Ce document décrit les étapes requises pour créer un pipeline qui entraîne automatiquement un modèle personnalisé de manière périodique ou lorsque de nouvelles données sont insérées dans l'ensemble de données à l'aide de Vertex AI Pipelines et Cloud Functions.
Objectifs
Ce processus se compose des étapes suivantes :
Acquérir et préparer un ensemble de données dans BigQuery.
Créer et importer un package d'entraînement personnalisé. Lors de son exécution, le pipeline va lire les données de l'ensemble de données et entraîner le modèle.
Créer un pipeline Vertex AI : Ce pipeline exécute le package d'entraînement personnalisé, importe le modèle dans Vertex AI Model Registry, exécute le job d'évaluation et envoie une notification par e-mail.
Exécuter manuellement le pipeline.
Créer une fonction Cloud avec un déclencheur Eventarc qui exécute le pipeline chaque fois que de nouvelles données sont insérées dans l'ensemble de données BigQuery.
Avant de commencer
Configurez votre projet et votre notebook.
Configuration du projet
-
In the Google Cloud console, go to the project selector page.
-
Select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
Créer un notebook
Nous allons utiliser un notebook Colab Enterprise pour exécuter une partie du code de ce tutoriel.
Si vous n'êtes pas le propriétaire du projet, demandez à un propriétaire de projet de vous accorder les rôles IAM
roles/resourcemanager.projectIamAdminetroles/aiplatform.colabEnterpriseUser.Vous devez disposer de ces rôles pour utiliser Colab Enterprise, et pour vous accorder à vous-même, ainsi qu'aux comptes de service, des rôles et des autorisations IAM.
Dans la console Google Cloud, accédez à la page "Notebooks Colab Enterprise".
Colab Enterprise vous demande d'activer les API requises suivantes, si ce n'est pas déjà fait.
- API Vertex AI
- API Dataform
- API Compute Engine
Dans le menu Région, sélectionnez la région dans laquelle vous souhaitez créer votre notebook. En cas de doute, utilisez la région us-central1.
Utilisez la même région pour toutes les ressources de ce tutoriel.
Cliquez sur Créer un notebook.
Votre nouveau notebook s'affiche dans l'onglet Mes notebooks. Pour exécuter du code dans votre notebook, ajoutez une cellule de code, puis cliquez sur le bouton Exécuter la cellule.
Configurer l'environnement de développement
Dans votre notebook, installez les packages Python 3 suivants.
! pip3 install google-cloud-aiplatform==1.34.0 \ google-cloud-pipeline-components==2.6.0 \ kfp==2.4.0 \ scikit-learn==1.0.2 \ mlflow==2.10.0Définissez le projet dans la Google Cloud CLI en exécutant la commande suivante :
PROJECT_ID = "PROJECT_ID" # Set the project id ! gcloud config set project {PROJECT_ID}Remplacez PROJECT_ID par l'ID du projet. Si nécessaire, vous pouvez retrouver celui-ci via la console Google Cloud.
Attribuez des rôles à votre compte Google, comme ci-après :
! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/bigquery.admin ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/aiplatform.user ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/storage.admin ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/pubsub.editor ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/cloudfunctions.admin ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/logging.viewer ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/logging.configWriter ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/iam.serviceAccountUser ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/eventarc.admin ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/aiplatform.colabEnterpriseUser ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/artifactregistry.admin ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/serviceusage.serviceUsageAdminActivez les API suivantes :
- API Artifact Registry
- API BigQuery
- API Cloud Build
- API Cloud Functions
- API Cloud Logging
- API Pub/Sub
- API Cloud Run Admin
- API Cloud Storage
- API Eventarc
- API Service Usage
- API Vertex AI
! gcloud services enable artifactregistry.googleapis.com bigquery.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com logging.googleapis.com pubsub.googleapis.com run.googleapis.com storage-component.googleapis.com eventarc.googleapis.com serviceusage.googleapis.com aiplatform.googleapis.comAttribuez des rôles aux comptes de service de votre projet :
Affichez les noms de vos comptes de service :
! gcloud iam service-accounts listNotez le nom de votre agent de service Compute. Il doit être au format
xxxxxxxx-compute@developer.gserviceaccount.com.Attribuez les rôles requis à l'agent de service.
! gcloud projects add-iam-policy-binding PROJECT_ID --member="serviceAccount:"SA_ID-compute@developer.gserviceaccount.com"" --role=roles/aiplatform.serviceAgent ! gcloud projects add-iam-policy-binding PROJECT_ID --member="serviceAccount:"SA_ID-compute@developer.gserviceaccount.com"" --role=roles/eventarc.eventReceiver
Acquérir et préparer l'ensemble de données
Dans ce tutoriel, vous allez créer un modèle capable de prédire le prix d'une course en taxi en fonction de caractéristiques telles que la durée de la course, le lieu desservi et la distance. Nous utiliserons les données de l'ensemble de données public Chicago Taxi Trips. Cet ensemble de données inclut les trajets en taxi de 2013 à nos jours, déclarés auprès de la ville de Chicago en sa qualité d'organisme de réglementation. Pour protéger simultanément la confidentialité des conducteurs et des utilisateurs du taxi, et permettre à l'agrégateur d'analyser les données, l'identifiant de taxi reste identique pour un numéro de licence donné, sans pour autant afficher ce numéro. En outre, les secteurs de recensement sont supprimés dans certains cas, et les temps sont arrondis au quart d'heure le plus proche.
Pour en savoir plus, consultez la page Chicago Taxi Trips sur Marketplace.
Créer un ensemble de données BigQuery
Dans la console Google Cloud, accédez à BigQuery Studio.
