このページでは、オンライン予測エンドポイントにデプロイされたモデルの Model Monitoring ジョブの結果を作成、管理、解釈する方法について説明します。Vertex AI Model Monitoring は、カテゴリ入力特徴および数値入力特徴のために、特徴のスキューとドリフトの検出をサポートします。
モデルが本番環境にデプロイされ、Model Monitoring が有効になっている場合、その受信予測リクエストは Google Cloud プロジェクトの BigQuery テーブルに記録されます。ログに記録されたリクエストに含まれる入力特徴値が分析され、スキューまたはドリフトが検出されます。
モデルに元のトレーニング データセットを提供する場合は、スキュー検出を有効にできます。それ以外の場合は、ドリフト検出を有効にする必要があります。詳細については、Vertex AI Model Monitoring の概要をご覧ください。
前提条件
Model Monitoring を使用するには、次の手順を行います。
Vertex AI で使用可能な、表形式の AutoML またはインポートされた表形式のカスタム トレーニングのいずれかのタイプのモデルを用意します。
- 既存のエンドポイントを使用している場合は、エンドポイントにデプロイされたすべてのモデルが、表形式の AutoML またはインポートされたカスタム トレーニング タイプであることを確認します。
スキュー検出を有効にする場合は、トレーニング データを Cloud Storage または BigQuery にアップロードし、そのデータの URI リンクを取得します。ドリフト検出の場合、トレーニング データは必要ありません。
省略可: カスタム トレーニングされたモデルの場合は、モデルの分析インスタンス スキーマを Cloud Storage にアップロードします。 Model Monitoring では、モニタリング プロセスを開始し、スキュー検出のベースライン分布を計算するためにスキーマが必要です。ジョブの作成時にスキーマを指定しない場合、Model Monitoring が、モデルが受け取った最初の 1,000 件の予測リクエストからスキーマを自動的に解析できるようになるまで、ジョブは保留状態のままになります。
Model Monitoring ジョブの作成
スキュー検出またはドリフト検出を設定するには、モデルのデプロイのモニタリング ジョブを作成します。
コンソール
Google Cloud コンソールを使用してモデルのデプロイのモニタリング ジョブを作成するには、エンドポイントを作成します。
Google Cloud コンソールで、[Vertex AI エンドポイント] ページに移動します。
[エンドポイントの作成] をクリックします。
[新しいエンドポイント] ペインで、エンドポイントの名前を指定して、リージョンを設定します。
[続行] をクリックします。
[モデル名] フィールドで、インポートされたカスタム トレーニングまたは表形式の AutoML モデルを選択します。
[バージョン] フィールドで、モデルのバージョンを選択します。
[続行] をクリックします。
[モデルのモニタリング] ペインで、[このエンドポイントのモデルのモニタリングを有効にする] がオンになっていることを確認します。構成したモニタリングの設定は、このエンドポイントにデプロイされたすべてのモデルに適用されます。
[モニタリング ジョブの表示名] を入力します。
[モニタリング ウィンドウの長さ] を入力します。
[通知メール] に、モデルがアラートのしきい値を超えたときにアラートを受け取るメールアドレスを、カンマ区切り形式で 1 つ以上入力します。
省略可: 通知チャネルの場合、モデルがアラートのしきい値を超えたときにアラートを受け取るには、Cloud Monitoring チャネルを追加します。[通知チャンネルを管理] をクリックして、既存の Cloud Monitoring チャネルを選択するか、新しい Cloud Monitoring チャネルを作成できます。コンソールでは、PagerDuty、Slack、Pub/Sub 通知チャネルがサポートされています。
[サンプリング レート] を入力します。
省略可: [予測入力スキーマ] と [分析入力スキーマ] を入力します。
[続行] をクリックします。[モニタリングの目標] ペインが開き、スキュー検出またはドリフト検出のオプションが表示されます。
スキュー検出
- [トレーニング サービング スキューの検出] を選択します。
- [トレーニング データソース] で、トレーニング データソースを入力します。
- [ターゲット列] に、モデルをトレーニングして予測するトレーニング データの列名を入力します。このフィールドはモニタリング分析から除外されます。
- (省略可)[アラートのしきい値] で、アラートをトリガーするしきい値を指定します。しきい値の形式については、 ヘルプアイコンの上にポインタを置いてください。
- [作成] をクリックします。
ドリフト検出
- [予測ドリフト検出] を選択します。
- (省略可)[アラートのしきい値] で、アラートをトリガーするしきい値を指定します。しきい値の形式については、 ヘルプアイコンの上にポインタを置いてください。
- [作成] をクリックします。
gcloud
gcloud CLI を使用してモデルデプロイのモニタリング ジョブを作成するには、まずエンドポイントにモデルをデプロイします。
モニタリング ジョブの構成は、エンドポイントにデプロイされたすべてのモデルに適用されます。
gcloud ai model-monitoring-jobs create コマンドを実行します。
