このドキュメントでは、Cloud Monitoring が提供するサービスの概要について説明します。これらのサービスは、アプリケーションや他の Google Cloud サービスの動作、健全性、パフォーマンスを把握するのに役立ちます。Cloud Monitoring は、ほとんどの Google Cloud サービスのパフォーマンス情報を自動的に収集して保存します。 Google Cloud Managed Service for Prometheus を使用して Prometheus 指標を収集できます。Compute Engine 仮想マシン(VM)に Ops エージェントをインストールすると、アプリケーションとサードパーティ アプリケーションから指標とログを収集できます。
Cloud Monitoring が提供するアラート、テスト、可視化のサービスを使用すると、次のような重要な疑問に対する回答を得ることができます。
- サービスの負荷はどのくらいか
- ウェブサイトが適切に応答しているか
- サービスが正しく動作しているか
- App Hub アプリケーションの健全性はどのような状態か
Cloud Monitoring は、ほとんどのサービスに対し Google Cloud コンソールと API サポートを提供します。一部のサービスは、Google Cloud CLI または Terraform もサポートしています。alertPolicies.list ページなどの Cloud Monitoring API リファレンス ページを使用すると、リファレンス ページから直接 API 呼び出しをテストできます。
Cloud Monitoring サービス
Cloud Monitoring には、使用しているアプリケーションやその他の Google Cloud サービスの健全性とパフォーマンスを把握するために使用できるさまざまなサービスが用意されています。
インシデントと通知
パフォーマンス指標の値が、定義した基準を満たしたときに通知を受け取るには、アラート ポリシーを作成します。アラート ポリシーには、通知を受け取るユーザーまたはグループのリストが含まれます。Monitoring は、メール、Cloud モバイルアプリ、PagerDuty や Slack などのサービスを含む、一般的な通知チャンネルをサポートしています。たとえば、VM の CPU 使用率が 80% を超えたときに通知を受け取るように、アラート ポリシーを作成できます。
各通知には、障害に関する関連情報とインシデントへのリンクが含まれます。インシデントは、障害のトラブルシューティングに使用できる情報を格納する永続レコードです。通常、レコードには、インシデントのステータス、ログへのリンク、記録された指標データのグラフ、ラベル、期間が含まれています。
アラート サービスは多くの Google Cloud サービスと統合されています。これらの統合が存在する場合、推奨アラートの一覧が表示されるパネルや、アラート ポリシーを作成できるボタンがグラフに表示されることがあります。どちらの場合も、アラート ポリシーは事前構成されているため、通知するユーザーまたはグループのリストを指定するだけです。
アラート ポリシーは、 Google Cloud コンソール、Cloud Monitoring API、Google Cloud CLI、Terraform を使用して作成および管理できます。
プロアクティブなモニタリングと検証
サービス、アプリケーション、ウェブページ、API の可用性、整合性、パフォーマンスをテストするには、合成モニターを作成します。たとえば、稼働時間チェックで HTTP、HTTPS、TCP のエンドポイントの応答性をプローブし、エンドポイントが応答しなかったときに通知を受け取ることができます。また、無効なリンク チェッカーを作成して、ウェブページをクロールし、無効なリンクが検出されたときに通知を受け取ることもできます。
合成モニターは、 Google Cloud コンソール、Cloud Monitoring API、Google Cloud CLI、または Terraform を使用して作成および管理できます。
データの可視化
