Migrasi Oracle ke BigQuery
Dokumen ini memberikan panduan tingkat tinggi tentang cara bermigrasi dari Oracle ke BigQuery. Panduan ini menjelaskan perbedaan arsitektur dasar dan menyarankan cara migrasi dari data warehouse dan data mart yang berjalan di RDBMS Oracle (termasuk Exadata) ke BigQuery. Dokumen ini memberikan detail yang dapat berlaku untuk Exadata, ExaCC, dan Oracle Autonomous Data Warehouse, karena ketiganya menggunakan software Oracle yang kompatibel.
Dokumen ini ditujukan untuk arsitek perusahaan, DBA, developer aplikasi, dan profesional keamanan IT yang ingin bermigrasi dari Oracle ke BigQuery dan mengatasi tantangan teknis dalam proses migrasi.
Anda juga dapat menggunakan terjemahan SQL batch untuk memigrasikan skrip SQL secara massal, atau terjemahan SQL interaktif untuk menerjemahkan kueri ad hoc. Oracle SQL, PL/SQL, dan Exadata didukung oleh kedua alat di pratinjau.
Pra-migrasi
Untuk memastikan keberhasilan migrasi data warehouse, mulailah merencanakan strategi migrasi lebih awal dari linimasa project Anda. Untuk informasi tentang cara merencanakan pekerjaan migrasi Anda secara sistematis, lihat Apa dan cara melakukan migrasi: Framework migrasi.
Perencanaan kapasitas BigQuery
Pada prinsipnya, throughput analisis di BigQuery diukur dalam slot. Slot BigQuery adalah unit milik Google untuk kapasitas komputasi yang diperlukan untuk menjalankan kueri SQL.
BigQuery terus menghitung berapa banyak slot yang diperlukan oleh kueri saat dijalankan, tetapi BigQuery mengalokasikan slot ke kueri berdasarkan fair scheduler.
Anda dapat memilih di antara model harga berikut saat perencanaan kapasitas untuk slot BigQuery:
Harga sesuai permintaan: Berdasarkan harga sesuai permintaan, BigQuery mengenakan biaya untuk jumlah byte yang diproses (ukuran data), sehingga Anda hanya membayar untuk kueri yang dijalankan. Untuk mengetahui informasi lebih lanjut tentang cara BigQuery menentukan ukuran data, lihat Penghitungan ukuran data. Karena slot menentukan kapasitas komputasi yang mendasarinya, Anda dapat membayar penggunaan BigQuery, bergantung pada jumlah slot yang Anda butuhkan (bukan byte yang diproses). Secara default, project Google Cloud dibatasi hingga maksimum 2.000 slot.
Harga berdasarkan kapasitas : Dengan harga berdasarkan kapasitas, Anda membeli slot pemesanan BigQuery (minimal 100) dan bukan membayar byte yang diproses oleh kueri yang Anda jalankan. Kami merekomendasikan harga berdasarkan kapasitas untuk workload data warehouse perusahaan, yang umumnya mengalami banyak kueri pelaporan serentak dan ekstrak, transformasi, pemuatan (ELT) dengan penggunaan yang dapat diprediksi.
Untuk membantu estimasi slot, sebaiknya siapkan pemantauan BigQuery menggunakan Cloud Monitoring dan menganalisis log audit Anda menggunakan BigQuery. Banyak pelanggan menggunakan Looker Studio (misalnya, lihat contoh open source dari Dasbor Looker Studio ), Looker, atau Tableau sebagai frontend untuk memvisualisasikan data log audit BigQuery, khususnya untuk penggunaan slot di seluruh kueri dan project. Anda juga dapat memanfaatkan data tabel sistem BigQuery untuk memantau penggunaan slot di berbagai tugas dan pemesanan. Sebagai contoh, lihat contoh open source pada dasbor Looker Studio.
Memantau dan menganalisis penggunaan slot secara rutin dapat membantu Anda memperkirakan jumlah total slot yang dibutuhkan organisasi saat Anda berkembang di Google Cloud.
Misalnya, Anda awalnya memesan 4.000 slot BigQuery untuk menjalankan 100 kueri dengan kompleksitas sedang secara bersamaan. Jika Anda melihat waktu tunggu yang tinggi dalam rencana eksekusi kueri, dan dasbor Anda menunjukkan penggunaan slot yang tinggi, hal ini mungkin menunjukkan bahwa Anda memerlukan slot BigQuery tambahan untuk membantu mendukung beban kerja Anda. Jika ingin membeli slot sendiri melalui komitmen tahunan atau tiga tahun, Anda dapat memulai pemesanan BigQuery menggunakan Google Cloud konsol atau alat command line bq.
Jika ada pertanyaan terkait paket Anda saat ini dan opsi sebelumnya, hubungi sales rep Anda.
Keamanan di Google Cloud
Bagian berikut menjelaskan kontrol keamanan Oracle yang umum dan cara memastikan bahwa data warehouse Anda tetap terlindungi di lingkungan Google Cloud.
Identity and Access Management (IAM)
Oracle memberikan pengguna, hak istimewa, peran, dan profil untuk mengelola akses ke resource.
BigQuery menggunakan IAM untuk mengelola akses ke resource dan menyediakan pengelolaan akses terpusat ke resource dan tindakan. Jenis resource yang tersedia di BigQuery meliputi organisasi, project, set data, tabel, dan tampilan. Dalam hierarki kebijakan IAM, set data adalah resource turunan dari project. Tabel mewarisi izin dari set data yang memuatnya
Untuk memberikan akses ke resource, tetapkan satu atau beberapa peran ke pengguna, grup, atau akun layanan. Peran organisasi dan project memengaruhi kemampuan untuk menjalankan tugas atau mengelola project, sedangkan peran set data memengaruhi kemampuan untuk mengakses atau mengubah data di dalam project.
IAM menyediakan jenis peran berikut:
- Peran bawaan berujuan untuk mendukung kasus penggunaan umum dan pola kontrol akses. Peran bawaan memberikan akses terperinci untuk layanan tertentu dan dikelola oleh Google Cloud.
Peran dasar mencakup peran Pemilik, Editor, dan Viewer.
Peran khusus memberikan akses terperinci sesuai dengan daftar izin yang ditentukan pengguna.
Saat Anda menetapkan peran dasar dan yang telah ditetapkan kepada pengguna, izin yang diberikan merupakan gabungan izin dari setiap peran individual.
Keamanan tingkat baris
Oracle Label Security (OLS) memungkinkan pembatasan akses data baris demi baris. Kasus penggunaan standar untuk keamanan tingkat baris adalah membatasi akses staf penjualan ke akun yang mereka kelola. Dengan menerapkan keamanan level baris, Anda mendapatkan kontrol akses yang mendetail.
Untuk mencapai keamanan tingkat baris di BigQuery, Anda dapat menggunakan tampilan diberi otorisasi dan kebijakan akses tingkat baris. Untuk mengetahui informasi selengkapnya tentang cara mendesain dan menerapkan kebijakan ini, lihat Pengantar keamanan tingkat baris BigQuery.
Enkripsi disk penuh
Oracle menawarkan Transparent Data Encryption (TDE) dan enkripsi jaringan untuk enkripsi data dalam penyimpanan dan dalam pengiriman. TDE memerlukan opsi Keamanan Lanjutan, yang dilisensikan secara terpisah.
BigQuery mengenkripsi semua data dalam penyimpanan dan dalam pengiriman secara default, terlepas dari sumber atau kondisi lainnya, serta tidak dapat dinonaktifkan. BigQuery juga mendukung kunci enkripsi yang dikelola pelanggan (CMEK) untuk pengguna yang ingin mengontrol dan mengelola kunci enkripsi kunci di Cloud Key Management Service. Untuk mengetahui informasi selengkapnya tentang enkripsi di Google Cloud, lihat Enkripsi dalam penyimpanan default dan Enkripsi saat dalam pengiriman.
Penyamaran dan penghapusan data
Oracle menggunakan penyamaran data dalam Pengujian Aplikasi Nyata dan penyuntingan data, yang memungkinkan Anda menyamarkan (menyunting) data yang ditampilkan dari kueri yang dikeluarkan oleh aplikasi.
BigQuery mendukung penyamaran data dinamis di tingkat kolom. Anda dapat menggunakan penyamaran data untuk menyamarkan data kolom secara selektif untuk sekelompok pengguna, sambil tetap mengizinkan akses ke kolom tersebut.
Anda dapat menggunakan Perlindungan Data Sensitif untuk mengidentifikasi dan menyamarkan informasi identitas pribadi (PII) yang bersifat sensitif di BigQuery.
Perbandingan BigQuery dan Oracle
Bagian ini menjelaskan perbedaan utama antara BigQuery dan Oracle. Sorotan ini membantu Anda mengidentifikasi rintangan migrasi dan merencanakan perubahan yang diperlukan.
Arsitektur sistem
Salah satu perbedaan utama antara Oracle dan BigQuery adalah BigQuery adalah EDW cloud serverless dengan lapisan penyimpanan dan komputasi terpisah yang dapat melakukan penskalaan berdasarkan kebutuhan kueri. Dengan sifat penawaran serverless BigQuery, Anda tidak dibatasi oleh keputusan hardware; sebagai gantinya, Anda dapat meminta lebih banyak resource untuk kueri dan pengguna melalui pemesanan. BigQuery juga tidak memerlukan konfigurasi software dan infrastruktur yang mendasarinya seperti sistem operasi (OS), sistem jaringan, dan sistem penyimpanan termasuk penskalaan dan ketersediaan tinggi. BigQuery menangani skalabilitas, pengelolaan, dan operasi administratif. Diagram berikut mengilustrasikan hierarki penyimpanan BigQuery.
