As inferências em lote são pedidos assíncronos que pedem inferências diretamente do recurso do modelo sem necessidade de implementar o modelo num ponto final.
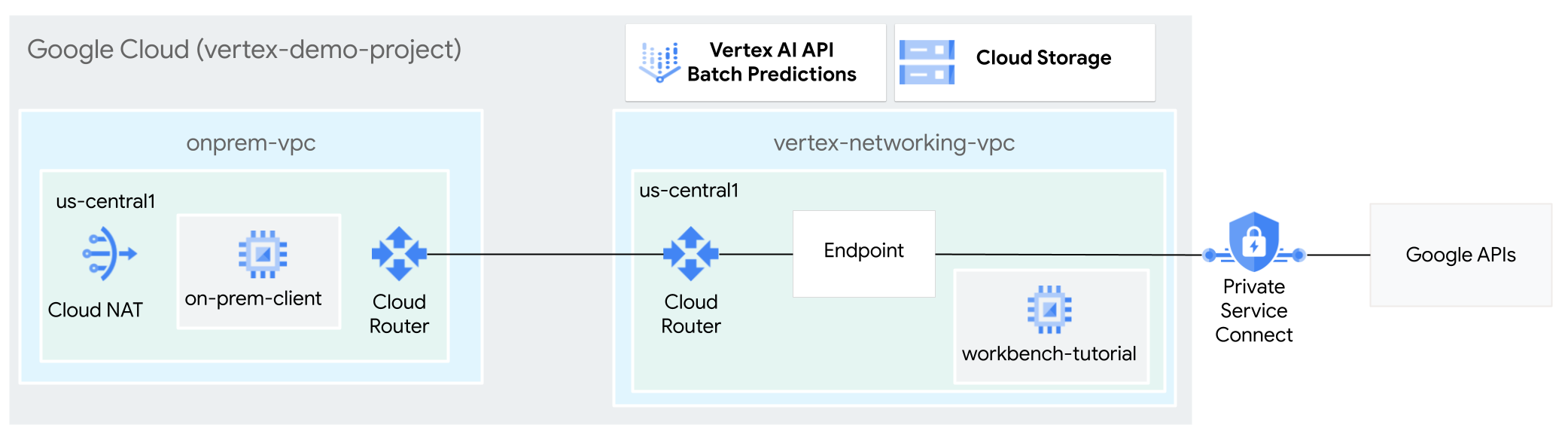
Neste tutorial, vai usar a VPN de alta disponibilidade (VPN de HA) para enviar pedidos de inferência em lote a um modelo preparado de forma privada, entre duas redes da nuvem virtual privada que podem servir de base para a conetividade privada multinuvem e no local.
Este tutorial destina-se a administradores de redes empresariais, cientistas de dados e investigadores que estão familiarizados com o Vertex AI, a nuvem virtual privada (VPC), a Google Cloud consola e oCloud Shell. A familiaridade com o Vertex AI Workbench é útil, mas não obrigatória.
Objetivos
- Crie duas redes da nuvem virtual privada (VPC), conforme mostrado no diagrama
anterior:
- Uma (
vertex-networking-vpc) destina-se ao acesso às APIs Google para inferência em lote. - O outro (
onprem-vpc) representa uma rede nas instalações.
- Uma (
- Implemente gateways de VPN de alta disponibilidade, túneis de Cloud VPN e Cloud Routers para ligar
vertex-networking-vpceonprem-vpc. - Crie um modelo de inferência em lote do Vertex AI e carregue-o para um contentor do Cloud Storage.
- Crie um ponto final do Private Service Connect (PSC) para encaminhar pedidos privados para a API REST de inferência em lote da Vertex AI.
- Configure o modo de anúncio personalizado do Cloud Router em
vertex-networking-vpcpara anunciar rotas para o ponto final do Private Service Connect paraonprem-vpc. - Crie uma instância de VM do Compute Engine em
onprem-vpcpara representar uma aplicação cliente (on-prem-client) que envia pedidos de inferência em lote de forma privada através da VPN de alta disponibilidade.
Custos
Neste documento, usa os seguintes componentes faturáveis do Google Cloud:
Para gerar uma estimativa de custos com base na sua utilização projetada,
use a calculadora de preços.
Quando terminar as tarefas descritas neste documento, pode evitar a faturação contínua eliminando os recursos que criou. Para mais informações, consulte o artigo Limpe.
Antes de começar
-
In the Google Cloud console, go to the project selector page.
-
Select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- Abra o Cloud Shell para executar os comandos indicados neste tutorial. O Cloud Shell é um ambiente de shell interativo para Google Cloud que lhe permite gerir os seus projetos e recursos a partir do navegador de Internet.
- No Cloud Shell, defina o projeto atual para o seu
Google Cloud ID do projeto e armazene o mesmo
ID do projeto na variável do shell
projectid:projectid="PROJECT_ID" gcloud config set project ${projectid} - Se não for o proprietário do projeto, peça-lhe que lhe conceda a função de administrador de IAM do projeto (roles/resourcemanager.projectIamAdmin). Tem de ter esta função para conceder funções da IAM no passo seguinte.
-
Make sure that you have the following role or roles on the project: roles/compute.instanceAdmin.v1, roles/compute.networkAdmin, roles/compute.securityAdmin, roles/dns.admin, roles/iap.tunnelResourceAccessor, roles/notebooks.admin, roles/iam.serviceAccountAdmin, roles/iam.serviceAccountUser, roles/servicedirectory.editor, roles/serviceusage.serviceUsageAdmin, roles/storage.admin, roles/aiplatform.admin, roles/aiplatform.user, roles/resourcemanager.projectIamAdmin
Check for the roles
-
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
-
In the Principal column, find all rows that identify you or a group that you're included in. To learn which groups you're included in, contact your administrator.
- For all rows that specify or include you, check the Role column to see whether the list of roles includes the required roles.
Grant the roles
-
In the Google Cloud console, go to the IAM page.
Aceder ao IAM - Selecione o projeto.
- Clique em Conceder acesso.
-
No campo Novos responsáveis, introduza o identificador do utilizador. Normalmente, este é o endereço de email de uma Conta Google.
- Na lista Selecionar uma função, selecione uma função.
- Para conceder funções adicionais, clique em Adicionar outra função e adicione cada função adicional.
- Clique em Guardar.
