La ricerca vettoriale è un potente motore di ricerca vettoriale basato su una tecnologia innovativa sviluppata da Google Research. Sfruttando l'algoritmo ScaNN, la ricerca vettoriale consente di creare sistemi di ricerca e consigli di nuova generazione, nonché applicazioni di IA generativa.
Puoi usufruire della stessa ricerca e della stessa tecnologia alla base dei prodotti Google di base, tra cui la Ricerca Google, YouTube e Google Play. Ciò significa che puoi usufruire della scalabilità, della disponibilità e delle prestazioni di cui ti puoi fidare per gestire set di dati di grandi dimensioni e ottenere risultati rapidissimi su scala globale. Con la ricerca vettoriale hai a disposizione una soluzione di livello enterprise per implementare funzionalità di ricerca semantica all'avanguardia nelle tue applicazioni.
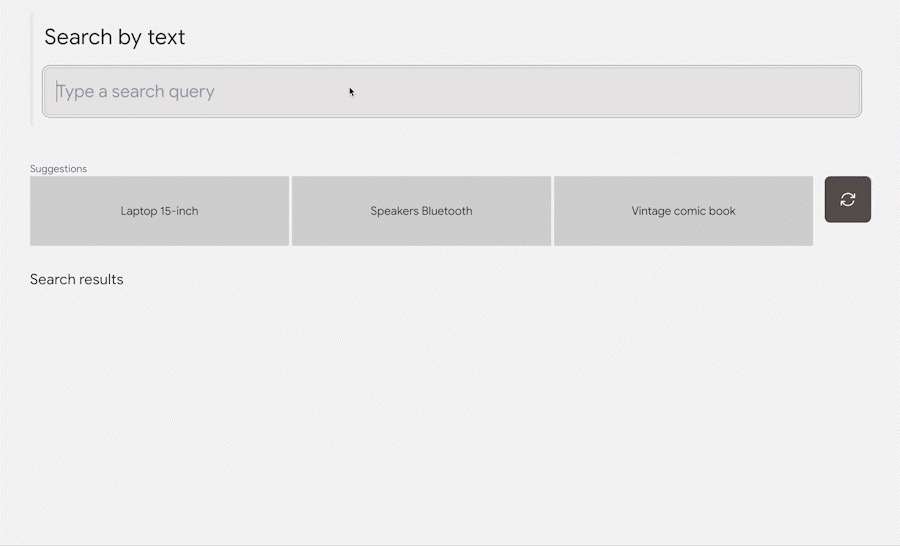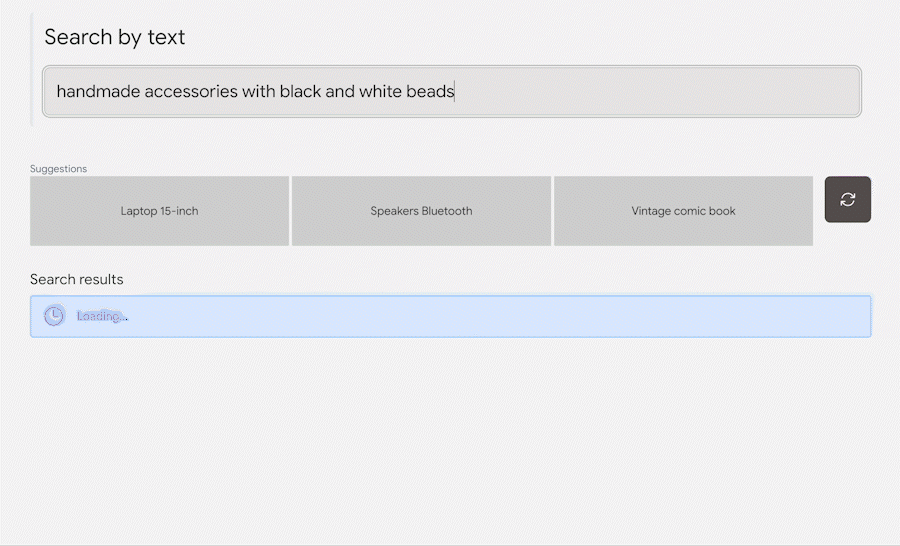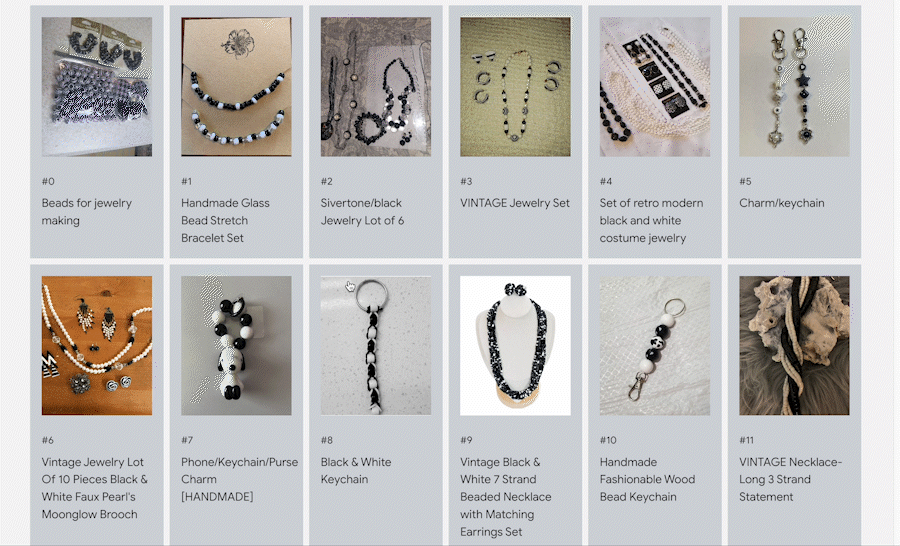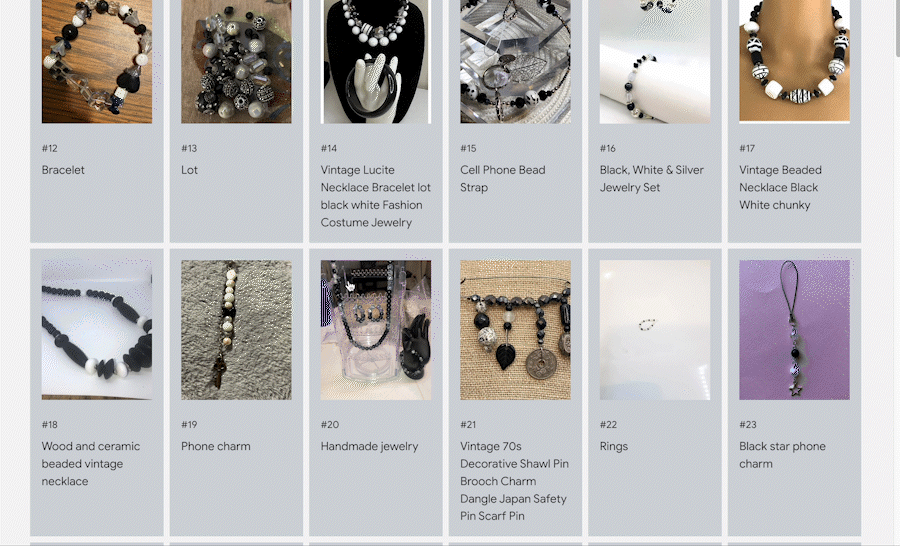
Post del blog: Ricerca multimodale con Vector Search |

|
Infinite Fleurs: scopri la creatività basata sull'IA in piena fioritura |

|
Inizia
Demo interattiva della ricerca vettoriale: guarda la demo dal vivo per un esempio realistico di cosa può fare la tecnologia di ricerca vettoriale e prendi un vantaggio con la ricerca vettoriale.
