Esegui una query
Questo documento mostra come eseguire una query in BigQuery e capire quanti dati verranno elaborati dalla query prima dell'esecuzione eseguendo un'esecuzione di prova.
Tipi di query
Puoi eseguire query sui dati BigQuery utilizzando uno dei seguenti tipi di job di query:
Job di query interattive. Per impostazione predefinita, BigQuery esegue le query come job di query interattive, che devono iniziare l'esecuzione il più rapidamente possibile.
Job di query batch. Le query batch hanno una priorità inferiore rispetto alle query interattive. Quando un progetto o una prenotazione utilizza tutte le risorse di calcolo disponibili, è più probabile che le query batch vengano messe in coda e rimangano in coda. Dopo l'avvio di una query batch, questa viene eseguita come una query interattiva. Per ulteriori informazioni, consulta la sezione Code di query.
Job di query continui. Con questi job, la query viene eseguita continuamente, consentendoti di analizzare i dati in entrata in BigQuery in tempo reale e quindi scrivere i risultati in una tabella BigQuery o esportarli in Bigtable o Pub/Sub. Puoi utilizzare questa funzionalità per eseguire attività sensibili al tempo, come creare e agire immediatamente in base agli approfondimenti, applicare l'inferenza di machine learning (ML) in tempo reale e creare pipeline di dati basate su eventi.
Puoi eseguire job di query utilizzando i seguenti metodi:
- Componi ed esegui una query nella consoleGoogle Cloud .
- Esegui il comando
bq querynello strumento a riga di comando bq. - Chiama in modo programmatico il metodo
jobs.queryojobs.insertnell'API REST di BigQuery. - Utilizza le librerie client di BigQuery.
BigQuery salva i risultati delle query in una tabella temporanea (impostazione predefinita) o in una tabella permanente. Quando specifichi una tabella permanente come tabella di destinazione per i risultati, puoi scegliere se aggiungere o sovrascrivere una tabella esistente oppure creare una nuova tabella con un nome univoco.
Ruoli obbligatori
Per ottenere le autorizzazioni necessarie per eseguire un job di query, chiedi all'amministratore di concederti i seguenti ruoli IAM:
-
Utente job BigQuery (
roles/bigquery.jobUser) sul progetto. -
Visualizzatore dati BigQuery (
roles/bigquery.dataViewer) su tutte le tabelle e le viste a cui fa riferimento la query. Per eseguire query sulle viste, devi disporre di questo ruolo anche su tutte le tabelle e le viste sottostanti. Se utilizzi viste autorizzate o set di dati autorizzati, non hai bisogno dell'accesso ai dati di origine sottostanti.
Per ulteriori informazioni sulla concessione dei ruoli, consulta Gestisci l'accesso a progetti, cartelle e organizzazioni.
Questi ruoli predefiniti contengono le autorizzazioni necessarie per eseguire un job di query. Per vedere quali sono esattamente le autorizzazioni richieste, espandi la sezione Autorizzazioni obbligatorie:
Autorizzazioni obbligatorie
Per eseguire un job di query sono necessarie le seguenti autorizzazioni:
-
bigquery.jobs.createsul progetto da cui viene eseguita la query, indipendentemente da dove sono archiviati i dati. -
bigquery.tables.getDatasu tutte le tabelle e le viste a cui fa riferimento la query. Per eseguire query sulle viste, devi disporre di questa autorizzazione anche per tutte le tabelle e le viste sottostanti. Se utilizzi viste autorizzate o set di dati autorizzati, non devi accedere ai dati di origine sottostanti.
Potresti anche ottenere queste autorizzazioni con ruoli personalizzati o altri ruoli predefiniti.
Risoluzione dei problemi
Access Denied: Project [project_id]: User does not have bigquery.jobs.create
permission in project [project_id].
Questo errore si verifica quando un principal non dispone dell'autorizzazione per creare query nel progetto.
Risoluzione: un amministratore deve concederti l'autorizzazione bigquery.jobs.create
per il progetto che stai interrogando. Questa autorizzazione è richiesta
in aggiunta a qualsiasi autorizzazione necessaria per accedere ai dati sottoposti a query.