Enable the DNS, Artifact Registry, IAM, Compute Engine, Notebooks, and Vertex AI APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Crie as redes VPC
Nesta secção, cria duas redes VPC: uma para aceder às APIs Google para inferência em lote e outra para simular uma rede no local. Em cada uma das duas redes VPC, cria um Cloud Router e um gateway Cloud NAT. Um gateway Cloud NAT oferece conetividade de saída para instâncias de máquinas virtuais (VM) do Compute Engine sem endereços IP externos.
Crie a
vertex-networking-vpcrede de VPC:gcloud compute networks create vertex-networking-vpc \ --subnet-mode customNa rede
vertex-networking-vpc, crie uma sub-rede denominadaworkbench-subnetcom um intervalo IPv4 principal de10.0.1.0/28:gcloud compute networks subnets create workbench-subnet \ --range=10.0.1.0/28 \ --network=vertex-networking-vpc \ --region=us-central1 \ --enable-private-ip-google-accessCrie a rede VPC para simular a rede no local (
onprem-vpc):gcloud compute networks create onprem-vpc \ --subnet-mode customNa rede
onprem-vpc, crie uma sub-rede denominadaonprem-vpc-subnet1com um intervalo IPv4 principal de172.16.10.0/29:gcloud compute networks subnets create onprem-vpc-subnet1 \ --network onprem-vpc \ --range 172.16.10.0/29 \ --region us-central1
Verifique se as redes VPC estão configuradas corretamente
Na Google Cloud consola, aceda ao separador Redes no projeto atual na página Redes de VPC.
Na lista de redes VPC, verifique se as duas redes foram criadas:
vertex-networking-vpceonprem-vpc.Clique no separador Sub-redes no projeto atual.
Na lista de sub-redes da VPC, verifique se as sub-redes
workbench-subneteonprem-vpc-subnet1foram criadas.
Configure a conetividade híbrida
Nesta secção, cria dois gateways de VPN de HA que estão ligados entre si. Uma reside na
vertex-networking-vpc rede VPC. O outro reside na rede VPC onprem-vpc. Cada gateway contém um Cloud Router e um par de túneis VPN.
Crie os gateways de VPN de alta disponibilidade
No Cloud Shell, crie o gateway de VPN de alta disponibilidade para a rede VPC
vertex-networking-vpc:gcloud compute vpn-gateways create vertex-networking-vpn-gw1 \ --network vertex-networking-vpc \ --region us-central1Crie o gateway de VPN de alta disponibilidade para a rede VPC:
onprem-vpcgcloud compute vpn-gateways create onprem-vpn-gw1 \ --network onprem-vpc \ --region us-central1Na Google Cloud consola, aceda ao separador Gateways de VPN do Cloud na página VPN.
Verifique se os dois gateways (
vertex-networking-vpn-gw1eonprem-vpn-gw1) foram criados e se cada gateway tem dois endereços IP de interface.
Crie routers do Cloud Router e gateways do Cloud NAT
Em cada uma das duas redes VPC, cria dois Cloud Routers: um geral e um regional. Em cada um dos Cloud Routers regionais, cria um gateway NAT na nuvem. As gateways NAT na nuvem oferecem conetividade de saída para instâncias de máquinas virtuais (VM) do Compute Engine que não têm endereços IP externos.
No Cloud Shell, crie um Cloud Router para a rede VPC:
vertex-networking-vpcgcloud compute routers create vertex-networking-vpc-router1 \ --region us-central1\ --network vertex-networking-vpc \ --asn 65001Crie um Cloud Router para a rede de VPC
onprem-vpc:gcloud compute routers create onprem-vpc-router1 \ --region us-central1\ --network onprem-vpc\ --asn 65002Crie um Cloud Router regional para a rede VPC:
vertex-networking-vpcgcloud compute routers create cloud-router-us-central1-vertex-nat \ --network vertex-networking-vpc \ --region us-central1Configure uma gateway do Cloud NAT no Cloud Router regional:
gcloud compute routers nats create cloud-nat-us-central1 \ --router=cloud-router-us-central1-vertex-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1Crie um Cloud Router regional para a rede VPC:
onprem-vpcgcloud compute routers create cloud-router-us-central1-onprem-nat \ --network onprem-vpc \ --region us-central1Configure uma gateway do Cloud NAT no Cloud Router regional:
gcloud compute routers nats create cloud-nat-us-central1-on-prem \ --router=cloud-router-us-central1-onprem-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1Na Google Cloud consola, aceda à página Routers na nuvem.
Na lista Routers do Cloud Router, verifique se os seguintes routers foram criados:
cloud-router-us-central1-onprem-natcloud-router-us-central1-vertex-natonprem-vpc-router1vertex-networking-vpc-router1
Pode ter de atualizar o separador do navegador da Google Cloud consola para ver os novos valores.
Na lista de routers do Cloud Router, clique em
cloud-router-us-central1-vertex-nat.Na página Detalhes do router, verifique se o gateway
cloud-nat-us-central1Cloud NAT foi criado.Clique na seta de retrocesso para regressar à página Cloud Routers.
Na lista de routers, clique em
cloud-router-us-central1-onprem-nat.Na página Detalhes do router, verifique se o gateway do Cloud NAT foi criado.
cloud-nat-us-central1-on-prem
Crie túneis de VPN
No Cloud Shell, na rede
vertex-networking-vpc, crie um túnel de VPN denominadovertex-networking-vpc-tunnel0:gcloud compute vpn-tunnels create vertex-networking-vpc-tunnel0 \ --peer-gcp-gateway onprem-vpn-gw1 \ --region us-central1 \ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router vertex-networking-vpc-router1 \ --vpn-gateway vertex-networking-vpn-gw1 \ --interface 0Na rede
vertex-networking-vpc, crie um túnel de VPN denominadovertex-networking-vpc-tunnel1:gcloud compute vpn-tunnels create vertex-networking-vpc-tunnel1 \ --peer-gcp-gateway onprem-vpn-gw1 \ --region us-central1 \ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router vertex-networking-vpc-router1 \ --vpn-gateway vertex-networking-vpn-gw1 \ --interface 1Na rede
onprem-vpc, crie um túnel de VPN denominadoonprem-vpc-tunnel0:gcloud compute vpn-tunnels create onprem-vpc-tunnel0 \ --peer-gcp-gateway vertex-networking-vpn-gw1 \ --region us-central1\ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router onprem-vpc-router1 \ --vpn-gateway onprem-vpn-gw1 \ --interface 0Na rede
onprem-vpc, crie um túnel de VPN denominadoonprem-vpc-tunnel1:gcloud compute vpn-tunnels create onprem-vpc-tunnel1 \ --peer-gcp-gateway vertex-networking-vpn-gw1 \ --region us-central1\ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router onprem-vpc-router1 \ --vpn-gateway onprem-vpn-gw1 \ --interface 1Na Google Cloud consola, aceda à página VPN.