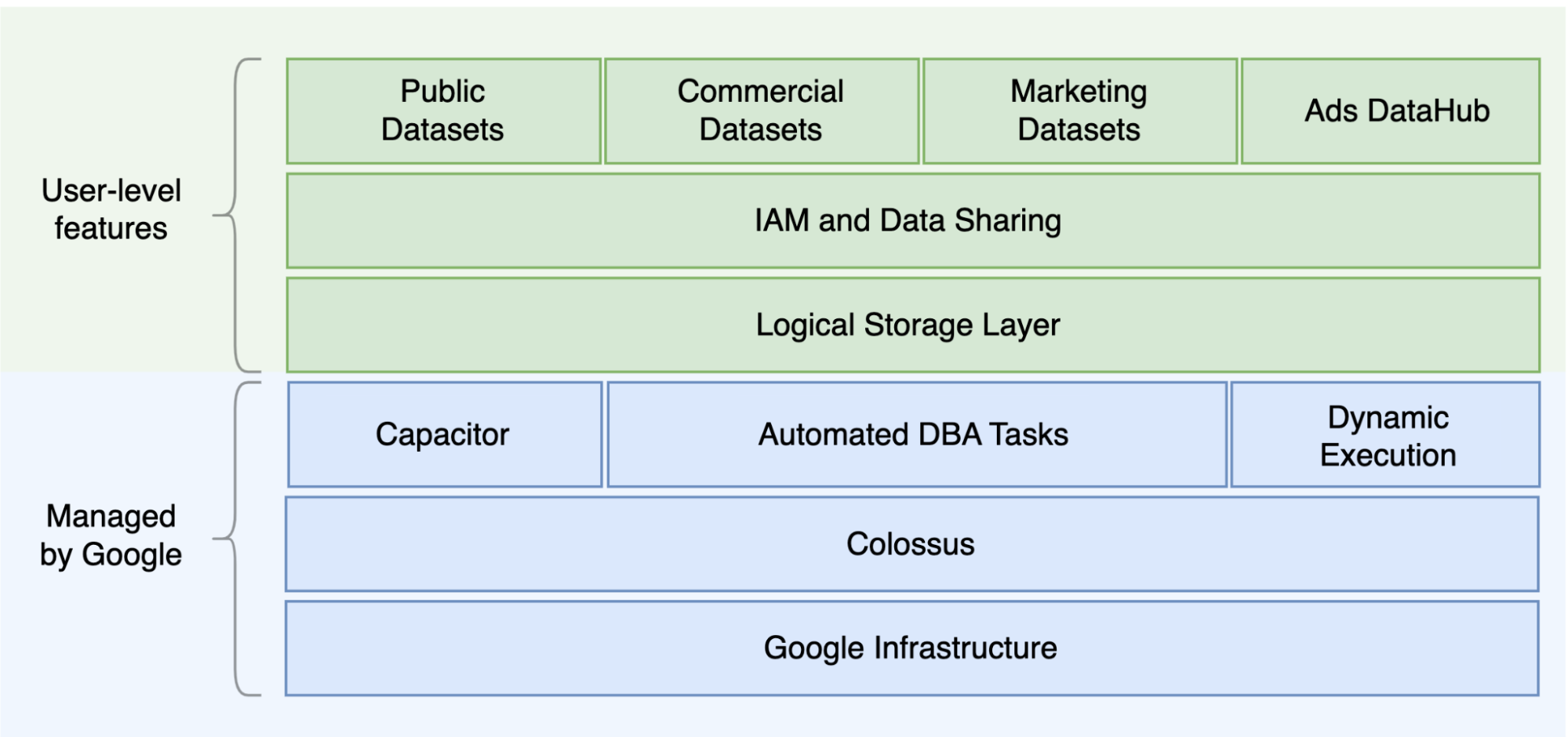
Pengetahuan tentang arsitektur pemrosesan kueri dan penyimpanan yang mendasarinya seperti pemisahan antara penyimpanan (Colossus) dan eksekusi kueri (Dremel) serta cara Google Cloud mengalokasikan resource (Borg) dapat berguna untuk memahami perbedaan perilaku serta mengoptimalkan performa kueri dan efektivitas biaya. Untuk mengetahui detailnya, lihat arsitektur sistem referensi untuk BigQuery, Oracle, dan Exadata.
Arsitektur data dan penyimpanan
Struktur data dan penyimpanan adalah bagian penting dari setiap sistem analisis data karena memengaruhi performa kueri, biaya, skalabilitas, dan efisiensi.
BigQuery memisahkan penyimpanan dan komputasi data serta menyimpan data di Colossus, tempat data dikompresi dan disimpan dalam format berbasis kolom yang disebut Capacitor.
BigQuery beroperasi langsung pada data terkompresi tanpa melakukan dekompresi dengan menggunakan Capacitor. BigQuery menyediakan set data sebagai abstraksi tingkat tertinggi untuk mengatur akses ke tabel seperti yang ditunjukkan pada diagram sebelumnya. Skema dan label dapat digunakan untuk pengaturan tabel lebih lanjut. BigQuery menawarkan partisi untuk meningkatkan performa dan biaya kueri, serta untuk mengelola siklus proses informasi. Resource penyimpanan dialokasikan saat Anda menggunakannya dan batal dialokasikan saat Anda menghapus data atau menghapus tabel.
Oracle menyimpan data dalam format baris menggunakan format blok Oracle yang diatur dalam segmen. Skema (dimiliki oleh pengguna) digunakan untuk mengatur tabel dan objek database lainnya. Mulai Oracle 12c, multitenant digunakan untuk membuat database yang dapat dicocokkan dalam satu instance database untuk isolasi lebih lanjut. Partisi dapat digunakan untuk meningkatkan performa kueri dan operasi siklus proses informasi. Oracle menawarkan beberapa opsi penyimpanan untuk database mandiri dan Real Application Clusters (RAC) seperti ASM, sistem file OS, dan sistem file cluster.
Exadata menyediakan infrastruktur penyimpanan yang dioptimalkan di server sel penyimpanan dan memungkinkan server Oracle mengakses data ini secara transparan dengan menggunakan ASM. Exadata menawarkan opsi Hybrid Columnar Compression (HCC) sehingga pengguna dapat mengompresi tabel dan partisi.
Oracle memerlukan kapasitas penyimpanan yang telah disediakan, pengukuran yang cermat, dan konfigurasi penambahan otomatis pada segmen, file data, dan tablespace.
Eksekusi dan performa kueri
BigQuery mengelola performa dan melakukan penskalaan pada tingkat kueri untuk memaksimalkan performa berdasarkan biaya. BigQuery menggunakan banyak pengoptimalan, misalnya:
- Eksekusi kueri dalam memori
- Arsitektur hierarki multilevel berdasarkan mesin eksekusi Dremel
- Pengoptimalan penyimpanan otomatis dalam Capacitor
- Total bandwidth dua bagian sebesar 1 petabit per detik dengan Jupiter
- Penskalaan otomatis pengelolaan resource untuk menyediakan kueri berskala petabyte yang cepat
BigQuery mengumpulkan statistik kolom saat memuat data dan menyertakan informasi rencana kueri dan pengaturan waktu diagnostik. Resource kueri dialokasikan sesuai dengan jenis dan kompleksitas kueri. Setiap kueri menggunakan sejumlah slot, yang merupakan unit komputasi yang mencakup jumlah CPU dan RAM tertentu.
Oracle menyediakan tugas pengumpulan data statistik. Pengoptimalan database menggunakan statistik untuk memberikan rencana eksekusi yang optimal. Indeks mungkin diperlukan untuk pencarian baris yang efisien dan operasi penggabungan. Oracle juga menyediakan penyimpanan kolom dalam memori untuk analisis dalam memori. Exadata memberikan beberapa peningkatan performa seperti pemindaian cerdas sel, indeks penyimpanan, cache flash, dan koneksi InfiniBand antara server penyimpanan dan server database. Real Application Clusters (RAC) dapat digunakan untuk mencapai ketersediaan tinggi server dan menskalakan database aplikasi yang membutuhkan CPU secara intensif menggunakan penyimpanan dasar yang sama.
Pengoptimalan performa kueri dengan Oracle memerlukan pertimbangan cermat terhadap opsi dan parameter database ini. Oracle menyediakan beberapa alat seperti, Active Session History (ASH), Automatic Database Diagnostic Monitor (ADDM), laporan Automatic Workload Repository (AWR), pemantauan SQL, dan Tuning Advisor, serta Undo dan Memory Tuning Advisor untuk peningkatan (kualitas) performa.
Analisis yang lebih tangkas
Di BigQuery, Anda dapat mengaktifkan berbagai project, pengguna, dan grup untuk membuat kueri set data dalam berbagai project. Pemisahan eksekusi kueri memungkinkan tim otonom bekerja dalam project mereka tanpa memengaruhi pengguna dan project lain dengan memisahkan kuota slot dan membuat kueri penagihan dari project lain dan project yang menghosting set data.
Ketersediaan tinggi, cadangan, dan pemulihan dari bencana
Oracle menyediakan Data Guard sebagai solusi pemulihan dari bencana (disaster recovery) dan replikasi database. Real Application Clusters (RAC) dapat dikonfigurasi untuk ketersediaan server. Cadangan Recovery Manager (RMAN) dapat dikonfigurasi untuk pencadangan database dan archivelog, serta digunakan untuk operasi pemulihan. Fitur Flashback database dapat digunakan untuk flashback database guna memutar mundur database ke titik waktu tertentu. Mengurungkan tablespace menyimpan snapshot tabel. Anda dapat membuat kueri snapshot lama dengan kueri flashback dandari" klausa kueri bergantung pada operasi DML/DDL yang dilakukan sebelumnya dan setelan urungkan retensi Anda. Di Oracle, seluruh integritas database harus dikelola dalam tablespace yang bergantung pada metadata sistem, mengurungkan, dan tablespace yang sesuai. Hal ini karena konsistensi yang kuat penting untuk pencadangan Oracle, dan prosedur pemulihan harus mencakup data primer yang lengkap. Anda dapat menjadwalkan ekspor di level skema tabel jika pemulihan point-in-time tidak diperlukan di Oracle.
