Cette page explique comment utiliser Vertex AI Model Monitoring avec Vertex Explainable AI pour détecter les décalages et les dérives liés aux attributions de caractéristiques d'entrée catégorielles et numériques.
Présentation de la surveillance basée sur l'attribution de caractéristiques
Les attributions de caractéristiques indiquent dans quelle mesure chaque caractéristique de votre modèle a contribué aux prédictions pour chaque instance donnée. Lorsque vous demandez des prédictions, vous obtenez des valeurs prédites correspondant à votre modèle. Lorsque vous demandez des explications, vous obtenez les prédictions ainsi que les informations d'attribution des caractéristiques.
Les scores d'attribution sont proportionnels à la contribution de la caractéristique à la prédiction d'un modèle. Ils sont généralement signés, ce qui indique si une caractéristique contribue à améliorer ou à affaiblir la prédiction. Les attributions sur l'ensemble des caractéristiques doivent totaliser le score de prédiction du modèle.
En surveillant les attributions de caractéristiques, Model Monitoring effectue le suivi des modifications apportées aux contributions d'une caractéristique aux prédictions d'un modèle au fil du temps. Une modification du score d'attribution d'une caractéristique clé indique souvent que la caractéristique a changé d'une manière susceptible d'affecter la précision des prédictions du modèle.
Pour en savoir plus sur le calcul du score d'attribution des caractéristiques, consultez la section Méthodes d'attribution des caractéristiques.
Décalages entraînement/livraison et dérives de prédiction au niveau de l'attribution des caractéristiques
Lorsque vous créez un job de surveillance pour un modèle avec Vertex Explainable AI activé, Model Monitoring surveille le décalage ou la dérive pour les distributions de caractéristiques et pour les attributions de caractéristiques. Pour en savoir plus sur le décalage et la dérive de la distribution des caractéristiques, consultez la page Présentation de Vertex AI Model Monitoring.
Pour les attributions de caractéristiques :
Le décalage entraînement/livraison se produit lorsque le score d'attribution d'une caractéristique en production s'écarte de son score d'attribution dans les données d'entraînement d'origine.
La dérive de prédiction se produit lorsque le score d'attribution d'une caractéristique en production évolue considérablement au fil du temps.
Vous pouvez activer la détection des décalages si vous fournissez l'ensemble de données d'entraînement d'origine pour votre modèle. Sinon, vous devez activer la détection des dérives. Vous pouvez aussi activer la détection à la fois des décalages et des dérives.
Prérequis
Pour utiliser Model Monitoring avec Vertex Explainable AI, procédez comme suit :
Si vous activez la détection des décalages, importez les données d'entraînement ou le résultat d'un job d'explication par lot pour votre ensemble de données d'entraînement dans Cloud Storage ou BigQuery. Obtenez le lien d'URI vers les données. Pour la détection des dérives, il n'est pas nécessaire de disposer de données d'entraînement ou d'une référence d'explication.
Vous devez avoir un modèle disponible dans Vertex AI qui est soit un modèle tabulaire AutoML, soit un modèle tabulaire importé d'entraînement personnalisé :
Vertex Explainable AI est automatiquement configuré sur un modèle tabulaire AutoML. Vous pouvez donc passer à l'étape Activer la détection des décalages ou des dérives. Notez que seuls les modèles de classification et de régression sont acceptés.
Un modèle personnalisé importé doit être configuré pour Vertex Explainable AI lorsque vous créez, importez ou déployez le modèle.
Configurez votre modèle pour utiliser Vertex Explainable AI lorsque vous créez, importez ou déployez le modèle. Le champ
ExplanationSpec.ExplanationParametersdoit être renseigné pour votre modèle.Facultatif : pour les modèles à entraînement personnalisé, importez le schéma d'instance d'analyse de votre modèle dans Cloud Storage. Model Monitoring nécessite que le schéma lance le processus de surveillance et calcule la distribution de référence pour la détection des écarts. Si vous ne fournissez pas le schéma lors de la création du job, celui-ci reste en attente jusqu'à ce que Model Monitoring puisse analyser automatiquement le schéma à partir des 1 000 premières requêtes de prédiction reçues par le modèle.