Dans le panneau Explorer, identifiez votre projet, cliquez sur Actions, puis sur Explorer.
Sur la page Créer l'ensemble de données :
Dans le champ ID de l'ensemble de données, saisissez
mlops. Pour en savoir plus, consultez la section Nommage des ensembles de données.Dans le champ Type d'emplacement, sélectionnez votre emplacement multirégional. Par exemple, sélectionnez US (plusieurs régions aux États-Unis) si vous utilisez
us-central1. Une fois l'ensemble de données créé, l'emplacement ne peut plus être modifié.Cliquez sur Créer un ensemble de données.
Pour en savoir plus, consultez la section Créer des ensembles de données.
Créer et remplir une table BigQuery
Dans cette section, vous allez créer la table et importer dans l'ensemble de données de votre projet les données cumulées sur un an, issues de l'ensemble de données public.
Accédez à BigQuery Studio.
Cliquez sur Créer une requête SQL, puis exécutez la requête SQL suivante en cliquant sur Exécuter.
CREATE OR REPLACE TABLE `PROJECT_ID.mlops.chicago` AS ( WITH taxitrips AS ( SELECT trip_start_timestamp, trip_end_timestamp, trip_seconds, trip_miles, payment_type, pickup_longitude, pickup_latitude, dropoff_longitude, dropoff_latitude, tips, tolls, fare, pickup_community_area, dropoff_community_area, company, unique_key FROM `bigquery-public-data.chicago_taxi_trips.taxi_trips` WHERE pickup_longitude IS NOT NULL AND pickup_latitude IS NOT NULL AND dropoff_longitude IS NOT NULL AND dropoff_latitude IS NOT NULL AND trip_miles > 0 AND trip_seconds > 0 AND fare > 0 AND EXTRACT(YEAR FROM trip_start_timestamp) = 2019 ) SELECT trip_start_timestamp, EXTRACT(MONTH from trip_start_timestamp) as trip_month, EXTRACT(DAY from trip_start_timestamp) as trip_day, EXTRACT(DAYOFWEEK from trip_start_timestamp) as trip_day_of_week, EXTRACT(HOUR from trip_start_timestamp) as trip_hour, trip_seconds, trip_miles, payment_type, ST_AsText( ST_SnapToGrid(ST_GeogPoint(pickup_longitude, pickup_latitude), 0.1) ) AS pickup_grid, ST_AsText( ST_SnapToGrid(ST_GeogPoint(dropoff_longitude, dropoff_latitude), 0.1) ) AS dropoff_grid, ST_Distance( ST_GeogPoint(pickup_longitude, pickup_latitude), ST_GeogPoint(dropoff_longitude, dropoff_latitude) ) AS euclidean, CONCAT( ST_AsText(ST_SnapToGrid(ST_GeogPoint(pickup_longitude, pickup_latitude), 0.1)), ST_AsText(ST_SnapToGrid(ST_GeogPoint(dropoff_longitude, dropoff_latitude), 0.1)) ) AS loc_cross, IF((tips/fare >= 0.2), 1, 0) AS tip_bin, tips, tolls, fare, pickup_longitude, pickup_latitude, dropoff_longitude, dropoff_latitude, pickup_community_area, dropoff_community_area, company, unique_key, trip_end_timestamp FROM taxitrips LIMIT 1000000 )Cette requête crée la table
<PROJECT_ID>.mlops.chicagoet la remplit avec les données de la table publiquebigquery-public-data.chicago_taxi_trips.taxi_trips.Pour afficher le schéma de la table, cliquez sur Accéder à la table, puis sur l'onglet Schéma.
Pour afficher le contenu de la table, cliquez sur l'onglet Aperçu.
Créer et importer un package d'entraînement personnalisé
Dans cette section, vous allez créer un package Python contenant le code qui lit l'ensemble de données, divise les données en ensembles d'entraînement et de test, et entraîne votre modèle personnalisé. L'exécution de votre package va correspondre à l'une des tâches de votre pipeline. Pour plus d'informations, consultez la page Créer une application d'entraînement Python pour un conteneur prédéfini.
Créer le package d'entraînement personnalisé
Dans votre notebook Colab, créez des dossiers parents pour l'application d'entraînement :
!mkdir -p training_package/trainerCréez un fichier
__init__.pydans chaque dossier pour en faire un package à l'aide de la commande suivante :! touch training_package/__init__.py ! touch training_package/trainer/__init__.pyVous pouvez voir les nouveaux fichiers et dossiers dans le panneau Fichiers correspondant au dossier.