Na lista de túneis VPN, verifique se os quatro túneis VPN foram criados.
Estabeleça sessões de BGP
O Cloud Router usa o protocolo de gateway de fronteira (BGP) para trocar rotas entre a sua rede VPC (neste caso, vertex-networking-vpc) e a sua rede nas instalações (representada por onprem-vpc). No Cloud Router, configura uma interface e um par BGP para o seu router nas instalações.
A interface e a configuração do par BGP formam em conjunto uma sessão de BGP.
Nesta secção, cria duas sessões BGP para vertex-networking-vpc e duas para onprem-vpc.
Depois de configurar as interfaces e os pares BGP entre os routers, estes começam automaticamente a trocar rotas.
Estabeleça sessões de BGP para vertex-networking-vpc
No Cloud Shell, na rede
vertex-networking-vpc, crie uma interface BGP paravertex-networking-vpc-tunnel0:gcloud compute routers add-interface vertex-networking-vpc-router1 \ --interface-name if-tunnel0-to-onprem \ --ip-address 169.254.0.1 \ --mask-length 30 \ --vpn-tunnel vertex-networking-vpc-tunnel0 \ --region us-central1Na rede
vertex-networking-vpc, crie um par BGP parabgp-onprem-tunnel0:gcloud compute routers add-bgp-peer vertex-networking-vpc-router1 \ --peer-name bgp-onprem-tunnel0 \ --interface if-tunnel0-to-onprem \ --peer-ip-address 169.254.0.2 \ --peer-asn 65002 \ --region us-central1Na rede
vertex-networking-vpc, crie uma interface BGP paravertex-networking-vpc-tunnel1:gcloud compute routers add-interface vertex-networking-vpc-router1 \ --interface-name if-tunnel1-to-onprem \ --ip-address 169.254.1.1 \ --mask-length 30 \ --vpn-tunnel vertex-networking-vpc-tunnel1 \ --region us-central1Na rede
vertex-networking-vpc, crie um par BGP parabgp-onprem-tunnel1:gcloud compute routers add-bgp-peer vertex-networking-vpc-router1 \ --peer-name bgp-onprem-tunnel1 \ --interface if-tunnel1-to-onprem \ --peer-ip-address 169.254.1.2 \ --peer-asn 65002 \ --region us-central1
Estabeleça sessões de BGP para onprem-vpc
Na rede
onprem-vpc, crie uma interface BGP paraonprem-vpc-tunnel0:gcloud compute routers add-interface onprem-vpc-router1 \ --interface-name if-tunnel0-to-vertex-networking-vpc \ --ip-address 169.254.0.2 \ --mask-length 30 \ --vpn-tunnel onprem-vpc-tunnel0 \ --region us-central1Na rede
onprem-vpc, crie um par BGP parabgp-vertex-networking-vpc-tunnel0:gcloud compute routers add-bgp-peer onprem-vpc-router1 \ --peer-name bgp-vertex-networking-vpc-tunnel0 \ --interface if-tunnel0-to-vertex-networking-vpc \ --peer-ip-address 169.254.0.1 \ --peer-asn 65001 \ --region us-central1Na rede
onprem-vpc, crie uma interface BGP paraonprem-vpc-tunnel1:gcloud compute routers add-interface onprem-vpc-router1 \ --interface-name if-tunnel1-to-vertex-networking-vpc \ --ip-address 169.254.1.2 \ --mask-length 30 \ --vpn-tunnel onprem-vpc-tunnel1 \ --region us-central1Na rede
onprem-vpc, crie um par BGP parabgp-vertex-networking-vpc-tunnel1:gcloud compute routers add-bgp-peer onprem-vpc-router1 \ --peer-name bgp-vertex-networking-vpc-tunnel1 \ --interface if-tunnel1-to-vertex-networking-vpc \ --peer-ip-address 169.254.1.1 \ --peer-asn 65001 \ --region us-central1
Valide a criação da sessão de BGP
Na Google Cloud consola, aceda à página VPN.
Na lista de túneis VPN, verifique se o valor na coluna Estado da sessão de BGP de cada um dos túneis mudou de Configurar sessão de BGP para BGP estabelecido. Pode ter de atualizar o separador do navegador da Google Cloud consola para ver os novos valores.
Valide os vertex-networking-vpc trajetos aprendidos
Na Google Cloud consola, aceda à página Redes VPC.
Na lista de redes de VPC, clique em
vertex-networking-vpc.Clique no separador Rotas.
Selecione us-central1 (Iowa) na lista Região e clique em Ver.
Na coluna Intervalo IP de destino, verifique se o intervalo IP da sub-rede (
172.16.10.0/29) aparece duas vezes.onprem-vpc-subnet1
Valide os onprem-vpc trajetos aprendidos
Clique na seta de retrocesso para regressar à página Redes de VPC.
Na lista de redes de VPC, clique em
onprem-vpc.Clique no separador Rotas.
Selecione us-central1 (Iowa) na lista Região e clique em Ver.
Na coluna Intervalo de IPs de destino, verifique se o
workbench-subnetintervalo de IPs da sub-rede (10.0.1.0/28) aparece duas vezes.
Crie o ponto final do consumidor do Private Service Connect
No Cloud Shell, reserve um endereço IP do ponto final do consumidor que vai ser usado para aceder às APIs Google:
gcloud compute addresses create psc-googleapi-ip \ --global \ --purpose=PRIVATE_SERVICE_CONNECT \ --addresses=192.168.0.1 \ --network=vertex-networking-vpcCrie uma regra de encaminhamento para ligar o ponto final às APIs e aos serviços Google.
gcloud compute forwarding-rules create pscvertex \ --global \ --network=vertex-networking-vpc\ --address=psc-googleapi-ip \ --target-google-apis-bundle=all-apis
Crie rotas anunciadas personalizadas para vertex-networking-vpc
Nesta secção, configura o modo de anúncio personalizado do Cloud Router para
anunciar intervalos de IP personalizados para
vertex-networking-vpc-router1 (o Cloud Router para
vertex-networking-vpc) para anunciar o endereço IP do ponto final do PSC à rede
onprem-vpc.