Guida rapida di Ricerca vettoriale: prova la Ricerca vettoriale in 30 minuti creando, implementando ed eseguendo query su un indice di Ricerca vettoriale utilizzando un set di dati di esempio. Questo tutorial illustra la configurazione, la preparazione dei dati, la creazione di indici, il deployment, l'esecuzione di query e la pulizia.
Prima di iniziare: prepara gli embedding scegliendo e addestrando un modello e preparando i dati. Quindi, scegli un endpoint pubblico o privato in cui eseguire il deployment dell'indice delle query.
Prezzi e calcolatore dei prezzi di Vector Search: i prezzi di Vector Search includono il costo delle macchine virtuali utilizzate per ospitare gli indici di cui è stato eseguito il deployment, nonché le spese per la creazione e l'aggiornamento degli indici. Anche una configurazione minima (meno di 100 $al mese) può supportare una maggiore larghezza di banda per i casi d'uso di dimensioni moderate. Per stimare i costi mensili:
- Vai al Calcolatore prezzi di Google Cloud.
- Fai clic su Aggiungi al preventivo.
- Cerca Vertex AI.
- Fai clic sul pulsante Vertex AI.
- Scegli Vertex AI Vector Search dal menu a discesa Tipo di servizio.
- Mantieni le impostazioni predefinite o configurane di tue. Il costo mensile stimato viene visualizzato nel riquadro Dettagli costi.
