Nesta página, descrevemos como usar o monitoramento de modelos da Vertex AI com a Vertex Explainable AI para detectar distorções e desvios para as atribuições de atributos de recursos de entrada categóricos e numéricos.
Visão geral do monitoramento baseado em atribuição de recursos
As atribuições de recursos indicam o quanto cada elemento no seu modelo contribuiu para as previsões para cada instância determinada. Ao solicitar previsões, você recebe os valores previstos conforme apropriado para seu modelo. Quando você solicita explicações, recebe as previsões junto com as informações de atribuição de recursos.
As pontuações de atribuição são proporcionais à contribuição do recurso para a predição de um modelo. Normalmente, eles são assinados, indicando se um recurso ajuda a enviar a previsão para cima ou para baixo. As atribuições de todos os atributos precisam totalizar a pontuação de previsão do modelo.
Ao monitorar atribuições de recursos, o monitoramento de modelos rastreia as alterações nas contribuições de um atributo para as previsões de um modelo ao longo do tempo. Uma alteração na pontuação de atribuição de um recurso importante geralmente indica que o recurso mudou de uma maneira que pode afetar a precisão das previsões do modelo.
Para mais informações sobre como a pontuação de atribuição de recursos é calculada, consulte Métodos de atribuição de recursos.
Desvio de treinamento/disponibilização de atribuição de atributos e desvio de previsão.
Quando você cria um job de monitoramento para um modelo com a Vertex Explainable AI ativada, o monitoramento de modelos monitora a distorção ou desvio para distribuições de atributos e atribuições de atributos. Para informações sobre desvio e desvio de distribuição de atributos, consulte Introdução ao Vertex AI Model Monitoring.
Para atribuições de atributos:
O desvio de treinamento para exibição ocorre quando a pontuação de atribuição de um atributo na produção é diferente da pontuação de atribuição do recurso nos dados de treinamento originais.
O desvio de previsão ocorre quando a pontuação de atribuição de um recurso na produção muda significativamente ao longo do tempo.
Para ativar a detecção de desvio, forneça o conjunto de dados de treinamento original do modelo. Caso contrário, habilite a detecção de deslocamento. Também é possível ativar a detecção de distorção e desvio.
Pré-requisitos
Para usar o monitoramento de modelos com a Vertex Explainable AI, siga estas etapas:
Se você estiver ativando a detecção de distorção, faça o upload dos dados de treinamento ou da saída de um job de explicação em lote do conjunto de dados de treinamento para o Cloud Storage ou BigQuery. Consiga o link do URI para os dados. Para detecção de desvio, os dados de treinamento ou o valor de referência de explicação não são necessários.
Tenha um modelo disponível na Vertex AI que seja um AutoML tabular ou um tipo de treinamento personalizado e tabular importado:
Um modelo tabular do AutoML tem a Vertex Explainable AI configurada automaticamente para que seja possível pular para como ativar a detecção de distorção ou desvio. Somente modelos de classificação e regressão são compatíveis.
Um modelo importado e treinado de maneira personalizada precisa ser configurado para a Vertex Explainable AI ao criar, importar ou implantar o modelo.
Configure o modelo para usar a Vertex Explainable AI ao criar, importar ou implantar o modelo. O campo
ExplanationSpec.ExplanationParametersprecisa ser preenchido para o modelo.Opcional: para modelos com treinamento personalizado, faça upload do esquema de instância de análise do modelo no Cloud Storage. O monitoramento de modelos requer o esquema para iniciar o processo de monitoramento e calcular a distribuição de valor de referência para a detecção de distorção. Se você não fornecer o esquema durante a criação do job, ele permanecerá em estado pendente até que o monitoramento de modelos possa analisá-lo automaticamente a partir das primeiras 1.000 solicitações de previsão recebidas pelo modelo.
Ativar detecção de desvio ou deslocamento
Para configurar a detecção de distorção ou de deslocamento, crie um job de monitoramento de implantação de modelo:
Console
Para criar um job de monitoramento de implantação de modelo usando o consoleGoogle Cloud , crie um endpoint:
No console Google Cloud , acesse a página Endpoints da Vertex AI.
Clique em Criar endpoint.
No painel Novo endpoint, nomeie seu endpoint e defina uma região.
Clique em Continuar.
No campo Nome do modelo, selecione um treinamento personalizado importado ou um modelo tabular do AutoML.
No campo Versão, selecione uma versão para o modelo.
Clique em Continuar.
No painel Monitoramento de modelos, verifique se a opção Ativar o monitoramento de modelos para este endpoint está ativada. Todas as configurações de monitoramento que você definir se aplicam a todos os modelos implantados no endpoint.