Activer la détection des décalages ou des dérives
Pour configurer la détection des décalages ou des dérives, créez un job de surveillance du déploiement de modèle :
Console
Pour créer un job de surveillance de déploiement de modèle à l'aide de la consoleGoogle Cloud , créez un point de terminaison :
Dans la console Google Cloud , accédez à la page Points de terminaison Vertex AI.
Cliquez sur Créer un point de terminaison.
Dans le volet Nouveau point de terminaison, nommez votre point de terminaison et définissez une région.
Cliquez sur Continuer.
Dans le champ Nom du modèle, sélectionnez un modèle AutoML d'entraînement personnalisé ou tabulaire importé.
Dans le champ Version, sélectionnez une version pour votre modèle.
Cliquez sur Continuer.
Dans le volet Surveillance des modèles, assurez-vous que l'option Activer la surveillance des modèles pour ce point de terminaison est activée. Les paramètres de surveillance que vous configurez s'appliquent à tous les modèles déployés sur le point de terminaison.
Saisissez un nom à afficher pour la tâche Monitoring.
Saisissez la durée de la période de surveillance.
Dans le champ E-mails de notification, saisissez une ou plusieurs adresses e-mail afin de recevoir des alertes lorsqu'un modèle dépasse un seuil d'alerte.
(Facultatif) Pour les Canaux de notification, sélectionnez les canaux Cloud Monitoring) pour recevoir des alertes lorsqu'un modèle dépasse un seuil d'alerte. Vous pouvez sélectionner des canaux Cloud Monitoring existants ou en créer un en cliquant sur Gérer les canaux de notification. La console est compatible avec les canaux de notification PagerDuty, Slack et Pub/Sub.
Saisissez un taux d'échantillonnage.
(Facultatif) Spécifiez le schéma d'entrée de prédiction et le schéma d'entrée d'analyse.
Cliquez sur Continuer. Le volet Objectif de Monitoring s'ouvre, avec des options de détection de décalages ou de dérives :
Détection des écarts
- Sélectionnez Détection du décalage entraînement/livraison.
- Sous Source de données d'entraînement, indiquez une source de données d'entraînement.
- Sous Colonne cible, saisissez le nom de la colonne des données d'entraînement que le modèle est entraîné à prédire. Ce champ est exclu de l'analyse de surveillance.
- Facultatif : Sous Seuils d'alerte, spécifiez les seuils auxquels les alertes doivent être déclenchées. Pour en savoir plus sur le format des seuils, maintenez le pointeur de la souris sur l'icône d'aide .
- Cliquez sur Créer.
Détection des dérives
- Sélectionnez Détection de la dérive de prédiction.
- Facultatif : Sous Seuils d'alerte, spécifiez les seuils auxquels les alertes doivent être déclenchées. Pour en savoir plus sur le format des seuils, maintenez le pointeur de la souris sur l'icône d'aide .
- Cliquez sur Créer.
gcloud
Pour créer un job de surveillance de déploiement de modèle à l'aide de gcloud CLI, commencez par déployer votre modèle sur un point de terminaison.
Une configuration de job de surveillance s'applique à tous les modèles déployés sous un point de terminaison.
