概要
このガイドでは、Google Kubernetes Engine(GKE)で複数のノードで画像処理装置(GPU)を使用して、DeepSeek-R1 671B や Llama 3.1 405B などの最先端の大規模言語モデル(LLM)をサービングする方法について説明します。
このガイドでは、ポータブルなオープンソース技術(Kubernetes、vLLM、LeaderWorkerSet(LWS)API)を使用して、GKE に AI / ML ワークロードをデプロイしてサービングする方法について説明します。これにより、GKE の詳細な制御、スケーラビリティ、復元力、ポータビリティ、費用対効果を活用できます。
このページを読む前に、次のことをよく理解しておいてください。
背景
このセクションでは、このガイドで使用されている重要なテクノロジーについて説明します。このガイドの例として使用されている 2 つの LLM(DeepSeek-R1 と Llama 3.1 405B)も含まれます。
DeepSeek-R1
DeepSeek-R1 は、DeepSeek が開発した 6,710 億個のパラメータを備えた大規模言語モデルで、さまざまなテキストベースのタスクにおける論理的推論、数学的推論、リアルタイムの問題解決を目的として設計されています。GKE は、DeepSeek-R1 のコンピューティング需要を処理し、スケーラブルなリソース、分散コンピューティング、効率的なネットワーキングによってその機能をサポートしています。
詳細については、DeepSeek のドキュメントをご覧ください。
Llama 3.1 405B
Llama 3.1 405B は、テキスト生成、翻訳、質問応答など、さまざまな自然言語処理タスク用に設計された Meta の大規模言語モデルです。GKE は、この規模のモデルの分散トレーニングとサービングの実現に欠かせない強固なインフラストラクチャを提供します。
詳細については、Llama のドキュメントをご覧ください。
GKE マネージド Kubernetes サービス
Google Cloud には、AI/ML ワークロードのデプロイと管理に適した GKE など、幅広いサービスが用意されています。GKE は、コンテナ化されたアプリケーションのデプロイ、スケーリング、管理を簡素化するマネージド Kubernetes サービスです。GKE は、LLM のコンピューティング需要を処理するために必要なインフラストラクチャ(スケーラブルなリソース、分散コンピューティング、効率的なネットワーキングなど)を提供します。
Kubernetes の主なコンセプトについて詳しくは、Kubernetes の学習を開始するをご覧ください。GKE の詳細と、GKE が Kubernetes のスケーリング、自動化、管理にどのように役立つかについては、GKE の概要をご覧ください。
GPU
画像処理装置(GPU)を使用すると、ML やデータ処理などの特定のワークロードを高速化できます。GKE には、これらの強力な GPU を搭載したノードが用意されています。これにより、ML タスクとデータ処理タスクで最適なパフォーマンスを実現するようにクラスタを構成できます。GKE には、NVIDIA H100、L4、A100 GPU を搭載したマシンタイプをはじめとして、ノード構成用のさまざまなマシンタイプ オプションが用意されています。
詳しくは、GKE での GPU についてをご覧ください。
LeaderWorkerSet(LWS)
LeaderWorkerSet(LWS)は、AI / ML マルチノード推論ワークロードの一般的なデプロイ パターンに対応する Kubernetes deployment API です。マルチノード サービングは、分散推論ワークロードを処理するために、それぞれが異なるノードで実行される可能性のある複数の Pod を活用します。LWS を使用すると、複数の Pod をグループとして扱うことができるため、分散モデル サービングの管理が簡素化されます。
vLLM とマルチホスト サービング
コンピューティング負荷の高い LLM を提供する場合は、vLLM を使用して、GPU 間でワークロードを実行することをおすすめします。
vLLM は、GPU のサービング スループットを向上できる、高度に最適化されたオープンソースの LLM サービング フレームワークであり、次のような機能を備えています。
- PagedAttention による Transformer の実装の最適化
- サービング スループットを全体的に向上させる連続的なバッチ処理
- 複数の GPU での分散サービング
1 つの GPU ノードに収まらない特に計算負荷の高い LLM では、複数の GPU ノードを使用してモデルをサービングできます。vLLM は、次の 2 つの方法による複数の GPU 間でのワークロードの実行をサポートしています。
テンソル並列処理では、Transformer レイヤの行列乗算を複数の GPU に分割します。ただし、この方法では GPU 間の通信が必要になるため、高速なネットワークが必要であり、ノード間でワークロードを実行する場合は適していません。