Documentazione
Gestire indici ed endpoint
Argomenti avanzati
Casi d'uso e blog
La tecnologia di ricerca vettoriale sta diventando un hub centrale per le aziende che utilizzano l'IA. In modo simile al funzionamento dei database relazionali nei sistemi IT, collega vari elementi aziendali come documenti, contenuti, prodotti, utenti, eventi e altre entità in base alla loro pertinenza. Oltre a cercare contenuti multimediali convenzionali come documenti e immagini, la ricerca vettoriale può anche fornire consigli intelligenti, abbinare i problemi aziendali alle soluzioni e persino collegare gli indicatori IoT agli avvisi di monitoraggio. È uno strumento versatile ed essenziale per navigare nel crescente panorama dei dati aziendali basati sull'IA.
|
Ricerca / retrieval delle informazioni
Sistemi |
In che modo la ricerca vettoriale di Vertex AI contribuisce a sbloccare app di IA generativa ad alte prestazioni: la ricerca vettoriale è alla base di diverse applicazioni, tra cui ecommerce, sistemi RAG e motori di consigli, oltre a chatbot, ricerca multimodale e altro ancora. La ricerca ibrida migliora ulteriormente i risultati per i termini di nicchia. Clienti come Bloomreach, eBay e Mercado Libre utilizzano Vertex AI per le sue prestazioni, la scalabilità e la convenienza, ottenendo vantaggi come una ricerca più rapida e un aumento delle conversioni. eBay utilizza la ricerca vettoriale per i consigli: mette in evidenza il modo in cui eBay utilizza la ricerca vettoriale per il suo sistema di consigli. Questa tecnologia consente a eBay di trovare prodotti simili nel suo vasto catalogo, migliorando l'esperienza utente. Mercari sfrutta la tecnologia di ricerca vettoriale di Google per creare un nuovo marketplace: Spiega in che modo Mercari utilizza la ricerca vettoriale per migliorare la sua nuova piattaforma di marketplace. La Ricerca vettoriale è alla base dei consigli della piattaforma, aiutando gli utenti a trovare prodotti pertinenti in modo più efficace. Vertex AI Embeddings per il testo: grounding dei