gcloud ai model-monitoring-jobs create \ --project=PROJECT_ID \ --region=REGION \ --display-name=MONITORING_JOB_NAME \ --emails=EMAIL_ADDRESS_1,EMAIL_ADDRESS_2 \ --endpoint=ENDPOINT_ID \ [--feature-thresholds=FEATURE_1=THRESHOLD_1, FEATURE_2=THRESHOLD_2] \ [--prediction-sampling-rate=SAMPLING_RATE] \ [--monitoring-frequency=MONITORING_FREQUENCY] \ [--analysis-instance-schema=ANALYSIS_INSTANCE_SCHEMA] \ --target-field=TARGET_FIELD \ --bigquery-uri=BIGQUERY_URI
ここで
PROJECT_ID は、Google Cloud プロジェクトの ID です。例:
my-project。REGION は、モニタリング ジョブのロケーションです。例:
us-central1。MONITORING_JOB_NAME は、モニタリング ジョブの名前です。例:
my-job。EMAIL_ADDRESS は、Model Monitoring からアラートを受け取るメールアドレスです。例:
example@example.com。ENDPOINT_ID は、モデルがデプロイされるエンドポイントの ID です。例:
1234567890987654321。省略可: FEATURE_1=THRESHOLD_1 は、モニタリングする各特徴のアラートしきい値です。たとえば、
Age=0.4を指定した場合、Age特徴について入力分布とベースライン分布の間の統計的距離が 0.4 を超えると、Model Monitoring によってアラートがログに記録されます。デフォルトでは、すべてのカテゴリ特徴と数値特徴がモニタリングされ、しきい値は 0.3 です。省略可: SAMPLING_RATE は、ログに記録する受信予測リクエストの割合です。例:
0.5。指定しない場合、Model Monitoring はすべての予測リクエストをログに記録します。省略可: MONITORING_FREQUENCY は、最近ログに記録された入力に対してモニタリング ジョブを実行する頻度です。最小粒度は 1 時間です。デフォルトは 24 時間です。例:
2。省略可: ANALYSIS_INSTANCE_SCHEMA は、入力データの形式を記述するスキーマ ファイルの Cloud Storage URI です。例:
gs://test-bucket/schema.yaml。(スキュー検出の場合のみ必須)TARGET_FIELD は、モデルによって予測されるフィールドです。このフィールドはモニタリング分析から除外されます。例:
housing-price。(スキュー検出の場合のみ必須)BIGQUERY_URI は、次の形式で BigQuery に保存されているトレーニング データセットへのリンクです。
bq://\PROJECT.\DATASET.\TABLE
例:
bq://\my-project.\housing-data.\san-francisco。bigquery-uriフラグは、トレーニング データセットへの代替リンクに置き換えることができます。Cloud Storage バケットに保存されている CSV ファイルの場合は、
--data-format=csv --gcs-uris=gs://BUCKET_NAME/OBJECT_NAMEを使用します。Cloud Storage バケットに保存されている TFRecord ファイルの場合は、
--data-format=tf-record --gcs-uris=gs://BUCKET_NAME/OBJECT_NAMEを使用します。表形式の AutoML マネージド データセットの場合は、
--dataset=DATASET_IDを使用します。
Python SDK
エンドツーエンドの Model Monitoring API ワークフローの詳細については、サンプル ノートブックをご覧ください。
REST API
まだデプロイしていない場合は、エンドポイントにモデルをデプロイします。モデルのデプロイ手順のエンドポイント ID を取得するステップで、JSON レスポンスの
deployedModels.id値を後で使用するために記録します。モデル モニタリング ジョブ リクエストを作成します。以下の手順は、ドリフト検出の基本的なモニタリング ジョブを作成する方法を示しています。JSON リクエストをカスタマイズするには、モニタリング ジョブのリファレンスをご覧ください。
リクエストのデータを使用する前に、次のように置き換えます。
- PROJECT_ID: Google Cloud プロジェクトの ID。例:
my-project - LOCATION: モニタリング ジョブのロケーション。例:
us-central1 - MONITORING_JOB_NAME: モニタリング ジョブの名前。例:
my-job - PROJECT_NUMBER: Google Cloud プロジェクトの番号。例:
1234567890 - ENDPOINT_ID: モデルがデプロイされるエンドポイントの ID。例:
1234567890 - DEPLOYED_MODEL_ID: デプロイされたモデルの ID。
- FEATURE:VALUE は、モニタリングする各特徴のアラートしきい値です。たとえば、
"Age": {"value": 0.4}を指定した場合、Age特徴について入力分布とベースライン分布の間の統計的距離が 0.4 を超えると、Model Monitoring によってアラートがログに記録されます。デフォルトでは、すべてのカテゴリ特徴と数値特徴がモニタリングされ、しきい値は 0.3 です。 - EMAIL_ADDRESS: Model Monitoring からアラートを受け取るメールアドレス。例:
example@example.com - NOTIFICATION_CHANNELS:
Model Monitoring からアラートを受け取る Cloud Monitoring 通知チャネルのリスト。通知チャネルのリソース名を使用します。これはプロジェクトの通知チャネルを一覧表示することで取得できます。例:
"projects/my-project/notificationChannels/1355376463305411567", "projects/my-project/notificationChannels/1355376463305411568"。 - 省略可: ANALYSIS_INSTANCE_SCHEMA は、入力データの形式を記述するスキーマ ファイルの Cloud Storage URI です。例:
gs://test-bucket/schema.yaml
リクエストの本文(JSON):
{ "displayName":"MONITORING_JOB_NAME", "endpoint":"projects/PROJECT_NUMBER/locations/LOCATION/endpoints/ENDPOINT_ID", "modelDeploymentMonitoringObjectiveConfigs": { "deployedModelId": "DEPLOYED_MODEL_ID", "objectiveConfig": { "predictionDriftDetectionConfig": { "driftThresholds": { "FEATURE_1": { "value": VALUE_1 }, "FEATURE_2": { "value": VALUE_2 } } }, }, }, "loggingSamplingStrategy": { "randomSampleConfig": { "sampleRate": 0.5, }, }, "modelDeploymentMonitoringScheduleConfig": { "monitorInterval": { "seconds": 3600, }, }, "modelMonitoringAlertConfig": { "emailAlertConfig": { "userEmails": ["EMAIL_ADDRESS"], }, "notificationChannels": [NOTIFICATION_CHANNELS] }, "analysisInstanceSchemaUri": ANALYSIS_INSTANCE_SCHEMA }リクエストを送信するには、次のいずれかのオプションを展開します。
次のような JSON レスポンスが返されます。
{ "name": "projects/PROJECT_NUMBER/locations/LOCATION/modelDeploymentMonitoringJobs/MONITORING_JOB_NUMBER", ... "state": "JOB_STATE_PENDING", "scheduleState": "OFFLINE", ... "bigqueryTables": [ { "logSource": "SERVING", "logType": "PREDICT", "bigqueryTablePath": "bq://PROJECT_ID.model_deployment_monitoring_8451189418714202112.serving_predict" } ], ... }- PROJECT_ID: Google Cloud プロジェクトの ID。例:
モニタリング ジョブが作成されると、Model Monitoring は PROJECT_ID.model_deployment_monitoring_ENDPOINT_ID.serving_predict という名前の生成された BigQuery テーブルに受信予測リクエストのログを記録します。リクエスト / レスポンス ロギングが有効になっている場合、Model Monitoring は、リクエスト / レスポンス ロギングと同じ BigQuery テーブルに受信リクエストのログを記録します。
(省略可)Model Monitoring ジョブのアラートを構成する
Model Monitoring ジョブのモニタリングとデバッグでアラートを使用できます。Model Monitoring は、ジョブの更新をメールで自動的に通知しますが、Cloud Logging と Cloud Monitoring の通知チャネルでアラートを設定することもできます。
メールアドレス
次のイベントが発生したとき、Model Monitoring は Model Monitoring ジョブの作成時に指定された各メールアドレスに、通知メールを送信します。
- スキュー検出またはドリフト検出が設定されたとき。
- 既存の Model Monitoring ジョブの構成が更新されたとき。
- スケジュール設定されたモニタリング パイプラインの実行が失敗したとき。
Cloud Logging
スケジュール設定されたモニタリング パイプラインの実行のログを有効にするには、modelDeploymentMonitoringJobs 構成の enableMonitoringPipelineLogs フィールドを true に設定します。モニタリング ジョブが設定されると、モニタリング間隔ごとにデバッグログが Cloud Logging に書き込まれます。
デバッグログは、model_monitoring というログ名で Cloud Logging に書き込まれます。例:
logName="projects/model-monitoring-demo/logs/aiplatform.googleapis.com%2Fmodel_monitoring" resource.labels.model_deployment_monitoring_job=6680511704087920640