パイプライン並列処理では、モデルをレイヤ(垂直方向)で分割します。この方法では、GPU 間の通信を常に行う必要がないため、ノードをまたいでモデルを実行する場合に適しています。
マルチノード サービングでは、どちらの戦略も使用できます。たとえば、それぞれ 8 個の H100 GPU が割り当てられた 2 つのノードを使用する場合、次の方法はどちらでも使用できます。
- 2 つのノード間でモデルをシャーディングする 2 方向パイプライン並列処理
- 各ノードの 8 個の GPU 間でモデルをシャーディングする 8 方向テンソル並列処理
詳細については、vLLM のドキュメントをご覧ください。
GKE クラスタを作成する
GKE Autopilot クラスタまたは GKE Standard クラスタの複数の GPU ノードで vLLM を使用してモデルをサービングできます。フルマネージドの Kubernetes エクスペリエンスを実現するには、Autopilot クラスタを使用することをおすすめします。ワークロードに最適な GKE の運用モードを選択するには、GKE の運用モードを選択するをご覧ください。
Autopilot
Cloud Shell で、次のコマンドを実行します。
gcloud container clusters create-auto ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--location=${REGION} \
--cluster-version=${CLUSTER_VERSION}
Standard
2 つの CPU ノードを含む GKE Standard クラスタを作成します。
gcloud container clusters create CLUSTER_NAME \ --project=PROJECT_ID \ --num-nodes=2 \ --location=REGION \ --machine-type=e2-standard-162 つのノードと 8 つの H100 で構成される A3 ノードプールを作成します。
gcloud container node-pools create gpu-nodepool \ --node-locations=ZONE \ --num-nodes=2 \ --machine-type=a3-highgpu-8g \ --accelerator=type=nvidia-h100-80gb,count=8,gpu-driver-version=LATEST \ --placement-type=COMPACT \ --cluster=CLUSTER_NAME --location=${REGION}
クラスタと通信を行うように kubectl を構成します。
次のコマンドを使用して、クラスタと通信するように kubectl を構成します。
gcloud container clusters get-credentials CLUSTER_NAME --location=REGION
Hugging Face の認証情報用の Kubernetes Secret を作成する
次のコマンドを使用して、Hugging Face トークンを含む Kubernetes Secret を作成します。
kubectl create secret generic hf-secret \
--from-literal=hf_api_token=${HF_TOKEN} \
--dry-run=client -o yaml | kubectl apply -f -
LeaderWorkerSet をインストールする
LWS をインストールするには、次のコマンドを実行します。
kubectl apply --server-side -f https://github.com/kubernetes-sigs/lws/releases/latest/download/manifests.yaml
次のコマンドを使用して、LeaderWorkerSet コントローラが lws-system Namespace で実行されていることを確認します。
kubectl get pod -n lws-system
出力は次のようになります。
NAME READY STATUS RESTARTS AGE
lws-controller-manager-546585777-crkpt 1/1 Running 0 4d21h
lws-controller-manager-546585777-zbt2l 1/1 Running 0 4d21h
vLLM モデルサーバーをデプロイする
vLLM モデルサーバーをデプロイする手順は次のとおりです。
デプロイする LLM に応じてマニフェストを適用します。
DeepSeek-R1
マニフェスト
vllm-deepseek-r1-A3.yamlを調べます。次のコマンドを実行してマニフェストを適用します。
kubectl apply -f vllm-deepseek-r1-A3.yaml
Llama 3.1 405B
マニフェスト
vllm-llama3-405b-A3.yamlを調べます。次のコマンドを実行してマニフェストを適用します。
