当您运行作业时,Model Monitoring v2 会使用来自目标数据集和基准数据集的数据,计算指标并可能生成提醒。Model Monitoring v2 提供按需作业以进行临时监控,或提供预定作业以进行持续监控。无论选择哪个选项,每个作业都是单一批量执行。
如需详细了解监控目标和支持的模型,请参阅 Model Monitoring v2 概览和设置模型监控。
按需运行作业
运行一次性监控作业。为要监控的目标设置目标数据集和基准数据集以及监控规范。您的配置将替换模型监控定义的任何默认值(如果设置)。
控制台
在 Google Cloud 控制台中,前往 Monitoring 页面。
点击要为其运行监控作业的模型监控。
在模型监控详细信息页面上,点击立即运行以配置监控作业。
配置作业或使用模型监控中定义的默认值。
点击运行。
Python SDK
from vertexai.resources.preview import ml_monitoring FEATURE_THRESHOLDS = { "culmen_length_mm": 0.001, "body_mass_g": 0.002, } FEATURE_DRIFT_SPEC=ml_monitoring.spec.DataDriftSpec( categorical_metric_type="l_infinity", numeric_metric_type="jensen_shannon_divergence", default_categorical_alert_threshold=0.001, default_numeric_alert_threshold=0.002, feature_alert_thresholds=FEATURE_THRESHOLDS, ) PREDICTION_OUTPUT_DRIFT_SPEC=ml_monitoring.spec.DataDriftSpec( categorical_metric_type="l_infinity", numeric_metric_type="jensen_shannon_divergence", default_categorical_alert_threshold=0.001, default_numeric_alert_threshold=0.001, ) FEATURE_ATTRIBUTION_SPEC=ml_monitoring.spec.FeatureAttributionSpec( default_alert_threshold=0.0003, feature_alert_thresholds={"cnt_ad_reward":0.0001}, ) EXPLANATION_SPEC=ExplanationSpec( parameters=ExplanationParameters( {"sampled_shapley_attribution": {"path_count": 2}} ), metadata=ExplanationMetadata( inputs={ "cnt_ad_reward": ExplanationMetadata.InputMetadata({ "input_tensor_name": "cnt_ad_reward", "encoding": "IDENTITY", "modality": "numeric" }), ... }, ... ) ) TRAINING_DATASET=ml_monitoring.spec.MonitoringInput( gcs_uri=TRAINING_URI, data_format="csv" ) TARGET_DATASET=ml_monitoring.spec.MonitoringInput( table_uri=BIGQUERY_URI ) model_monitoring_job=my_model_monitor.run( display_name=JOB_DISPLAY_NAME, baseline_dataset=TRAINING_DATASET, target_dataset=TARGET_DATASET, tabular_objective_spec=ml_monitoring.spec.TabularObjective( # Optional: set to monitor input feature drift. feature_drift_spec=FEATURE_DRIFT_SPEC, # Optional: set to monitor prediction output drift. prediction_output_drift_spec=PREDICTION_OUTPUT_DRIFT_SPEC, # Optional: set to monitor feature attribution drift. feature_attribution_spec=FEATURE_ATTRIBUTION_SPEC ), # Optional: additional configurations to override default values. explanation_config=EXPLANATION_SPEC, notification_spec=NOTIFICATION_SPEC, output_spec=OUTPUT_SPEC )
安排持续运行
您可以为模型监控设置一个或多个运行时间表。如需使用带时间指定的持续监控,您的数据集必须包含一个时间戳列,以便 Model Monitoring v2 可以从指定时间范围中检索数据。
控制台
Python SDK
如需设置监控作业的频率,请使用 cron 表达式。
my_model_monitoring_schedule=my_model_monitor.create_schedule( display_name=SCHEDULE_DISPLAY_NAME, # Every day at 0:00(midnight) cron='"0 * * * *"', baseline_dataset=ml_monitoring.spec.MonitoringInput( endpoints=[ENDPOINT_RESOURCE_NAME], offset="24h", window="24h", ), target_dataset=ml_monitoring.spec.MonitoringInput( endpoints=[ENDPOINT_RESOURCE_NAME], window="24h" ), tabular_objective_spec=ml_monitoring.spec.TabularObjective( # Optional: set to monitor input feature drift. feature_drift_spec=FEATURE_DRIFT_SPEC, # Optional: set to monitor prediction output drift. prediction_output_drift_spec=PREDICTION_OUTPUT_DRIFT_SPEC, # Optional: set to monitor feature attribution drift. feature_attribution_spec=FEATURE_ATTRIBUTION_SPEC ), # Optional: additional configurations to override default values. explanation_config=EXPLANATION_SPEC, output_spec=OUTPUT_SPEC, notification_spec=NOTIFICATION_SPEC, )
暂停或恢复时间表
您可以暂停或恢复时间表,以跳过或暂时停止监控作业运行。
控制台
在 Google Cloud 控制台中,前往 Monitoring 页面。
点击包含要修改的时间表的模型监控。
在详细信息页面上,转到时间表标签页。
点击要修改的时间表。
点击暂停或恢复以暂停或恢复时间表。
Python SDK
# Pause schedule my_model_monitor.pause_schedule(my_monitoring_schedule.name) # Resume schedule my_model_monitor.resume_schedule(my_monitoring_schedule.name)
删除时间表
可删除您未使用的时间表。您的现有数据以及之前创建的所有作业都将保留。
控制台
在 Google Cloud 控制台中,前往 Monitoring 页面。
点击包含要修改的时间表的模型监控。
在详细信息页面上,转到时间表标签页。
点击要修改的时间表。
点击删除,然后再次点击删除进行确认。
Python SDK
my_model_monitor.delete_schedule(my_monitoring_schedule.name)
分析监控作业结果
您可以使用 Google Cloud 控制台直观呈现每个监控目标的数据分布,并了解哪些变化导致随时间发生偏移。
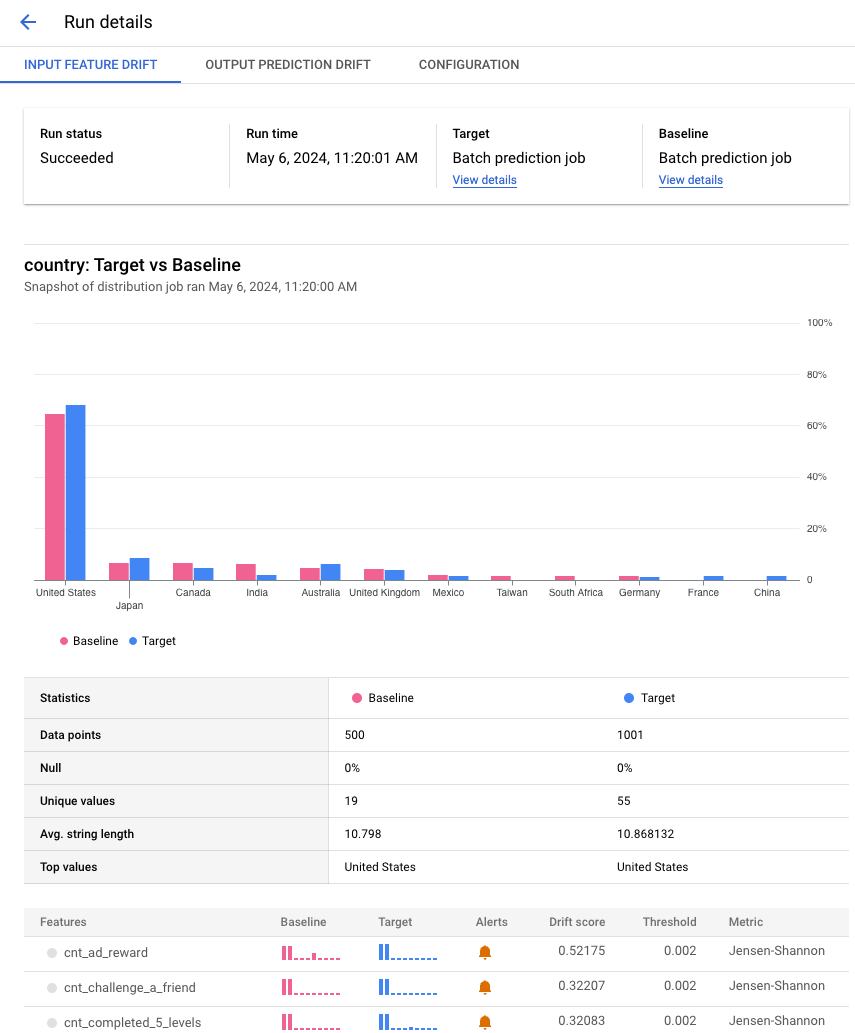
这些可视化内容显示了比较目标数据与基准数据之间的数据分布的直方图。例如,您可以根据容忍级别决定调整特征生成流水线或重新训练模型。
查看作业详情
查看监控作业运行的详细信息,例如受监控特征的列表以及哪些特征生成了提醒。
控制台
在 Google Cloud 控制台中,前往 Monitoring 页面。
点击包含要分析的作业的模型监控。
在监控详细信息页面上,点击运行标签页。
在运行列表中,点击某个运行以查看其详细信息,例如运行中包含的所有特征。
以下示例显示针对批量预测作业中的国家/地区特征的分布对比。 Google Cloud 控制台还会根据指标提供有关对比的详细信息,例如唯一值的数量、平均值和标准差。
查看特征详情
查看有关特征的信息以及包含相应特征的监控作业的列表。
控制台
在 Google Cloud 控制台中,前往 Monitoring 页面。
点击包含要分析的作业的模型监控。
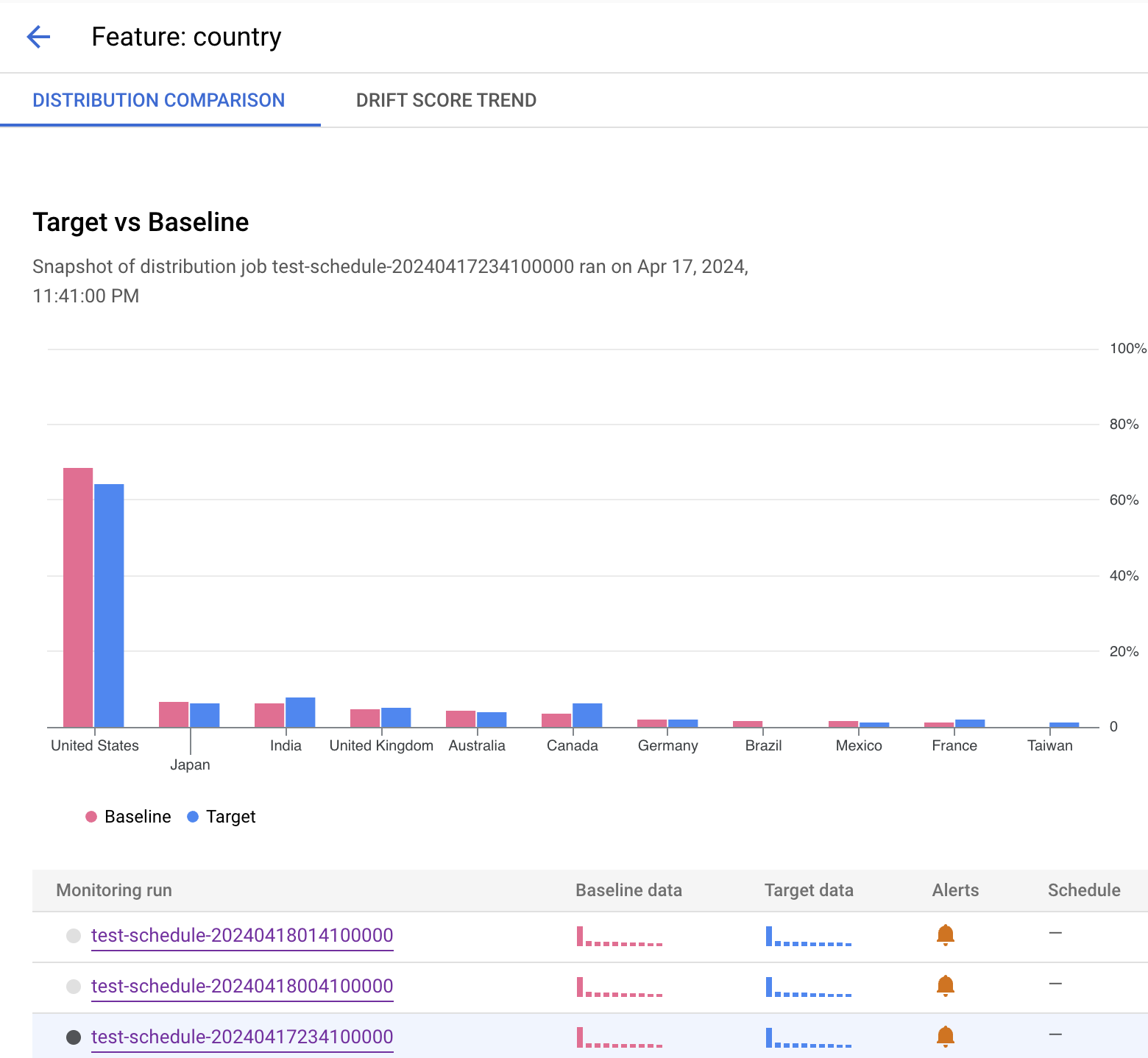
在概览标签页中,您可以查看摘要,其中包含所有受监控目标的偏移趋势(如果您设置了持续监控)。您还可以深入了解特定目标以查看详细信息,例如受监控的特征名称和监控运行列表。
以下示例显示针对国家/地区特征的分布对比。在直方图之后,您可以查看哪些运行生成了提醒,或者选择另一个包含此特征的监控数据的监控作业。