Per saperne di più sulle autorizzazioni BigQuery, consulta Controllo dell'accesso con IAM.
Eseguire una query interattiva
Per eseguire una query interattiva, seleziona una delle seguenti opzioni:
Console
Vai alla pagina BigQuery.
Fai clic su Query SQL.
Nell'editor di query, inserisci una query GoogleSQL valida.
Ad esempio, esegui una query sul set di dati pubblico BigQuery
usa_namesper determinare i nomi più comuni negli Stati Uniti tra il 1910 e il 2013:SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;In alternativa, puoi utilizzare il riquadro Riferimento per creare nuove query.
(Facoltativo) Per visualizzare automaticamente i suggerimenti di codice quando digiti una query, fai clic su Altro e poi seleziona Completamento automatico SQL. Se non hai bisogno di suggerimenti per il completamento automatico, deseleziona Completamento automatico SQL. In questo modo vengono disattivati anche i suggerimenti di compilazione automatica del nome del progetto.
(Facoltativo) Per selezionare impostazioni query aggiuntive, fai clic su Altro e poi su Impostazioni query.
Fai clic su Esegui.
Se non specifichi una tabella di destinazione, il job query scrive l'output in una tabella temporanea (cache).
Ora puoi esplorare i risultati della query nella scheda Risultati del riquadro Risultati query.
(Facoltativo) Per ordinare i risultati della query per colonna, fai clic su Apri menu di ordinamento accanto al nome della colonna e seleziona un ordinamento. Se i byte stimati elaborati per l'ordinamento sono maggiori di zero, il numero di byte viene visualizzato nella parte superiore del menu.
(Facoltativo) Per visualizzare la visualizzazione dei risultati della query, vai alla scheda Visualizzazione. Puoi ingrandire o ridurre il grafico, scaricarlo come file PNG o attivare/disattivare la visibilità della legenda.
Nel riquadro Configurazione visualizzazione puoi modificare il tipo di visualizzazione e configurare le misure e le dimensioni della visualizzazione. I campi in questo riquadro sono precompilati con la configurazione iniziale dedotta dallo schema della tabella di destinazione della query. La configurazione viene mantenuta tra le esecuzioni di query successive nello stesso editor di query.
Per le visualizzazioni a linee, a barre o a dispersione, le dimensioni supportate sono i tipi di dati
INT64,FLOAT64,NUMERIC,BIGNUMERIC,TIMESTAMP,DATE,DATETIME,TIMEeSTRING, mentre le metriche supportate sono i tipi di datiINT64,FLOAT64,NUMERICeBIGNUMERIC.Se i risultati della query includono il tipo
GEOGRAPHY, Mappa è il tipo di visualizzazione predefinito, che ti consente di visualizzare i risultati su una mappa interattiva.(Facoltativo) Nella scheda JSON, puoi esplorare i risultati della query in formato JSON, dove la chiave è il nome della colonna e il valore è il risultato per quella colonna.
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Utilizza il comando
bq query. Nell'esempio seguente, il flag--use_legacy_sql=falseconsente di utilizzare la sintassi GoogleSQL.bq query \ --use_legacy_sql=false \ 'QUERY'
Sostituisci QUERY con una query GoogleSQL valida. Ad esempio, esegui una query sul set di dati pubblico BigQuery
usa_namesper determinare i nomi più comuni negli Stati Uniti tra il 1910 e il 2013:bq query \ --use_legacy_sql=false \ 'SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;'Il job query scrive l'output in una tabella temporanea (cache).
Se vuoi, puoi specificare la tabella di destinazione e la posizione per i risultati della query. Per scrivere i risultati in una tabella esistente, includi il flag appropriato per aggiungere (
--append_table=true) o sovrascrivere (--replace=true) la tabella.bq query \ --location=LOCATION \ --destination_table=TABLE \ --use_legacy_sql=false \ 'QUERY'
Sostituisci quanto segue:
LOCATION: la regione o la multiregione per la tabella di destinazione, ad esempio
USIn questo esempio, il set di dati
usa_namesè archiviato nella località con più regioni Stati Uniti. Se specifichi una tabella di destinazione per questa query, anche il set di dati che contiene la tabella di destinazione deve trovarsi nella multi-regione Stati Uniti. Non puoi eseguire query su un set di dati in una posizione e scrivere i risultati in una tabella in un'altra posizione.Puoi impostare un valore predefinito per la località utilizzando il file.bigqueryrc.
