOCATION_ID \ --deployed-model-id=$DEPLOYED_MODEL_ID gcloud ai endpoints delete $ENDPOINT_ID \ --region=LOCATION_ID \ --quietRemplacez LOCATION_ID par la région dans laquelle vous avez créé votre modèle dans une section précédente.
Pour supprimer votre modèle, exécutez la commande suivante dans votre interface système :
MODEL_ID=$(gcloud ai models list \ --region=LOCATION_ID \ --filter=display_name=DEPLOYED_MODEL_NAME \ --format="value(name)") gcloud ai models delete $MODEL_ID \ --region=LOCATION_ID \ --quietRemplacez LOCATION_ID par la région dans laquelle vous avez créé votre modèle dans une section précédente.
Pour supprimer le dépôt Artifact Registry et l'image de conteneur, exécutez la commande suivante dans votre interface système :
gcloud artifacts repositories delete getting-started-nvidia-triton \ --location=LOCATION_ID \ --quietRemplacez LOCATION_ID par la région dans laquelle vous avez créé votre dépôt Artifact Registry dans une section précédente.
Limites
- Le conteneur personnalisé Triton n'est pas compatible avec Vertex Explainable AI ni Vertex AI Model Monitoring.
Étape suivante
- Consultez les tutoriels sur les notebooks Jupyter sur Vertex AI pour obtenir des modèles de déploiement avec le serveur d'inférence NVIDIA Triton sur Vertex AI Prediction.