Execute uma consulta
Este documento mostra como executar uma consulta no BigQuery e compreender a quantidade de dados que a consulta vai processar antes da execução através de uma execução de teste.
Tipos de consultas
Pode consultar dados do BigQuery usando um dos seguintes tipos de tarefas de consulta:
Tarefas de consulta interativas. Por predefinição, o BigQuery executa consultas como tarefas de consulta interativas, que se destinam a começar a ser executadas o mais rapidamente possível.
Tarefas de consulta em lote. As consultas em lote têm uma prioridade inferior à das consultas interativas. Quando um projeto ou uma reserva usa todos os recursos de computação disponíveis, é mais provável que as consultas em lote sejam colocadas em fila e permaneçam na fila. Depois de uma consulta em lote começar a ser executada, esta é executada da mesma forma que uma consulta interativa. Para mais informações, consulte filas de consultas.
Tarefas de consulta contínuas. Com estes trabalhos, a consulta é executada continuamente, o que lhe permite analisar os dados recebidos no BigQuery em tempo real e, em seguida, escrever os resultados numa tabela do BigQuery ou exportá-los para o Bigtable ou o Pub/Sub. Pode usar esta capacidade para realizar tarefas sensíveis ao tempo, como criar e agir imediatamente com base em estatísticas, aplicar inferência de aprendizagem automática (AA) em tempo real e criar pipelines de dados orientados por eventos.
Pode executar tarefas de consulta através dos seguintes métodos:
- Componha e execute uma consulta na Google Cloud consola.
- Execute o comando
bq queryna ferramenta de linhas de comando bq. - Chame programaticamente o método
jobs.queryoujobs.insertna API REST do BigQuery. - Use as bibliotecas cliente do BigQuery.
O BigQuery guarda os resultados da consulta numa tabela temporária (predefinição) ou numa tabela permanente. Quando especifica uma tabela permanente como a tabela de destino dos resultados, pode escolher se quer acrescentar ou substituir uma tabela existente, ou criar uma nova tabela com um nome único.
Funções necessárias
Para receber as autorizações de que precisa para executar uma tarefa de consulta, peça ao seu administrador que lhe conceda as seguintes funções do IAM:
-
Utilizador de tarefas do BigQuery (
roles/bigquery.jobUser) no projeto. -
Visualizador de dados do BigQuery (
roles/bigquery.dataViewer) em todas as tabelas e vistas a que a sua consulta faz referência. Para consultar visualizações, também precisa desta função em todas as tabelas e visualizações subjacentes. Se estiver a usar vistas autorizadas ou conjuntos de dados autorizados, não precisa de acesso aos dados de origem subjacentes.
Para mais informações sobre a atribuição de funções, consulte o artigo Faça a gestão do acesso a projetos, pastas e organizações.
Estas funções predefinidas contêm as autorizações necessárias para executar uma tarefa de consulta. Para ver as autorizações exatas que são necessárias, expanda a secção Autorizações necessárias:
Autorizações necessárias
São necessárias as seguintes autorizações para executar uma tarefa de consulta:
-
bigquery.jobs.createno projeto a partir do qual a consulta está a ser executada, independentemente de onde os dados estão armazenados. -
bigquery.tables.getDataem todas as tabelas e vistas a que a sua consulta faz referência. Para consultar visualizações, também precisa desta autorização em todas as tabelas e visualizações subjacentes. Se estiver a usar vistas autorizadas ou conjuntos de dados autorizados, não precisa de acesso aos dados de origem subjacentes.
Também pode conseguir estas autorizações com funções personalizadas ou outras funções predefinidas.
Resolução de problemas
Access Denied: Project [project_id]: User does not have bigquery.jobs.create
permission in project [project_id].
Este erro ocorre quando um principal não tem autorização para criar tarefas de consulta no projeto.
Resolução: um administrador tem de lhe conceder a autorização bigquery.jobs.create no projeto que está a consultar. Esta autorização é necessária
além de qualquer autorização necessária para aceder aos dados consultados.
Para mais informações sobre as autorizações do BigQuery, consulte o artigo Controlo de acesso com a IAM.
Execute uma consulta interativa
Para executar uma consulta interativa, selecione uma das seguintes opções:
Consola
Aceda à página do BigQuery.
Clique em Consulta SQL.
No editor de consultas, introduza uma consulta GoogleSQL válida.
Por exemplo, consulte o conjunto de dados públicos do BigQuery
usa_namespara determinar os nomes mais comuns nos Estados Unidos entre os anos de 1910 e 2013:SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;Em alternativa, pode usar o painel de referência para criar novas consultas.
Opcional: para apresentar automaticamente sugestões de código quando escreve uma consulta, clique em Mais e, de seguida, selecione Preenchimento automático de SQL. Se não precisar de sugestões de preenchimento automático, desmarque a opção Preenchimento automático de SQL. Esta ação também desativa as sugestões de preenchimento automático do nome do projeto.