Dans le panneau Fichiers, créez un fichier nommé
task.pydans le dossier training_package/trainer, contenant le code suivant.# Import the libraries from sklearn.model_selection import train_test_split, cross_val_score from sklearn.preprocessing import OneHotEncoder, StandardScaler from google.cloud import bigquery, bigquery_storage from sklearn.ensemble import RandomForestRegressor from sklearn.compose import ColumnTransformer from sklearn.pipeline import Pipeline from google import auth from scipy import stats import numpy as np import argparse import joblib import pickle import csv import os # add parser arguments parser = argparse.ArgumentParser() parser.add_argument('--project-id', dest='project_id', type=str, help='Project ID.') parser.add_argument('--training-dir', dest='training_dir', default=os.getenv("AIP_MODEL_DIR"), type=str, help='Dir to save the data and the trained model.') parser.add_argument('--bq-source', dest='bq_source', type=str, help='BigQuery data source for training data.') args = parser.parse_args() # data preparation code BQ_QUERY = """ with tmp_table as ( SELECT trip_seconds, trip_miles, fare, tolls, company, pickup_latitude, pickup_longitude, dropoff_latitude, dropoff_longitude, DATETIME(trip_start_timestamp, 'America/Chicago') trip_start_timestamp, DATETIME(trip_end_timestamp, 'America/Chicago') trip_end_timestamp, CASE WHEN (pickup_community_area IN (56, 64, 76)) OR (dropoff_community_area IN (56, 64, 76)) THEN 1 else 0 END is_airport, FROM `{}` WHERE dropoff_latitude IS NOT NULL and dropoff_longitude IS NOT NULL and pickup_latitude IS NOT NULL and pickup_longitude IS NOT NULL and fare > 0 and trip_miles > 0 and MOD(ABS(FARM_FINGERPRINT(unique_key)), 100) between 0 and 99 ORDER BY RAND() LIMIT 10000) SELECT *, EXTRACT(YEAR FROM trip_start_timestamp) trip_start_year, EXTRACT(MONTH FROM trip_start_timestamp) trip_start_month, EXTRACT(DAY FROM trip_start_timestamp) trip_start_day, EXTRACT(HOUR FROM trip_start_timestamp) trip_start_hour, FORMAT_DATE('%a', DATE(trip_start_timestamp)) trip_start_day_of_week FROM tmp_table """.format(args.bq_source) # Get default credentials credentials, project = auth.default() bqclient = bigquery.Client(credentials=credentials, project=args.project_id) bqstorageclient = bigquery_storage.BigQueryReadClient(credentials=credentials) df = ( bqclient.query(BQ_QUERY) .result() .to_dataframe(bqstorage_client=bqstorageclient) ) # Add 'N/A' for missing 'Company' df.fillna(value={'company':'N/A','tolls':0}, inplace=True) # Drop rows containing null data. df.dropna(how='any', axis='rows', inplace=True) # Pickup and dropoff locations distance df['abs_distance'] = (np.hypot(df['dropoff_latitude']-df['pickup_latitude'], df['dropoff_longitude']-df['pickup_longitude']))*100 # Remove extremes, outliers possible_outliers_cols = ['trip_seconds', 'trip_miles', 'fare', 'abs_distance'] df=df[(np.abs(stats.zscore(df[possible_outliers_cols].astype(float))) < 3).all(axis=1)].copy() # Reduce location accuracy df=df.round({'pickup_latitude': 3, 'pickup_longitude': 3, 'dropoff_latitude':3, 'dropoff_longitude':3}) # Drop the timestamp col X=df.drop(['trip_start_timestamp', 'trip_end_timestamp'],axis=1) # Split the data into train and test X_train, X_test = train_test_split(X, test_size=0.10, random_state=123) ## Format the data for batch predictions # select string cols string_cols = X_test.select_dtypes(include='object').columns # Add quotes around string fields X_test[string_cols] = X_test[string_cols].apply(lambda x: '\"' + x + '\"') # Add quotes around column names X_test.columns = ['\"' + col + '\"' for col in X_test.columns] # Save DataFrame to csv X_test.to_csv(os.path.join(args.training_dir,"test.csv"),index=False,quoting=csv.QUOTE_NONE, escapechar=' ') # Save test data without the target for batch predictions X_test.drop('\"fare\"',axis=1,inplace=True) X_test.to_csv(os.path.join(args.training_dir,"test_no_target.csv"),index=False,quoting=csv.QUOTE_NONE, escapechar=' ') # Separate the target column y_train=X_train.pop('fare') # Get the column indexes col_index_dict = {col: idx for idx, col in enumerate(X_train.columns)} # Create a column transformer pipeline ct_pipe = ColumnTransformer(transformers=[ ('hourly_cat', OneHotEncoder(categories=[range(0,24)], sparse = False), [col_index_dict['trip_start_hour']]), ('dow', OneHotEncoder(categories=[['Mon', 'Tue', 'Sun', 'Wed', 'Sat', 'Fri', 'Thu']], sparse = False), [col_index_dict['trip_start_day_of_week']]), ('std_scaler', StandardScaler(), [ col_index_dict['trip_start_year'], col_index_dict['abs_distance'], col_index_dict['pickup_longitude'], col_index_dict['pickup_latitude'], col_index_dict['dropoff_longitude'], col_index_dict['dropoff_latitude'], col_index_dict['trip_miles'], col_index_dict['trip_seconds']]) ]) # Add the random-forest estimator to the pipeline rfr_pipe = Pipeline([ ('ct', ct_pipe), ('forest_reg', RandomForestRegressor( n_estimators = 20, max_features = 1.0, n_jobs = -1, random_state = 3, max_depth=None, max_leaf_nodes=None, )) ]) # train the model rfr_score = cross_val_score(rfr_pipe, X_train, y_train, scoring = 'neg_mean_squared_error', cv = 5) rfr_rmse = np.sqrt(-rfr_score) print ("Crossvalidation RMSE:",rfr_rmse.mean()) final_model=rfr_pipe.fit(X_train, y_train) # Save the model pipeline with open(os.path.join(args.training_dir,"model.pkl"), 'wb') as model_file: pickle.dump(final_model, model_file)Le code effectue les tâches suivantes :
- Sélection des caractéristiques.
- Transformation de l'heure de prise en charge et de l'heure de dépôt, exprimées en temps UTC, en heure locale de Chicago.
- Extraction de la date, de l'heure, du jour de la semaine, du mois et de l'année à partir des date et heure de prise en charge.
- Calcul de la durée du trajet à l'aide des heures de début et de fin.
- Identification et marquage des trajets qui commencent ou se terminent dans un aéroport, en fonction des zones communautaires.