modelli LLM semplificato: si concentra sul grounding dei modelli LLM utilizzando Vertex AI Embeddings per i dati di testo. La ricerca di vettori svolge un ruolo importante nella ricerca di passaggi di testo pertinenti che garantiscano che le risposte del modello siano basate su informazioni oggettive. Che cos'è la ricerca multimodale: i "LLM con visione" cambiano le attività: illustra la ricerca multimodale, che combina i LLM con la comprensione visiva. Spiega come Vector Search elabora e confronta i dati di testo e di immagini, consentendo esperienze di ricerca più complete. Sblocca la ricerca multimodale su larga scala: combina testo e immagini con Vertex AI: descrive la creazione di un motore di ricerca multimodale con Vertex AI che combina la ricerca di testo e immagini utilizzando un metodo di ensemble basato sul ranking reciproco ponderato. In questo modo, l'esperienza utente viene migliorata e vengono forniti risultati più pertinenti. Scalabilità del recupero avanzato con i consigli di TensorFlow e la ricerca vettoriale: spiega come creare un sistema di consigli per le playlist utilizzando i consigli di TensorFlow e la ricerca vettoriale, che coprono i modelli di recupero avanzato, l'addestramento, il deployment e la scalabilità. |
|
IA generativa: recupero per RAG e agenti |
Vertex AI e Denodo sbloccano i dati aziendali con l'IA generativa: mostra in che modo l'integrazione di Vertex AI con Denodo consente alle aziende di utilizzare l'IA generativa per ottenere approfondimenti dai propri dati. Vector Search è fondamentale per accedere e analizzare in modo efficiente i dati pertinenti all'interno di un ambiente aziendale. Infinite Nature e la natura dei settori: questa demo "selvaggia" mostra le diverse possibilità dell'IA: Mostra una demo che illustra il potenziale dell'IA in diversi settori. Utilizza la Ricerca vettoriale per offrire suggerimenti generativi e ricerca semantica multimodale. Infinite Fleurs: scopri la creatività assistita dall'IA in piena fioritura: Infinite Fleurs di Google, un