以下目标部分包含有关数据要求、输入/输出架构文件以及架构定义的数据导入文件(JSON 行和 CSV)的信息。
权限
如需使用 Cloud Storage 存储桶中的映像,您必须为 Vertex AI Service Agent 授予该存储桶的 Storage Object Viewer 角色。Service Agent 是 Google 托管式服务账号,Vertex AI 会使用该账号代表您访问您的数据。如需查看更详细的说明,请参阅 Service Agent。
对象检测
数据要求
| 常规图片要求 | |
|---|---|
| 支持的文件类型 |
|
| 图片类型 | AutoML 模型针对真实物体的照片进行了优化。 |
| 训练图片文件大小 (MB) | 大小上限为 30MB。 |
| 预测图片文件* 大小 (MB) | 大小上限为 1.5MB。 |
| 图片大小(像素) | 建议最大值为 1024×1024 像素。 对于大小超过 1024×1024 像素很多的图片,在 Vertex AI 的图片标准化过程中,图片质量可能会在一定程度上受损。 |
| 标签和边界框要求 | |
|---|---|
| 以下要求适用于训练 AutoML 模型的数据集。 | |
| 用于训练的标签实例 | 最少 10 个注释(实例)。 |
| 注释要求 | 对于每个标签,您必须至少拥有 10 张图片,每张图片至少具有 1 个注释(边界框和标签)。 不过,出于模型训练目的,建议您对每个标签使用约 1000 个注释。一般情况下,每个标签对应的图片越多,模型的表现就越好。 |
| 标签比例(最常见标签与最不常见标签的比例): | 如果最常见标签下的图片数量不超过最不常见标签下图片数量的 100 倍,则模型效果最佳。 出于模型性能考虑,我们建议您移除出现频率极低的标签。 |
| 边界框边长 | 至少为图片边长×0.01。例如,1000×900 像素的图片需要至少 10×9 像素的边界框。 边界框最小尺寸:8 x 8 像素。 |
| 以下要求适用于用于训练 AutoML 或自定义训练的模型的数据集。 | |
| 每个不同图片的边界框数 | 最大值为 500。 |
| 从预测请求返回的边界框 | 默认值为 100,最大值为 500。 |
| 训练数据和数据集要求 | |
|---|---|
| 以下要求适用于训练 AutoML 模型的数据集。 | |
| 训练图片特征 | 训练数据应尽可能接近要对其执行预测的数据。 例如,如果您的使用场景涉及模糊的低分辨率图片(例如来自监控摄像头的图片),则训练数据应由模糊的低分辨率图片组成。 一般来说,您还应该考虑为训练图片提供多种角度、分辨率和背景。 Vertex AI 模型通常不能预测人类无法分配的标签。因此,如果一个人经过训练,仍无法在观察图片 1-2 秒后分配标签,那么模型可能也无法通过训练达到此目的。 |
| 内部图片预处理 | 导入图片后,Vertex AI 会对数据执行预处理。预处理的图片是训练模型时使用的实际数据。 当图片的最小边缘大于 1024 像素时,便会进行图片预处理(尺寸调整)。如果图片的较小边大于 1024 像素,则较小的边会被缩小为 1024 像素。较长的侧边和指定的边界框按比例缩小为与较小边相同的量。因此,如果任何缩减的注释(边界框和标签)小于 8 像素 × 8 像素,则系统会将其移除。 边长小于 1024 像素的图片不符合预处理大小要求。 |
| 以下要求适用于用于训练 AutoML 或自定义训练的模型的数据集。 | |
| 每个数据集中的图片数 | 最大值:150000 |
| 每个数据集中的注释边界框总数 | 最大值:1000000 |
| 每个数据集中的标签数 | 最小值:1;最大值:1000 |
YAML 架构文件
使用以下可公开访问的架构文件导入图片对象检测注解(边界框和标签)。此架构文件规定数据输入文件的格式。此文件的结构遵循 OpenAPI 架构。
gs://google-cloud-aiplatform/schema/dataset/ioformat/image_bounding_box_io_format_1.0.0.yaml
完整架构文件
title: ImageBoundingBox description: > Import and export format for importing/exporting images together with bounding box annotations. Can be used in Dataset.import_schema_uri field. type: object required: - imageGcsUri properties: imageGcsUri: type: string description: > A Cloud Storage URI pointing to an image. Up to 30MB in size. Supported file mime types: `image/jpeg`, `image/gif`, `image/png`, `image/webp`, `image/bmp`, `image/tiff`, `image/vnd.microsoft.icon`. boundingBoxAnnotations: type: array description: Multiple bounding box Annotations on the image. items: type: object description: > Bounding box anntoation. `xMin`, `xMax`, `yMin`, and `yMax` are relative to the image size, and the point 0,0 is in the top left of the image. properties: displayName: type: string description: > It will be imported as/exported from AnnotationSpec's display name, i.e. the name of the label/class. xMin: description: The leftmost coordinate of the bounding box. type: number format: double xMax: description: The rightmost coordinate of the bounding box. type: number format: double yMin: description: The topmost coordinate of the bounding box. type: number format: double yMax: description: The bottommost coordinate of the bounding box. type: number format: double annotationResourceLabels: description: Resource labels on the Annotation. type: object additionalProperties: type: string dataItemResourceLabels: description: Resource labels on the DataItem. type: object additionalProperties: type: string