kubectl apply -f vllm-llama3-405b-A3.yaml
モデルのチェックポイントのダウンロードが完了するまで待ちます。このオペレーションは完了するまでに数分かかることがあります。
次のコマンドを使用して、実行中のモデルサーバーのログを表示します。
kubectl logs vllm-0 -c vllm-leader出力は次のようになります。
INFO 08-09 21:01:34 api_server.py:297] Route: /detokenize, Methods: POST INFO 08-09 21:01:34 api_server.py:297] Route: /v1/models, Methods: GET INFO 08-09 21:01:34 api_server.py:297] Route: /version, Methods: GET INFO 08-09 21:01:34 api_server.py:297] Route: /v1/chat/completions, Methods: POST INFO 08-09 21:01:34 api_server.py:297] Route: /v1/completions, Methods: POST INFO 08-09 21:01:34 api_server.py:297] Route: /v1/embeddings, Methods: POST INFO: Started server process [7428] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
モデルをサービングする
次のコマンドを実行して、モデルへのポート転送を設定します。
kubectl port-forward svc/vllm-leader 8080:8080
curl を使用してモデルを操作する
curl を使用してモデルを操作する手順は次のとおりです。
DeepSeek-R1
新しいターミナルで、サーバーにリクエストを送信します。
curl http://localhost:8080/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-ai/DeepSeek-R1",
"prompt": "I have four boxes. I put the red box on the bottom and put the blue box on top. Then I put the yellow box on top the blue. Then I take the blue box out and put it on top. And finally I put the green box on the top. Give me the final order of the boxes from bottom to top. Show your reasoning but be brief",
"max_tokens": 1024,
"temperature": 0
}'
出力例を以下に示します。
{
"id": "cmpl-f2222b5589d947419f59f6e9fe24c5bd",
"object": "text_completion",
"created": 1738269669,
"model": "deepseek-ai/DeepSeek-R1",
"choices": [
{
"index": 0,
"text": ".\n\nOkay, let's see. The user has four boxes and is moving them around. Let me try to visualize each step. \n\nFirst, the red box is placed on the bottom. So the stack starts with red. Then the blue box is put on top of red. Now the order is red (bottom), blue. Next, the yellow box is added on top of blue. So now it's red, blue, yellow. \n\nThen the user takes the blue box out. Wait, blue is in the middle. If they remove blue, the stack would be red and yellow. But where do they put the blue box? The instruction says to put it on top. So after removing blue, the stack is red, yellow. Then blue is placed on top, making it red, yellow, blue. \n\nFinally, the green box is added on the top. So the final