TABLE: un nome per la tabella di destinazione, ad esempio
myDataset.myTableSe la tabella di destinazione è una nuova tabella, BigQuery la crea quando esegui la query. Tuttavia, devi specificare un set di dati esistente.
Se la tabella non si trova nel progetto corrente, aggiungi l'ID progettoGoogle Cloud utilizzando il formato
PROJECT_ID:DATASET.TABLE, ad esempiomyProject:myDataset.myTable. Se--destination_tablenon è specificato, viene generato un job query che scrive l'output in una tabella temporanea.
API
Per eseguire una query utilizzando l'API, inserisci un nuovo job e compila la proprietà di configurazione del job query. Se vuoi, specifica la tua
posizione nella proprietà location della sezione jobReference della
risorsa job.
Richiedi i risultati chiamando
getQueryResults.
Sondaggio fino a jobComplete uguale a true. Controlla la presenza di errori e avvisi nell'elenco
errors.
C#
Prima di provare questo esempio, segui le istruzioni di configurazione di C# nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery C#.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Vai
Prima di provare questo esempio, segui le istruzioni di configurazione di Go nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Go.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Java
Prima di provare questo esempio, segui le istruzioni di configurazione di Java nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Java.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Per eseguire una query con un proxy, consulta Configurazione di un proxy.
Node.js
Prima di provare questo esempio, segui le istruzioni di configurazione di Node.js nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Node.js.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
PHP
Prima di provare questo esempio, segui le istruzioni di configurazione di PHP nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery PHP.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Python
Prima di provare questo esempio, segui le istruzioni di configurazione di Python nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Python.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Ruby
Prima di provare questo esempio, segui le istruzioni di configurazione di Ruby nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Ruby.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Eseguire una query batch
Per eseguire una query batch, seleziona una delle seguenti opzioni:
Console
Vai alla pagina BigQuery.
Fai clic su Query SQL.
Nell'editor di query, inserisci una query GoogleSQL valida.
Ad esempio, esegui una query sul set di dati pubblico BigQuery
usa_namesper determinare i nomi più comuni negli Stati Uniti tra il 1910 e il 2013:SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;Fai clic su Altro, quindi fai clic su Impostazioni query.
Nella sezione Gestione risorse, seleziona Batch.
(Facoltativo) Modifica le impostazioni della query.
Fai clic su Salva.
Fai clic su Esegui.
Se non specifichi una tabella di destinazione, il job query scrive l'output in una tabella temporanea (cache).
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Utilizza il comando
bq querye specifica il flag--batch. Nell'esempio seguente, il flag--use_legacy_sql=falseconsente di utilizzare la sintassi GoogleSQL.bq query \ --batch \ --use_legacy_sql=false \ 'QUERY'
Sostituisci QUERY con una query GoogleSQL valida. Ad esempio, esegui una query sul set di dati pubblico BigQuery
usa_namesper determinare i nomi più comuni negli Stati Uniti tra il 1910 e il 2013:bq query \ --batch \ --use_legacy_sql=false \ 'SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;'Il job query scrive l'output in una tabella temporanea (cache).
Se vuoi, puoi specificare la tabella di destinazione e la posizione per i risultati della query. Per scrivere i risultati in una tabella esistente, includi il flag appropriato per aggiungere (
--append_table=true) o sovrascrivere (--replace=true) la tabella.bq query \ --batch \ --location=LOCATION \ --destination_table=TABLE \ --use_legacy_sql=false \ 'QUERY'
Sostituisci quanto segue:
LOCATION: la regione o la multiregione per la tabella di destinazione, ad esempio
USIn questo esempio, il set di dati
usa_namesè archiviato nella località con più regioni Stati Uniti. Se specifichi una tabella di destinazione per questa query, anche il set di dati che contiene la tabella di destinazione deve trovarsi nella multi-regione Stati Uniti. Non puoi eseguire query su un set di dati in una posizione e scrivere i risultati in una tabella in un'altra posizione.Puoi impostare un valore predefinito per la località utilizzando il file.bigqueryrc.