Google Cloud リソースをインスタンス化するか、App Hub にアプリケーションを登録すると、ダッシュボード サービスが自動的に Google Cloud管理ダッシュボードを作成します。これらのダッシュボードには、リソースとアプリケーションの健全性を把握する際に役立つ厳選された情報が表示されます。たとえば、App Hub アプリケーションの場合、アプリケーションと、そのサービスとワークロードごとにダッシュボードが作成されます。これらのダッシュボードには、アプリケーションのログデータや指標データ、対応待ちのアラートの数などの情報が表示されます。
Google Cloud で作成されたダッシュボードで、調査を完了するのに十分な情報を得られる場合もあります。ただし、傾向の把握、外れ値の特定、データに関するその他の詳細の表示に必要なデータが正確に提供されない場合があります。これらのタスクを完了するには、ダッシュボード サービスとグラフ作成サービスを使用します。
表示するデータとそのデータの表示形式を制御するには、カスタム ダッシュボードを作成します。たとえば、Grafana ダッシュボードをインポートしたり、テンプレートからダッシュボードをインストールできます。
カスタム ダッシュボードには、次の情報を表示できます。
- 指標データを表示するグラフと表
- ログデータとエラーグループ
- アラート ポリシーのグラフ
- アラートに関する情報
- テキスト
- システムのオペレーションに影響する再起動やクラッシュなどのイベント。
ダッシュボードの作成と管理は、Google Cloud コンソールまたは API を使用して行うことができます。
グラフサービスである Metrics Explorer を使用すると、時系列データをすばやく可視化して分析できます。グラフの設定では、現在のデータと以前のデータの比較、外れ値やパーセンタイルの表示、複数の指標の表示が可能です。グラフを保存して、カスタム ダッシュボードに追加することもできます。
データの収集と保存
Cloud Monitoring は、次の種類の指標データを収集して保存します。
- Google Cloud サービスによって生成されたシステム指標。これらの指標から、サービスの運用に関する情報を得られます。
- Ops エージェントが Compute Engine インスタンス上で実行されているシステム リソースやアプリケーションについて収集するシステムとアプリケーションの指標。Apache または Nginx ウェブサーバー、MongoDB または PostgreSQL データベースなどのサードパーティ プラグインから指標を収集するように Ops エージェントを構成できます。
Cloud Monitoring API を使用するか、OpenTelemetry などのライブラリを使用して作成されるユーザー定義の指標。
一部のオープンソース ライブラリまたはサードパーティ プロバイダによって定義される外部指標。
Google Cloud Managed Service for Prometheus、または Ops エージェントと Prometheus レシーバーまたは OTLP レシーバーを使用して収集される Prometheus 指標。
- Cloud Logging に書き込まれたログに関する数値情報を記録するログベースの指標。Google が定義しているログベースの指標には、サービスが検出したエラーの数と、 Google Cloud プロジェクトが受信したログエントリの合計数が含まれます。ログベースの指標を定義することもできます。
クエリ言語
アラート ポリシーまたはグラフを作成する場合は、モニタリングまたはグラフ化するデータを記述するクエリを指定する必要があります。
Google Cloud コンソール: メニューから選択してクエリを作成することも、クエリを記述して作成することもできます。クエリエディタは、Prometheus Query Language(PromQL)で使用できます。クエリエディタは構文のチェックと提案を実施します。また、Monitoring フィルタ式を作成することもできます。
Cloud Monitoring API: この API は、Prometheus Query Language(PromQL)と Monitoring フィルタ式をサポートしています。
大規模なシステムをモニタリングする
このセクションでは、リソースをコレクションとして管理する方法と、複数の Google Cloud プロジェクトに保存されている指標をモニタリングする方法について説明します。