BigQuery terkelola sepenuhnya dan berbeda dari sistem database tradisional dalam fungsi pencadangannya yang lengkap. Anda tidak perlu mempertimbangkan server, kegagalan penyimpanan, bug sistem, dan kerusakan data fisik. BigQuery mereplikasi data di berbagai pusat data bergantung pada lokasi set data untuk memaksimalkan keandalan dan ketersediaan. Fungsionalitas multi-region BigQuery mereplikasi data di berbagai region dan melindungi dari tidak tersedianya satu zona dalam region tersebut. Fungsionalitas satu region BigQuery mereplikasi data di berbagai zona dalam region yang sama.
Dengan BigQuery, Anda dapat membuat kueri snapshot historis tabel hingga tujuh hari dan memulihkan tabel yang dihapus dalam dua hari menggunakan perjalanan waktu.
Anda dapat menyalin tabel yang dihapus (untuk memulihkannya) dengan menggunakan sintaksis snapshot (dataset.table@timestamp). Anda dapat mengekspor dari tabel BigQuery untuk kebutuhan pencadangan tambahan, seperti untuk memulihkan
dari operasi pengguna yang tidak disengaja. Strategi dan jadwal pencadangan yang sudah terbukti yang digunakan untuk sistem data warehouse (DWH) yang ada dapat digunakan untuk pencadangan.
Operasi batch dan teknik snapshot memungkinkan strategi pencadangan yang berbeda untuk BigQuery, sehingga Anda tidak perlu sering mengekspor tabel dan partisi yang tidak diubah. Satu cadangan ekspor partisi atau tabel sudah cukup setelah operasi pemuatan atau ETL selesai. Untuk mengurangi biaya pencadangan, Anda dapat menyimpan file ekspor di Cloud StorageNearline Storage atau Coldline Storage dan menentukankebijakan siklus proses untuk menghapus file setelah jangka waktu tertentu, tergantung pada persyaratan retensi data.
Menyimpan data ke dalam cache
BigQuery menawarkan cache per pengguna, dan jika data tidak berubah, hasil kueri akan disimpan ke dalam cache selama sekitar 24 jam. Jika hasilnya diambil dari cache, maka kueri tidak akan dikenai biaya.
Oracle menawarkan beberapa cache untuk data dan hasil kueri, seperti cache buffer, cache hasil, Exadata Flash Cache, dan penyimpanan kolom dalam memori.
Koneksi
BigQuery menangani pengelolaan koneksi dan tidak mengharuskan Anda melakukan konfigurasi sisi server apa pun. BigQuery menyediakan driver JDBC dan
ODBC. Anda dapat menggunakan Google Cloud console atau bq command-line tool untuk membuat kueri interaktif. Anda dapat menggunakan REST API dan library klien untuk berinteraksi secara terprogram dengan BigQuery. Anda dapat menghubungkan Google Spreadsheet langsung dengan BigQuery dan menggunakan driver ODBC dan JDBC untuk terhubung ke Excel. Jika Anda mencari klien desktop, ada alat gratis
seperti DBeaver.
Oracle menyediakan pemroses, layanan, pengendali layanan, beberapa parameter konfigurasi dan penyesuaian, serta server bersama dan khusus untuk menangani koneksi database. Oracle menyediakan driver JDBC, JDBC Thin, ODBC, Oracle Client, dan koneksi TNS. Pemroses pemindaian, alamat IP pemindaian, dan nama pemindaian diperlukan untuk konfigurasi RACI.
Penetapan harga dan pemberian lisensi
Oracle memerlukan lisensi dan biaya dukungan berdasarkan jumlah core untuk edisi Database dan opsi Database seperti RAC, multitenant, Active Data Guard, partisi, dalam memori, Real Application Testing, GoldenGate, serta Spatial and Graph.
BigQuery menawarkan opsi harga yang fleksibel berdasarkan penggunaan penyimpanan, kueri, dan streaming insert. BigQuery menawarkan harga berdasarkan kapasitas bagi pelanggan yang membutuhkan biaya yang dapat diprediksi dan kapasitas slot di region tertentu. Slot yang digunakan untuk streaming insert dan pemuatan tidak dihitung berdasarkan kapasitas slot project. Untuk menentukan jumlah slot yang ingin dibeli untuk data warehouse, lihat Perencanaan kapasitas BigQuery.
BigQuery juga secara otomatis memotong biaya penyimpanan menjadi setengahnya untuk data yang tidak dimodifikasi yang disimpan selama lebih dari 90 hari.
Pelabelan
Set data, tabel, dan tabel virtual BigQuery dapat diberi label dengan key-value pair. Label dapat digunakan untuk membedakan biaya penyimpanan dan penagihan balik internal.
Logging audit dan pemantauan
Oracle menyediakan berbagai level dan jenis opsi audit database dan audit vault dan fitur firewall database, yang dilisensikan secara terpisah. Oracle menyediakan Enterprise Manager untuk pemantauan database.
Untuk BigQuery, Cloud Audit Logs digunakan untuk log akses data dan log audit, yang diaktifkan secara default. Log akses data tersedia selama 30 hari, dan peristiwa sistem serta log aktivitas admin lainnya tersedia selama 400 hari. Jika memerlukan retensi yang lebih lama, Anda dapat mengekspor log ke BigQuery, Cloud Storage, atau Pub/Sub seperti yang dijelaskan dalam Analisis log keamanan di Google Cloud. Jika diperlukan integrasi dengan alat pemantauan insiden yang sudah ada, Pub/Sub dapat digunakan untuk ekspor dan pengembangan kustom harus dilakukan pada alat yang sudah ada untuk membaca log dari Pub/Sub.
Log audit mencakup semua panggilan API, pernyataan kueri, dan status tugas. Anda dapat menggunakan Cloud Monitoring untuk memantau alokasi slot, byte yang dipindai dalam kueri dan disimpan, serta metrik BigQuery lainnya. linimasa dan paket kueri BigQuery dapat digunakan untuk menganalisis tahapan dan performa kueri.
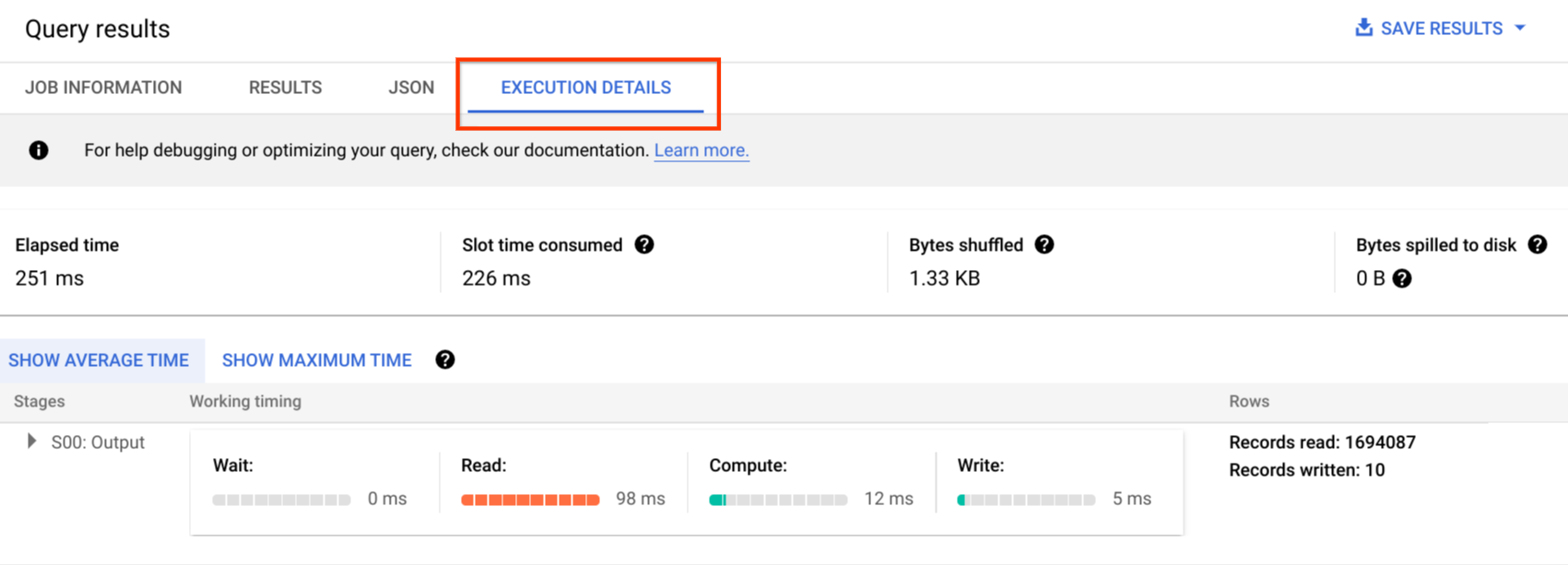
Anda dapat menggunakan tabel pesan error untuk memecahkan masalah tugas kueri dan error API. Untuk membedakan alokasi slot per kueri atau tugas, Anda dapat menggunakan utilitas ini, yang bermanfaat bagi pelanggan yang menggunakan harga berbasis kapasitas dan memiliki banyak project yang didistribusikan ke sejumlah tim.
Pemeliharaan, upgrade, dan versi
BigQuery adalah layanan terkelola sepenuhnya dan tidak mengharuskan Anda melakukan pemeliharaan atau upgrade apa pun. BigQuery tidak menawarkan versi yang berbeda. Upgrade bersifat berkelanjutan dan tidak memerlukan periode nonaktif atau menghambat performa sistem. Untuk informasi selengkapnya, lihat Catatan rilis.