TABLE: un nome per la tabella di destinazione, ad esempio
myDataset.myTableSe la tabella di destinazione è una nuova tabella, BigQuery la crea quando esegui la query. Tuttavia, devi specificare un set di dati esistente.
Se la tabella non si trova nel progetto corrente, aggiungi l'ID progettoGoogle Cloud utilizzando il formato
PROJECT_ID:DATASET.TABLE, ad esempiomyProject:myDataset.myTable. Se--destination_tablenon è specificato, viene generato un job query che scrive l'output in una tabella temporanea.
API
Per eseguire una query utilizzando l'API, inserisci un nuovo job e compila la proprietà di configurazione del job query. Se vuoi, specifica la tua
posizione nella proprietà location della sezione jobReference della
risorsa job.
Quando compili le proprietà del job di query, includi la proprietà configuration.query.priority e imposta il valore su BATCH.
Richiedi i risultati chiamando
getQueryResults.
Sondaggio fino a jobComplete uguale a true. Controlla la presenza di errori e avvisi nell'elenco
errors.
Vai
Prima di provare questo esempio, segui le istruzioni di configurazione di Go nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Go.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Java
Per eseguire una query batch, imposta la priorità della query su QueryJobConfiguration.Priority.BATCH quando crei una QueryJobConfiguration.
Prima di provare questo esempio, segui le istruzioni di configurazione di Java nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Java.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Node.js
Prima di provare questo esempio, segui le istruzioni di configurazione di Node.js nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Node.js.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Python
Prima di provare questo esempio, segui le istruzioni di configurazione di Python nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Python.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Eseguire una query continua
L'esecuzione di un job di query continua richiede una configurazione aggiuntiva. Per ulteriori informazioni, vedi Creare query continue.
Utilizzare il riquadro Riferimento
Nell'editor di query, il riquadro Riferimento mostra in modo dinamico informazioni sensibili al contesto su tabelle, snapshot, viste e viste materializzate. Il riquadro ti consente di visualizzare l'anteprima dei dettagli dello schema di queste risorse o di aprirle in una nuova scheda. Puoi anche utilizzare il riquadro Riferimento per creare nuove query o modificare quelle esistenti inserendo snippet di query o nomi di campi.
Per creare una nuova query utilizzando il riquadro Riferimento:
Nella console Google Cloud , vai alla pagina BigQuery.
Fai clic su Query SQL.
Fai clic su quick_reference_all Riferimento.
Fai clic su una tabella o una visualizzazione recente o aggiunta a Speciali. Puoi anche utilizzare la barra di ricerca per trovare tabelle e viste.
Fai clic su Visualizza azioni, quindi fai clic su Inserisci snippet di query.