Na Google Cloud consola, aceda à página Routers na nuvem.
Na lista do Cloud Router, clique em
vertex-networking-vpc-router1.Na página Detalhes do router, clique em Editar.
Na secção Rotas anunciadas, para Rotas, selecione Criar rotas personalizadas.
Selecione a caixa de verificação Anunciar todas as sub-redes visíveis para o Cloud Router para continuar a anunciar as sub-redes disponíveis para o Cloud Router. A ativação desta opção imita o comportamento do Cloud Router no modo de anúncio predefinido.
Clique em Adicionar um trajeto personalizado.
Para Origem, selecione Intervalo de IPs personalizado.
Para o Intervalo de endereços IP, introduza o seguinte endereço IP:
192.168.0.1Em Descrição, introduza o seguinte texto:
Custom route to advertise Private Service Connect endpoint IP addressClique em Concluído e, de seguida, clique em Guardar.
Valide se onprem-vpc aprendeu os trajetos anunciados
Na Google Cloud consola, aceda à página Rotas.
No separador Rotas eficazes, faça o seguinte:
- Para Rede, escolha
onprem-vpc. - Para Região, escolha
us-central1 (Iowa). - Clique em Ver.
Na lista de rotas, verifique se existem entradas cujos nomes começam por
onprem-vpc-router1-bgp-vertex-networking-vpc-tunnel0eonprem-vpc-router1-bgp-vfertex-networking-vpc-tunnel1e se ambas têm um intervalo de IPs de destino de192.168.0.1.Se estas entradas não aparecerem imediatamente, aguarde alguns minutos e, em seguida, atualize o separador do navegador da consola Google Cloud .
- Para Rede, escolha
Crie uma VM em onprem-vpc que use uma conta de serviço gerida pelo utilizador
Nesta secção, cria uma instância de VM que simula uma aplicação cliente no local que envia pedidos de inferência em lote. Seguindo as práticas recomendadas do Compute Engine e do IAM, esta VM usa uma conta de serviço gerida pelo utilizador em vez da conta de serviço predefinida do Compute Engine.
Crie uma conta de serviço gerida pelo utilizador
No Cloud Shell, execute os seguintes comandos, substituindo PROJECT_ID pelo ID do seu projeto:
projectid=PROJECT_ID gcloud config set project ${projectid}Crie uma conta de serviço com o nome
onprem-user-managed-sa:gcloud iam service-accounts create onprem-user-managed-sa \ --display-name="onprem-user-managed-sa-onprem-client"Atribua a função Utilizador do Vertex AI (
roles/aiplatform.user) à conta de serviço:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"Atribua a função Leitor de objetos do armazenamento (
storage.objectViewer) à conta de serviço:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.objectViewer"
Crie a instância de VM on-prem-client
A instância de VM que criar não tem um endereço IP externo e não permite o acesso direto através da Internet. Para ativar o acesso administrativo à VM, usa o encaminhamento TCP do Identity-Aware Proxy (IAP).
No Cloud Shell, crie a instância de VM
on-prem-client:gcloud compute instances create on-prem-client \ --zone=us-central1-a \ --image-family=debian-11 \ --image-project=debian-cloud \ --subnet=onprem-vpc-subnet1 \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --no-address \ --shielded-secure-boot \ --service-account=onprem-user-managed-sa@$projectid.iam.gserviceaccount.com \ --metadata startup-script="#! /bin/bash sudo apt-get update sudo apt-get install tcpdump dnsutils -y"Crie uma regra de firewall para permitir que o IAP se ligue à sua instância de VM:
gcloud compute firewall-rules create ssh-iap-on-prem-vpc \ --network onprem-vpc \ --allow tcp:22 \ --source-ranges=35.235.240.0/20
Valide o acesso público à API Vertex AI
Nesta secção, vai usar o utilitário dig para fazer uma pesquisa de DNS a partir da instância de VM on-prem-client para a API Vertex AI (us-central1-aiplatform.googleapis.com). O resultado dig mostra que o acesso predefinido usa apenas VIPs públicos para aceder à API Vertex AI.
Na secção seguinte, vai configurar o acesso privado à API Vertex AI.
No Cloud Shell, inicie sessão na instância de VM através do IAP:
on-prem-clientgcloud compute ssh on-prem-client \ --zone=us-central1-a \ --tunnel-through-iapNa instância de VM
on-prem-client, execute o comandodig:dig us-central1-aiplatform.googleapis.comDeverá ver um resultado
digsemelhante ao seguinte, em que os endereços IP na secção de resposta são endereços IP públicos:; <<>> DiG 9.16.44-Debian <<>> us-central1.aiplatfom.googleapis.com ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 42506 ;; flags: qr rd ra; QUERY: 1, ANSWER: 16, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 512 ;; QUESTION SECTION: ;us-central1.aiplatfom.googleapis.com. IN A ;; ANSWER SECTION: us-central1.aiplatfom.googleapis.com. 300 IN A 173.194.192.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.250.152.95 us-central1.aiplatfom.googleapis.com. 300 IN A 172.217.219.95 us-central1.aiplatfom.googleapis.com. 300 IN A 209.85.146.95 us-central1.aiplatfom.googleapis.com. 300 IN A 209.85.147.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.250.125.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.250.136.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.250.148.95 us-central1.aiplatfom.googleapis.com. 300 IN A 209.85.200.95 us-central1.aiplatfom.googleapis.com. 300 IN A 209.85.234.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.251.171.95 us-central1.aiplatfom.googleapis.com. 300 IN A 108.177.112.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.250.128.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.251.6.95 us-central1.aiplatfom.googleapis.com. 300 IN A 172.217.212.95 us-central1.aiplatfom.googleapis.com. 300 IN A 74.125.124.95 ;; Query time: 8 msec ;; SERVER: 169.254.169.254#53(169.254.169.254) ;; WHEN: Wed Sep 27 04:10:16 UTC 2023 ;; MSG SIZE rcvd: 321
Configure e valide o acesso privado à API Vertex AI
Nesta secção, configura o acesso privado à API Vertex AI para que, quando enviar pedidos de inferência em lote, estes sejam redirecionados para o seu ponto final do PSC. Por sua vez, o ponto final do PSC encaminha estes pedidos privados para a API REST de inferência em lote do Vertex AI.