Oracle dan Exadata mengharuskan Anda melakukan patching, upgrade, dan pemeliharaan database dan tingkat infrastruktur yang mendasarinya. Ada banyak versi Oracle dan versi utama baru ini direncanakan akan dirilis setiap tahun. Meskipun versi baru kompatibel dengan versi lama, performa kueri, konteks, dan fitur dapat berubah.
Mungkin ada aplikasi yang memerlukan versi tertentu seperti 10g, 11g, atau 12c. Perencanaan dan pengujian yang cermat diperlukan untuk upgrade database yang besar. Migrasi dari versi yang berbeda mungkin mencakup kebutuhan konversi teknis yang berbeda pada klausa kueri dan objek database.
Beban kerja
Oracle Exadata mendukung workload campuran termasuk workload OLTP. BigQuery dirancang untuk analisis dan tidak dirancang untuk menangani workload OLTP. Workload OLTP yang menggunakan Oracle yang sama harus dimigrasikan ke Cloud SQL, Spanner, atau Firestore diGoogle Cloud. Oracle menawarkan opsi tambahan seperti Advanced Analytics dan Spatial and Graph. Workload ini mungkin perlu ditulis ulang untuk migrasi ke BigQuery. Untuk informasi selengkapnya, lihat Memigrasikan opsi Oracle.
Parameter dan setelan
Oracle menawarkan dan memerlukan banyak parameter untuk dikonfigurasi dan disesuaikan pada level OS .Database .RAC .ASM,dan Pemroses untuk workload dan aplikasi yang berbeda. BigQuery adalah layanan terkelola sepenuhnya dan tidak mengharuskan Anda mengonfigurasi parameter inisialisasi apa pun.
Batas dan kuota
Oracle memiliki batas tetap dan tidak tetap berdasarkan infrastruktur, kapasitas hardware, parameter, versi software, dan pemberian lisensi. BigQuery memiliki kuota dan batas untuk tindakan dan objek tertentu.
Penyediaan BigQuery
BigQuery adalah platform as a service (PaaS) dan data warehouse pemrosesan paralel secara masif Cloud. Kapasitasnya akan naik dan turun tanpa intervensi apa pun dari pengguna saat Google mengelola backend. Akibatnya, berbeda halnya dengan banyak sistem RDBMS, BigQuery tidak mengharuskan Anda menyediakan resource sebelum digunakan. BigQuery mengalokasikan resource kueri dan penyimpanan secara dinamis berdasarkan pola penggunaan Anda. Resource penyimpanan dialokasikan saat Anda menggunakannya dan dibatalkan alokasinya saat Anda menghapus data atau menghapus tabel. Resource kueri dialokasikan sesuai dengan jenis dan kompleksitas kueri. Setiap kueri menggunakan slot. Fairness scheduler tertunda akan digunakan, sehingga mungkin ada periode singkat saat beberapa kueri mendapatkan bagian slot yang lebih tinggi, tetapi scheduler pada akhirnya akan mengoreksinya.
Dalam istilah VM tradisional, BigQuery memberi Anda hasil yang setara dengan:
- Penagihan per detik
- Penskalaan per detik
Untuk menyelesaikan tugas ini, BigQuery melakukan hal berikut:
- Menjaga resource dalam jumlah besar tetap di-deploy agar tidak perlu melakukan penskalaan dengan cepat.
- Menggunakan resource multitenant untuk langsung mengalokasikan potongan besar dalam beberapa detik.
- Mengalokasikan resource secara efisien ke berbagai pengguna dengan skala ekonomi.
- Hanya akan mengenakan biaya kepada Anda untuk tugas yang Anda jalankan, bukan untuk resource yang di-deploy, sehingga Anda membayar resource yang digunakan.
Untuk mengetahui informasi selengkapnya tentang harga, lihatMemahami penskalaan cepat dan penetapan harga yang sederhana BigQuery.
Migrasi Skema
Untuk memigrasikan data dari Oracle ke BigQuery, Anda harus mengetahui jenis data Oracle dan pemetaan BigQuery.
Jenis data Oracle dan pemetaan BigQuery
Jenis data Oracle berbeda dengan jenis data BigQuery. Untuk mengetahui informasi lebih lanjut tentang jenis data BigQuery, baca dokumentasi resmi.
Untuk perbandingan mendetail antara jenis data Oracle dan BigQuery, lihat panduan penerjemahan Oracle SQL.
Indeks
Di banyak workload analitis, tabel kolom yang digunakan bukan penyimpanan baris. Hal ini sangat meningkatkan operasi berbasis kolom dan meniadakan penggunaan indeks untuk analisis batch. BigQuery juga menyimpan data dalam format kolom, sehingga indeks tidak diperlukan dalam BigQuery. Jika workload analitis memerlukan satu set akses berbasis baris dalam jumlah kecil, Bigtable dapat menjadi alternatif yang lebih baik. Jika workload memerlukan pemrosesan transaksi dengan konsistensi relasional yang kuat, Spanner atau Cloud SQL dapat menjadi alternatif yang lebih baik.
Singkatnya, indeks tidak diperlukan dan tidak ditawarkan di BigQuery untuk analisis batch. Anda dapat menggunakan partisi atau pengelompokan. Untuk mengetahui informasi selengkapnya tentang cara menyesuaikan dan meningkatkan performa kueri di BigQuery, lihat Pengantar cara mengoptimalkan performa kueri.
Tabel Virtual
Serupa dengan Oracle, BigQuery memungkinkan pembuatan tampilan kustom. Namun, tampilan di BigQuery tidak mendukung pernyataan DML.
Tampilan terwujud
Tampilan terwujud biasanya digunakan untuk meningkatkan waktu rendering laporan dalam penulisan sekali, baca-banyak jenis laporan dan workload.
Tampilan terwujud ditawarkan di Oracle untuk meningkatkan performa tampilan hanya dengan membuat dan mengelola tabel untuk menyimpan set data hasil kueri. Ada dua cara untuk memuat ulang tampilan terwujud di Oracle: on-commit dan on-demand.
Fungsi tampilan terwujud juga tersedia di BigQuery. BigQuery memanfaatkan hasil prakomputasi dari tampilan terwujud dan jika memungkinkan, hanya membaca perubahan delta dari tabel dasar untuk menghitung hasil terbaru.
Menyimpan fungsi ke dalam cache di Looker Studio atau alat BI modern lainnya juga dapat meningkatkan performa dan menghilangkan kebutuhan untuk menjalankan ulang kueri yang sama, sehingga menghemat biaya.
Partisi tabel
Partisi tabel banyak digunakan di data warehouse Oracle. Berbeda dengan Oracle, BigQuery tidak mendukung partisi hierarkis.
BigQuery menerapkan tiga jenis partisi tabel yang memungkinkan kueri menentukan filter predikat berdasarkan kolom partisi untuk mengurangi jumlah data yang dipindai.
- Tabel yang dipartisi menurut waktu penyerapan: Tabel dipartisi berdasarkan waktu penyerapan data.
- Tabel dipartisi menurut kolom:
Tabel dipartisi berdasarkan kolom
TIMESTAMPatauDATE. - Tabel yang dipartisi menurut rentang bilangan bulat: Tabel dipartisi berdasarkan kolom bilangan bulat.
Untuk mengetahui informasi selengkapnya tentang batas dan kuota yang diterapkan pada tabel yang dipartisi di BigQuery, lihat Pengantar tabel yang dipartisi.
Jika batasan BigQuery memengaruhi fungsionalitas database yang dimigrasikan, sebaiknya gunakan sharding, bukan partisi.
Selain itu, BigQuery tidak mendukung EXCHANGE PARTITION,
SPLIT PARTITION, atau mengonversi tabel yang tidak dipartisi menjadi tabel yang dipartisi.
Pengelompokan
Pengelompokan membantu mengatur dan mengambil data yang disimpan di beberapa kolom yang sering diakses bersama secara efisien. Namun, Oracle dan BigQuery memiliki situasi berbeda dalam hal pengelompokan yang berfungsi paling baik. Di BigQuery, jika sebuah tabel umumnya difilter dan digabungkan dengan kolom tertentu, gunakan pengelompokan. Pengelompokan dapat dipertimbangkan untuk memigrasikan tabel yang dipartisi daftar atau terorganisir indeks dari Oracle.
Tabel sementara
Tabel sementara sering digunakan di pipeline ETL Oracle. Tabel sementara menyimpan data selama sesi pengguna. Data ini akan otomatis dihapus pada akhir sesi.
BigQuery menggunakan tabel sementara untuk meng-cache hasil kueri yang tidak ditulis ke tabel permanen. Setelah kueri selesai, tabel sementara akan ada hingga 24 jam. Tabel dibuat dalam set data khusus dan diberi nama secara acak. Anda juga dapat membuat tabel sementara untuk digunakan sendiri. Untuk informasi selengkapnya, lihat Tabel sementara.
Tabel eksternal
Serupa dengan Oracle, BigQuery memungkinkan Anda membuat kueri sumber data eksternal. BigQuery mendukung pembuatan kueri data langsung dari sumber data eksternal termasuk:
- Layanan Simple Storage Amazon (Amazon S3)
- Azure Blob Storage
- Bigtable
- Spanner
- Cloud SQL
- Cloud Storage
- Google Drive
Pemodelan data
Model data bintang atau kepingan salju dapat menjadi pilihan efisien untuk penyimpanan analisis dan biasa digunakan untuk data warehouse di Oracle Exadata.
Tabel yang didenormalisasi menghilangkan operasi gabungan yang mahal dan umumnya memberikan performa yang lebih baik untuk analisis di BigQuery. Model data bintang dan snowflake juga didukung oleh BigQuery. Untuk mengetahui detail desain data warehouse selengkapnya tentang BigQuery, lihat Mendesain skema.
Format baris versus format kolom dan batas server versus serverless
Oracle menggunakan format baris yang digunakan untuk menyimpan baris tabel dalam blok data, sehingga kolom yang tidak diperlukan akan diambil dalam blok untuk kueri analisis, berdasarkan pemfilteran dan agregasi kolom tertentu.