esperimento di AI che utilizza la ricerca vettoriale, i modelli Gemini e Imagen, genera bouquet di fiori unici in base ai prompt degli utenti. Questa tecnologia mostra il potenziale dell'IA per ispirare la creatività in vari settori. LlamaIndex per RAG su Google Cloud: descrive come utilizzare LlamaIndex per semplificare la Retrieval Augmented Generation (RAG) con modelli linguistici di grandi dimensioni. LlamaIndex utilizza la ricerca vettoriale per recuperare informazioni pertinenti da una knowledge base, ottenendo risposte più accurate e appropriate al contesto. RAG e grounding su Vertex AI: esamina le tecniche RAG e grounding su Vertex AI. La ricerca vettoriale aiuta a identificare informazioni di base pertinenti durante il recupero, il che rende i contenuti generati più accurati e affidabili. Vector Search su LangChain: fornisce una guida all'utilizzo di Vector Search con LangChain per la creazione e il deployment di un indice di database vettoriale per i dati di testo, inclusa la risposta alle domande e l'elaborazione di PDF. |
|
BI, analisi dei dati, monitoraggio e altro ancora |
Abilitazione dell'IA in tempo reale con l'importazione di streaming in Vertex AI: esamina l'aggiornamento in streaming in Vector Search e come fornisce funzionalità di IA in tempo reale. Questa tecnologia consente di elaborare e analizzare in tempo reale gli stream di dati in entrata. |
Risorse correlate
Per iniziare a utilizzare la ricerca vettoriale, puoi utilizzare le seguenti risorse:
- Notebook e soluzioni
- Tutorial e formazione
- Prodotti correlati
- Materiale approfondito sugli approfondimenti
Notebook e soluzioni

|
|
|
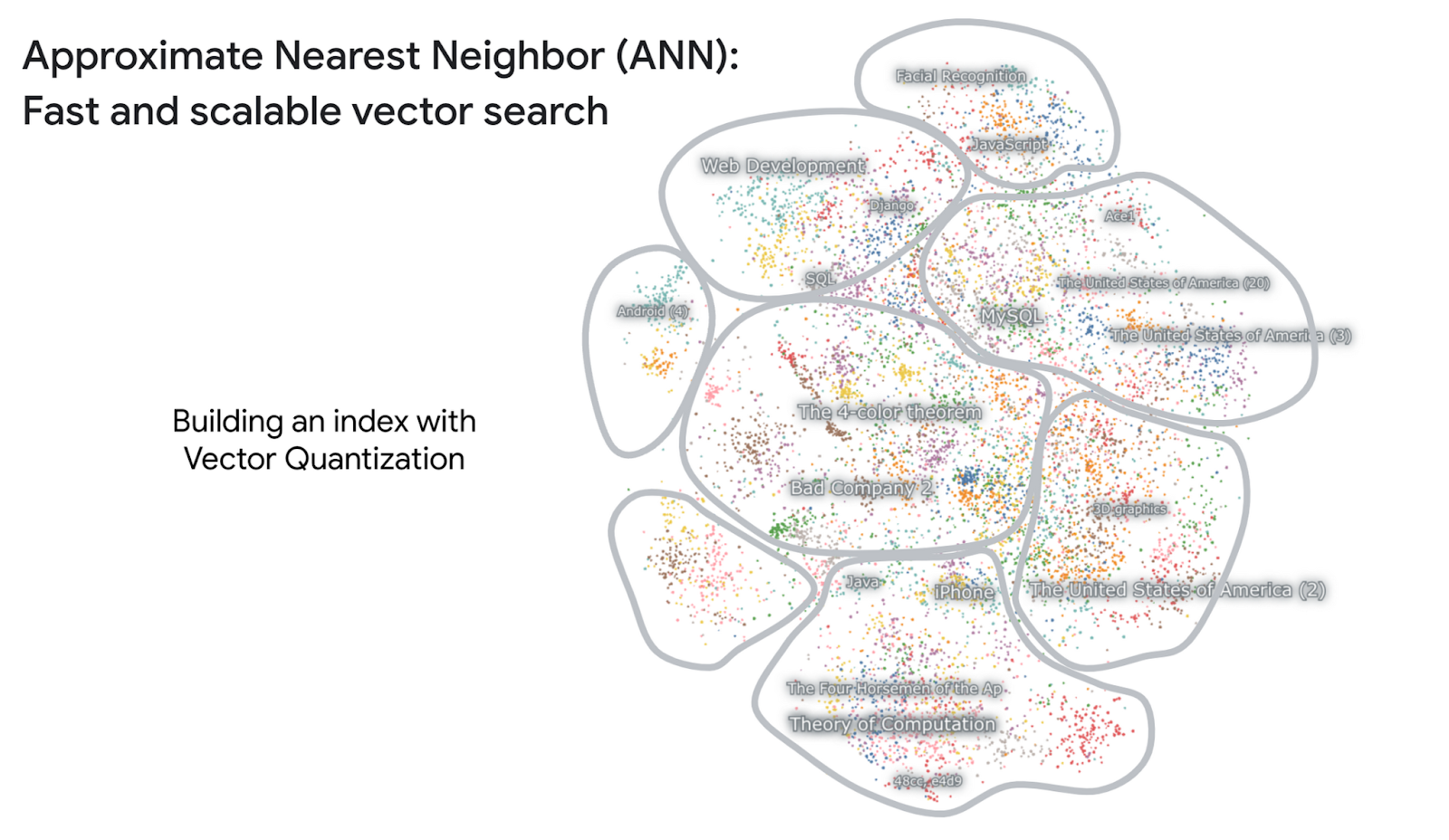
Guida rapida a Vertex AI Vector Search: fornisce una panoramica di Vector Search. È progettato per gli utenti che non hanno mai utilizzato la piattaforma e vogliono iniziare rapidamente. |
Iniziare a utilizzare gli embedding di testo e la ricerca vettoriale: illustra gli embedding di testo e la ricerca vettoriale. Spiega come funzionano queste tecnologie e come possono essere utilizzate per migliorare i risultati di ricerca. |