リソースをコレクションとして管理する
リソースを個別ではなくコレクションとして管理するには、リソース グループを作成します。リソース グループは、指定した条件を満たすリソースの動的コレクションです。Compute Engine VM インスタンスをGoogle Cloud プロジェクトに追加するなど、リソースを追加または削除すると、グループのメンバーが自動的に変更されます。リソース グループの例を次に示します。
- 名前が文字列
prod-で始まる Compute Engine インスタンス。 - タグ
test-clusterが付いているリソース。 - リージョン A またはリージョン B の Amazon EC2 インスタンス。
リソース グループを定義したら、グループを単一のリソースのようにモニタリングできます。たとえば、リソース グループをモニタリングする稼働時間チェックを構成できます。グラフとアラート ポリシーの場合、グループ名に基づいてフィルタリングできます。
詳細については、リソース グループを構成するをご覧ください。
複数の Google Cloud プロジェクトの指標をモニタリングする
複数のGoogle Cloud プロジェクトと AWS アカウントの時系列データを 1 つのインターフェースで表示してモニタリングするには、マルチプロジェクトの指標スコープを構成します。
デフォルトでは、 Google Cloud コンソールの Cloud Monitoring ページでは、スコーピング プロジェクトに格納されている時系列のみにアクセスできます。スコーピング プロジェクトは、Google Cloud コンソール プロジェクト選択ツールで選択したプロジェクトです。スコーピング プロジェクトには、構成するアラート、合成モニター、ダッシュボード、モニタリング グループが格納されています。
スコーピング プロジェクトは指標スコープもホストします。指標スコープは、スコーピング プロジェクトに表示される指標を持つプロジェクトとアカウントを定義します。指標スコープを構成して、他の Google Cloud プロジェクトや AWS アカウントからの時系列データを含めることができます。指標スコープを変更する方法については、複数のプロジェクトの指標スコープを構成するをご覧ください。
Cloud Monitoring のデータモデル
このセクションでは、Cloud Monitoring データモデルについて説明します。
指標タイプは、測定対象を表します。指標タイプの例として、VM の CPU 使用率や使用されるディスクの割合などがあります。
時系列は、指標のタイムスタンプ付き測定値と、測定値のソースと意味に関する情報を含むデータ構造です。
時系列に何が含まれるかについては、以下の詳細をご確認ください。
points配列には、タイムスタンプ付きの測定値が含まれます。2 つの値を含む
points配列の例を次に示します。"points": [ { "interval": { "startTime": "2020-07-27T20:20:21.597143Z", "endTime": "2020-07-27T20:20:21.597143Z" }, "value": { "doubleValue": 0.473005 } }, { "interval": { "startTime": "2020-07-27T20:19:21.597239Z", "endTime": "2020-07-27T20:19:21.597239Z" }, "value": { "doubleValue": 0.473025 } }, ],ある値の意味を理解するには、時系列に含まれる他のデータとそのデータの定義を参照する必要があります。