Digite um Nome de exibição do job de monitoramento.
Insira uma Duração da janela de monitoramento.
Em E-mails de notificação, insira um ou mais endereços de e-mail separados por vírgula para receber alertas quando um modelo exceder um limite de alerta.
Opcional: em Canais de notificação, adicione canais do Cloud Monitoring para receber alertas quando um modelo exceder um limite de alertas. Selecione canais existentes do Cloud Monitoring ou crie um novo clicando em Gerenciar canais de notificação. O Console é compatível com os canais de notificação PagerDuty, Slack e Pub/Sub.
Insira uma Taxa de amostragem.
Opcional: insira o Esquema de entrada de previsão e o Esquema de entrada da análise.
Clique em Continuar. O painel Objetivo de monitoramento é aberto, com opções para detecção de distorção ou desvio:
Detecção de desvio
- Selecione Detecção de desvio de treinamento/disponibilização.
- Em Fonte de dados de treinamento, forneça uma fonte de dados de treinamento.
- Em Coluna de destino, insira o nome da coluna dos dados de treinamento que o modelo é treinado para prever. Esse campo é excluído da análise de monitoramento.
- Opcional: em Limites de alerta, especifique limites para acionar alertas. Para informações sobre como formatar os limites, passe o cursor sobre o ícone de ajuda .
- Clique em Criar.
Detecção de furtos
- Selecione Detecção de desvio de previsão.
- Opcional: em Limites de alerta, especifique limites para acionar alertas. Para informações sobre como formatar os limites, passe o cursor sobre o ícone de ajuda .
- Clique em Criar.
gcloud
Para criar um job de monitoramento de implantação de modelo usando a CLI gcloud, primeiro implante o modelo em um endpoint.
Uma configuração de job de monitoramento se aplica a todos os modelos implantados em um endpoint.
Execute o comando gcloud ai model-monitoring-jobs create:
gcloud ai model-monitoring-jobs create \ --project=PROJECT_ID \ --region=REGION \ --display-name=MONITORING_JOB_NAME \ --emails=EMAIL_ADDRESS_1,EMAIL_ADDRESS_2 \ --endpoint=ENDPOINT_ID \ --feature-thresholds=FEATURE_1=THRESHOLD_1,FEATURE_2=THRESHOLD_2 \ --prediction-sampling-rate=SAMPLING_RATE \ --monitoring-frequency=MONITORING_FREQUENCY \ --target-field=TARGET_FIELD \ --bigquery-uri=BIGQUERY_URI
em que:
PROJECT_ID é o ID do projeto Google Cloud . Por exemplo,
my-project.REGION é o local do job de monitoramento. Por exemplo,
us-central1.MONITORING_JOB_NAME é o nome do job de monitoramento. Por exemplo,
my-job.EMAIL_ADDRESS é o endereço de e-mail em que você quer receber alertas do monitoramento de modelos. Por exemplo,
example@example.com.ENDPOINT_ID é o ID do endpoint em que o modelo é implantado. Por exemplo,
1234567890987654321.FEATURE_1=THRESHOLD_1: e : é o limite de alerta para cada recurso que você quer monitorar. Por exemplo, se você especificar
Age=0.4, o monitoramento de modelos registrará um alerta quando aAgedistância estatística entre as distribuições de entrada e referência para o recurso exceder 0,4.Opcional: SAMPLING_RATE é a fração das solicitações de previsão recebidas que você quer registrar. Por exemplo,
0.5. Se não for especificado, o monitoramento de modelos registrará todas as solicitações de previsão.Opcional: MONITORING_FREQUENCY é a frequência com que você quer que o job de monitoramento seja executado nas entradas registradas recentemente. A granularidade mínima é de uma hora. O padrão é 24 horas. Por exemplo,
2.(obrigatório apenas para a detecção de distorção) TARGET_FIELD é o campo que está sendo previsto pelo modelo. Esse campo é excluído da análise de monitoramento. Por exemplo,
housing-price.(obrigatório apenas para detecção de distorção) BIGQUERY_URI é o link para o conjunto de dados de treinamento armazenado no BigQuery, usando o seguinte formato:
bq://\PROJECT.\DATASET.\TABLE
Por exemplo,
bq://\my-project.\housing-data.\san-franciscoÉ possível substituir a sinalização
bigquery-uripor links alternativos ao conjunto de dados de treinamento:Para um arquivo CSV armazenado em um bucket do Cloud Storage, use
--data-format=csv --gcs-uris=gs://BUCKET_NAME/OBJECT_NAME.Para um arquivo TFRecord armazenado em um bucket do Cloud Storage, use
--data-format=tf-record --gcs-uris=gs://BUCKET_NAME/OBJECT_NAME.Para um [conjunto de dados gerenciado do AutoML tabular][dataset-id], use
--dataset=DATASET_ID.