ジョブの進行状況のログエントリの例を次に示します。
{ "insertId": "e2032791-acb9-4d0f-ac73-89a38788ccf3@a1", "jsonPayload": { "@type": "type.googleapis.com/google.cloud.aiplatform.logging.ModelMonitoringPipelineLogEntry", "statusCode": { "message": "Scheduled model monitoring pipeline finished successfully for job projects/677687165274/locations/us-central1/modelDeploymentMonitoringJobs/6680511704087920640" }, "modelDeploymentMonitoringJob": "projects/677687165274/locations/us-central1/modelDeploymentMonitoringJobs/6680511704087920640" }, "resource": { "type": "aiplatform.googleapis.com/ModelDeploymentMonitoringJob", "labels": { "model_deployment_monitoring_job": "6680511704087920640", "location": "us-central1", "resource_container": "projects/677687165274" } }, "timestamp": "2022-02-04T15:33:54.778883Z", "severity": "INFO", "logName": "projects/model-monitoring-demo/logs/staging-aiplatform.sandbox.googleapis.com%2Fmodel_monitoring", "receiveTimestamp": "2022-02-04T15:33:56.343298321Z" }
通知チャネル
スケジュールされたモニタリング パイプラインの実行が失敗するたびに、Model Monitoring は、Model Monitoring ジョブの作成時に指定した Cloud Monitoring 通知チャネルに通知を送信します。
特徴異常のアラートを構成する
特徴に設定されたしきい値を超えると、Model Monitoring が異常を検出します。Model Monitoring は、検出された異常をメールで自動的に通知しますが、Cloud Logging と Cloud Monitoring の通知チャネルでアラートを設定することもできます。
メールアドレス
モニタリング間隔ごとに、少なくとも 1 つの特徴値がしきい値を超えていれば、Model Monitoring は Model Monitoring ジョブの作成時に指定した各メールアドレスにメール通知アラートを送信します。このメール メッセージには次の内容が含まれます。
- モニタリング ジョブの実行時刻。
- スキューまたはドリフトがある特徴の名前。
- アラートのしきい値と記録された統計的距離の測定値。
Cloud Logging
Cloud Logging アラートを有効にするには、ModelMonitoringAlertConfig 構成の enableLogging フィールドを true に設定します。
各モニタリング間隔で、少なくとも 1 つの特徴の分布がその特徴のしきい値を超えると、異常ログが Cloud Logging に書き込まれます。ログは、Cloud Logging がサポートする任意のサービス(Pub/Sub など)に転送できます。
異常は、model_monitoring_anomaly というログ名で Cloud Logging に書き込まれます。例:
logName="projects/model-monitoring-demo/logs/aiplatform.googleapis.com%2Fmodel_monitoring_anomaly" resource.labels.model_deployment_monitoring_job=6680511704087920640
以下に、異常のログエントリの例を示します。
{ "insertId": "b0e9c0e9-0979-4aff-a5d3-4c0912469f9a@a1", "jsonPayload": { "anomalyObjective": "RAW_FEATURE_SKEW", "endTime": "2022-02-03T19:00:00Z", "featureAnomalies": [ { "featureDisplayName": "age", "deviation": 0.9, "threshold": 0.7 }, { "featureDisplayName": "education", "deviation": 0.6, "threshold": 0.3 } ], "totalAnomaliesCount": 