Atualize o ficheiro /etc/hosts para apontar para o ponto final do PSC
Neste passo, adiciona uma linha ao ficheiro /etc/hosts que faz com que os pedidos
enviados para o ponto final do serviço público (us-central1-aiplatform.googleapis.com)
sejam redirecionados para o ponto final do PSC (192.168.0.1).
Na instância de VM, use um editor de texto, como o
vimou onanopara abrir o ficheiro/etc/hosts:on-prem-clientsudo vim /etc/hostsAdicione a seguinte linha ao ficheiro:
192.168.0.1 us-central1-aiplatform.googleapis.comEsta linha atribui o endereço IP do ponto final do PSC (
192.168.0.1) ao nome de domínio totalmente qualificado para a API Google Vertex AI (us-central1-aiplatform.googleapis.com).O ficheiro editado deve ter o seguinte aspeto:
127.0.0.1 localhost ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters 192.168.0.1 us-central1-aiplatform.googleapis.com # Added by you 172.16.10.6 on-prem-client.us-central1-a.c.vertex-genai-400103.internal on-prem-client # Added by Google 169.254.169.254 metadata.google.internal # Added by GoogleGuarde o ficheiro da seguinte forma:
- Se estiver a usar o
vim, prima a teclaEsce, de seguida, escreva:wqpara guardar o ficheiro e sair. - Se estiver a usar o
nano, escrevaControl+Oe primaEnterpara guardar o ficheiro e, de seguida, escrevaControl+Xpara sair.
- Se estiver a usar o
Envie um ping para o ponto final do Vertex AI da seguinte forma:
ping us-central1-aiplatform.googleapis.comO comando
pingdeve devolver o seguinte resultado.192.168.0.1é o endereço IP do ponto final do PSC:PING us-central1-aiplatform.googleapis.com (192.168.0.1) 56(84) bytes of data.Escreva
Control+Cpara sair deping.Escreva
exitpara sair da instância de VMon-prem-client.
Crie uma conta de serviço gerida pelo utilizador para o Vertex AI Workbench no vertex-networking-vpc
Nesta secção, para controlar o acesso à sua instância do Vertex AI Workbench, cria uma conta de serviço gerida pelo utilizador e, em seguida, atribui funções do IAM à conta de serviço. Quando cria a instância, especifica a conta de serviço.
No Cloud Shell, execute os seguintes comandos, substituindo PROJECT_ID pelo ID do seu projeto:
projectid=PROJECT_ID gcloud config set project ${projectid}Crie uma conta de serviço com o nome
workbench-sa:gcloud iam service-accounts create workbench-sa \ --display-name="workbench-sa"Atribua a função IAM Utilizador da Vertex AI (
roles/aiplatform.user) à conta de serviço:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"Atribua a função de IAM Utilizador do BigQuery (
roles/bigquery.user) à conta de serviço:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/bigquery.user"Atribua a função do IAM Administrador de armazenamento (
roles/storage.admin) à conta de serviço:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.admin"Atribua a função de IAM Leitor de registos (
roles/logging.viewer) à conta de serviço:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/logging.viewer"
Crie a instância do Vertex AI Workbench
No Cloud Shell, crie uma instância do Vertex AI Workbench, especificando a
workbench-saconta de serviço:gcloud workbench instances create workbench-tutorial \ --vm-image-project=deeplearning-platform-release \ --vm-image-family=common-cpu-notebooks \ --machine-type=n1-standard-4 \ --location=us-central1-a \ --subnet-region=us-central1 \ --shielded-secure-boot=True \ --subnet=workbench-subnet \ --disable-public-ip \ --service-account-email=workbench-sa@$projectid.iam.gserviceaccount.comNa Google Cloud consola, aceda ao separador Instâncias na página Vertex AI Workbench.
Junto ao nome da instância do Vertex AI Workbench (
workbench-tutorial), clique em Abrir JupyterLab.A sua instância do Vertex AI Workbench abre o JupyterLab.
Selecione Ficheiro > Novo > Bloco de notas.
No menu Selecionar kernel, selecione Python 3 (Local) e clique em Selecionar.
Quando o novo bloco de notas é aberto, existe uma célula de código predefinida onde pode introduzir código. Parece que
[ ]:é seguido de um campo de texto. O campo de texto é onde cola o código.Para instalar o SDK do Vertex AI para Python, cole o seguinte código na célula e clique em Executar as células selecionadas e avançar:
!pip3 install --upgrade google-cloud-bigquery scikit-learn==1.2Neste passo e em cada um dos seguintes, adicione uma nova célula de código (se necessário) clicando em Inserir uma célula abaixo, cole o código na célula e, de seguida, clique em Executar as células selecionadas e avançar.
Para usar os pacotes instalados recentemente neste tempo de execução do Jupyter, tem de reiniciar o tempo de execução:
# Restart kernel after installs so that your environment can access the new packages import IPython app = IPython.Application.instance() app.kernel.do_shutdown(True)Defina as seguintes variáveis de ambiente no seu bloco de notas do JupyterLab, substituindo PROJECT_ID pelo ID do projeto.
# set project ID and location PROJECT_ID = "PROJECT_ID" REGION = "us-central1"Crie um contentor do Cloud Storage para preparar a tarefa de preparação:
BUCKET_NAME = f"{PROJECT_ID}-ml-staging" BUCKET_URI = f"gs://{BUCKET_NAME}" !gcloud storage buckets create {BUCKET_URI} --location={REGION} --project={PROJECT_ID}
Prepare os dados de preparação
Nesta secção, prepara os dados a usar para preparar um modelo de inferência.