order should be red (bottom), yellow, blue, green. Let me double-check each step to make sure I didn't mix up any steps. Starting with red, then blue, then yellow. Remove blue from the middle, so yellow is now on top of red. Then place blue on top of that, so red, yellow, blue. Then green on top. Yes, that seems right. The key step is removing the blue box from the middle, which leaves yellow on red, then blue goes back on top, followed by green. So the final order from bottom to top is red, yellow, blue, green.\n\n**Final Answer**\nThe final order from bottom to top is \\boxed{red}, \\boxed{yellow}, \\boxed{blue}, \\boxed{green}.\n</think>\n\n1. Start with the red box at the bottom.\n2. Place the blue box on top of the red box. Order: red (bottom), blue.\n3. Place the yellow box on top of the blue box. Order: red, blue, yellow.\n4. Remove the blue box (from the middle) and place it on top. Order: red, yellow, blue.\n5. Place the green box on top. Final order: red, yellow, blue, green.\n\n\\boxed{red}, \\boxed{yellow}, \\boxed{blue}, \\boxed{green}",
"logprobs": null,
"finish_reason": "stop",
"stop_reason": null,
"prompt_logprobs": null
}
],
"usage": {
"prompt_tokens": 76,
"total_tokens": 544,
"completion_tokens": 468,
"prompt_tokens_details": null
}
}
Llama 3.1 405B
新しいターミナルで、サーバーにリクエストを送信します。
curl http://localhost:8080/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "meta-llama/Meta-Llama-3.1-405B-Instruct",
"prompt": "San Francisco is a",
"max_tokens": 7,
"temperature": 0
}'
出力例を以下に示します。
{"id":"cmpl-0a2310f30ac3454aa7f2c5bb6a292e6c",
"object":"text_completion","created":1723238375,"model":"meta-llama/Llama-3.1-405B-Instruct","choices":[{"index":0,"text":" top destination for foodies, with","logprobs":null,"finish_reason":"length","stop_reason":null}],"usage":{"prompt_tokens":5,"total_tokens":12,"completion_tokens":7}}
カスタム オートスケーラーを設定する
このセクションでは、カスタム Prometheus 指標を使用するように水平 Pod 自動スケーリングを設定します。vLLM サーバーから Google Cloud Managed Service for Prometheus の指標を使用します。
詳細については、Google Cloud Managed Service for Prometheus をご覧ください。これは GKE クラスタでデフォルトで有効になっています。
クラスタにカスタム指標の Stackdriver アダプタを設定します。
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/k8s-stackdriver/master/custom-metrics-stackdriver-adapter/deploy/production/adapter_new_resource_model.yamlカスタム指標の Stackdriver アダプタが使用するサービス アカウントに Monitoring 閲覧者のロールを追加します。