|
|
|
Combinazione di ricerca semantica e per parole chiave: un tutorial sulla ricerca ibrida con Vertex AI Vector Search: fornisce istruzioni su come utilizzare Vector Search per la ricerca ibrida. Descrive i passaggi necessari per impostare e configurare un sistema di ricerca ibrido. |
Motore RAG di Vertex AI con Ricerca vettoriale: Esplora l'utilizzo del motore RAG di Vertex AI con la ricerca vettoriale. Vengono descritti i vantaggi dell'utilizzo combinato di queste due tecnologie e vengono forniti esempi di come possono essere utilizzate in applicazioni reali. |
|
|
|
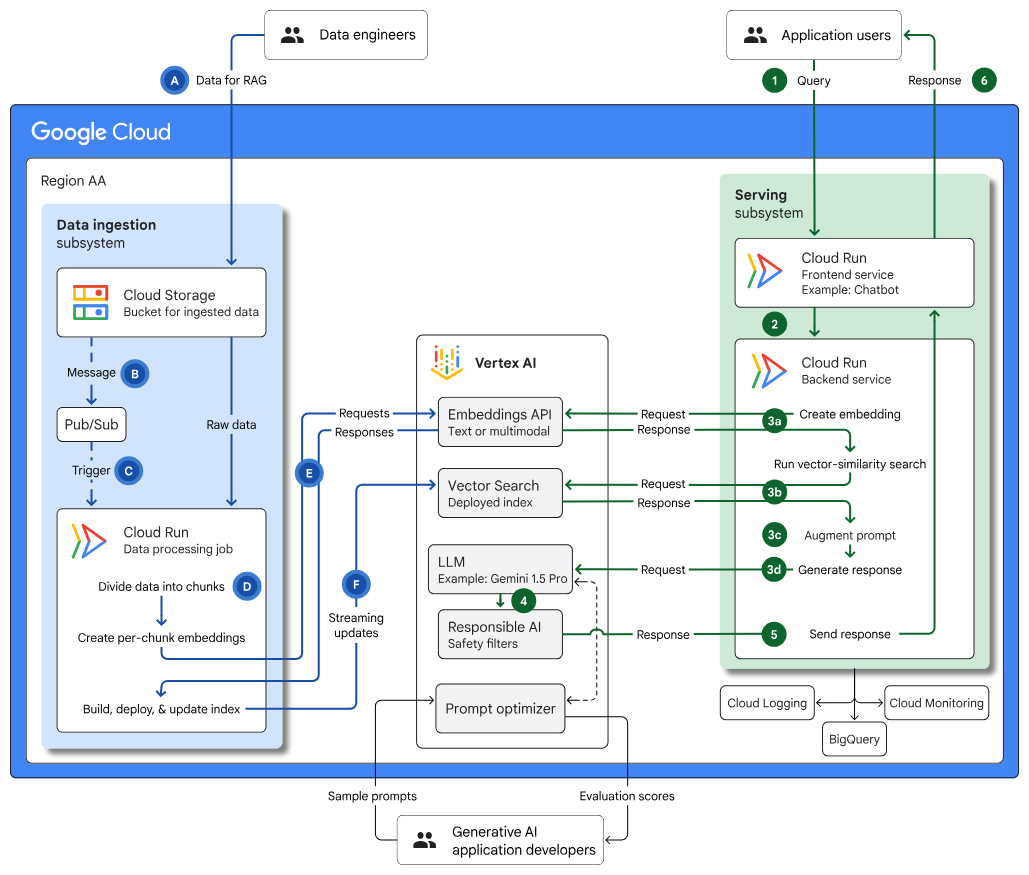
Infrastruttura per un'applicazione di AI generativa compatibile con RAG che utilizza Vertex AI e Vector Search: descrive in dettaglio l'architettura per la creazione di un'applicazione di AI generativa e RAG utilizzando Vector Search, Cloud Run e Cloud Storage, coprendo casi d'uso, scelte di progettazione e considerazioni chiave. |
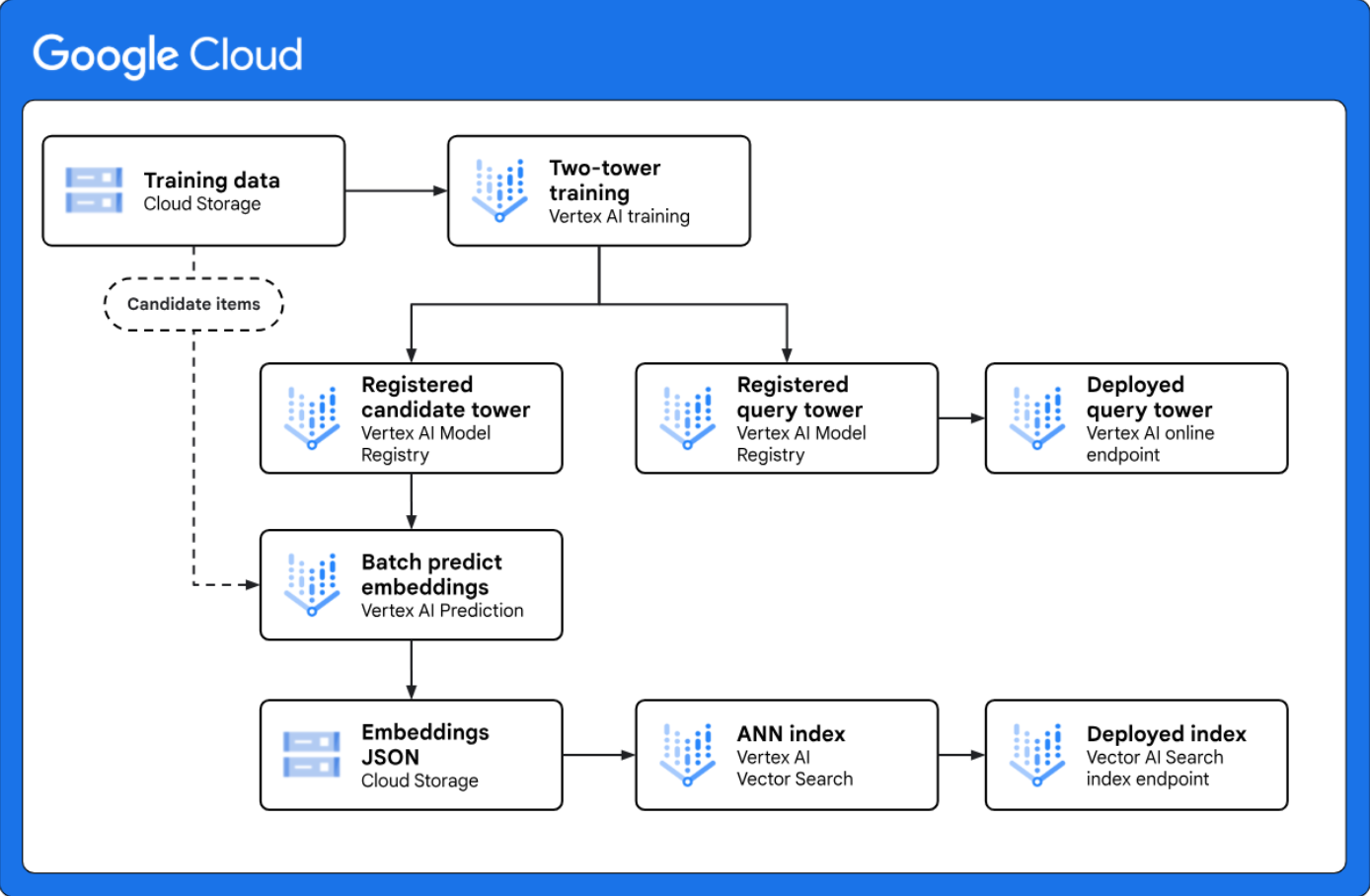
<p"> Implementa il recupero a due torri per la generazione di candidati su larga scala: fornisce un'architettura di riferimento che mostra come implementare un flusso di lavoro end-to-end di generazione di candidati a due torri con Vertex AI. Il framework di modellazione a due torri è una potente tecnica di recupero per i casi d'uso di personalizzazione perché apprende la somiglianza semantica tra due entità diverse, come query web e articoli candidati. </p"> |
Formazione
Introduzione alla ricerca vettoriale e agli incorporamenti La ricerca vettoriale viene utilizzata per trovare elementi simili o correlati. Può essere utilizzato per consigli, ricerca, chatbot e classificazione del testo. Il processo prevede la creazione di incorporamenti, il loro caricamento su Google Cloude la loro indicizzazione per le query. Questo lab si concentra sugli embedding di testo utilizzando Vertex AI, ma gli embedding possono essere generati per altri tipi di dati.