No bloco de notas do JupyterLab, crie um cliente do BigQuery:
from google.cloud import bigquery bq_client = bigquery.Client(project=PROJECT_ID)Obtenha dados do
ml_datasetsconjunto de dados público do BigQuery:DATA_SOURCE = "bigquery-public-data.ml_datasets.census_adult_income" # Define the SQL query to fetch the dataset query = f""" SELECT * FROM `{DATA_SOURCE}` LIMIT 20000 """ # Download the dataset to a dataframe df = bq_client.query(query).to_dataframe() df.head()Use a biblioteca
sklearnpara dividir os dados para preparação e testes:from sklearn.model_selection import train_test_split # Split the dataset X_train, X_test = train_test_split(df, test_size=0.3, random_state=43) # Print the shapes of train and test sets print(X_train.shape, X_test.shape)Exporte os dataframes de preparação e teste para ficheiros CSV no contentor de preparação:
X_train.to_csv(f"{BUCKET_URI}/train.csv",index=False, quoting=1, quotechar='"') X_test[[i for i in X_test.columns if i != "income_bracket"]].iloc[:20].to_csv(f"{BUCKET_URI}/test.csv",index=False,quoting=1, quotechar='"')
Prepare a aplicação de preparação
Nesta secção, cria e compila a aplicação de preparação Python e guarda-a no contentor de preparação.
No seu bloco de notas do JupyterLab, crie uma nova pasta para os ficheiros da aplicação de preparação:
!mkdir -p training_package/trainerAgora, deve ver uma pasta denominada
training_packageno menu de navegação do JupyterLab.Defina as funcionalidades, o alvo, a etiqueta e os passos para preparar e exportar o modelo para um ficheiro:
%%writefile training_package/trainer/task.py from sklearn.ensemble import RandomForestClassifier from sklearn.feature_selection import SelectKBest from sklearn.pipeline import FeatureUnion, Pipeline from sklearn.preprocessing import LabelBinarizer import pandas as pd import argparse import joblib import os TARGET = "income_bracket" # Define the feature columns that you use from the dataset COLUMNS = ( "age", "workclass", "functional_weight", "education", "education_num", "marital_status", "occupation", "relationship", "race", "sex", "capital_gain", "capital_loss", "hours_per_week", "native_country", ) # Categorical columns are columns that have string values and # need to be turned into a numerical value to be used for training CATEGORICAL_COLUMNS = ( "workclass", "education", "marital_status", "occupation", "relationship", "race", "sex", "native_country", ) # load the arguments parser = argparse.ArgumentParser() parser.add_argument('--training-dir', dest='training_dir', default=os.getenv('AIP_MODEL_DIR'), type=str,help='get the staging directory') args = parser.parse_args() # Load the training data X_train = pd.read_csv(os.path.join(args.training_dir,"train.csv")) # Remove the column we are trying to predict ('income-level') from our features list # Convert the Dataframe to a lists of lists train_features = X_train.drop(TARGET, axis=1).to_numpy().tolist() # Create our training labels list, convert the Dataframe to a lists of lists train_labels = X_train[TARGET].to_numpy().tolist() # Since the census data set has categorical features, we need to convert # them to numerical values. We'll use a list of pipelines to convert each # categorical column and then use FeatureUnion to combine them before calling # the RandomForestClassifier. categorical_pipelines = [] # Each categorical column needs to be extracted individually and converted to a numerical value. # To do this, each categorical column will use a pipeline that extracts one feature column via # SelectKBest(k=1) and a LabelBinarizer() to convert the categorical value to a numerical one. # A scores array (created below) will select and extract the feature column. The scores array is # created by iterating over the COLUMNS and checking if it is a CATEGORICAL_COLUMN. for i, col in enumerate(COLUMNS): if col in CATEGORICAL_COLUMNS: # Create a scores array to get the individual categorical column. # Example: # data = [39, 'State-gov', 77516, 'Bachelors', 13, 'Never-married', 'Adm-clerical', # 'Not-in-family', 'White', 'Male', 2174, 0, 40, 'United-States'] # scores = [0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] # # Returns: [['Sate-gov']] scores = [] # Build the scores array for j in range(len(COLUMNS)): if i == j: # This column is the categorical column we want to extract. scores.append(1) # Set to 1 to select this column else: # Every other column should be ignored. scores.append(0) skb = SelectKBest(k=1) skb.scores_ = scores # Convert the categorical column to a numerical value lbn = LabelBinarizer() r = skb.transform(train_features) lbn.fit(r) # Create the pipeline to extract the categorical feature categorical_pipelines.append( ( "categorical-{}".format(i), Pipeline([("SKB-{}".format(i), skb), ("LBN-{}".format(i), lbn)]), ) ) # Create pipeline to extract the numerical features skb = SelectKBest(k=6) # From COLUMNS use the features that are numerical skb.scores_ = [1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0] categorical_pipelines.append(("numerical", skb)) # Combine all the features using FeatureUnion preprocess = FeatureUnion(categorical_pipelines) # Create the classifier classifier = RandomForestClassifier() # Transform the features and fit them to the classifier classifier.fit(preprocess.transform(train_features), train_labels) # Create the overall model as a single pipeline pipeline = Pipeline([("union", preprocess), ("classifier", classifier)]) # Save the model pipeline joblib.dump(pipeline, os.path.join(args.training_dir,"model.joblib"))Crie um ficheiro
__init__.pyem cada subdiretório para o tornar um pacote:!touch training_package/__init__.py !touch training_package/trainer/__init__.pyCrie um script de configuração do pacote Python:
%%writefile training_package/setup.py from setuptools import find_packages from setuptools import setup setup( name='trainer', version='0.1', packages=find_packages(), include_package_data=True, description='Training application package for census income classification.' )Use o comando
sdistpara criar a distribuição de origem da aplicação de preparação:!cd training_package && python setup.py sdist --formats=gztarCopie o pacote Python para o contentor de preparação:
!gcloud storage cp training_package/dist/trainer-0.1.tar.gz $BUCKET_URI/Verifique se o contentor de preparação contém três ficheiros:
!gcloud storage ls $BUCKET_URIO resultado deve ser:
gs://$BUCKET_NAME/test.csv gs://$BUCKET_NAME/train.csv gs://$BUCKET_NAME/trainer-0.1.tar.gz
Prepare o modelo
Nesta secção, prepara o modelo criando e executando uma tarefa de preparação personalizada.