Opcional: para selecionar definições de consulta adicionais, clique em Mais e, de seguida, clique em Definições de consulta.
Clique em Executar.
Se não especificar uma tabela de destino, a tarefa de consulta escreve o resultado numa tabela temporária (cache).
Agora, pode explorar os resultados da consulta no separador Resultados do painel Resultados da consulta.
Opcional: para ordenar os resultados da consulta por coluna, clique em Abrir menu de ordenação junto ao nome da coluna e selecione uma ordem de ordenação. Se os bytes estimados processados para a ordenação forem superiores a zero, o número de bytes é apresentado na parte superior do menu.
Opcional: para ver a visualização dos resultados da consulta, aceda ao separador Visualização. Pode aumentar ou diminuir o zoom do gráfico, transferir o gráfico como um ficheiro PNG ou ativar/desativar a visibilidade da legenda.
No painel Configuração da visualização, pode alterar o tipo de visualização e configurar as métricas e as dimensões da visualização. Os campos neste painel são pré-preenchidos com a configuração inicial inferida do esquema da tabela de destino da consulta. A configuração é preservada entre as execuções de consultas seguintes no mesmo editor de consultas.
Para visualizações de linhas, barras ou dispersão, os tipos de dados de dimensões suportados são
INT64,FLOAT64,NUMERIC,BIGNUMERIC,TIMESTAMP,DATE,DATETIME,TIMEeSTRING, enquanto os tipos de dados de medidas suportados sãoINT64,FLOAT64,NUMERICeBIGNUMERIC.Se os resultados da sua consulta incluírem o tipo
GEOGRAPHY, o Mapa é o tipo de visualização predefinido, que lhe permite visualizar os resultados num mapa interativo.Opcional: no separador JSON, pode explorar os resultados da consulta no formato JSON, em que a chave é o nome da coluna e o valor é o resultado dessa coluna.
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Use o comando
bq query. No exemplo seguinte, a flag--use_legacy_sql=falsepermite-lhe usar a sintaxe do GoogleSQL.bq query \ --use_legacy_sql=false \ 'QUERY'
Substitua QUERY por uma consulta GoogleSQL válida. Por exemplo, consulte o conjunto de dados público do BigQuery
usa_namespara determinar os nomes mais comuns nos Estados Unidos entre 1910 e 2013:bq query \ --use_legacy_sql=false \ 'SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;'A tarefa de consulta escreve o resultado numa tabela temporária (cache).
Opcionalmente, pode especificar a tabela de destino e a localização para os resultados da consulta. Para escrever os resultados numa tabela existente, inclua a flag adequada para anexar (
--append_table=true) ou substituir (--replace=true) a tabela.bq query \ --location=LOCATION \ --destination_table=TABLE \ --use_legacy_sql=false \ 'QUERY'
Substitua o seguinte:
LOCATION: a região ou a multirregião da tabela de destino, por exemplo,
USNeste exemplo, o conjunto de dados
usa_namesé armazenado na localização multirregional dos EUA. Se especificar uma tabela de destino para esta consulta, o conjunto de dados que contém a tabela de destino também tem de estar na multirregião dos EUA. Não pode consultar um conjunto de dados numa localização e escrever os resultados numa tabela noutra localização.Pode definir um valor predefinido para a localização através do ficheiro.bigqueryrc.
TABLE: um nome para a tabela de destino, por exemplo,
myDataset.myTableSe a tabela de destino for uma tabela nova, o BigQuery cria a tabela quando executa a consulta. No entanto, tem de especificar um conjunto de dados existente.
Se a tabela não estiver no seu projeto atual, adicione o Google Cloud ID do projeto usando o formato
PROJECT_ID:DATASET.TABLE, por exemplo,myProject:myDataset.myTable. Se--destination_tablenão for especificado, é gerada uma tarefa de consulta que escreve o resultado numa tabela temporária.
API
Para executar uma consulta através da API, insira uma nova tarefa
e preencha a propriedade de configuração da tarefa query. Opcionalmente, especifique a sua localização na propriedade location na secção jobReference do recurso de tarefa .
Sonde os resultados chamando
getQueryResults.
A sondagem até jobComplete é igual a true. Verifique se existem erros e avisos na lista errors.
C#
Antes de experimentar este exemplo, siga as C#instruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API C# BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Go
Antes de experimentar este exemplo, siga as Goinstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Go BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Java
Antes de experimentar este exemplo, siga as Javainstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Java BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Para executar uma consulta com um proxy, consulte o artigo Configurar um proxy.
Node.js
Antes de experimentar este exemplo, siga as Node.jsinstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Node.js BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
PHP
Antes de experimentar este exemplo, siga as PHPinstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API PHP BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Python
Antes de experimentar este exemplo, siga as Pythoninstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Python BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Ruby
Antes de experimentar este exemplo, siga as Rubyinstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Ruby BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Execute uma consulta em lote
Para executar uma consulta em lote, selecione uma das seguintes opções:
Consola
Aceda à página do BigQuery.