- Prédiction du tarif de la course en taxi à l'aide du modèle de régression Random Forest, entraîné à cette fin, et du framework scikit-learn.
Le modèle entraîné est enregistré dans un fichier pickle
model.pkl.L'approche retenue et l'ingénierie des caractéristiques sont basées sur l'exploration et l'analyse des données concernant la prédiction du tarif d'une course en taxi à Chicago.
Dans le panneau Fichiers, créez un fichier nommé
setup.pydans le dossier training_package, contenant le code suivant.from setuptools import find_packages from setuptools import setup REQUIRED_PACKAGES=["google-cloud-bigquery[pandas]","google-cloud-bigquery-storage"] setup( name='trainer', version='0.1', install_requires=REQUIRED_PACKAGES, packages=find_packages(), include_package_data=True, description='Training application package for chicago taxi trip fare prediction.' )Dans votre notebook, exécutez
setup.pypour créer la distribution source de votre application d'entraînement :! cd training_package && python setup.py sdist --formats=gztar && cd ..
À la fin de cette section, votre panneau Fichiers doit contenir les fichiers et dossiers suivants dans le dossier training-package.
dist
trainer-0.1.tar.gz
trainer
__init__.py
task.py
trainer.egg-info
__init__.py
setup.py
Importer le package d'entraînement personnalisé dans Cloud Storage
Créer un bucket Cloud Storage
REGION="REGION" BUCKET_NAME = "BUCKET_NAME" BUCKET_URI = f"gs://{BUCKET_NAME}" ! gcloud storage buckets create gs://$BUCKET_URI --location=$REGION --project=$PROJECT_IDRemplacez les valeurs de paramètre suivantes :
REGION: choisissez la même région que celle choisie lors de la création de votre notebook Colab.BUCKET_NAME: nom du bucket.
Importez votre package d'entraînement dans le bucket Cloud Storage.
# Copy the training package to the bucket ! gcloud storage cp training_package/dist/trainer-0.1.tar.gz $BUCKET_URI/
Créer votre pipeline
Un pipeline est une description d'un workflow MLOps sous la forme d'un graphe d'étapes appelées tâches de pipeline.
Dans cette section, vous allez définir vos tâches de pipeline, les compiler en YAML et enregistrer votre pipeline dans Artifact Registry afin qu'il puisse être soumis au contrôle des versions et exécuté plusieurs fois, par un seul utilisateur ou par plusieurs utilisateurs.
Voici une visualisation des tâches dans votre pipeline, y compris l'entraînement du modèle, son importation et son évaluation, ainsi que les notifications par e-mail :
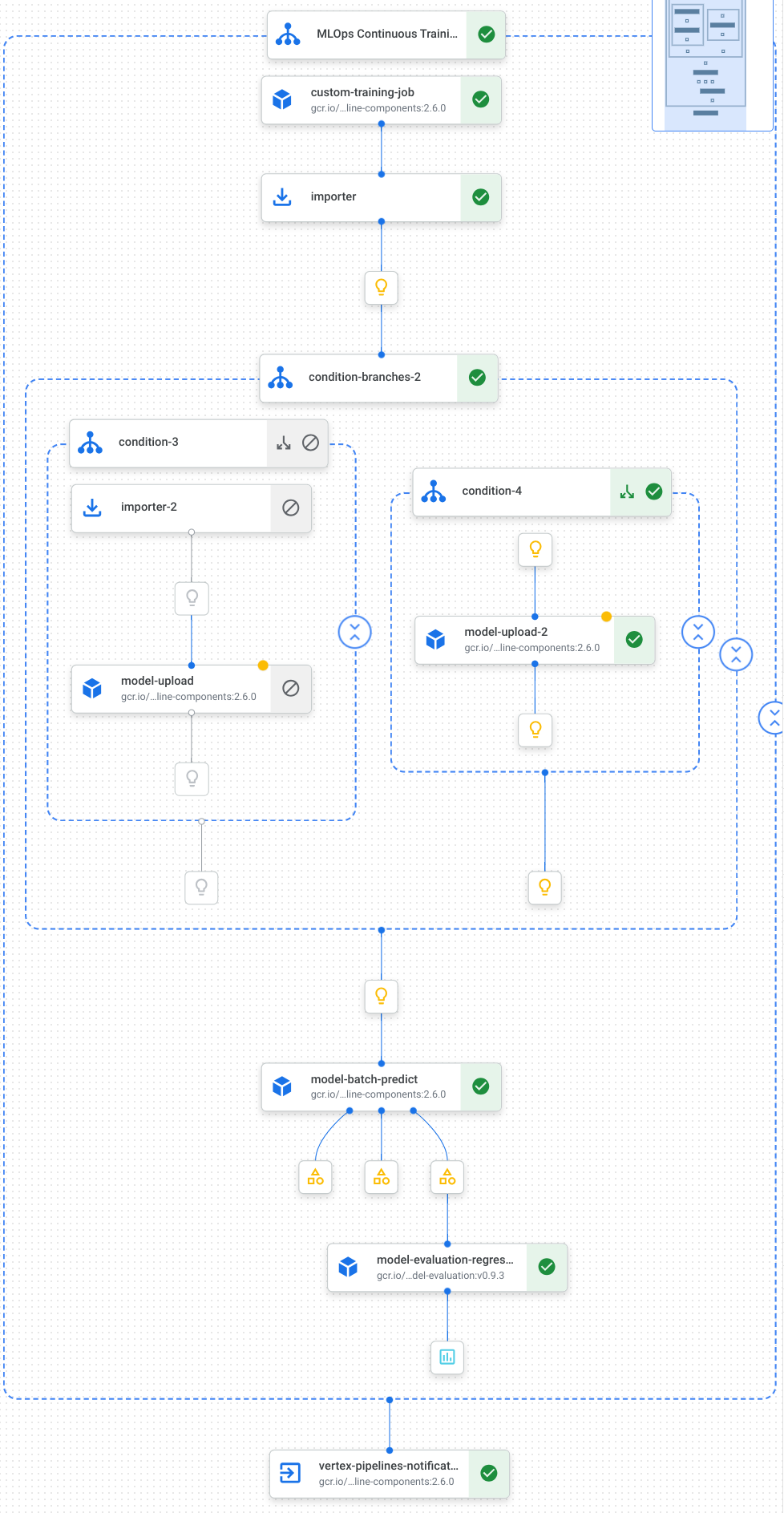
Pour en savoir plus, consultez la page Créer des modèles de pipeline.