Oracle memiliki arsitektur bersama, dengan dependensi resource hardware tetap, seperti memori dan penyimpanan, yang ditetapkan ke server. Ini adalah dua kekuatan utama yang mendasari banyak teknik pemodelan data yang berkembang untuk meningkatkan efisiensi penyimpanan dan performa kueri analisis. Skema bintang dan kepingan salju dan pemodelan vault data adalah beberapa di antaranya.
BigQuery menggunakan format berbasis kolom untuk menyimpan data dan tidak memiliki batas penyimpanan dan memori tetap. Arsitektur ini memungkinkan Anda melakukan denormalisasi dan mendesain skema lebih lanjut berdasarkan operasi baca dan kebutuhan bisnis, sehingga mengurangi kompleksitas serta meningkatkan fleksibilitas, skalabilitas, dan performa.
Denormalisasi
Salah satu tujuan utama normalisasi database relasional adalah untuk mengurangi redundansi data. Meskipun model ini paling cocok untuk database relasional yang menggunakan format baris, denormalisasi data lebih disukai untuk database berbasis kolom. Untuk mengetahui informasi selengkapnya tentang keuntungan denormalisasi data dan strategi pengoptimalan kueri lainnya di BigQuery, lihat Denormalisasi.
Teknik untuk meratakan skema yang ada
Teknologi BigQuery memanfaatkan kombinasi akses dan pemrosesan data berdasarkan kolom, penyimpanan dalam memori, dan pemrosesan terdistribusi untuk memberikan performa kueri yang berkualitas.
Saat mendesain skema DWH BigQuery, membuat tabel fakta dalam
struktur tabel datar (menggabungkan semua tabel dimensi menjadi satu
data dalam tabel fakta) akan lebih baik untuk pemanfaatan penyimpanan daripada menggunakan
beberapa dimensi DWH tabel sementara. Selain penggunaan penyimpanan yang lebih sedikit, memiliki
tabel datar di BigQuery juga menyebabkan lebih sedikit penggunaan JOIN. Diagram berikut
mengilustrasikan contoh meratakan skema Anda.
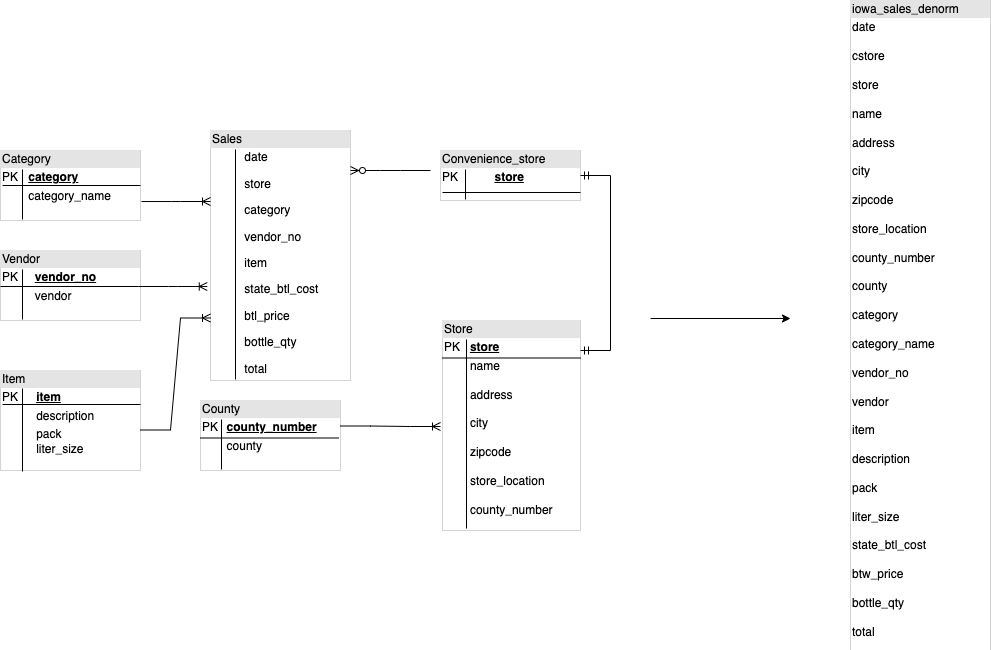
Contoh meratakan skema bintang
Gambar 1 menunjukkan database manajemen penjualan fiktif yang mencakup empat tabel:
- Tabel pesanan/penjualan (tabel fakta)
- Tabel karyawan
- Tabel lokasi
- Tabel pelanggan
Kunci utama untuk tabel penjualan adalah OrderNum, yang juga berisi
kunci asing untuk tiga tabel lainnya.
Gambar 1: Contoh data penjualan dalam skema bintang
Data sampel
Pesanan/konten tabel fakta
| OrderNum | CustomerID | SalesPersonID | amount | Location |
| O-1 | 1234 | 12 | 234.22 | 18 |
| O-2 | 4567 | 1 | 192.10 | 27 |
| O-3 | 12 | 14.66 | 18 | |
| O-4 | 4567 | 4 | 182.00 | 26 |
Konten tabel karyawan
| SalesPersonID | FName | LName | title |
| 1 | Alex | Smith | Sales Associate |
| 4 | Lisa | Doe | Sales Associate |
| 12 | John | Doe | Sales Associate |
Konten tabel pelanggan
| CustomerID | FName | LName |
| 1234 | Amanda | Lee |
| 4567 | Matt | Ryan |
Konten tabel lokasi
| Location | kota | kota | kota |
| 18 | Bronx | NY | 10452 |
| 26 | Mountain View | CA | 90210 |
| 27 | Chicago | IL | 60613 |
Kueri untuk meratakan data menggunakan LEFT OUTER JOIN
#standardSQL INSERT INTO flattened SELECT orders.ordernum, orders.customerID, customer.fname, customer.lname, orders.salespersonID, employee.fname, employee.lname, employee.title, orders.amount, orders.location, location.city, location.state, location.zipcode FROM orders LEFT OUTER JOIN customer ON customer.customerID = orders.customerID LEFT OUTER JOIN employee ON employee.salespersonID = orders.salespersonID LEFT OUTER JOIN location ON location.locationID = orders.locationID
Output data yang diratakan
| OrderNum | CustomerID | FName | LName | SalesPersonID | FName | LName | amount | Location | kota | dengan status tersembunyi akhir | zipcode |
| O-1 | 1234 | Amanda | Lee | 12 | John | Doe | 234.22 | 18 | Bronx | NY | 10452 |
| O-2 | 4567 | Matt | Ryan | 1 | Alex | Smith | 192.10 | 27 | Chicago | IL | 60613 |
| O-3 | 12 | John | Doe | 14.66 | 18 | Bronx | NY | 10452 | |||
| O-4 | 4567 | Matt | Ryan | 4 | Lisa | Doe | 182.00 | 26 | Gunung
Lihat |
CA | 90210 |
Kolom bertingkat dan berulang.
Untuk mendesain dan membuat skema DWH dari skema relasional (misalnya, skema bintang dan kepingan salju yang menyimpan dimensi dan tabel fakta), BigQuery menyajikan fungsi kolom bertingkat dan berulang. Oleh karena itu, hubungan dapat dipertahankan dengan cara yang sama seperti skema DWH yang dinormalisasi (atau dinormalisasi sebagian) relasional tanpa memengaruhi performa. Untuk informasi selengkapnya, lihat praktik terbaik performa.
Untuk lebih memahami implementasi kolom bertingkat dan berulang, lihat
skema relasional sederhana dari tabel CUSTOMERS dan tabel ORDER/SALES. Keduanya
adalah dua tabel yang berbeda, satu untuk setiap entity, dan hubungan ditentukan
menggunakan kunci seperti kunci utama dan kunci asing sebagai link antar-tabel
saat membuat kueri menggunakan JOIN. Kolom bertingkat dan berulang BigQuery
memungkinkan Anda mempertahankan hubungan yang sama antar-entity dalam satu
tabel. Hal ini dapat diterapkan dengan memiliki semua data pelanggan, sementara data
pesanan disusun bertingkat untuk setiap pelanggan. Untuk mengetahui informasi selengkapnya, lihat Menentukan
kolom bertingkat dan berulang.
Untuk mengonversi struktur datar menjadi skema bertingkat atau berulang, tempatkan kolom seperti berikut:
CustomerID,FName,LNameditambahkan ke kolom baru bernamaCustomer.SalesPersonID,FName,LNameditambahkan ke kolom baru bernamaSalesperson.LocationID,city,state,zip codedisusun bertingkat ke kolom baru bernamaLocation.
Kolom OrderNum dan amount tidak bertingkat, karena mewakili elemen
unik.
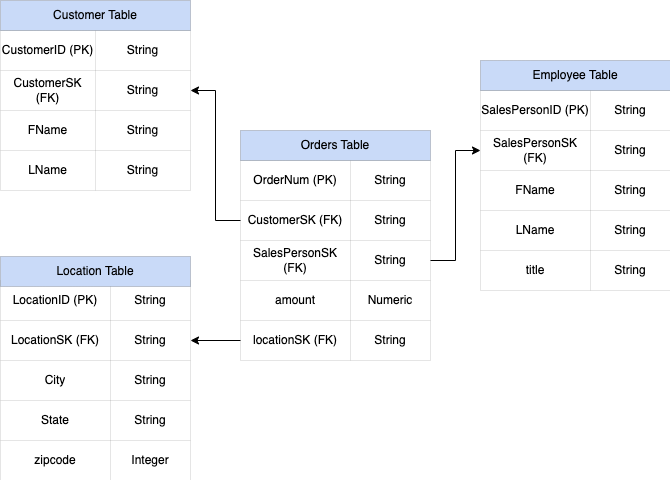
Anda perlu membuat skema yang cukup fleksibel agar setiap pesanan memiliki lebih dari satu pelanggan: primer dan sekunder. Kolom pelanggan ditandai sebagai berulang. Skema yang dihasilkan ditunjukkan pada Gambar 2, yang menggambarkan kolom bertingkat dan berulang.