2, "@type": "type.googleapis.com/google.cloud.aiplatform.logging.ModelMonitoringAnomaliesLogEntry", "startTime": "2022-02-03T18:00:00Z", "modelDeploymentMonitoringJob": "projects/677687165274/locations/us-central1/modelDeploymentMonitoringJobs/6680511704087920640", "deployedModelId": "1645828169292316672" }, "resource": { "type": "aiplatform.googleapis.com/ModelDeploymentMonitoringJob", "labels": { "model_deployment_monitoring_job": "6680511704087920640", "location": "us-central1", "resource_container": "projects/677687165274" } }, "timestamp": "2022-02-03T19:00:00Z", "severity": "WARNING", "logName": "projects/model-monitoring-demo/logs/staging-aiplatform.sandbox.googleapis.com%2Fmodel_monitoring_anomaly", "receiveTimestamp": "2022-02-03T19:59:52.121398388Z" }
通知チャネル
モニタリング間隔ごとに、少なくとも 1 つの特徴値がしきい値を超えていれば、Model Monitoring は Model Monitoring ジョブの作成時に指定した Cloud Monitoring 通知チャネルにアラートを送信します。このアラートには、アラートをトリガーした Model Monitoring ジョブに関する情報が含まれます。
Model Monitoring ジョブの更新
Model Monitoring ジョブは、次の方法で表示、更新、一時停止、削除できます。ジョブを削除するには、ジョブを一時停止する必要があります。
コンソール
Google Cloud コンソールでは、一時停止と削除はサポートされていません。代わりに gcloud CLI を使用してください。
Model Monitoring ジョブのパラメータを更新するには
Google Cloud コンソールで、[Vertex AI エンドポイント] ページに移動します。
編集するエンドポイントの名前をクリックします。
[設定を編集] をクリックします。
[エンドポイントの編集] ペインで、[モデルのモニタリング] または [モニタリングの目的] を選択します。
変更するフィールドを更新します。
[更新] をクリックします。
モデルの指標、アラート、モニタリング プロパティを表示するには
Google Cloud コンソールで、[Vertex AI エンドポイント] ページに移動します。
エンドポイントの名前をクリックします。
表示するモデルの [モニタリング] 列で、[有効] をクリックします。
gcloud
次のコマンドを実行します。
gcloud ai model-monitoring-jobs COMMAND MONITORING_JOB_ID \ --PARAMETER=VALUE --project=PROJECT_ID --region=LOCATION
ここで
COMMAND は、モニタリング ジョブで実行するコマンドです。たとえば、
update、pause、resume、deleteなどです。詳細については、gcloud CLI リファレンスをご覧ください。MONITORING_JOB_ID は、モニタリング ジョブの ID です。例:
123456789。[retrieving the endpoint information][retrieve-id] を行うか、Google Cloud コンソールでモデルの [モニタリング プロパティ] を表示して ID を確認できます。ID は、projects/PROJECT_NUMBER/locations/LOCATION/modelDeploymentMonitoringJobs/MONITORING_JOB_IDの形式でモニタリング ジョブのリソース名に含まれています。(省略可)PARAMETER=VALUE は、更新するパラメータです。このフラグは、
updateコマンドを使用する場合にのみ必要です。例:monitoring-frequency=2。更新できるパラメータの一覧については、gcloud CLI リファレンスをご覧ください。PROJECT_IDは Google Cloud プロジェクトの ID です。例:
my-project。LOCATION は、モニタリング ジョブのロケーションです。例:
us-central1。
REST API
ジョブの一時停止
リクエストのデータを使用する前に、次のように置き換えます。
- PROJECT_NUMBER: Google Cloud プロジェクトの番号。例:
1234567890 - LOCATION: モニタリング ジョブのロケーション。例:
us-central1 - MONITORING_JOB_ID: モニタリング ジョブの ID。例:
0987654321
リクエストを送信するには、次のいずれかのオプションを展開します。
次のような JSON レスポンスが返されます。
{}
ジョブの削除
リクエストのデータを使用する前に、次のように置き換えます。
- PROJECT_NUMBER: Google Cloud プロジェクトの番号。例:
my-project - LOCATION: モニタリング ジョブのロケーション。例:
us-central1 - MONITORING_JOB_ID: モニタリング ジョブの ID。例:
0987654321
リクエストを送信するには、次のいずれかのオプションを展開します。
次のような JSON レスポンスが返されます。
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION/operations/MONITORING_JOB_ID",
...
"done": true,
...