Définir des constantes et initialiser les clients
Dans votre notebook, définissez les constantes qui seront utilisées aux étapes suivantes :
import os EMAIL_RECIPIENTS = [ "NOTIFY_EMAIL" ] PIPELINE_ROOT = "{}/pipeline_root/chicago-taxi-pipe".format(BUCKET_URI) PIPELINE_NAME = "vertex-pipeline-datatrigger-tutorial" WORKING_DIR = f"{PIPELINE_ROOT}/mlops-datatrigger-tutorial" os.environ['AIP_MODEL_DIR'] = WORKING_DIR EXPERIMENT_NAME = PIPELINE_NAME + "-experiment" PIPELINE_FILE = PIPELINE_NAME + ".yaml"Remplacez
NOTIFY_EMAILpar une adresse e-mail. Une fois le job de pipeline terminé, un e-mail est envoyé à cette adresse, et ce que le job ait abouti ou non.Initialisez le SDK Vertex AI en spécifiant le projet, le bucket de préproduction, l'emplacement et le nom du test.
from google.cloud import aiplatform aiplatform.init( project=PROJECT_ID, staging_bucket=BUCKET_URI, location=REGION, experiment=EXPERIMENT_NAME) aiplatform.autolog()
Définir les tâches de pipeline
Dans votre notebook, définissez votre pipeline custom_model_training_evaluation_pipeline :
from kfp import dsl
from kfp.dsl import importer
from kfp.dsl import OneOf
from google_cloud_pipeline_components.v1.custom_job import CustomTrainingJobOp
from google_cloud_pipeline_components.types import artifact_types
from google_cloud_pipeline_components.v1.model import ModelUploadOp
from google_cloud_pipeline_components.v1.batch_predict_job import ModelBatchPredictOp
from google_cloud_pipeline_components.v1.model_evaluation import ModelEvaluationRegressionOp
from google_cloud_pipeline_components.v1.vertex_notification_email import VertexNotificationEmailOp
from google_cloud_pipeline_components.v1.endpoint import ModelDeployOp
from google_cloud_pipeline_components.v1.endpoint import EndpointCreateOp
from google.cloud import aiplatform
# define the train-deploy pipeline
@dsl.pipeline(name="custom-model-training-evaluation-pipeline")
def custom_model_training_evaluation_pipeline(
project: str,
location: str,
training_job_display_name: str,
worker_pool_specs: list,
base_output_dir: str,
prediction_container_uri: str,
model_display_name: str,
batch_prediction_job_display_name: str,
target_field_name: str,
test_data_gcs_uri: list,
ground_truth_gcs_source: list,
batch_predictions_gcs_prefix: str,
batch_predictions_input_format: str="csv",
batch_predictions_output_format: str="jsonl",
ground_truth_format: str="csv",
parent_model_resource_name: str=None,
parent_model_artifact_uri: str=None,
existing_model: bool=False
):
# Notification task
notify_task = VertexNotificationEmailOp(
recipients= EMAIL_RECIPIENTS
)
with dsl.ExitHandler(notify_task, name='MLOps Continuous Training Pipeline'):
# Train the model
custom_job_task = CustomTrainingJobOp(
project=project,
display_name=training_job_display_name,
worker_pool_specs=worker_pool_specs,
base_output_directory=base_output_dir,
location=location
)
# Import the unmanaged model
import_unmanaged_model_task = importer(
artifact_uri=base_output_dir,
artifact_class=artifact_types.UnmanagedContainerModel,
metadata={
"containerSpec": {
"imageUri": prediction_container_uri,
},
},
).after(custom_job_task)
with dsl.If(existing_model == True):
# Import the parent model to upload as a version
import_registry_model_task = importer(
artifact_uri=parent_model_artifact_uri,
artifact_class=artifact_types.VertexModel,
metadata={
"resourceName": parent_model_resource_name
},
).after(import_unmanaged_model_task)
# Upload the model as a version
model_version_upload_op = ModelUploadOp(
project=project,
location=location,
display_name=model_display_name,
parent_model=import_registry_model_task.outputs["artifact"],
unmanaged_container_model=import_unmanaged_model_task.outputs["artifact"],
)
with dsl.Else():
# Upload the model
model_upload_op = ModelUploadOp(
project=project,
location=location,
display_name=model_display_name,
unmanaged_container_model=import_unmanaged_model_task.outputs["artifact"],
)
# Get the model (or model version)
model_resource = OneOf(model_version_upload_op.outputs["model"], model_upload_op.outputs["model"])
# Batch prediction
batch_predict_task = ModelBatchPredictOp(
project= project,
job_display_name= batch_prediction_job_display_name,
model= model_resource,
location= location,
instances_format= batch_predictions_input_format,
predictions_format= batch_predictions_output_format,
gcs_source_uris= test_data_gcs_uri,
gcs_destination_output_uri_prefix= batch_predictions_gcs_prefix,
machine_type= 'n1-standard-2'
)
# Evaluation task
evaluation_task = ModelEvaluationRegressionOp(
project= project,
target_field_name= target_field_name,
location= location,
# model= model_resource,
predictions_format= batch_predictions_output_format,
predictions_gcs_source= batch_predict_task.outputs["gcs_output_directory"],
ground_truth_format= ground_truth_format,
ground_truth_gcs_source= ground_truth_gcs_source
)
return
Votre pipeline consiste en un graphe de tâches qui utilisent les composants de pipeline Google Cloud suivants :
CustomTrainingJobOp: exécute des jobs d'entraînement personnalisés dans Vertex AI.ModelUploadOp: importe le modèle de machine learning entraîné dans Model Registry.ModelBatchPredictOp: crée un job de prédiction par lot.ModelEvaluationRegressionOp: évalue un job de régression par lot.VertexNotificationEmailOp: envoie des notifications par e-mail.