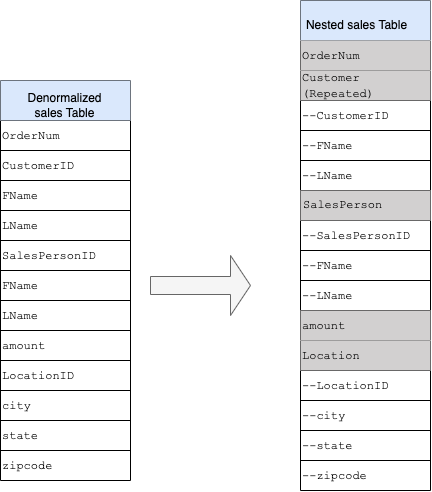
Gambar 2: Representasi logis struktur bertingkat
Dalam beberapa kasus, denormalisasi menggunakan kolom bertingkat dan berulang tidak menghasilkan peningkatan performa. Untuk mengetahui informasi selengkapnya tentang batasan dan larangan, lihat Menentukan kolom bertingkat dan berulang dalam skema tabel.
Kunci surrogate
Mengidentifikasi baris dengan kunci unik dalam tabel adalah hal yang umum. Urutan biasa
digunakan di Oracle untuk membuat kunci ini. Di
BigQuery, Anda dapat membuat kunci surrogate menggunakan fungsi row_number dan
partition by. Untuk informasi selengkapnya, lihat BigQuery dan kunci surrogate: pendekatan praktis.
Melacak perubahan dan histori
Saat merencanakan migrasi DWH BigQuery, pertimbangkan konsep dimensi yang berubah secara perlahan (SCD). Secara umum, istilah SCD menjelaskan proses perubahan (operasi DML) dalam tabel dimensi.
Karena beberapa alasan, data warehouse tradisional menggunakan jenis yang berbeda untuk menangani perubahan data dan menyimpan data historis dalam dimensi yang berubah secara perlahan. Penggunaan jenis ini diperlukan oleh batasan hardware dan persyaratan efisiensi yang telah dibahas sebelumnya. Karena penyimpanannya jauh lebih murah daripada komputasi dan sangat skalabel, redundansi dan duplikasi data akan dianjurkan jika menghasilkan kueri yang lebih cepat di BigQuery. Anda dapat menggunakan teknik snapshot data dengan seluruh data dimuat ke dalam partisi harian baru.
Tampilan spesifik per peran dan pengguna
Gunakan tampilan spesifik per peran dan khusus pengguna jika pengguna menjadi bagian dari tim yang berbeda dan seharusnya hanya melihat catatan dan hasil yang diperlukan.
Dukungan BigQuerykolom- dankeamanan tingkat baris. Keamanan tingkat kolom memberikan akses yang lebih terperinci ke kolom sensitif menggunakan tag kebijakan, atau klasifikasi data berbasis jenis. Keamanan tingkat baris yang memungkinkan Anda memfilter data dan mengizinkan akses ke baris tertentu dalam tabel berdasarkan kondisi pengguna yang memenuhi syarat.
Migrasi data
Bagian ini memberikan informasi tentang migrasi data dari Oracle ke BigQuery, termasuk pemuatan awal, pengambilan data perubahan (CDC), serta alat dan pendekatan ETL/ELT.
Aktivitas migrasi
Sebaiknya lakukan migrasi secara bertahap dengan mengidentifikasi kasus penggunaan yang sesuai untuk migrasi. Ada beberapa alat dan layanan yang tersedia untuk memigrasikan data dari Oracle ke Google Cloud. Meskipun tidak lengkap, daftar ini memberikan gambaran tentang ukuran dan cakupan upaya migrasi.
Mengekspor data dari Oracle: Untuk mengetahui informasi selengkapnya, lihat Pemuatan awal serta CDC dan penyerapan streaming dari Oracle ke BigQuery. Alat ETL dapat digunakan untuk pemuatan awal.
Data staging (di Cloud Storage): Cloud Storage adalah tempat landing yang direkomendasikan (area staging) untuk data yang diekspor dari Oracle. Cloud Storage dirancang untuk penyerapan data terstruktur atau tidak terstruktur secara cepat dan fleksibel.
Proses ETL: Untuk mengetahui informasi selengkapnya, lihat Migrasi ETL/ELT.
Memuat data langsung ke BigQuery: Anda dapat memuat data ke BigQuery langsung dari Cloud Storage, melalui Dataflow, atau melalui streaming real-time. Gunakan Dataflow saat transformasi data diperlukan.
Pemuatan awal
Migrasi data awal dari data warehouse Oracle yang ada ke BigQuery mungkin berbeda dengan pipeline ETL/ELT inkremental, bergantung pada ukuran data dan bandwidth jaringan. Pipeline ETL/ELT yang sama, dapat digunakan jika ukuran datanya adalah beberapa terabyte.
Jika ukuran data mencapai beberapa terabyte, membuang data dan menggunakan gcloud storage untuk transfer dapat jauh lebih efisien daripada menggunakan metodologi ekstraksi database terprogram yang mirip dengan JdbcIO, karena pendekatan terprogram mungkin memerlukan
penyesuaian performa yang jauh lebih terperinci. Jika ukuran data lebih dari beberapa terabyte dan
data disimpan di cloud atau penyimpanan online (seperti Amazon Simple Storage Service (Amazon S3)), pertimbangkan
untuk menggunakan BigQuery Data Transfer Service. Untuk transfer berskala besar
(terutama transfer dengan bandwidth jaringan terbatas), Transfer Appliance adalah opsi yang berguna.
Batasan untuk pemuatan awal
Saat merencanakan migrasi data, pertimbangkan hal berikut:
- Ukuran data Oracle DWH: Ukuran sumber skema Anda memberikan bobot yang signifikan pada metode transfer data yang dipilih, terutama jika ukuran data besar (terabyte dan lebih tinggi). Jika ukuran data relatif kecil, proses transfer data dapat diselesaikan dalam langkah yang lebih sedikit. Berurusan dengan ukuran data berskala besar membuat keseluruhan proses menjadi lebih kompleks.
Periode nonaktif: Menentukan apakah periode nonaktif merupakan opsi untuk migrasi ke BigQuery sangatlah penting. Untuk mengurangi periode nonaktif, Anda dapat memuat data historis yang stabil secara massal dan memiliki solusi CDC untuk mengikuti perubahan yang terjadi selama proses transfer.
Harga: Dalam beberapa skenario, Anda mungkin memerlukan alat integrasi pihak ketiga (misalnya, alat ETL atau replikasi) yang memerlukan lisensi tambahan.
Transfer data awal (batch)
Transfer data menggunakan metode batch menunjukkan bahwa data akan diekspor secara konsisten dalam satu proses (misalnya, mengekspor data skema DWH Oracle ke file CSV, Avro, atau Parquet atau mengimpornya ke Cloud Storage untuk membuat set data di BigQuery. Semua alat dan konsep ETL yang dijelaskan dalam migrasi ETL/ELT dapat digunakan untuk pemuatan awal.
Jika tidak ingin menggunakan alat ETL/ELT untuk pemuatan awal, Anda dapat menulis skrip kustom untuk mengekspor data ke file (CSV, Avro, atau Parquet) dan mengupload data tersebut ke Cloud Storage menggunakan gcloud storage, BigQuery Data Transfer Service, atau
Transfer Appliance. Untuk informasi selengkapnya tentang performa yang menyesuaikan opsi transfer
dan transfer data besar, lihat Mentransfer set
data besar. Kemudian, muat data dari Cloud Storage ke BigQuery.
Cloud Storage sangat cocok untuk menangani landing awal data. Cloud Storage adalah layanan penyimpanan objek yang sangat tersedia dan tahan lama tanpa batasan jumlah file, dan Anda hanya membayar untuk penyimpanan yang digunakan. Layanan ini dioptimalkan agar dapat berfungsi dengan layanan Google Cloud lain seperti BigQuery dan Dataflow.
CDC dan penyerapan streaming dari Oracle ke BigQuery
Ada beberapa cara untuk mengambil data yang diubah dari Oracle. Setiap opsi memiliki kekurangan, terutama dalam dampak performa pada sistem sumber, persyaratan pengembangan dan konfigurasi, serta harga dan pemberian lisensi.
CDC berbasis log
Oracle GoldenGate adalah alat yang direkomendasikan Oracle untuk mengekstrak log ulangi, dan Anda dapat menggunakan GoldenGate untuk Big Data untuk streaming log ke BigQuery. GoldenGate memerlukan pemberian lisensi per CPU. Untuk mengetahui informasi tentang harganya, lihat Daftar Harga Global Oracle Technology. Jika Oracle GoldenGate untuk Big Data tersedia (jika lisensi sudah diperoleh), menggunakan GoldenGate dapat menjadi pilihan yang tepat untuk membuat pipeline data guna mentransfer data (pemuatan awal), lalu menyinkronkan semua modifikasi data.
Oracle XStream
Oracle menyimpan setiap commit dalam file log ulangi, dan file ulangi ini dapat digunakan untuk CDC. Oracle XStream Out dibuat berdasarkan LogMiner dan disediakan oleh alat pihak ketiga seperti Debezium (mulai versi 0.8) atau secara komersial menggunakan alat seperti Striim. Penggunaan XStream API memerlukan pembelian lisensi untuk Oracle GoldenGate meskipun GoldenGate tidak diinstal dan digunakan. XStream memungkinkan Anda menyebarkan pesan Stream antara Oracle dan software lainnya secara efisien.