gcloud projects add-iam-policy-binding projects/PROJECT_ID \ --role roles/monitoring.viewer \ --member=principal://iam.googleapis.com/projects/PROJECT_NUMBER/locations/global/workloadIdentityPools/PROJECT_ID.svc.id.goog/subject/ns/custom-metrics/sa/custom-metrics-stackdriver-adapter次のマニフェストを
vllm_pod_monitor.yamlとして保存します。マニフェストをクラスタに適用します。
kubectl apply -f vllm_pod_monitor.yaml
vLLM エンドポイントに負荷を生成する
vLLM サーバーに負荷をかけて、GKE がカスタム vLLM 指標で自動スケーリングする方法を確認します。
モデルへのポート転送を設定します。
kubectl port-forward svc/vllm-leader 8080:8080bash スクリプト(
load.sh)を実行して、N個の並列リクエストを vLLM エンドポイントに送信します。#!/bin/bash # Set the number of parallel processes to run. N=PARALLEL_PROCESSES # Get the external IP address of the vLLM load balancer service. export vllm_service=$(kubectl get service vllm-service -o jsonpath='{.status.loadBalancer.ingress[0].ip}') # Loop from 1 to N to start the parallel processes. for i in $(seq 1 $N); do # Start an infinite loop to continuously send requests. while true; do # Use curl to send a completion request to the vLLM service. curl http://$vllm_service:8000/v1/completions -H "Content-Type: application/json" -d '{"model": "meta-llama/Llama-3.1-70B", "prompt": "Write a story about san francisco", "max_tokens": 100, "temperature": 0}' done & # Run in the background done # Keep the script running until it is manually stopped. waitPARALLEL_PROCESSES は、実行する並列プロセスの数に置き換えます。
bash スクリプトを実行します。
nohup ./load.sh &
Google Cloud Managed Service for Prometheus が指標を取り込むことを確認する
Google Cloud Managed Service for Prometheus が指標をスクレイピングし、vLLM エンドポイントに負荷をかけると、Cloud Monitoring で指標を表示できます。
Google Cloud コンソールで、Metrics Explorer のページに移動します。
[< > PromQL] をクリックします。
次のクエリを入力して、トラフィック指標を確認します。
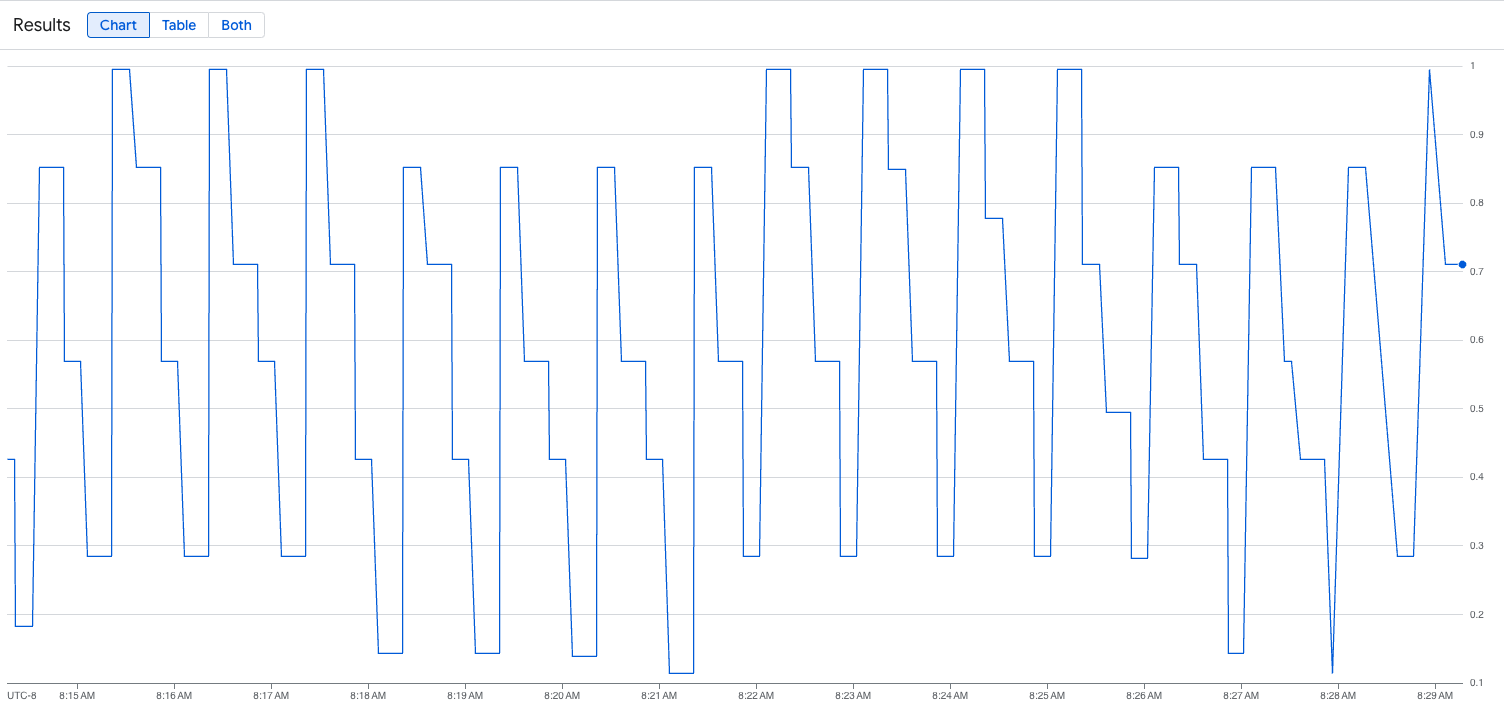
vllm:gpu_cache_usage_perc{cluster='CLUSTER_NAME'}
次の画像は、ロード スクリプト実行後のグラフの例です。このグラフは、vLLM エンドポイントに追加された負荷に応じて、Google Cloud Managed Service for Prometheus がトラフィック指標を取り込んでいることを示しています。
HorizontalPodAutoscaler 構成をデプロイする
自動スケーリングする指標を決定する場合は、vLLM に次の指標を使用することをおすすめします。
num_requests_waiting: この指標は、モデルサーバーのキューで待機しているリクエストの数に関連しています。この数は、kv キャッシュがいっぱいになると著しく増加します。gpu_cache_usage_perc: この指標は kv キャッシュの使用率に関連しており、モデルサーバーで特定の推論サイクルで処理されるリクエスト数に直接関連しています。