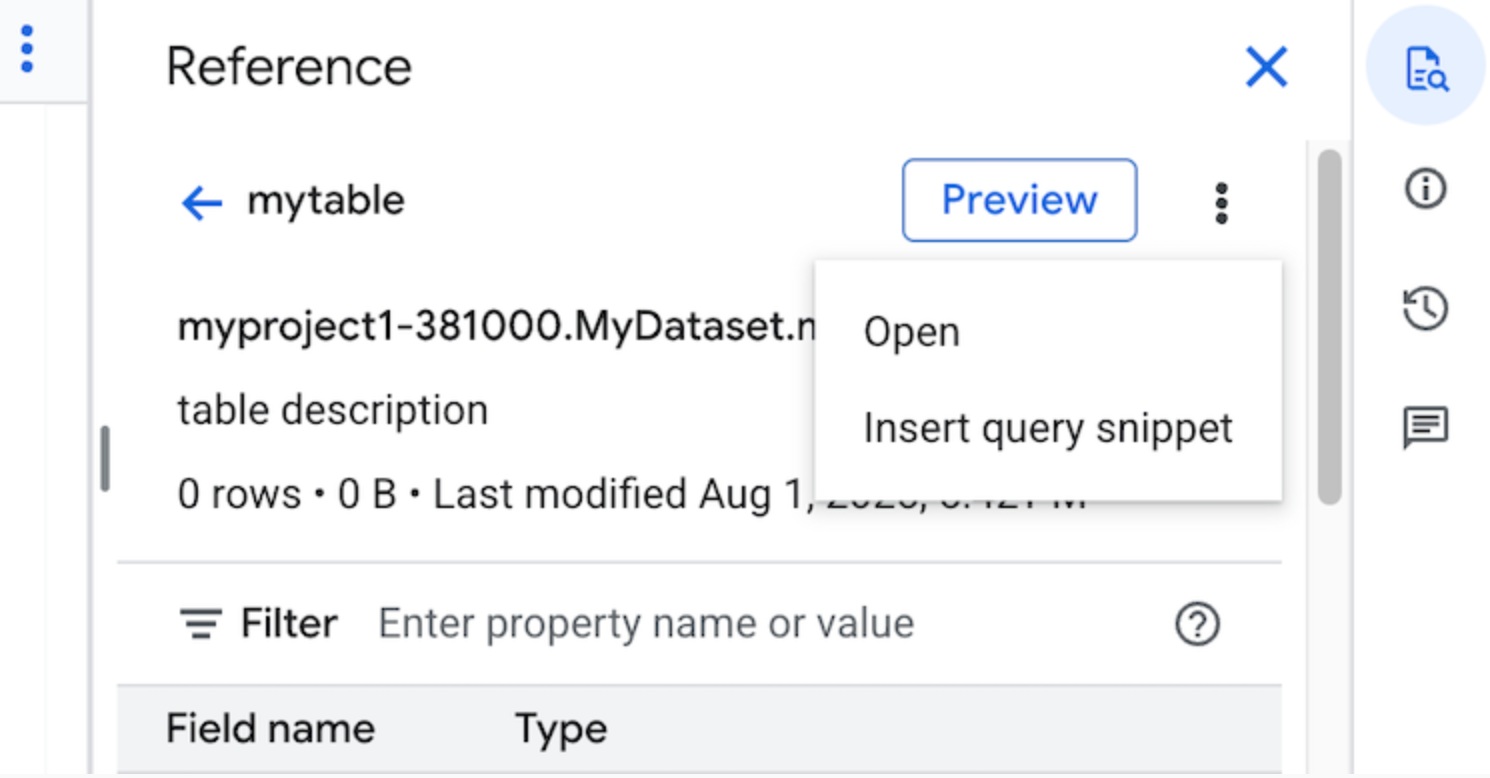
(Facoltativo) Puoi visualizzare l'anteprima dei dettagli dello schema della tabella o della vista oppure aprirli in una nuova scheda.
Ora puoi modificare la query manualmente o inserire i nomi dei campi direttamente nella query. Per inserire un nome di campo, fai clic su un punto dell'editor di query in cui vuoi inserire il nome del campo, quindi fai clic sul nome del campo nel riquadro Riferimento.
Impostazioni query
Quando esegui una query, puoi specificare le seguenti impostazioni:
Una tabella di destinazione per i risultati della query.
La priorità del job.
Se utilizzare i risultati delle query memorizzati nella cache.
Timeout del job in millisecondi.
Se utilizzare la modalità sessione.
Il tipo di crittografia da utilizzare.
Il numero massimo di byte fatturati per la query.
Il dialetto SQL da utilizzare.
La posizione in cui eseguire la query. La query deve essere eseguita nella stessa località di tutte le tabelle a cui fa riferimento.
La prenotazione per eseguire la query in (anteprima).
Modalità di creazione dei job facoltativa
La modalità di creazione dei job facoltativa può migliorare la latenza complessiva delle query eseguite
per un breve periodo di tempo, ad esempio quelle dei workload di dashboard o di esplorazione dei dati. Questa modalità esegue la query e restituisce i risultati in linea per le istruzioni
SELECT senza richiedere l'utilizzo di
jobs.getQueryResults
per recuperare i risultati. Le query che utilizzano la modalità di creazione facoltativa dei job non creano un job quando vengono eseguite, a meno che BigQuery non determini che la creazione di un job sia necessaria per completare la query.