Oracle LogMiner
Tidak diperlukan lisensi khusus untuk LogMiner. Anda dapat menggunakan opsi LogMiner di konektor komunitas Debezium. API ini juga tersedia secara komersial menggunakan alat seperti Attunity, Striim, atau StreamSets. LogMiner mungkin memiliki dampak performa pada database sumber yang sangat aktif dan harus digunakan dengan hati-hati jika volume perubahan (ukuran pengulangan) lebih dari 10 GB per jam, bergantung pada CPU server, memori, serta kapasitas dan pemanfaatan I/O.
CDC berbasis SQL
Ini adalah pendekatan ETL inkremental. Kueri SQL terus-menerus melakukan polling
tabel sumber untuk setiap perubahan, bergantung pada kunci yang meningkat secara monoton dan kolom
stempel waktu yang menyimpan tanggal terakhir diubah atau disisipkan. Jika tidak ada
kunci yang meningkat secara monoton, penggunaan kolom stempel waktu (tanggal diubah) dengan
presisi kecil (detik) dapat menyebabkan data duplikat atau data yang terlewat, bergantung pada
volume dan operator perbandingan, seperti > atau >=.
Untuk mengatasi masalah tersebut, Anda dapat menggunakan presisi yang lebih tinggi dalam kolom stempel waktu, seperti enam digit pecahan (mikrodetik, yang merupakan presisi maksimum yang didukung di BigQuery, atau Anda dapat menambahkan tugas penghapusan duplikat di ETL/ELT Anda tergantung pada kunci bisnis dan karakteristik data.
Harus ada indeks pada kolom kunci atau stempel waktu untuk mendapatkan performa ekstraksi yang lebih baik
dan mengurangi dampak pada database sumber. Operasi penghapusan merupakan
tantangan untuk metodologi ini karena harus ditangani di aplikasi
sumber dengan cara penghapusan sementara, seperti menempatkan tanda yang dihapus dan memperbarui
last_modified_date. Solusi alternatif dapat berupa mencatat operasi ini ke dalam log di tabel lain menggunakan pemicu.
Triggers
Pemicu database dapat dibuat pada tabel sumber untuk mencatat perubahan ke dalam tabel
jurnal bayangan. Tabel jurnal dapat menyimpan seluruh baris untuk melacak setiap
perubahan kolom, atau hanya dapat menyimpan kunci utama dengan jenis operasi
(menyisipkan, memperbarui, atau menghapus). Kemudian, data yang diubah dapat diambil dengan pendekatan
berbasis SQL yang dijelaskan dalam CDC berbasis SQL. Menggunakan pemicu dapat memengaruhi performa transaksi dan menggandakan latensi operasi DML baris tunggal jika baris lengkap disimpan. Hanya menyimpan kunci utama dapat mengurangi beban ini, tetapi dalam hal ini, operasi JOIN dengan tabel asli
diperlukan dalam ekstraksi berbasis SQL, yang melewatkan perubahan perantara.
Migrasi ETL/ELT
Ada banyak kemungkinan cara menangani ETL/ELT di Google Cloud. Panduan teknis tentang konversi workload ETL tertentu tidak tercakup dalam dokumen ini. Anda dapat mempertimbangkan pendekatan lift-and-shift atau merancang ulang platform integrasi data bergantung pada batasan seperti biaya dan waktu. Untuk mengetahui informasi selengkapnya tentang cara memigrasikan pipeline data Anda ke Google Cloud dan berbagai konsep migrasi lainnya, lihat Memigrasikan pipeline data.
Pendekatan lift-and-shift
Jika platform yang ada mendukung BigQuery dan Anda ingin terus menggunakan alat integrasi data yang sudah ada:
- Anda dapat mempertahankan platform ETL/ELT sebagaimana adanya dan mengubah tahap penyimpanan yang diperlukan dengan BigQuery dalam tugas ETL/ELT.
- Jika ingin memigrasikan platform ETL/ELT ke Google Cloud juga, Anda dapat bertanya kepada vendor apakah alat mereka berlisensi di Google Cloudatau tidak, dan jika ya, Anda dapat menginstalnya di Compute Engine atau mencarinya di Google Cloud Marketplace.
Untuk mengetahui informasi tentang penyedia solusi integrasi data, lihat Partner BigQuery.
Merancang ulang platform ETL/ELT
Jika Anda ingin menyusun ulang pipeline data, sebaiknya pertimbangkan untuk menggunakan layanan Google Cloud .
Cloud Data Fusion
Cloud Data Fusion adalah CDAP terkelola di Google Cloud yang menawarkan antarmuka visual dengan banyak plugin untuk berbagai tugas seperti pengembangan pipeline serta tarik lalu lepas. Cloud Data Fusion dapat digunakan untuk mengambil data dari berbagai jenis sistem sumber serta menawarkan kemampuan replikasi batch dan streaming. Cloud Data Fusion atau plugin Oracle dapat digunakan untuk mengambil data dari Oracle. Plugin BigQuery dapat digunakan untuk memuat data ke BigQuery dan menangani pembaruan skema.
Tidak ada skema output yang ditentukan pada plugin sumber dan sink, serta
select * from digunakan dalam plugin sumber untuk mereplikasi kolom baru.
Anda dapat menggunakan fitur Cloud Data Fusion Wrangle untuk pembersihan dan persiapan data.
Dataflow
Dataflow adalah platform pemrosesan data serverless yang dapat melakukan penskalaan otomatis serta melakukan pemrosesan data batch dan streaming. Dataflow dapat menjadi pilihan yang tepat untuk developer Python dan Java yang ingin membuat kode pipeline data mereka dan menggunakan kode yang sama untuk workload streaming dan batch Gunakan template JDBC ke BigQuery untuk mengekstrak data dari Oracle atau database relasional lainnya dan memuatnya ke BigQuery.
Cloud Composer
Cloud Composer adalah Google Cloud layanan orkestrasi alur kerja terkelola sepenuhnya yang di-build di Apache Airflow. Dengan layanan ini, Anda dapat membuat, menjadwalkan, dan memantau pipeline yang mencakup seluruh lingkungan cloud dan pusat data lokal. Cloud Composer menyediakan operator dan kontribusi yang dapat menjalankan teknologi multi-cloud untuk kasus penggunaan termasuk ekstrak dan pemuatan, transformasi ELT, dan panggilan REST API.
Cloud Composer menggunakan grafik asiklik terarah (DAG) untuk penjadwalan dan orkestrasi alur kerja. Untuk memahami konsep aliran udara umum, lihat konsep Airflow Apache. Untuk informasi selengkapnya tentang DAG, lihat Menulis DAG (alur kerja). Untuk mengetahui contoh praktik terbaik ETL dengan Apache Airflow, lihat Praktik terbaik ETL dengan situs dokumentasi Airflow disesuaikan. Anda dapat mengganti operator Hive dalam contoh tersebut dengan operator BigQuery, dan konsep yang sama akan berlaku.
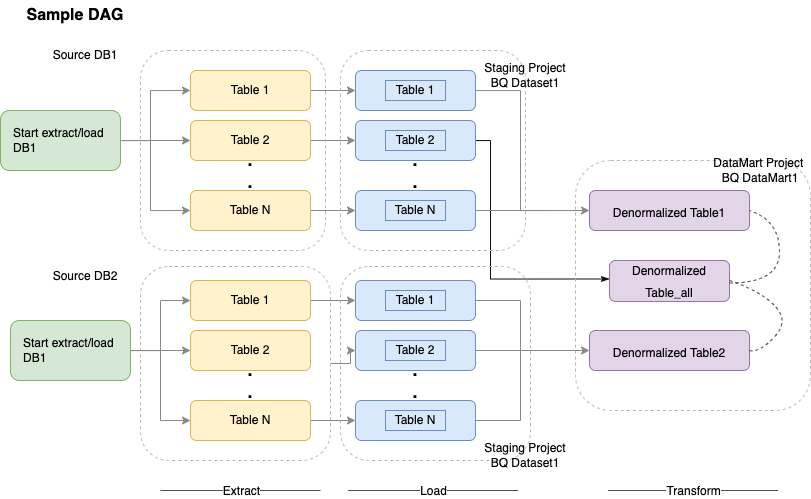
Kode contoh berikut adalah bagian tingkat tinggi dari contoh DAG untuk diagram sebelumnya:
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': airflow.utils.dates.days_ago(2),
'email': ['airflow@example.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 2,
'retry_delay': timedelta(minutes=10),
}
schedule_interval = "00 01 * * *"
dag = DAG('load_db1_db2',catchup=False, default_args=default_args,
schedule_interval=schedule_interval)
tables = {
'DB1_TABLE1': {'database':'DB1', 'table_name':'TABLE1'},
'DB1_TABLE2': {'database':'DB1', 'table_name':'TABLE2'},
'DB1_TABLEN': {'database':'DB1', 'table_name':'TABLEN'},
'DB2_TABLE1': {'database':'DB2', 'table_name':'TABLE1'},
'DB2_TABLE2': {'database':'DB2', 'table_name':'TABLE2'},
'DB2_TABLEN': {'database':'DB2', 'table_name':'TABLEN'},
}
start_db1_daily_incremental_load = DummyOperator(
task_id='start_db1_daily_incremental_load', dag=dag)
start_db2_daily_incremental_load = DummyOperator(
task_id='start_db2_daily_incremental_load', dag=dag)
load_denormalized_table1 = BigQueryOperator(
task_id='load_denormalized_table1',
use_legacy_sql=False,
write_disposition='WRITE_TRUNCATE',
allow_large_results=True,
trigger_rule='all_done',
bql='''
#standardSQL
select
t1.*,tN.* except (ID)
from `ingest-project.ingest_db1.TABLE1` as t1
left join `ingest-project.ingest_db1.TABLEN` as tN on t1.ID = tN.ID
''', destination_dataset_table='datamart-project.dm1.dt1', dag=dag)
load_denormalized_table2 = BigQueryOperator(
task_id='load_denormalized_table2',
use_legacy_sql=False,
write_disposition='WRITE_TRUNCATE',
allow_large_results=True,
trigger_rule='all_done',
bql='''
#standardSQL
select
t1.*,t2.* except (ID),tN.* except (ID)
from `ingest-project.ingest_db1.TABLE1` as t1
left join `ingest-project.ingest_db2.TABLE2` as t2 on t1.ID = t2.ID
left join `ingest-project.ingest_db2.TABLEN` as tN on t2.ID = tN.ID
''', destination_dataset_table='datamart-project.dm1.dt2', dag=dag)
load_denormalized_table_all = BigQueryOperator(
task_id='load_denormalized_table_all',
use_legacy_sql=False,
write_disposition='WRITE_TRUNCATE',
allow_large_results=True,
trigger_rule='all_done',
bql='''
#standardSQL
select
t1.*,t2.* except (ID),t3.* except (ID)
from `datamart-project.dm1.dt1` as t1
left join `ingest-project.ingest_db1.TABLE2` as t2 on t1.ID = t2.ID
left join `datamart-project.dm1.dt2` as t3 on t2.ID = t3.ID
''', destination_dataset_table='datamart-project.dm1.dt_all', dag=dag)
def start_pipeline(database,table,...):
#start initial or incremental load job here
#you can write your custom operator to integrate ingestion tool
#or you can use operators available in composer instead
for table,table_attr in tables.items():
tbl=table_attr['table_name']
db=table_attr['database'])
load_start = PythonOperator(
task_id='start_load_{db}_{tbl}'.format(tbl=tbl,db=db),
python_callable=start_pipeline,
op_kwargs={'database': db,
'table':tbl},
dag=dag
)
load_monitor = HttpSensor(
task_id='load_monitor_{db}_{tbl}'.format(tbl=tbl,db=db),
http_conn_id='ingestion-tool',
endpoint='restapi-endpoint/',
request_params={},
response_check=lambda response: """{"status":"STOPPED"}""" in
response.text,
poke_interval=1,
dag=dag,
)
load_start.set_downstream(load_monitor)
if table_attr['database']=='db1':
load_start.set_upstream(start_db1_daily_incremental_load)
else:
load_start.set_upstream(start_db2_daily_incremental_load)
if table_attr['database']=='db1':
load_monitor.set_downstream(load_denormalized_table1)
else:
load_monitor.set_downstream(load_denormalized_table2)
load_denormalized_table1.set_downstream(load_denormalized_table_all)
load_denormalized_table2.set_downstream(load_denormalized_table_all)
Kode sebelumnya diberikan untuk tujuan demonstrasi dan tidak dapat digunakan sebagaimana adanya.