Compiler le pipeline
Compilez le pipeline à l'aide du compilateur Kubeflow Pipelines (KFP) dans un fichier YAML, qui va contenir une représentation hermétique de votre pipeline.
from kfp import dsl
from kfp import compiler
compiler.Compiler().compile(
pipeline_func=custom_model_training_evaluation_pipeline,
package_path="{}.yaml".format(PIPELINE_NAME),
)
Un fichier YAML nommé vertex-pipeline-datatrigger-tutorial.yaml doit s'afficher dans votre répertoire de travail.
Importer le pipeline en tant que modèle
Créez un dépôt de type
KFPdans Artifact Registry.REPO_NAME = "mlops" # Create a repo in the artifact registry ! gcloud artifacts repositories create $REPO_NAME --location=$REGION --repository-format=KFPImportez le pipeline compilé dans le dépôt.
from kfp.registry import RegistryClient host = f"https://{REGION}-kfp.pkg.dev/{PROJECT_ID}/{REPO_NAME}" client = RegistryClient(host=host) TEMPLATE_NAME, VERSION_NAME = client.upload_pipeline( file_name=PIPELINE_FILE, tags=["v1", "latest"], extra_headers={"description":"This is an example pipeline template."}) TEMPLATE_URI = f"https://{REGION}-kfp.pkg.dev/{PROJECT_ID}/{REPO_NAME}/{TEMPLATE_NAME}/latest"Dans la console Google Cloud, vérifiez que votre modèle apparaît dans Modèles de pipeline.
Exécuter manuellement le pipeline
Pour vous assurer que le pipeline fonctionne, vous allez l'exécuter manuellement.
Dans votre notebook, spécifiez les paramètres nécessaires à l'exécution du pipeline en tant que job.
DATASET_NAME = "mlops" TABLE_NAME = "chicago" worker_pool_specs = [{ "machine_spec": {"machine_type": "e2-highmem-2"}, "replica_count": 1, "python_package_spec":{ "executor_image_uri": "us-docker.pkg.dev/vertex-ai/training/sklearn-cpu.1-0:latest", "package_uris": [f"{BUCKET_URI}/trainer-0.1.tar.gz"], "python_module": "trainer.task", "args":["--project-id",PROJECT_ID, "--training-dir",f"/gcs/{BUCKET_NAME}","--bq-source",f"{PROJECT_ID}.{DATASET_NAME}.{TABLE_NAME}"] }, }] parameters = { "project": PROJECT_ID, "location": REGION, "training_job_display_name": "taxifare-prediction-training-job", "worker_pool_specs": worker_pool_specs, "base_output_dir": BUCKET_URI, "prediction_container_uri": "us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.1-0:latest", "model_display_name": "taxifare-prediction-model", "batch_prediction_job_display_name": "taxifare-prediction-batch-job", "target_field_name": "fare", "test_data_gcs_uri": [f"{BUCKET_URI}/test_no_target.csv"], "ground_truth_gcs_source": [f"{BUCKET_URI}/test.csv"], "batch_predictions_gcs_prefix": f"{BUCKET_URI}/batch_predict_output", "existing_model": False }Créez un job de pipeline et exécutez-le.
# Create a pipeline job job = aiplatform.PipelineJob( display_name="triggered_custom_regression_evaluation", template_path=TEMPLATE_URI , parameter_values=parameters, pipeline_root=BUCKET_URI, enable_caching=False ) # Run the pipeline job job.run()L'exécution de ce job prend environ 30 minutes.
Dans la console, vous devriez voir une nouvelle exécution du pipeline sur la page Pipelines :
Une fois l'exécution du pipeline terminée, vous devriez voir un nouveau modèle nommé
taxifare-prediction-modelou une nouvelle version de modèle dans Vertex AI Model Registry :Vous devriez également voir un nouveau job de prédiction par lot s'afficher :
Exécuter automatiquement le pipeline
Il existe deux façons d'exécuter automatiquement le pipeline : en suivant un calendrier ou lorsque de nouvelles données sont insérées dans l'ensemble de données.
Exécuter le pipeline selon un calendrier
Dans votre notebook, appelez
PipelineJob.create_schedule.job_schedule = job.create_schedule( display_name="mlops tutorial schedule", cron="0 0 1 * *", # max_concurrent_run_count=1, max_run_count=12, )L'expression
cronplanifie l'exécution de la tâche chaque 1er du mois à minuit (UTC).Pour ce tutoriel, nous ne souhaitons pas que plusieurs tâches s'exécutent simultanément. Nous définissons donc
max_concurrent_run_countsur 1.Dans la console Google Cloud, vérifiez que votre
scheduleapparaît dans Programmations de pipelines.