SDK do Python
Para informações sobre o fluxo de trabalho completo da API Modelo Monitoring, consulte o exemplo de notebook.
API REST
Implante o modelo em um endpoint se ainda não tiver feito isso.
Recupere o ID do modelo implantado ao receber as informações do endpoint. Observe DEPLOYED_MODEL_ID, que é o valor
deployedModels.idna resposta.Criar uma solicitação de job de monitoramento de modelo. As instruções abaixo mostram como criar um job básico de monitoramento para detecção de deslocamento com atribuições. Para detecção de distorção, adicione o objeto
explanationBaselineao campoexplanationConfigno corpo JSON da solicitação e forneça uma das seguintes informações:A saída de um job de explicação em lote para o conjunto de dados de treinamento
Uma
TrainingDatasetem que o serviço executa um jobBatchExplainpara gerar um valor de referência.
Para mais detalhes, consulte a Referência de jobs de monitoramento.
Antes de usar os dados da solicitação abaixo, faça as substituições a seguir:
- PROJECT_ID: é o ID do seu projeto Google Cloud . Por exemplo,
my-project. - LOCATION: é o local do job de monitoramento. Por exemplo,
us-central1. - MONITORING_JOB_NAME: é o nome do job de monitoramento. Por
exemplo,
my-job. - PROJECT_NUMBER: é o número do seu projeto Google Cloud . Por exemplo,
1234567890. - ENDPOINT_ID é o ID do endpoint em que o modelo é implantado. Por
exemplo,
1234567890. - DEPLOYED_MODEL_ID: é o ID do modelo implantado.
- FEATURE:VALUE e
: é o limite de alerta para
cada recurso que você quer monitorar. Por exemplo,
"housing-latitude": {"value": 0.4}. Um alerta é registrado quando a distância estatística entre a distribuição do atributo de entrada e o valor de referência correspondente excede o limite especificado. Por padrão, todos os atributos categóricos e numéricos são monitorados com valores limite de 0,3. - EMAIL_ADDRESS é o endereço de e-mail em que você quer receber alertas do monitoramento de modelos. Por exemplo,
example@example.com. - NOTIFICATION_CHANNELS:
uma lista de
canais de notificação do Cloud Monitoring
em que você quer receber alertas do monitoramento de modelos. Use os nomes dos recursos
para os canais de notificação, que podem ser recuperados por
meio da listagem dos canais de notificação
em seu projeto. Por exemplo,
"projects/my-project/notificationChannels/1355376463305411567", "projects/my-project/notificationChannels/1355376463305411568".
Corpo JSON da solicitação:
{ "displayName":"MONITORING_JOB_NAME", "endpoint":"projects/PROJECT_NUMBER/locations/LOCATION/endpoints/ENDPOINT_ID", "modelDeploymentMonitoringObjectiveConfigs": { "deployedModelId": "DEPLOYED_MODEL_ID", "objectiveConfig": { "predictionDriftDetectionConfig": { "driftThresholds": { "FEATURE_1": { "value": VALUE_1 }, "FEATURE_2": { "value": VALUE_2 } } }, "explanationConfig": { "enableFeatureAttributes": true } } }, "loggingSamplingStrategy": { "randomSampleConfig": { "sampleRate": 0.5, }, }, "modelDeploymentMonitoringScheduleConfig": { "monitorInterval": { "seconds": 3600, }, }, "modelMonitoringAlertConfig": { "emailAlertConfig": { "userEmails": ["EMAIL_ADDRESS"], }, "notificationChannels": [NOTIFICATION_CHANNELS] } }Para enviar a solicitação, expanda uma destas opções:
Você receberá uma resposta JSON semelhante a esta:
{ "name": "projects/PROJECT_NUMBER/locations/LOCATION/modelDeploymentMonitoringJobs/MONITORING_JOB_NUMBER", ... "state": "JOB_STATE_PENDING", "scheduleState": "OFFLINE", ... "bigqueryTables": [ { "logSource": "SERVING", "logType": "PREDICT", "bigqueryTablePath": "bq://PROJECT_ID.model_deployment_monitoring_8451189418714202112.serving_predict" } ], ... }
Depois que o job de monitoramento é criado, o monitoramento de modelos registra
as solicitações de previsão recebidas em uma tabela gerada do BigQuery chamada
PROJECT_ID.model_deployment_monitoring_ENDPOINT_ID.serving_predict.
Se a geração de registros de solicitação/resposta estiver ativada, o monitoramento de modelos registrará as solicitações recebidas na mesma tabela do BigQuery usada para a geração de registros de solicitação/resposta.