No seu notebook do JupyterLab, execute o seguinte comando para criar uma tarefa de preparação personalizada:
!gcloud ai custom-jobs create --display-name=income-classification-training-job \ --project=$PROJECT_ID \ --worker-pool-spec=replica-count=1,machine-type='e2-highmem-2',executor-image-uri='us-docker.pkg.dev/vertex-ai/training/sklearn-cpu.1-0:latest',python-module=trainer.task \ --python-package-uris=$BUCKET_URI/trainer-0.1.tar.gz \ --args="--training-dir","/gcs/$BUCKET_NAME" \ --region=$REGIONO resultado deve ser semelhante ao seguinte. O primeiro número em cada caminho de tarefa personalizado é o número do projeto (PROJECT_NUMBER). O segundo número é o ID da tarefa personalizada (CUSTOM_JOB_ID). Tome nota destes números para os poder usar no passo seguinte.
Using endpoint [https://us-central1-aiplatform.googleapis.com/] CustomJob [projects/721032480027/locations/us-central1/customJobs/1100328496195960832] is submitted successfully. Your job is still active. You may view the status of your job with the command $ gcloud ai custom-jobs describe projects/721032480027/locations/us-central1/customJobs/1100328496195960832 or continue streaming the logs with the command $ gcloud ai custom-jobs stream-logs projects/721032480027/locations/us-central1/customJobs/1100328496195960832Execute a tarefa de preparação personalizada e mostre o progresso fazendo stream dos registos da tarefa à medida que é executada:
!gcloud ai custom-jobs stream-logs projects/PROJECT_NUMBER/locations/us-central1/customJobs/CUSTOM_JOB_IDSubstitua os seguintes valores:
- PROJECT_NUMBER: o número do projeto da saída do comando anterior
- CUSTOM_JOB_ID: o ID da tarefa personalizada do resultado do comando anterior
A tarefa de preparação personalizada está agora em execução. Demora cerca de 10 minutos a concluir.
Quando a tarefa estiver concluída, pode importar o modelo do contentor de preparação para o Registo de modelos do Vertex AI.
Importe o modelo
A tarefa de preparação personalizada carrega o modelo preparado para o contentor de preparação. Quando a tarefa estiver concluída, pode importar o modelo do contentor para o Registo de modelos do Vertex AI.
No seu bloco de notas do JupyterLab, importe o modelo executando o seguinte comando:
!gcloud ai models upload --container-image-uri="us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.1-2:latest" \ --display-name=income-classifier-model \ --artifact-uri=$BUCKET_URI \ --project=$PROJECT_ID \ --region=$REGIONApresente os modelos da Vertex AI no projeto da seguinte forma:
!gcloud ai models list --region=us-central1O resultado deve ter o seguinte aspeto. Se forem apresentados dois ou mais modelos, o primeiro da lista é o que importou mais recentemente.
Tome nota do valor na coluna MODEL_ID. Precisa dele para criar o pedido de inferência em lote.
Using endpoint [https://us-central1-aiplatform.googleapis.com/] MODEL_ID DISPLAY_NAME 1871528219660779520 income-classifier-modelEm alternativa, pode listar os modelos no seu projeto da seguinte forma:
Na Google Cloud consola, na secção Vertex AI, aceda à página Registo de modelos Vertex AI.
Aceda à página do Registo de modelos do Vertex AI
Para ver os IDs dos modelos e outros detalhes de um modelo, clique no nome do modelo e, de seguida, clique no separador Detalhes da versão.
Obtenha inferências em lote do modelo
Agora, pode pedir inferências em lote ao modelo. Os pedidos de inferência em lote são feitos a partir da instância de VM.on-prem-client
Crie o pedido de inferência em lote
Neste passo, usa sshpara iniciar sessão na instância de VM on-prem-client.
Na instância de VM, cria um ficheiro de texto denominado request.json que contém
a carga útil de um pedido curl de exemplo que envia para o seu modelo para obter
inferências em lote.
No Cloud Shell, execute os seguintes comandos, substituindo PROJECT_ID pelo ID do seu projeto:
projectid=PROJECT_ID gcloud config set project ${projectid}Inicie sessão na instância de VM
on-prem-clientatravés dessh:gcloud compute ssh on-prem-client \ --project=$projectid \ --zone=us-central1-aNa instância de VM
on-prem-client, use um editor de texto, comovimounano, para criar um novo ficheiro denominadorequest.jsonque contenha o seguinte texto:{ "displayName": "income-classification-batch-job", "model": "projects/PROJECT_ID/locations/us-central1/models/MODEL_ID", "inputConfig": { "instancesFormat": "csv", "gcsSource": { "uris": ["BUCKET_URI/test.csv"] } }, "outputConfig": { "predictionsFormat": "jsonl", "gcsDestination": { "outputUriPrefix": "BUCKET_URI" } }, "dedicatedResources": { "machineSpec": { "machineType": "n1-standard-4", "acceleratorCount": "0" }, "startingReplicaCount": 1, "maxReplicaCount": 2 } }Substitua os seguintes valores:
- PROJECT_ID: o ID do seu projeto
- MODEL_ID: o ID do modelo
- BUCKET_URI: o URI do contentor de armazenamento onde preparou o modelo
Execute o seguinte comando para enviar o pedido de inferência em lote:
curl -X POST \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ -d @request.json \ "https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/batchPredictionJobs"Substitua PROJECT_ID pelo ID do seu projeto.
Deverá ver a seguinte linha na resposta:
"state": "JOB_STATE_PENDING"A sua tarefa de inferência em lote está agora a ser executada de forma assíncrona. Demora cerca de 20 minutos a ser executado.
Na Google Cloud consola, na secção Vertex AI, aceda à página Previsões em lote.
Aceda à página Previsões em lote
Enquanto a tarefa de inferência em lote está em execução, o respetivo estado é
Running. Quando termina, o estado muda paraFinished.Clique no nome da tarefa de inferência em lote (
income-classification-batch-job) e, de seguida, clique no link Localização de exportação na página de detalhes para ver os ficheiros de saída da tarefa em lote no Cloud Storage.Em alternativa, pode clicar no ícone Ver resultado da previsão no Cloud Storage (entre a coluna Última atualização e o menu Ações).