Exécuter le pipeline lorsqu'il y a de nouvelles données
Créer une fonction avec un déclencheur Eventarc
Créez une fonction Cloud Functions (2nd gen) qui exécute le pipeline chaque fois que de nouvelles données sont insérées dans la table BigQuery.
Plus précisément, nous utilisons un Eventarc pour déclencher la fonction chaque fois qu'un événement google.cloud.bigquery.v2.JobService.InsertJob se produit. La fonction exécute ensuite le modèle de pipeline.
Pour en savoir plus, consultez les pages Déclencheurs Eventarc et Types d'événements compatibles.
Dans la console Google Cloud, accédez à Cloud Functions.
Cliquez sur le bouton Créer une fonction. Sur la page Configuration :
Sélectionnez 2nd gen comme environnement.
Dans le champ Nom de la fonction, utilisez mlops.
Dans le champ Région, sélectionnez la même région que celle utilisée pour votre bucket Cloud Storage et votre dépôt Artifact Registry.
Dans le champ Déclencheur, sélectionnez Autre déclencheur. Le volet Déclencheur Eventarc s'affiche.
Dans le champ Type de déclencheur, sélectionnez Sources Google.
Dans le champ Fournisseur d'événements, sélectionnez BigQuery.
Dans le champ Type d'événement, sélectionnez
google.cloud.bigquery.v2.JobService.InsertJob.Dans le champ Ressource, choisissez Ressource spécifique et spécifiez la table BigQuery.
projects/PROJECT_ID/datasets/mlops/tables/chicagoDans le champ Région, sélectionnez un emplacement pour le déclencheur Eventarc, le cas échéant. Pour en savoir plus, consultez la section Emplacement du déclencheur.
Cliquez sur Enregistrer le déclencheur.
Si vous êtes invité à attribuer des rôles à un ou plusieurs comptes de service, cliquez sur Tout autoriser.
Cliquez sur Suivant pour accéder à la page Code. Sur cette page Code :
Définissez le champ Environnement d'exécution sur Python 3.12.
Définissez le champ Point d'entrée sur
mlops_entrypoint.Dans l'éditeur intégré, ouvrez le fichier
main.pyet remplacez le contenu par ce qui suit :Remplacez
PROJECT_ID,REGIONetBUCKET_NAMEpar les valeurs que vous avez utilisées précédemment.import json import functions_framework import requests import google.auth import google.auth.transport.requests # CloudEvent function to be triggered by an Eventarc Cloud Audit Logging trigger # Note: this is NOT designed for second-party (Cloud Audit Logs -> Pub/Sub) triggers! @functions_framework.cloud_event def mlops_entrypoint(cloudevent): # Print out the CloudEvent's (required) `type` property # See https://github.com/cloudevents/spec/blob/v1.0.1/spec.md#type print(f"Event type: {cloudevent['type']}") # Print out the CloudEvent's (optional) `subject` property # See https://github.com/cloudevents/spec/blob/v1.0.1/spec.md#subject if 'subject' in cloudevent: # CloudEvent objects don't support `get` operations. # Use the `in` operator to verify `subject` is present. print(f"Subject: {cloudevent['subject']}") # Print out details from the `protoPayload` # This field encapsulates a Cloud Audit Logging entry # See https://cloud.google.com/logging/docs/audit#audit_log_entry_structure payload = cloudevent.data.get("protoPayload") if payload: print(f"API method: {payload.get('methodName')}") print(f"Resource name: {payload.get('resourceName')}") print(f"Principal: {payload.get('authenticationInfo', dict()).get('principalEmail')}") row_count = payload.get('metadata', dict()).get('tableDataChange',dict()).get('insertedRowsCount') print(f"No. of rows: {row_count} !!") if row_count: if int(row_count) > 0: print ("Pipeline trigger Condition met !!") submit_pipeline_job() else: print ("No pipeline triggered !!!") def submit_pipeline_job(): PROJECT_ID = 'PROJECT_ID' REGION = 'REGION' BUCKET_NAME = "BUCKET_NAME" DATASET_NAME = "mlops" TABLE_NAME = "chicago" base_output_dir = BUCKET_NAME BUCKET_URI = "gs://{}".format(BUCKET_NAME) PIPELINE_ROOT = "{}/pipeline_root/chicago-taxi-pipe".format(BUCKET_URI) PIPELINE_NAME = "vertex-mlops-pipeline-tutorial" EXPERIMENT_NAME = PIPELINE_NAME + "-experiment" REPO_NAME ="mlops" TEMPLATE_NAME="custom-model-training-evaluation-pipeline" TRAINING_JOB_DISPLAY_NAME="taxifare-prediction-training-job" worker_pool_specs = [{ "machine_spec": {"machine_type": "e2-highmem-2"}, "replica_count": 1, "python_package_spec":{ "executor_image_uri": "us-docker.pkg.dev/vertex-ai/training/sklearn-cpu.1-0:latest", "package_uris": [f"{BUCKET_URI}/trainer-0.1.tar.gz"], "python_module": "trainer.task", "args":["--project-id",PROJECT_ID,"--training-dir",f"/gcs/{BUCKET_NAME}","--bq-source",f"{PROJECT_ID}.{DATASET_NAME}.{TABLE_NAME}"] }, }] parameters = { "project": PROJECT_ID, "location": REGION, "training_job_display_name": "taxifare-prediction-training-job", "worker_pool_specs": worker_pool_specs, "base_output_dir": BUCKET_URI, "prediction_container_uri": "us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.1-0:latest", "model_display_name": "taxifare-prediction-model", "batch_prediction_job_display_name": "taxifare-prediction-batch-job", "target_field_name": "fare", "test_data_gcs_uri": [f"{BUCKET_URI}/test_no_target.csv"], "ground_truth_gcs_source": [f"{BUCKET_URI}/test.csv"], "batch_predictions_gcs_prefix": f"{BUCKET_URI}/batch_predict_output", "existing_model": False } TEMPLATE_URI = f"https://{REGION}-kfp.pkg.dev/{PROJECT_ID}/{REPO_NAME}/{TEMPLATE_NAME}/latest" print("TEMPLATE URI: ", TEMPLATE_URI) request_body = { "name": PIPELINE_NAME, "displayName": PIPELINE_NAME, "runtimeConfig":{ "gcsOutputDirectory": PIPELINE_ROOT, "parameterValues": parameters, }, "templateUri": TEMPLATE_URI } pipeline_url = "https://us-central1-aiplatform.googleapis.com/v1/projects/{}/locations/{}/pipelineJobs".format(PROJECT_ID, REGION) creds, project = google.auth.default() auth_req = google.auth.transport.requests.Request() creds.refresh(auth_req) headers = { 'Authorization': 'Bearer {}'.format(creds.token), 'Content-Type': 'application/json; charset=utf-8' } response = requests.request("POST", pipeline_url, headers=headers, data=json.dumps(request_body)) print(response.text)Ouvrez le fichier
requirements.txtet remplacez son contenu par ce qui suit :requests==2.31.0 google-auth==2.25.1
Cliquez sur Déployer pour déployer la fonction.