输入文件
JSON 行
每行上的 JSON 代码:
{
"imageGcsUri": "gs://bucket/filename.ext",
"boundingBoxAnnotations": [
{
"displayName": "OBJECT1_LABEL",
"xMin": "X_MIN",
"yMin": "Y_MIN",
"xMax": "X_MAX",
"yMax": "Y_MAX",
"annotationResourceLabels": {
"aiplatform.googleapis.com/annotation_set_name": "displayName",
"env": "prod"
}
},
{
"displayName": "OBJECT2_LABEL",
"xMin": "X_MIN",
"yMin": "Y_MIN",
"xMax": "X_MAX",
"yMax": "Y_MAX"
}
],
"dataItemResourceLabels": {
"aiplatform.googleapis.com/ml_use": "test/train/validation"
}
}字段说明:
imageGcsUri- 唯一的必填字段。annotationResourceLabels- 可以包含任意数量的键值对字符串。系统保留的唯一键值对如下:- "aiplatform.googleapis.com/annotation_set_name" : "value"
其中 value 是数据集中现有注释集的显示名之一。
dataItemResourceLabels- 可以包含任意数量的键值对字符串。下面是唯一的系统预留键值对,用于指定数据项的机器学习使用集:- "aiplatform.googleapis.com/ml_use" : "training/test/validation"
示例 JSON 行 - object_detection.jsonl:
{"imageGcsUri": "gs://bucket/filename1.jpeg", "boundingBoxAnnotations": [{"displayName": "Tomato", "xMin": "0.3", "yMin": "0.3", "xMax": "0.7", "yMax": "0.6"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "test"}}
{"imageGcsUri": "gs://bucket/filename2.gif", "boundingBoxAnnotations": [{"displayName": "Tomato", "xMin": "0.8", "yMin": "0.2", "xMax": "1.0", "yMax": "0.4"},{"displayName": "Salad", "xMin": "0.0", "yMin": "0.0", "xMax": "1.0", "yMax": "1.0"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "training"}}
{"imageGcsUri": "gs://bucket/filename3.png", "boundingBoxAnnotations": [{"displayName": "Baked goods", "xMin": "0.5", "yMin": "0.7", "xMax": "0.8", "yMax": "0.8"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "training"}}
{"imageGcsUri": "gs://bucket/filename4.tiff", "boundingBoxAnnotations": [{"displayName": "Salad", "xMin": "0.1", "yMin": "0.2", "xMax": "0.8", "yMax": "0.9"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "validation"}}
...CSV
CSV 格式:
[ML_USE],GCS_FILE_PATH,[LABEL],[BOUNDING_BOX]*
ML_USE(可选)。在训练模型时用于拆分数据。使用训练、测试或验证。如需详细了解手动数据拆分,请参阅 AutoML 模型的数据拆分简介。GCS_FILE_PATH- 此字段包含图片的 Cloud Storage URI。Cloud Storage URI 区分大小写。LABEL(可选) - 标签必须以字母开头,且只能包含字母、数字和下划线。BOUNDING_BOX。图片中对象的边界框。指定边界框涉及多个列。
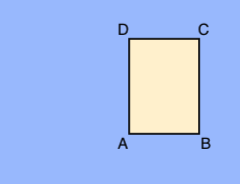
A。X_MIN,Y_MIN
B。X_MAX,Y_MIN
C。X_MAX,Y_MAX
D。X_MIN,Y_MAX每个顶点由 x、y 坐标值指定。坐标是标准化浮点值 [0,1]; 0.0 表示 X_MIN 或 Y_MIN,1.0 为 X_MAX 或 Y_MAX。
例如,整个图片的边界框表示为 (0.0,0.0,,,1.0,1.0,,) 或 (0.0,0.0,1.0,0.0,1.0,1.0,0.0,1.0)。
可以通过以下两种方式之一指定对象的边界框:
- 两个矩形(两组 x,y 坐标),它们是矩形的对角点。
A。X_MIN,Y_MIN
C。X_MAX,Y_MAX
(如下例所示):
A、C、X_MIN,Y_MIN,,,X_MAX,Y_MAX,, - 指定全部四个顶点,如下所示:
X_MIN,Y_MIN,X_MAX,Y_MIN, X_MAX,Y_MAX,X_MIN,Y_MAX,
如果指定的四个顶点未形成与图片边缘平行的矩形,Vertex AI 会指定可形成此类矩形的顶点。
- 两个矩形(两组 x,y 坐标),它们是矩形的对角点。
CSV 示例 - object_detection.csv:
test,gs://bucket/filename1.jpeg,Tomato,0.3,0.3,,,0.7,0.6,,
training,gs://bucket/filename2.gif,Tomato,0.8,0.2,,,1.0,0.4,,
gs://bucket/filename2.gif
gs://bucket/filename3.png,Baked goods,0.5,0.7,0.8,0.7,0.8,0.8,0.5,0.8
validation,gs://bucket/filename4.tiff,Salad,0.1,0.2,,,0.8,0.9,,
...