Dataprep by Trifacta
Dataprep adalah layanan data untuk menjelajahi, membersihkan, dan menyiapkan data terstruktur dan tidak terstruktur secara visual untuk analisis, pelaporan, dan machine learning. Anda mengekspor data sumber ke dalam file JSON atau CSV, mengubah data menggunakan Dataprep, dan memuat data menggunakan Dataflow. Sebagai contoh, lihat Data Oracle (ETL) ke BigQuery menggunakan Dataflow dan Dataprep.
Dataproc
Dataproc adalah layanan Hadoop yang dikelola Google. Anda dapat menggunakan Sqoop untuk mengekspor data dari Oracle dan banyak database relasional ke dalam Cloud Storage sebagai file Avro, lalu Anda dapat memuat file Avro ke BigQuery menggunakan bq tool. Sangatlah umum untuk menginstal alat ETL seperti CDAP di Hadoop yang menggunakan JDBC untuk mengekstrak data dan Apache Spark atau MapReduce untuk transformasi data.
Alat partner untuk migrasi data
Ada beberapa vendor di ruang ekstraksi, transformasi, dan pemuatan (ETL). Pemimpin pasar ETL seperti Informatica, Talend, Matillion, Infoworks, Stitch, Fivetran, dan Striim terintegrasi erat dengan BigQuery dan Oracle serta dapat membantu mengekstrak, mengubah, memuat data, dan mengelola alur kerja pemrosesan.
Alat ETL telah ada selama bertahun-tahun. Beberapa organisasi mungkin merasa mudah untuk memanfaatkan investasi yang ada dalam skrip ETL tepercaya. Beberapa solusi partner utama kami tercantum di situs partner BigQuery. Mengetahui kapan harus memilih alat partner dibandingkan utilitas bawaanGoogle Cloud bergantung pada infrastruktur Anda saat ini dan kenyamanan tim IT Anda dalam mengembangkan pipeline data dalam kode Java atau Python.
Migrasi alat business intelligence (BI)
BigQuery mendukung rangkaian fleksibel solusi business intelligence (BI) untuk Pelaporan dan analisis yang dapat Anda manfaatkan. Untuk mengetahui informasi selengkapnya tentang migrasi alat BI dan integrasi BigQuery, baca Ringkasan analisis BigQuery.
Terjemahan kueri (SQL)
GoogleSQL BigQuery mendukung kepatuhan terhadap standar SQL 2011 dan memiliki ekstensi yang mendukung kueri data bertingkat dan berulang. Semua fungsi dan operator SQL yang sesuai dengan ANSI dapat digunakan dengan sedikit modifikasi. Untuk mengetahui perbandingan mendetail antara sintaksis dan fungsi Oracle dan BigQuery SQL, lihat referensi penerjemahan Oracle ke BigQuery SQL.
Gunakan terjemahan SQL batch untuk memigrasikan kode SQL secara massal, atau terjemahan SQL interaktif untuk menerjemahkan kueri ad hoc.
Memigrasikan opsi Oracle
Bagian ini menampilkan rekomendasi dan referensi arsitektur untuk mengonversi aplikasi yang menggunakan fungsi Oracle Data Mining, R, dan Spasial dan Graph.
Opsi Oracle Advanced Analytics
Oracle menawarkan opsi analisis lanjutan untuk penambangan data, algoritma machine learning (ML) dasar, dan penggunaan R. Opsi Advanced Analytics memerlukan lisensi. Anda dapat memilih dari daftar lengkap produk Google AI/ML, bergantung pada kebutuhan Anda, mulai dari pengembangan hingga produksi dalam skala besar.
Oracle R Enterprise
Oracle R Enterprise (ORE), yang merupakan komponen opsi Oracle Advanced Analytics, membuat bahasa pemrograman statistik R open source terintegrasi dengan Oracle Database. Dalam deployment ORE standar, R diinstal pada server Oracle.
Untuk skala data yang sangat besar atau pendekatan warehousing, mengintegrasikan R dengan BigQuery adalah pilihan ideal. Anda dapat menggunakan library R bigrquery open source untuk mengintegrasikan R dengan BigQuery.
Google telah berpartner dengan RStudio untuk menyediakan alat-alat canggih di bidang ini kepada pengguna. RStudio dapat digunakan untuk mengakses data berukuran terabyte dalam model BigQuery Fit di TensorFlow, dan menjalankan model machine learning dalam skala besar dengan AI Platform. Di Google Cloud, R dapat diinstal di Compute Engine dalam skala besar.
Oracle Data Mining
Oracle Data Mining (ODM), yang merupakan komponen opsi Oracle Advanced Analytics, memungkinkan developer membuat model machine learning menggunakan Oracle PL/SQL Developer di Oracle.
Dengan BigQuery ML, developer dapat menjalankan berbagai jenis model, seperti regresi linear, regresi logistik biner, regresi logistik multi-kelas, pengelompokan k-means, dan impor model TensorFlow. Untuk informasi selengkapnya, lihat Pengantar BigQuery ML.
Konversi tugas ODM mungkin memerlukan penulisan ulang kode. Anda dapat memilih dari penawaran produk Google AI yang komprehensif seperti BigQuery ML, AI API (Speech-to-Text, Text-to-Speech, Dialogflow, Cloud Translation, Cloud Natural Language API, Cloud Vision, TimeSeries Insights API, dan lainnya), atau Vertex AI.
Vertex AI Workbench dapat digunakan sebagai lingkungan pengembangan untuk data scientist, dan Vertex AI Training dapat digunakan untuk menjalankan pelatihan dan penskoran workload dalam skala besar.
Opsi Spasial dan Grafik
Oracle menawarkan opsi Spasial dan Grafik untuk membuat kueri geometri dan grafik, serta memerlukan lisensi untuk opsi ini. Anda dapat menggunakan fungsi geometri di BigQuery tanpa biaya atau lisensi tambahan dan menggunakan database grafik lainnya di Google Cloud.
Spasial
BigQuery menawarkan fungsi dan jenis data analisis geospasial. Untuk mengetahui informasi selengkapnya, lihat Menangani data analisis geospasial. Jenis data dan fungsi Spasial Oracle dapat dikonversi menjadi fungsi geografis di SQL standar BigQuery. Fungsi geografi tidak menimbulkan biaya tambahan selain harga BigQuery standar.
Grafik
JanusGraph adalah solusi database grafik open source yang dapat menggunakan Bigtable sebagai backend penyimpanan. Untuk informasi selengkapnya, lihat Menjalankan JanusGraph di GKE dengan Bigtable.
Neo4j adalah solusi database grafik lain yang disediakan sebagai layanan Google Cloud yang berjalan di Google Kubernetes Engine (GKE).
Oracle Application Express
Aplikasi Oracle Application Express (APEX) bersifat unik untuk Oracle dan perlu ditulis ulang. Fungsi pelaporan dan visualisasi data dapat dikembangkan menggunakan Looker Studio atau BI engine, sedangkan fungsi tingkat aplikasi seperti membuat dan mengedit baris dapat dikembangkan tanpa coding di AppSheet menggunakan Cloud SQL.
Langkah berikutnya
- Pelajari cara Mengoptimalkan workload untuk pengoptimalan performa dan pengurangan biaya secara keseluruhan.
- Pelajari cara Mengoptimalkan penyimpanan di BigQuery.
- Untuk update BigQuery, lihat catatan rilis.
- Lihat panduan penerjemahan Oracle SQL.