Exécutez la commande gcloud ai model-monitoring-jobs create :
gcloud ai model-monitoring-jobs create \ --project=PROJECT_ID \ --region=REGION \ --display-name=MONITORING_JOB_NAME \ --emails=EMAIL_ADDRESS_1,EMAIL_ADDRESS_2 \ --endpoint=ENDPOINT_ID \ --feature-thresholds=FEATURE_1=THRESHOLD_1,FEATURE_2=THRESHOLD_2 \ --prediction-sampling-rate=SAMPLING_RATE \ --monitoring-frequency=MONITORING_FREQUENCY \ --target-field=TARGET_FIELD \ --bigquery-uri=BIGQUERY_URI
où :
PROJECT_ID est l'ID de votre projet Google Cloud . Exemple :
my-project.REGION est l'emplacement de votre job de surveillance. Exemple :
us-central1.MONITORING_JOB_NAME est le nom de votre job de surveillance. Exemple :
my-job.EMAIL_ADDRESS est l'adresse e-mail à laquelle vous souhaitez recevoir des alertes de la surveillance de modèles. Exemple :
example@example.com.ENDPOINT_ID est l'ID du point de terminaison sous lequel votre modèle est déployé. Par exemple,
1234567890987654321.Facultatif : FEATURE_1=THRESHOLD_1 est le seuil d'alerte pour chaque caractéristique que vous souhaitez surveiller. Par exemple, si vous spécifiez
Age=0.4, la surveillance du modèle enregistre une alerte lorsque la [distance statistique][stat-distance] entre la distribution d'entrée et la distribution de référence de la caractéristiqueAgedépasse 0,4.Facultatif : SAMPLING_RATE est la fraction des requêtes de prédiction entrantes que vous souhaitez consigner. Par exemple,
0.5. Si ce n'est pas spécifié, la surveillance des modèles consigne toutes les requêtes de prédiction.Facultatif : MONITORING_FREQUENCY correspond à la fréquence à laquelle vous souhaitez que le job de surveillance s'exécute sur les entrées récemment consignées. La précision minimale est d'une heure. La valeur par défaut est 24 heures. Par exemple,
2.(Obligatoire uniquement pour la détection des décalages) TARGET_FIELD est le champ de prédiction du modèle. Ce champ est exclu de l'analyse de surveillance. Exemple :
housing-price(Obligatoire uniquement pour la détection des décalages) BIGQUERY_URI est le lien vers l'ensemble de données d'entraînement stocké dans BigQuery, au format suivant :
bq://\PROJECT.\DATASET.\TABLE
Par exemple,
bq://\my-project.\housing-data.\san-francisco.Vous pouvez remplacer l'option
bigquery-uripar d'autres liens vers votre ensemble de données d'entraînement :Pour un fichier CSV stocké dans un bucket Cloud Storage, utilisez
--data-format=csv --gcs-uris=gs://BUCKET_NAME/OBJECT_NAME.Pour un fichier TFRecord stocké dans un bucket Cloud Storage, utilisez
--data-format=tf-record --gcs-uris=gs://BUCKET_NAME/OBJECT_NAME.Pour un [ensemble de données tabulaire géré par AutoML][dataset-id], utilisez
--dataset=DATASET_ID.
SDK Python
Pour en savoir plus sur le workflow complet de l'API Model Monitoring, consultez l'exemple de notebook.
API REST
Si vous ne l'avez pas déjà fait, déployez votre modèle sur un point de terminaison.
Récupérez l'ID de modèle déployé pour votre modèle en obtenant les informations sur le point de terminaison. Notez l'élément DEPLOYED_MODEL_ID, qui correspond à la valeur
deployedModels.iddans la réponse.Créez une requête de job de surveillance de modèle. Les instructions ci-dessous montrent comment créer un job de surveillance de base pour détecter la dérive sur les attributions. Pour la détection des décalages, ajoutez l'objet
explanationBaselineau champexplanationConfigdans le corps JSON de la requête, puis fournissez l'un des éléments suivants :Le résultat d'un job d'explication par lot pour votre ensemble de données d'entraînement.
Un
TrainingDatasetsur lequel le service exécute un jobBatchExplainpour générer une référence.
Pour en savoir plus, consultez la documentation de référence sur les jobs de surveillance.
Avant d'utiliser les données de requête ci-dessous, effectuez les remplacements suivants :
- PROJECT_ID : ID de votre projet Google Cloud . Par exemple,
my-project. - LOCATION est l'emplacement de votre job de surveillance. Exemple :
us-central1. - MONITORING_JOB_NAME est le nom de votre job de surveillance. Exemple :
my-job. - PROJECT_NUMBER : numéro de votre projet Google Cloud . Par exemple,
1234567890. - ENDPOINT_ID est l'ID du point de terminaison sur lequel votre modèle est déployé. Exemple :
1234567890. - DEPLOYED_MODEL_ID est l'ID du modèle déployé.