スループットと費用を最適化する場合、また、モデルサーバーの最大スループットでレイテンシ目標を達成できる場合は、num_requests_waiting を使用することをおすすめします。
キューベースのスケーリングでは要件を満たせない、レイテンシの影響を受けやすいワークロードがある場合は、gpu_cache_usage_perc を使用することをおすすめします。
詳細については、GPU を使用して大規模言語モデル(LLM)推論ワークロードを自動スケーリングするためのベスト プラクティスをご覧ください。
HPA 構成の averageValue ターゲットを選択する場合は、自動スケーリングに使用する指標をテストで決定する必要があります。テストを最適化する方法については、ブログ投稿 GPU のコストを削減: GKE の推論ワークロード向けのスマートな自動スケーリングをご覧ください。このブログ投稿で使用した profile-generator は vLLM でも機能します。
num_requests_waiting を使用して HorizontalPodAutoscaler 構成をデプロイする手順は次のとおりです。
次のマニフェストを
vllm-hpa.yamlとして保存します。Google Cloud Managed Service for Prometheus の vLLM 指標は
vllm:metric_name形式に従います。ベスト プラクティス: スループットをスケーリングするには
num_requests_waitingを使用します。レイテンシの影響を受けやすい GPU のユースケースにはgpu_cache_usage_percを使用します。HorizontalPodAutoscaler 構成をデプロイします。
kubectl apply -f vllm-hpa.yamlGKE は、デプロイする別の Pod をスケジュールします。これにより、ノードプール オートスケーラーがトリガーされ、2 番目の vLLM レプリカをデプロイする前に 2 番目のノードを追加します。
Pod の自動スケーリングの進行状況を確認します。
kubectl get hpa --watch出力は次のようになります。
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE lws-hpa LeaderWorkerSet/vllm 0/1 1 2 1 6d1h lws-hpa LeaderWorkerSet/vllm 1/1 1 2 1 6d1h lws-hpa LeaderWorkerSet/vllm 0/1 1 2 1 6d1h lws-hpa LeaderWorkerSet/vllm 4/1 1 2 1 6d1h lws-hpa LeaderWorkerSet/vllm 0/1 1 2 2 6d1h
Google Cloud Hyperdisk ML でモデルの読み込み時間を短縮する
このようなタイプの LLM では、vLLM がそれぞれの新しいレプリカでダウンロード、読み込み、ウォームアップを完了するまでに時間がかかる可能性があります。たとえば、Llama 3.1 405B では、このプロセスに約 90 分かかります。モデルを Hyperdisk ML ボリュームに直接ダウンロードし、そのボリュームを各 Pod にマウントすることで、この時間を短縮できます(Llama 3.1 405B の場合は 20 分)。この処理を完了するため、このチュートリアルでは Hyperdisk ML ボリュームと Kubernetes Job を使用します。Kubernetes の Job コントローラは、1 つ以上の Pod を作成し、特定のタスクが正常に実行されるようにします。
モデルの読み込み時間を短縮するには、次の操作を行います。
次のマニフェストの例を
producer-pvc.yamlとして保存します。kind: PersistentVolumeClaim apiVersion: v1 metadata: name: producer-pvc spec: # Specifies the StorageClass to use. Hyperdisk ML is optimized for ML workloads. storageClassName: hyperdisk-ml accessModes: - ReadWriteOnce resources: requests: storage: 800Gi次のマニフェストの例を
producer-job.yamlとして保存します。DeepSeek-R1
Llama 3.1 405B
前の手順で作成した 2 つのファイルを使用して、Hyperdisk ML で AI / ML データの読み込みを高速化するの説明に従って操作します。
この手順を完了すると、Hyperdisk ML ボリュームが作成され、モデルデータが自動的に入力されます。
vLLM マルチノード GPU サーバーのデプロイメントをデプロイします。このデプロイでは、モデルデータに新しく作成された Hyperdisk ML ボリュームが使用されます。
DeepSeek-R1
Llama 3.1 405B