Ricerca vettoriale e embedding Questo corso introduce la ricerca vettoriale e descrive come può essere impiegata per creare un'applicazione di ricerca con API per modelli linguistici di grandi dimensioni (LLM) per gli embedding. Il corso è composto da lezioni concettuali su Vector Search e sugli embedding di testo, demo pratiche su come creare Vector Search su Vertex AI e un lab pratico.
Comprendere e applicare gli embedding di testo
L'API Vertex AI Embeddings genera embedding di testo, ovvero
rappresentazioni numeriche del testo utilizzate per attività come l'identificazione di elementi simili.
In questo corso utilizzerai gli embedding di testo per attività come la classificazione e la ricerca semantica e combinerai la ricerca semantica con gli LLM per creare sistemi di risposta alle domande utilizzando Vertex AI.
Machine Learning Crash Course: Embeddings Questo corso introduce le rappresentazioni distribuite di parole, mettendole a confronto con le rappresentazioni sparse. Esplora i metodi per ottenere gli embedding e distingue tra embedding statici e contestuali.
Prodotti correlati
Vertex AI Embeddings Fornisce una panoramica dell'API Embeddings. Casi d'uso di incorporamento di testo e multimodale, insieme a link a risorse aggiuntive e servizi Google Cloud correlati.
API di ranking per le applicazioni di IA L'API di ranking assegna un nuovo ranking ai documenti in base alla pertinenza a una query utilizzando un modello linguistico preaddestrato, fornendo punteggi precisi. È ideale per migliorare i risultati di ricerca provenienti da varie fonti, tra cui la ricerca vettoriale.
Vertex AI Feature Store Ti consente di gestire e pubblicare i dati delle funzionalità utilizzando BigQuery come origine dati. Esegue il provisioning delle risorse per il servizio online, fungendo da livello di metadati per pubblicare gli ultimi valori delle funzionalità direttamente da BigQuery. Feature Store consente di recuperare istantaneamente i valori delle caratteristiche per gli elementi restituiti da Vector Store per le query.
Vertex AI Pipelines Vertex AI Pipelines consente l'automazione, il monitoraggio e la governance degli impianti di ML in modo serverless orchestrando i flussi di lavoro di ML con le pipeline di ML. Puoi eseguire in batch le pipeline di ML definite utilizzando Kubeflow Pipelines o il framework TensorFlow Extended (TFX). Pipelines consente di creare pipeline automatiche per generare embedding, creare e aggiornare gli indici di ricerca di vettori e formare una configurazione MLOps per i sistemi di ricerca e consigli di produzione.
Risorse di approfondimento
Miglioramento del caso d'uso dell'IA generativa con gli incorporamenti e i tipi di attività di Vertex AI Si concentra sul miglioramento delle applicazioni di IA generativa che utilizzano gli incorporamenti e i tipi di attività di Vertex AI. La ricerca vettoriale può essere utilizzata con gli incorporamenti di tipo di attività per migliorare il contesto e l'accuratezza dei contenuti generati trovando informazioni più pertinenti.
TensorFlow Recommenders Una libreria open source per la creazione di sistemi di consigli. Semplifica il processo dalla preparazione dei dati al deployment e supporta la creazione di modelli flessibili. TFRS offre tutorial e risorse e consente la creazione di modelli di consigli sofisticati.
TensorFlow Ranking TensorFlow Ranking è una libreria open source per la creazione di modelli di apprendimento per il ranking (LTR) neurali scalabili. Supporta varie funzioni di perdita e metriche di ranking, con applicazioni in ricerca, consigli e altri campi. La libreria è sviluppata attivamente dall'IA di Google.
Annuncio di ScaNN: ricerca di similarità vettoriale efficiente ScaNN di Google, un algoritmo per la ricerca di similarità vettoriale efficiente, utilizza una nuova tecnica per migliorare l'accuratezza e la velocità nella ricerca dei vicini più prossimi. Ha un rendimento migliore rispetto ai metodi esistenti e ha ampie applicazioni nelle attività di machine learning che richiedono la ricerca semantica. Le attività di ricerca di Google abbracciano varie aree, tra cui l'IA di base e gli impatti sociali dell'IA.