- FEATURE :VALUE est le seuil d'alerte pour chaque caractéristique que vous souhaitez surveiller. Exemple :
"housing-latitude": {"value": 0.4}. Une alerte est consignée lorsque la distance statistique entre la distribution des caractéristiques d'entrée et la référence correspondante dépasse le seuil spécifié. Par défaut, chaque caractéristique catégorielle et numérique est surveillée, avec des valeurs de seuil de 0.3. - EMAIL_ADDRESS est l'adresse e-mail à laquelle vous souhaitez recevoir des alertes de la surveillance de modèles. Exemple :
example@example.com. - NOTIFICATION_CHANNELS : liste des canaux de notification Cloud Monitoring dans lesquels vous souhaitez recevoir des alertes de la surveillance de modèles. Utilisez les noms de ressources des canaux de notification, que vous pouvez récupérer en répertoriant les canaux de notification de votre projet. Exemple :
"projects/my-project/notificationChannels/1355376463305411567", "projects/my-project/notificationChannels/1355376463305411568".
Corps JSON de la requête :
{ "displayName":"MONITORING_JOB_NAME", "endpoint":"projects/PROJECT_NUMBER/locations/LOCATION/endpoints/ENDPOINT_ID", "modelDeploymentMonitoringObjectiveConfigs": { "deployedModelId": "DEPLOYED_MODEL_ID", "objectiveConfig": { "predictionDriftDetectionConfig": { "driftThresholds": { "FEATURE_1": { "value": VALUE_1 }, "FEATURE_2": { "value": VALUE_2 } } }, "explanationConfig": { "enableFeatureAttributes": true } } }, "loggingSamplingStrategy": { "randomSampleConfig": { "sampleRate": 0.5, }, }, "modelDeploymentMonitoringScheduleConfig": { "monitorInterval": { "seconds": 3600, }, }, "modelMonitoringAlertConfig": { "emailAlertConfig": { "userEmails": ["EMAIL_ADDRESS"], }, "notificationChannels": [NOTIFICATION_CHANNELS] } }Pour envoyer votre requête, développez l'une des options suivantes :
Vous devriez recevoir une réponse JSON de ce type :
{ "name": "projects/PROJECT_NUMBER/locations/LOCATION/modelDeploymentMonitoringJobs/MONITORING_JOB_NUMBER", ... "state": "JOB_STATE_PENDING", "scheduleState": "OFFLINE", ... "bigqueryTables": [ { "logSource": "SERVING", "logType": "PREDICT", "bigqueryTablePath": "bq://PROJECT_ID.model_deployment_monitoring_8451189418714202112.serving_predict" } ], ... }
Une fois le job de surveillance créé, Model Monitoring enregistre les requêtes de prédiction entrantes dans une table BigQuery générée nommée PROJECT_ID.model_deployment_monitoring_ENDPOINT_ID.serving_predict.
Si la journalisation des requêtes et réponses est activée, Model Monitoring enregistre les requêtes entrantes dans la même table BigQuery que celle utilisée pour la journalisation des requêtes et réponses.
Consultez la section Utiliser Model Monitoring pour savoir comment effectuer les tâches facultatives suivantes :
Mettre à jour un job Model Monitoring
Configurer des alertes pour le job Model Monitoring
Configurer des alertes d'anomalies
Analyser les données liées aux écarts et aux dérives d'attribution des caractéristiques
Vous pouvez utiliser la console Google Cloud pour visualiser les attributions de caractéristiques de chaque caractéristique surveillée au fil du temps et identifier les modifications qui ont entraîné un écart ou une dérive. Pour en savoir plus sur l'analyse des données de distribution des caractéristiques, consultez Analyser les données d'écarts et de dérives.