Per attivare la modalità di creazione dei job facoltativa, imposta il campo jobCreationMode dell'istanza
QueryRequest su JOB_CREATION_OPTIONAL nel corpo della richiesta
jobs.query.
Quando il valore di questo campo è impostato su JOB_CREATION_OPTIONAL,
BigQuery determina se la query può utilizzare la modalità di creazione
del job facoltativa. In questo caso, BigQuery esegue la query e restituisce
tutti i risultati nel campo rows della risposta. Poiché per questa query non viene creato un job, BigQuery non restituisce un jobReference nel corpo della risposta. Restituisce invece un campo queryId, che puoi utilizzare per ottenere
approfondimenti sulla query utilizzando la visualizzazione INFORMATION_SCHEMA.JOBS. Poiché non viene creato alcun job, non è possibile passare alcun jobReference alle API jobs.get e jobs.getQueryResults per cercare queste query.
Se BigQuery determina che è necessario un job per completare la
query, viene restituito un jobReference. Puoi esaminare il campo job_creation_reason
nella visualizzazione
INFORMATION_SCHEMA.JOBS per determinare
il motivo per cui è stato creato un job per la query. In questo caso, devi utilizzare
jobs.getQueryResults
per recuperare i risultati al termine della query.
Quando utilizzi il valore JOB_CREATION_OPTIONAL, il campo jobReference potrebbe
non essere presente nella risposta. Verifica che il campo esista prima di accedervi.
Quando JOB_CREATION_OPTIONAL viene specificato per le query multi-istruzione (script),
BigQuery potrebbe ottimizzare il processo di esecuzione. Nell'ambito di questa
ottimizzazione, BigQuery potrebbe determinare di poter completare lo
script creando meno risorse job rispetto al numero di singole istruzioni,
potenzialmente anche eseguendo l'intero script senza creare alcun job.
Questa ottimizzazione dipende dalla valutazione dello script da parte di BigQuery e
potrebbe non essere applicata in tutti i casi. L'ottimizzazione è completamente
automatizzata dal sistema. Non sono richiesti controlli o azioni da parte dell'utente.
Per eseguire una query utilizzando la modalità di creazione facoltativa del job, seleziona una delle seguenti opzioni:
Console
Vai alla pagina BigQuery.
Fai clic su Query SQL.
Nell'editor di query, inserisci una query GoogleSQL valida.
Ad esempio, esegui una query sul set di dati pubblico BigQuery
usa_namesper determinare i nomi più comuni negli Stati Uniti tra il 1910 e il 2013:SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;Fai clic su Altro e poi scegli la modalità di query Creazione dei job facoltativa. Per confermare questa scelta, fai clic su Conferma.
Fai clic su Esegui.
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Utilizza il comando
bq querye specifica il flag--job_creation_mode=JOB_CREATION_OPTIONAL. Nell'esempio seguente, il flag--use_legacy_sql=falseconsente di utilizzare la sintassi GoogleSQL.bq query \ --rpc=true \ --use_legacy_sql=false \ --job_creation_mode=JOB_CREATION_OPTIONAL \ --location=LOCATION \ 'QUERY'
Sostituisci QUERY con una query GoogleSQL valida e LOCATION con una regione valida in cui si trova il set di dati. Ad esempio, esegui una query sul set di dati pubblico BigQuery
usa_namesper determinare i nomi più comuni negli Stati Uniti tra il 1910 e il 2013:bq query \ --rpc=true \ --use_legacy_sql=false \ --job_creation_mode=JOB_CREATION_OPTIONAL \ --location=us \ 'SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;'Il job di query restituisce l'output incorporato nella risposta.
API
Per eseguire una query in modalità di creazione facoltativa del job utilizzando l'API, esegui una query in modo sincrono
e compila la proprietà QueryRequest. Includi la proprietà jobCreationMode e impostane il valore su JOB_CREATION_OPTIONAL.
Controlla la risposta. Se jobComplete è uguale a true e jobReference è vuoto, leggi i risultati dal campo rows. Puoi anche ottenere il queryId dalla risposta.
