데이터 과학자에게 일반적인 워크플로는 로컬에서 노트북을 사용하여 모델을 학습시키고, 매개변수를 로깅하고, 학습 시계열 측정항목을 Vertex AI 텐서보드에 로깅하고, 평가 측정항목을 로깅하는 것입니다.
데이터 과학자는 수행되는 모든 복잡한 데이터 랭글링을 단순화 및 표준화하기 위해 회사 내에서 다른 사람들이 작성한 데이터 사전 처리 코드를 재사용할 수 있기를 바랍니다. 데이터 과학자에게 필요한 기능은 다음과 같습니다.
Python 데이터 사전 처리 라이브러리를 사용하여 노트북에서 인메모리 데이터 세트(Pandas Dataframe)를 삭제합니다.
Keras를 사용하여 모델을 학습합니다(노트북에서 다시 수행).
노트북: 사전 처리된 데이터로 모델 실험
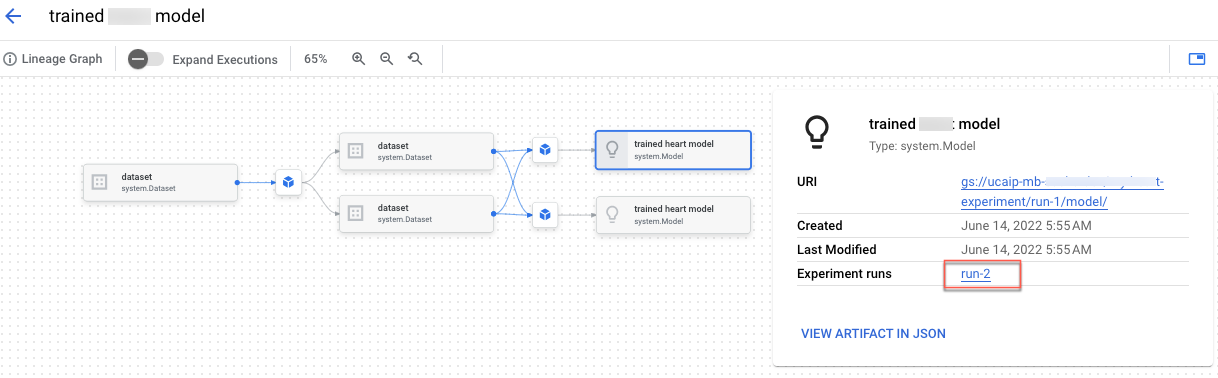
'커스텀 학습용 Vertex AI 실험 계보 빌드' 노트북에서는 Vertex AI Experiments에서 전처리 코드를 통합하는 방법을 알아봅니다.
또한 ML 여정에 따라 생성되는 메타데이터 및 아티팩트를 기록, 분석, 디버깅할 수 있게 해주는 실험 계보를 빌드합니다.