}
スキューデータとドリフトデータを分析する
Google Cloud コンソールを使用すると、モニタリング対象の各特徴の分布を可視化し、どの変更がスキューやドリフトを発生させたかを時系列で確認できます。特徴値の分布はヒストグラムとして表示できます。
コンソール
Google Cloud コンソールで特徴量分布のヒストグラムに移動するには、[エンドポイント] ページに移動します。
[エンドポイント] ページで、分析するエンドポイントをクリックします。
選択したエンドポイントの詳細ページには、そのエンドポイントにデプロイされているすべてのモデルのリストが表示されます。分析するモデルの名前をクリックします。
モデルの詳細ページには、モデルの入力特徴と、各特徴のアラートしきい値や、特徴の以前のアラート数などの関連情報が一覧表示されます。
特徴を分析するには、特徴の名前をクリックします。その特徴の特徴量分布のヒストグラムがページに表示されます。
モニタリング対象の特徴ごとに、Google Cloud コンソールで直近 50 個のモニタリング ジョブの分布を確認できます。スキュー検出の場合は、トレーニング データの分布が入力データの分布の隣に表示されます。
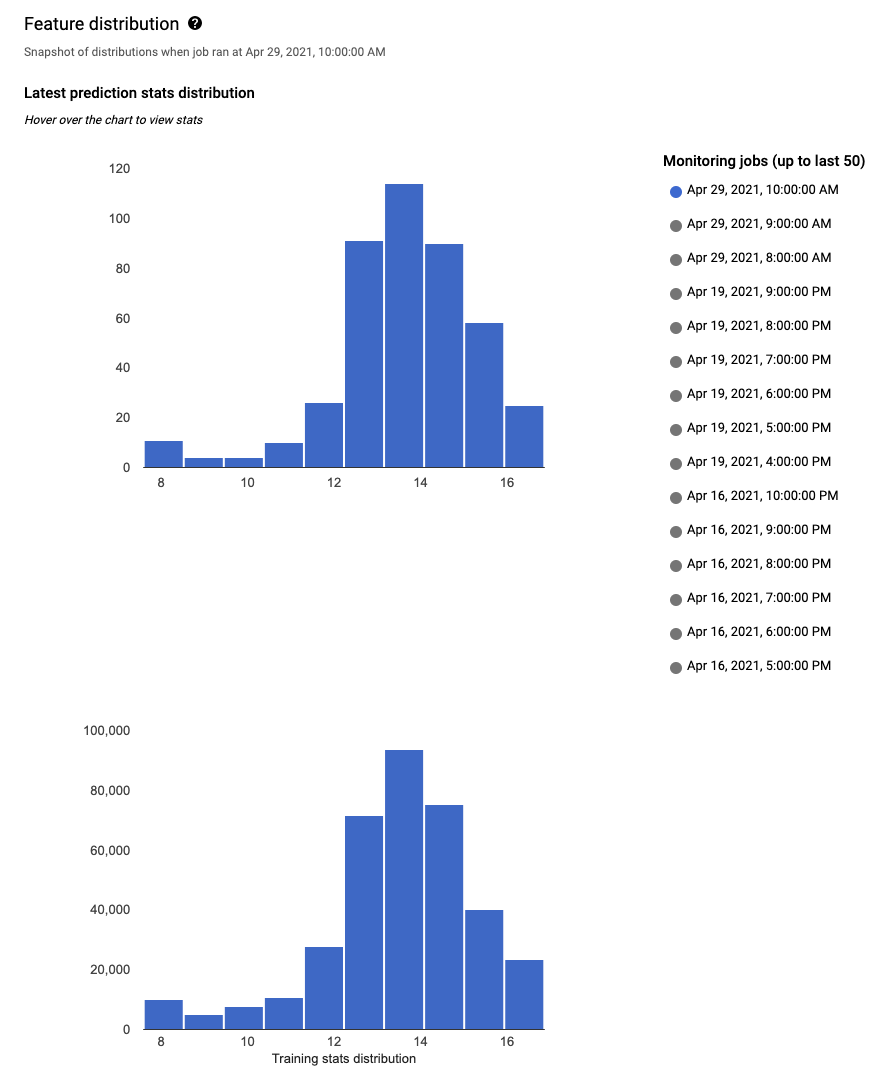
データ分布をヒストグラムとして可視化すると、データ内で発生した変更をすばやく確認できます。その後、特徴生成パイプラインの調整や、モデルの再トレーニングを決定できます。
次のステップ
- API ドキュメントに従って Model Monitoring を使用する。
- gcloud CLI ドキュメントに従って Model Monitoring を使用する。
- Colab でサンプル ノートブックを試すか、GitHub で表示する。
- Model Monitoring がトレーニング / サービング スキューと予測ドリフトを計算する方法を学習する。