Se è presente jobReference, puoi controllare jobCreationReason per scoprire perché un job è stato creato da BigQuery. Richiedi i risultati chiamando
getQueryResults.
Sondaggio fino a jobComplete uguale a true. Controlla la presenza di errori e avvisi nell'elenco
errors.
Java
Versione disponibile: 2.51.0 e successive
Prima di provare questo esempio, segui le istruzioni di configurazione di Java nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Java.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Per eseguire una query con un proxy, consulta Configurazione di un proxy.
Python
Versione disponibile: 3.34.0 e successive
Prima di provare questo esempio, segui le istruzioni di configurazione di Python nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Python.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Nodo
Versioni disponibili: 8.1.0 e successive
Prima di provare questo esempio, segui le istruzioni di configurazione di Node.js nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Node.js.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Vai
Versione disponibile: 1.69.0 e successive
Prima di provare questo esempio, segui le istruzioni di configurazione di Go nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Go.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Driver JDBC
Versione disponibile: JDBC v1.6.1 e successive
Richiede l'impostazione di JobCreationMode=2 nella stringa di connessione.
jdbc:bigquery://https://www.googleapis.com/bigquery/v2:443;JobCreationMode=2;Location=US;
Driver ODBC
Versione disponibile: ODBC v3.0.7.1016 e successive
Richiede l'impostazione di JobCreationMode=2 nel file .ini.
[ODBC Data Sources] Sample DSN=Simba Google BigQuery ODBC Connector 64-bit [Sample DSN] JobCreationMode=2
Quote
Per informazioni sulle quote relative alle query interattive e batch, consulta la sezione Job di query.
Monitorare le query
Puoi ottenere informazioni sulle query durante l'esecuzione utilizzando lo
strumento di esplorazione dei job o eseguendo query sulla
vista INFORMATION_SCHEMA.JOBS_BY_PROJECT.
Dry run
Una prova in BigQuery fornisce le seguenti informazioni:
- stima dei costi in modalità on demand
- convalida della query
- byte approssimativi elaborati dalla query in modalità capacità
Le prove non utilizzano slot di query e non ti viene addebitato alcun costo per l'esecuzione di una prova. Puoi utilizzare la stima restituita da un test dry run per calcolare i costi delle query nel Calcolatore prezzi.
Eseguire una prova
Per eseguire un dry run:
Console
Vai alla pagina BigQuery.
Inserisci la query nell'editor di query.
Se la query è valida, viene visualizzato automaticamente un segno di spunta insieme alla quantità di dati che verranno elaborati dalla query. Se la query non è valida, viene visualizzato un punto esclamativo con un messaggio di errore.
bq
Inserisci una query come la seguente utilizzando il flag --dry_run.
bq query \ --use_legacy_sql=false \ --dry_run \ 'SELECT COUNTRY, AIRPORT, IATA FROM `project_id`.dataset.airports LIMIT 1000'
Per una query valida, il comando produce la seguente risposta:
Query successfully validated. Assuming the tables are not modified, running this query will process 10918 bytes of data.
API
Per eseguire una prova utilizzando l'API, invia un job di query con
dryRun impostato su true nel tipo
JobConfiguration.
Vai
Prima di provare questo esempio, segui le istruzioni di configurazione di Go nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Go.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Java
Prima di provare questo esempio, segui le istruzioni di configurazione di Java nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Java.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Node.js
Prima di provare questo esempio, segui le istruzioni di configurazione di Node.js nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Node.js.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
PHP
Prima di provare questo esempio, segui le istruzioni di configurazione di PHP nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery PHP.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Python
Imposta la proprietà
QueryJobConfig.dry_run
su True.
Client.query()
restituisce sempre un
QueryJob
completato quando viene fornita una configurazione di query di prova.
Prima di provare questo esempio, segui le istruzioni di configurazione di Python nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Python.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Passaggi successivi
- Scopri come gestire i job di query.
- Scopri come visualizzare la cronologia delle query.
- Scopri come salvare e condividere le query.
- Scopri di più sulle code di query.
- Scopri come scrivere i risultati delle query.