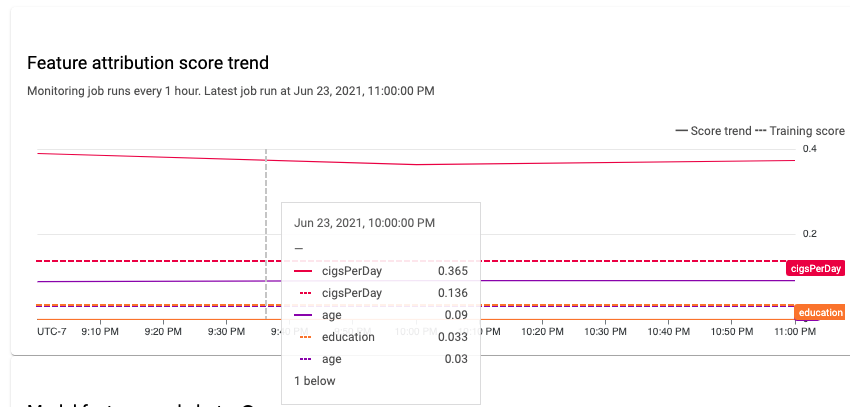
Dans un système de machine learning stable, l'importance relative des caractéristiques reste généralement stable au fil du temps. La baisse de l'importance d'une caractéristique peut indiquer qu'elle a changé. Les causes courantes de dérive ou de décalage au niveau de l'importance des caractéristiques sont les suivantes :
- Modifications des sources de données
- Modifications du schéma de données et de la journalisation
- Modifications du panel d'utilisateurs finaux ou de leur comportement (par exemple, en raison de changements saisonniers ou d'événements aberrants)
- Modifications en amont des caractéristiques générées par un autre modèle de machine learning.
En voici quelques exemples :
- Mises à jour de modèle qui entraînent une augmentation ou une diminution de la couverture (globale ou pour une valeur de classification individuelle)
- Modification des performances du modèle (qui modifie la signification de la caractéristique)
- Mises à jour du pipeline de données, ce qui peut entraîner une diminution de la couverture globale
En outre, tenez compte des points suivants lors de l'analyse des données liées aux décalages et aux dérives d'attribution des caractéristiques :
Effectuer le suivi des caractéristiques les plus importantes. Une modification importante de l'attribution d'une caractéristique signifie que la contribution de la caractéristique à la prédiction a changé. Comme le score de prédiction est égal à la somme des contributions de caractéristiques, une dérive importante d'attribution des caractéristiques les plus importantes indique généralement un décalage important dans les prédictions du modèle.
Surveiller toutes les représentations de caractéristiques. Les attributions des caractéristiques sont toujours numériques, quel que soit le type de caractéristique sous-jacent. En raison de leur nature additive, les attributions d'une caractéristique multidimensionnelle (par exemple, les représentations vectorielles continues) peuvent être réduites à une seule valeur numérique en additionnant les attributions des différentes dimensions. Cela vous permet d'utiliser des méthodes de détection de dérives univariées standards pour tous les types de caractéristiques.
Prendre en compte les interactions entre les caractéristiques. L'attribution d'une caractéristique prend en compte sa contribution à la prédiction, individuellement et par ses interactions avec les autres caractéristiques. Si les interactions d'une caractéristique avec d'autres fonctionnalités changent, la distribution des attributions à une caractéristique change, même si la distribution marginale de la caractéristique reste la même.
Surveiller des groupes de caractéristiques. Comme les attributions sont additives, nous pouvons ajouter des attributions à des caractéristiques associées pour obtenir l'attribution d'un groupe de caractéristiques. Par exemple, dans un modèle d'octroi de crédit, combinez l'attribution de toutes les caractéristiques liées au type de prêt (par exemple, "grade", "sub_grade", "purpose") pour obtenir l'attribution d'un prêt spécifique. Cette attribution au niveau du groupe peut ensuite être suivie pour surveiller les modifications apportées au groupe de caractéristiques.
Étape suivante
- Utilisez Model Monitoring en suivant la documentation de l'API.
- Utilisez l'API Model Monitoring en suivant la documentation de gcloud CLI.
- Essayez l'exemple de notebook dans Colab ou affichez-le sur GitHub.
- Découvrez comment Model Monitoring calcule les écarts entraînement/diffusion et les dérives de prédiction.