SOAR: nuovi algoritmi per una ricerca vettoriale ancora più veloce con ScaNN L'algoritmo SOAR di Google migliora l'efficienza della ricerca vettoriale introducendo la ridondanza controllata, che consente ricerche più rapide con indici più piccoli. SOAR assegna i vettori a più cluster, creando percorsi di ricerca di "backup" per migliorare il rendimento.
Video correlati
Inizia a utilizzare Ricerca vettoriale con Vertex AI
La ricerca vettoriale è uno strumento potente per creare applicazioni basate sull'IA. Questo video presenta la tecnologia e fornisce una guida passo passo per iniziare.
Scopri la ricerca ibrida con la ricerca vettoriale
La ricerca vettoriale può essere utilizzata per la ricerca ibrida, consentendoti di combinare la potenza della ricerca vettoriale con la flessibilità e la velocità di un motore di ricerca convenzionale. Questo video introduce la ricerca ibrida e mostra come utilizzare la ricerca vettoriale per la ricerca ibrida.
Utilizzi già la ricerca di icone. Ecco come diventare un esperto
Sapevi che probabilmente usi la ricerca di vettori ogni giorno senza rendertene conto? Dalla ricerca di un prodotto introvabile sui social media al rintracciamento di un brano che non riesci a toglierti dalla testa, la ricerca di vettori è la magia dell'AI alla base di queste esperienze quotidiane.
Il nuovo embedding "tipo di attività" del team di DeepMind migliora la qualità della ricerca RAG
Migliora la precisione e la pertinenza dei tuoi sistemi RAG con nuovi embedding di tipo di attività sviluppati dal team di Google DeepMind. Guarda il video e scopri le sfide comuni nella qualità della ricerca RAG e come gli incorporamenti dei tipi di attività possono colmare efficacemente il divario semantico tra domande e risposte, portando a un recupero più efficace e a un miglioramento delle prestazioni di RAG.
Terminologia di Vector Search
Questo elenco contiene alcune terminologie importanti che devi conoscere per utilizzare la ricerca vettoriale:
Vettore: un vettore è un elenco di valori float con grandezza e direzione. Può essere utilizzato per rappresentare qualsiasi tipo di dati, ad esempio numeri, punti nello spazio e indicazioni stradali.
Incorporamento: un incorporamento è un tipo di vettore utilizzato per rappresentare i dati in modo da coglierne il significato semantico. In genere, gli embedding vengono creati utilizzando tecniche di machine learning e vengono spesso utilizzati nell'elaborazione del linguaggio naturale (NLP) e in altre applicazioni di machine learning.
Inserimenti densi: rappresentano il significato semantico del testo utilizzando array che contengono principalmente valori diversi da zero. Con gli embedding di densità elevata, è possibile restituire risultati di ricerca simili in base alla somiglianza semantica.
Embedding sparsi: gli embedding sparsi rappresentano la sintassi del testo, utilizzando array di dimensioni elevate che contengono pochissimi valori diversi da zero rispetto agli embedding densi. Gli embedding sparsi vengono spesso utilizzati per le ricerche di parole chiave.
Ricerca ibrida: la ricerca ibrida utilizza sia embedding densi che sparsi, il che consente di eseguire ricerche in base a una combinazione di ricerca per parole chiave e ricerca semantica. La ricerca vettoriale supporta la ricerca basata su embedding densi, embedding sparsi e ricerca ibrida.
Indice: una raccolta di vettori implementati insieme per la ricerca di similarità. I vettori possono essere aggiunti o rimossi da un indice. Le query di ricerca di somiglianza vengono inviate a un indice specifico e cercano i vettori in quell'indice.
Dati empirici reali: un termine che si riferisce alla verifica dell'accuratezza del machine learning rispetto al mondo reale, ad esempio un set di dati di dati empirici reali.
Richiamo: la percentuale di vicini più vicini restituiti dall'indice che sono effettivamente veri vicini più vicini. Ad esempio, se una query sul vicino più prossimo per 20 vicini più prossimi ha restituito 19 dei vicini più prossimi del vero e proprio, il richiamo è 19/20 x 100 = 95%.
Limita: funzionalità che limita le ricerche a un sottoinsieme dell'indice utilizzando regole booleane. La limitazione è indicata anche come "filtro". Con la ricerca vettoriale, puoi utilizzare i filtri numerici e di attributi di testo.