Insérer des données pour déclencher le pipeline
Dans la console Google Cloud, accédez à BigQuery Studio.
Cliquez sur Créer une requête SQL, puis exécutez la requête SQL suivante en cliquant sur Exécuter.
INSERT INTO `PROJECT_ID.mlops.chicago` ( WITH taxitrips AS ( SELECT trip_start_timestamp, trip_end_timestamp, trip_seconds, trip_miles, payment_type, pickup_longitude, pickup_latitude, dropoff_longitude, dropoff_latitude, tips, tolls, fare, pickup_community_area, dropoff_community_area, company, unique_key FROM `bigquery-public-data.chicago_taxi_trips.taxi_trips` WHERE pickup_longitude IS NOT NULL AND pickup_latitude IS NOT NULL AND dropoff_longitude IS NOT NULL AND dropoff_latitude IS NOT NULL AND trip_miles > 0 AND trip_seconds > 0 AND fare > 0 AND EXTRACT(YEAR FROM trip_start_timestamp) = 2022 ) SELECT trip_start_timestamp, EXTRACT(MONTH from trip_start_timestamp) as trip_month, EXTRACT(DAY from trip_start_timestamp) as trip_day, EXTRACT(DAYOFWEEK from trip_start_timestamp) as trip_day_of_week, EXTRACT(HOUR from trip_start_timestamp) as trip_hour, trip_seconds, trip_miles, payment_type, ST_AsText( ST_SnapToGrid(ST_GeogPoint(pickup_longitude, pickup_latitude), 0.1) ) AS pickup_grid, ST_AsText( ST_SnapToGrid(ST_GeogPoint(dropoff_longitude, dropoff_latitude), 0.1) ) AS dropoff_grid, ST_Distance( ST_GeogPoint(pickup_longitude, pickup_latitude), ST_GeogPoint(dropoff_longitude, dropoff_latitude) ) AS euclidean, CONCAT( ST_AsText(ST_SnapToGrid(ST_GeogPoint(pickup_longitude, pickup_latitude), 0.1)), ST_AsText(ST_SnapToGrid(ST_GeogPoint(dropoff_longitude, dropoff_latitude), 0.1)) ) AS loc_cross, IF((tips/fare >= 0.2), 1, 0) AS tip_bin, tips, tolls, fare, pickup_longitude, pickup_latitude, dropoff_longitude, dropoff_latitude, pickup_community_area, dropoff_community_area, company, unique_key, trip_end_timestamp FROM taxitrips LIMIT 1000000 )Cette requête SQL permet d'insérer de nouvelles lignes dans la table.
Pour vérifier si l'événement a été déclenché, recherchez la chaîne
pipeline trigger condition metdans le journal de votre fonction.Si la fonction a été déclenchée correctement, vous devriez voir une nouvelle exécution de pipeline dans Vertex AI Pipelines. L'exécution du job de pipeline prend environ 30 minutes.
Effectuer un nettoyage
Pour nettoyer toutes les ressources Google Cloud utilisées dans ce projet, vous pouvez supprimer le projet Google Cloud que vous avez utilisé lors de ce tutoriel.
Sinon, vous pouvez supprimer les ressources individuelles que vous avez créées pour ce tutoriel.
Supprimez le modèle comme suit :
Dans la section Vertex AI, accédez à la page Registre de modèles.
À côté du nom de votre modèle, cliquez sur le menu Actions, puis sélectionnez Supprimer le modèle.
Supprimez les exécutions du pipeline :
Accédez à la page Exécutions du pipeline.
À côté du nom de chaque exécution de pipeline, cliquez sur le menu Actions, puis sélectionnez Supprimer l'exécution du pipeline.
Supprimez les jobs d'entraînement personnalisés :
À côté du nom de chaque job d'entraînement personnalisé, cliquez sur le menu Actions, puis sélectionnez Supprimer le job d'entraînement personnalisé.
Supprimez les jobs de prédiction par lot comme suit :
À côté du nom de votre job de prédiction par lot, cliquez sur le menu Actions, puis sélectionnez Supprimer le job de prédiction par lot.