Clique no link do ficheiro
prediction.results-00000-of-00002ouprediction.results-00001-of-00002e, de seguida, clique no link URL autenticado para abrir o ficheiro.O resultado da tarefa de inferência em lote deve ser semelhante a este exemplo:
{"instance": ["27", " Private", "391468", " 11th", "7", " Divorced", " Craft-repair", " Own-child", " White", " Male", "0", "0", "40", " United-States"], "prediction": " <=50K"} {"instance": ["47", " Self-emp-not-inc", "192755", " HS-grad", "9", " Married-civ-spouse", " Machine-op-inspct", " Wife", " White", " Female", "0", "0", "20", " United-States"], "prediction": " <=50K"} {"instance": ["32", " Self-emp-not-inc", "84119", " HS-grad", "9", " Married-civ-spouse", " Craft-repair", " Husband", " White", " Male", "0", "0", "45", " United-States"], "prediction": " <=50K"} {"instance": ["32", " Private", "236543", " 12th", "8", " Divorced", " Protective-serv", " Own-child", " White", " Male", "0", "0", "54", " Mexico"], "prediction": " <=50K"} {"instance": ["60", " Private", "160625", " HS-grad", "9", " Married-civ-spouse", " Prof-specialty", " Husband", " White", " Male", "5013", "0", "40", " United-States"], "prediction": " <=50K"} {"instance": ["34", " Local-gov", "22641", " HS-grad", "9", " Never-married", " Protective-serv", " Not-in-family", " Amer-Indian-Eskimo", " Male", "0", "0", "40", " United-States"], "prediction": " <=50K"} {"instance": ["32", " Private", "178623", " HS-grad", "9", " Never-married", " Other-service", " Not-in-family", " Black", " Female", "0", "0", "40", " ?"], "prediction": " <=50K"} {"instance": ["28", " Private", "54243", " HS-grad", "9", " Divorced", " Transport-moving", " Not-in-family", " White", " Male", "0", "0", "60", " United-States"], "prediction": " <=50K"} {"instance": ["29", " Local-gov", "214385", " 11th", "7", " Divorced", " Other-service", " Unmarried", " Black", " Female", "0", "0", "20", " United-States"], "prediction": " <=50K"} {"instance": ["49", " Self-emp-inc", "213140", " HS-grad", "9", " Married-civ-spouse", " Exec-managerial", " Husband", " White", " Male", "0", "1902", "60", " United-States"], "prediction": " >50K"}
Limpar
Para evitar incorrer em custos na sua Google Cloud conta pelos recursos usados neste tutorial, elimine o projeto que contém os recursos ou mantenha o projeto e elimine os recursos individuais.
Pode eliminar os recursos individuais na Google Cloud consola da seguinte forma:
Elimine a tarefa de inferência em lote da seguinte forma:
Na Google Cloud consola, na secção Vertex AI, aceda à página Previsões em lote.
Junto ao nome da tarefa de inferência em lote (
income-classification-batch-job), clique no menu Ações e escolha Eliminar tarefa de previsão em lote.
Elimine o modelo da seguinte forma:
Na Google Cloud consola, na secção Vertex AI, aceda à página Registo de modelos.
Junto ao nome do modelo (
income-classifier-model), clique no menu Ações e escolha Eliminar modelo.
Elimine a instância do Vertex AI Workbench da seguinte forma:
Na Google Cloud consola, na secção Vertex AI, aceda ao separador Instâncias na página Workbench.
Selecione a
workbench-tutorialinstância do Vertex AI Workbench e clique em Eliminar.
Elimine a instância de VM do Compute Engine da seguinte forma:
Na Google Cloud consola, aceda à página Compute Engine.
Selecione a instância de VM
on-prem-cliente clique em Eliminar.
Elimine os túneis de VPN da seguinte forma:
Na Google Cloud consola, aceda à página VPN.
Na página VPN, clique no separador Túneis do Cloud VPN.
Na lista de túneis de VPN, selecione os quatro túneis de VPN que criou neste tutorial e clique em Eliminar.
Elimine os gateways de VPN de alta disponibilidade da seguinte forma:
Na página VPN, clique no separador Gateways de VPN na nuvem.
Na lista de gateways de VPN, clique em
onprem-vpn-gw1.Na página Detalhes do gateway do Cloud VPN, clique em Eliminar gateway de VPN.
Clique na seta para trás, se necessário, para regressar à lista de gateways de VPN e, de seguida, clique em
vertex-networking-vpn-gw1.Na página Detalhes do gateway do Cloud VPN, clique em Eliminar gateway de VPN.
Elimine os routers do Cloud Router da seguinte forma:
Aceda à página Routers na nuvem.
Na lista de Cloud Routers, selecione os quatro routers que criou neste tutorial.
Para eliminar os routers, clique em Eliminar.
Esta ação também elimina os dois gateways de NAT da nuvem ligados aos routers da nuvem.
Elimine a regra de encaminhamento
pscvertexpara a rede de VPCvertex-networking-vpcda seguinte forma:Aceda ao separador Front-ends da página Equilíbrio de carga.
Na lista de regras de encaminhamento, clique em
pscvertex.Na página Detalhes da regra de encaminhamento, clique em Eliminar.
Elimine as redes de VPC da seguinte forma:
Aceda à página Redes VPC.
Na lista de redes de VPC, clique em
onprem-vpc.Na página Detalhes da rede de VPC, clique em Eliminar rede de VPC.
A eliminação de cada rede também elimina as respetivas sub-redes, rotas e regras de firewall.
Na lista de redes de VPC, clique em
vertex-networking-vpc.Na página Detalhes da rede de VPC, clique em Eliminar rede de VPC.
Elimine o contentor de armazenamento da seguinte forma:
Na Google Cloud consola, aceda à página Cloud Storage.
Selecione o contentor de armazenamento e clique em Eliminar.
Elimine as contas de serviço
workbench-saeonprem-user-managed-sada seguinte forma:Aceda à página Contas de serviço.
Selecione as contas de serviço
onprem-user-managed-saeworkbench-sae clique em Eliminar.
O que se segue?
- Saiba mais sobre as opções de rede empresarial para aceder aos serviços e pontos finais do Vertex AI
- Saiba como funciona o Private Service Connect e por que motivo oferece vantagens significativas em termos de desempenho.
- Saiba como usar os VPC Service Controls para criar perímetros seguros para permitir ou negar o acesso à Vertex AI e a outras APIs Google no seu ponto final de inferência online.
- Saiba como e por que motivo
usar uma zona de encaminhamento de DNS
em vez de atualizar o ficheiro
/etc/hostsem grande escala e ambientes de produção.