Consulte Como usar o monitoramento de modelos para instruções sobre como realizar as tarefas opcionais a seguir:
Atualizar um job de monitoramento de modelos.
Configurar alertas para o job de monitoramento de modelos
Configurar alertas para anomalias.
Analisar os dados de desvios e distorções da atribuição de atributos
É possível usar o console do Google Cloud para visualizar as atribuições de recursos de cada recurso monitorado e saber quais mudanças levaram a distorções ou desvios. Para informações sobre como analisar dados de distribuição de atributos, consulte Analisar dados de distorção e desvio.
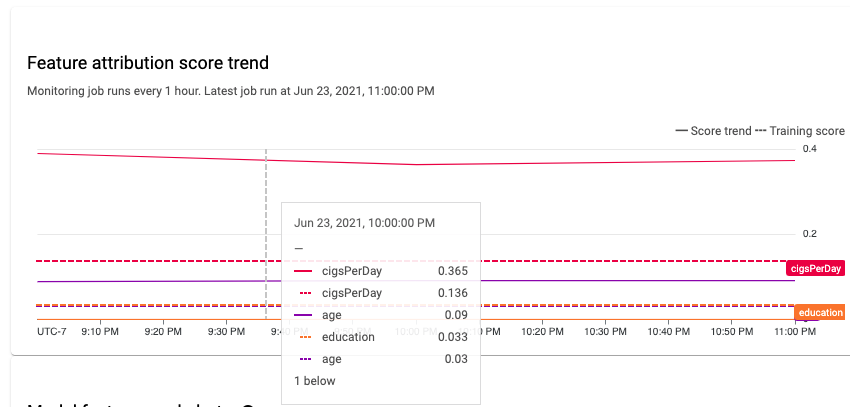
Em um sistema de machine learning estável, a importância relativa dos recursos permanece relativamente estável ao longo do tempo. Se um recurso importante cair na importância, isso poderá indicar que algo sobre ele mudou. Veja algumas causas comuns de desvio ou desvio de recursos:
- Alterações na fonte de dados
- Alterações no esquema e nos registros de dados
- Alterações no mix ou comportamento do usuário final (por exemplo, devido a alterações sazonais ou eventos outliers)
- Alterações upstream dos recursos gerados por outro modelo de machine learning.
Alguns exemplos são:
- Atualizações de modelo que causam um aumento ou uma diminuição na cobertura (em geral ou para um valor de classificação individual)
- uma mudança no desempenho do modelo (que altera o significado do atributo);
- Atualizações do pipeline de dados, que podem causar uma redução na cobertura geral
Além disso, considere o seguinte ao analisar os dados de desvio e desvios da atribuição de atributos:
Monitore os recursos mais importantes. Uma grande alteração na atribuição a um recurso significa que a contribuição do recurso para a previsão mudou. Como a previsão é igual à soma das contribuições dos recursos, um grande deslocamento de atribuição (dos recursos mais importantes) geralmente indica um desvio grande nas previsões do modelo.
Monitore todas as representações de recursos. As atribuições de recursos são sempre numéricas, independentemente do tipo de recurso subjacente. Além disso, devido à natureza aditiva delas, as atribuições para um recurso multidimensional (por exemplo, incorporações) podem ser reduzidas para um único valor numérico somando as atribuições em todas as dimensões. Isso permite usar os métodos padrão de detecção de deslocamento univariado para todos os tipos de atributos.
Considere as interações com recursos. A atribuição a um recurso considera a contribuição do recurso para a previsão, tanto individualmente quanto por suas interações com outros recursos. Se as interações de um recurso com outros atributos mudarem, a distribuição de atribuições para um recurso mudar, mesmo que a distribuição marginal do recurso permaneça a mesma.
Monitore os grupos de recursos. Como as atribuições são somadas, podemos adicionar atribuições para recursos relacionados para conseguir a atribuição de um grupo de recursos. Por exemplo, em um modelo de empréstimo de crédito, combine a atribuição a todos os atributos relacionados ao tipo de empréstimo (por exemplo, "grade", "sub_grade" e "purpose") para receber um único empréstimo. atribuição. Essa atribuição no nível do grupo pode ser rastreada para monitorar alterações no grupo de recursos.
A seguir
- Trabalhe com o monitoramento de modelos seguindo os documentos da API.
- Trabalhe com o monitoramento de modelos seguindo os documentos da CLI gcloud.
- Teste o notebook de exemplo no Colab ou visualize-o no GitHub.
- Saiba como o Monitoramento de Modelos calcula o desvio de treinamento/disponibilização e deslocamento de previsão.