resourceフィールドは、モニタリング対象のハードウェア コンポーネントまたはソフトウェア コンポーネントを表します。Cloud Monitoring では、ハードウェア コンポーネントまたはソフトウェア コンポーネントはモニタリング対象リソースと呼ばれます。モニタリング対象リソースの例としては、Compute Engine インスタンスや App Engine アプリケーションなどが挙げられます。モニタリング対象リソースの一覧については、モニタリング対象リソースの一覧をご覧ください。resourceフィールドの例を次に示します。"resource": { "type": "gce_instance", "labels": { "instance_id": "2708613220420473591", "zone": "us-east1-b", "project_id": "sampleproject" } }typeフィールドには、モニタリング対象リソースがgce_instanceとしてリストされます。これは、これらの測定が Compute Engine VM インスタンスで実行されることを示します。labelsフィールドには、モニタリング対象リソースに関する詳細情報を提供する Key-Value ペアが格納されています。gce_instanceタイプの場合、ラベルはモニタリング対象の VM インスタンスを表します。
metricフィールドは、測定対象を表します。metricフィールドの例を次に示します。"metric": { "labels": { "instance_name": "test" }, "type": "compute.googleapis.com/instance/cpu/utilization" },- Google Cloud サービスの場合、
typeフィールドで、サービスとモニタリング対象を指定します。この例では、Compute Engine サービスが CPU 使用率を測定しています。typeフィールドがcustomまたはexternalで始まる場合、指標はカスタム指標またはサードパーティによって定義された指標のいずれかです。
labelsフィールドには、測定に関する詳細情報を提供する Key-Value ペアが格納されます。これらのラベルは、MetricDescriptorの一部と定義されます。これは、測定されたデータの属性を定義するデータ構造です。指標compute.googleapis.com/instance/cpu/utilizationのMetricDescriptorには、instance_nameラベルが含まれます。
- Google Cloud サービスの場合、
metricKindフィールドは、時系列内の近似測定値間の関係を表します。GAUGE指標には、特定の時点で測定される値(時間単位の温度レコードなど)が格納されます。CUMULATIVE指標には、特定の時点に測定対象となったデータの累積値が保存されます(例: 車両の走行距離計)。DELTA指標には、特定の期間に測定される対象の値の変化が保存されます(株式の損失や損失を示す株式の概要など)。
valueTypeフィールドは、測定値のデータ型、すなわちINT64、DOUBLE、BOOL、STRING、またはDISTRIBUTIONを表します。
- 各 VM インスタンスの CPU 使用率を表示できます。
- 特定の VM インスタンスの CPU 使用率を表示するには、
instance_idラベルの単一の値で時系列をフィルタリングします。 VM インスタンスごと、
machine_typeラベルごとにグループ化して、平均 CPU 使用率を表示できます。次のスクリーンショットは、この構成のグラフを示しています。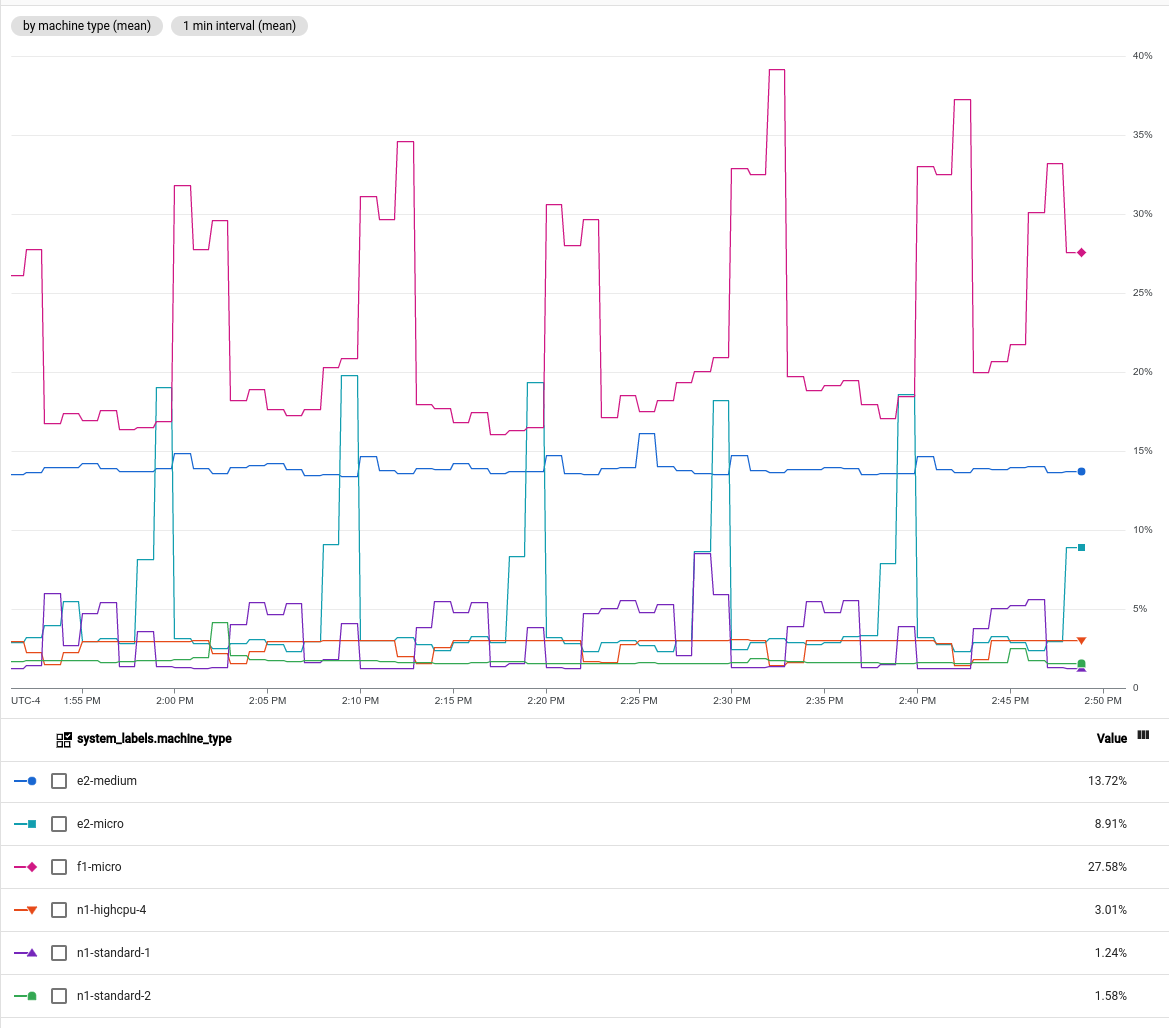
料金
一般に、Cloud Monitoring システムの指標は無料であり、外部システム、エージェント、またはアプリケーションの指標はそうではありません。課金対象の指標は、取り込まれたバイト数とサンプル数のいずれかによって課金されます。
詳細については、Google Cloud Observability の料金ページの Cloud Monitoring セクションをご覧ください。
次のステップ
- Cloud Monitoring を探索するには、Compute Engine インスタンスをモニタリングするためのクイックスタートをお試しください。
- 複数の Google Cloud プロジェクトと AWS アカウントの指標を表示するように Google Cloud プロジェクトを構成する方法については、指標スコープの概要をご覧ください。
Cloud Monitoring データモデルについては、指標、時系列、リソースをご覧ください。
Cloud Monitoring API の詳細については、API とリファレンスをご覧ください。
指標とモニタリング対象リソースの一覧については、指標の一覧とモニタリング対象リソースの一覧をご覧ください。