Clique em Consulta SQL.
No editor de consultas, introduza uma consulta GoogleSQL válida.
Por exemplo, consulte o conjunto de dados públicos do BigQuery
usa_namespara determinar os nomes mais comuns nos Estados Unidos entre os anos de 1910 e 2013:SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;Clique em Mais e, de seguida, clique em Definições de consulta.
Na secção Gestão de recursos, selecione Lote.
Opcional: ajuste as definições de consulta.
Clique em Guardar.
Clique em Executar.
Se não especificar uma tabela de destino, a tarefa de consulta escreve o resultado numa tabela temporária (cache).
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Use o
bq querycomando e especifique a flag--batch. No exemplo seguinte, a flag--use_legacy_sql=falsepermite-lhe usar a sintaxe do GoogleSQL.bq query \ --batch \ --use_legacy_sql=false \ 'QUERY'
Substitua QUERY por uma consulta GoogleSQL válida. Por exemplo, consulte o conjunto de dados público do BigQuery
usa_namespara determinar os nomes mais comuns nos Estados Unidos entre 1910 e 2013:bq query \ --batch \ --use_legacy_sql=false \ 'SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;'A tarefa de consulta escreve o resultado numa tabela temporária (cache).
Opcionalmente, pode especificar a tabela de destino e a localização para os resultados da consulta. Para escrever os resultados numa tabela existente, inclua a flag adequada para anexar (
--append_table=true) ou substituir (--replace=true) a tabela.bq query \ --batch \ --location=LOCATION \ --destination_table=TABLE \ --use_legacy_sql=false \ 'QUERY'
Substitua o seguinte:
LOCATION: a região ou a multirregião da tabela de destino, por exemplo,
USNeste exemplo, o conjunto de dados
usa_namesé armazenado na localização multirregional dos EUA. Se especificar uma tabela de destino para esta consulta, o conjunto de dados que contém a tabela de destino também tem de estar na multirregião dos EUA. Não pode consultar um conjunto de dados numa localização e escrever os resultados numa tabela noutra localização.Pode definir um valor predefinido para a localização através do ficheiro.bigqueryrc.
TABLE: um nome para a tabela de destino, por exemplo,
myDataset.myTableSe a tabela de destino for uma tabela nova, o BigQuery cria a tabela quando executa a consulta. No entanto, tem de especificar um conjunto de dados existente.
Se a tabela não estiver no seu projeto atual, adicione o Google Cloud ID do projeto usando o formato
PROJECT_ID:DATASET.TABLE, por exemplo,myProject:myDataset.myTable. Se--destination_tablenão for especificado, é gerada uma tarefa de consulta que escreve o resultado numa tabela temporária.
API
Para executar uma consulta através da API, insira uma nova tarefa
e preencha a propriedade de configuração da tarefa query. Opcionalmente, especifique a sua localização na propriedade location na secção jobReference do recurso de tarefa .
Quando preencher as propriedades da tarefa de consulta, inclua a propriedade
configuration.query.priority e defina o valor como BATCH.
Sonde os resultados chamando
getQueryResults.
A sondagem até jobComplete é igual a true. Verifique se existem erros e avisos na lista errors.
Go
Antes de experimentar este exemplo, siga as Goinstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Go BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Java
Para executar uma consulta em lote, defina a prioridade da consulta como QueryJobConfiguration.Priority.BATCH quando criar uma QueryJobConfiguration.
Antes de experimentar este exemplo, siga as Javainstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Java BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Node.js
Antes de experimentar este exemplo, siga as Node.jsinstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Node.js BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Python
Antes de experimentar este exemplo, siga as Pythoninstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Python BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Execute uma consulta contínua
A execução de uma tarefa de consulta contínua requer uma configuração adicional. Para mais informações, consulte Crie consultas contínuas.
Use o painel Referência
No editor de consultas, o painel Referência apresenta dinamicamente informações sensíveis ao contexto sobre tabelas, instantâneos, vistas e vistas materializadas. O painel permite-lhe pré-visualizar os detalhes do esquema destes recursos ou abri-los num novo separador. Também pode usar o painel Referência para criar novas consultas ou editar consultas existentes inserindo fragmentos de consultas ou nomes de campos.
Para criar uma nova consulta através do painel Referência, siga estes passos:
Na Google Cloud consola, aceda à página BigQuery.
Clique em Consulta SQL.
Clique em quick_reference_all Referência.
Clique numa tabela ou vista recente ou marcada com estrela. Também pode usar a barra de pesquisa para encontrar tabelas e vistas.
Clique em Ver ações e, de seguida, clique em Inserir fragmento de consulta.
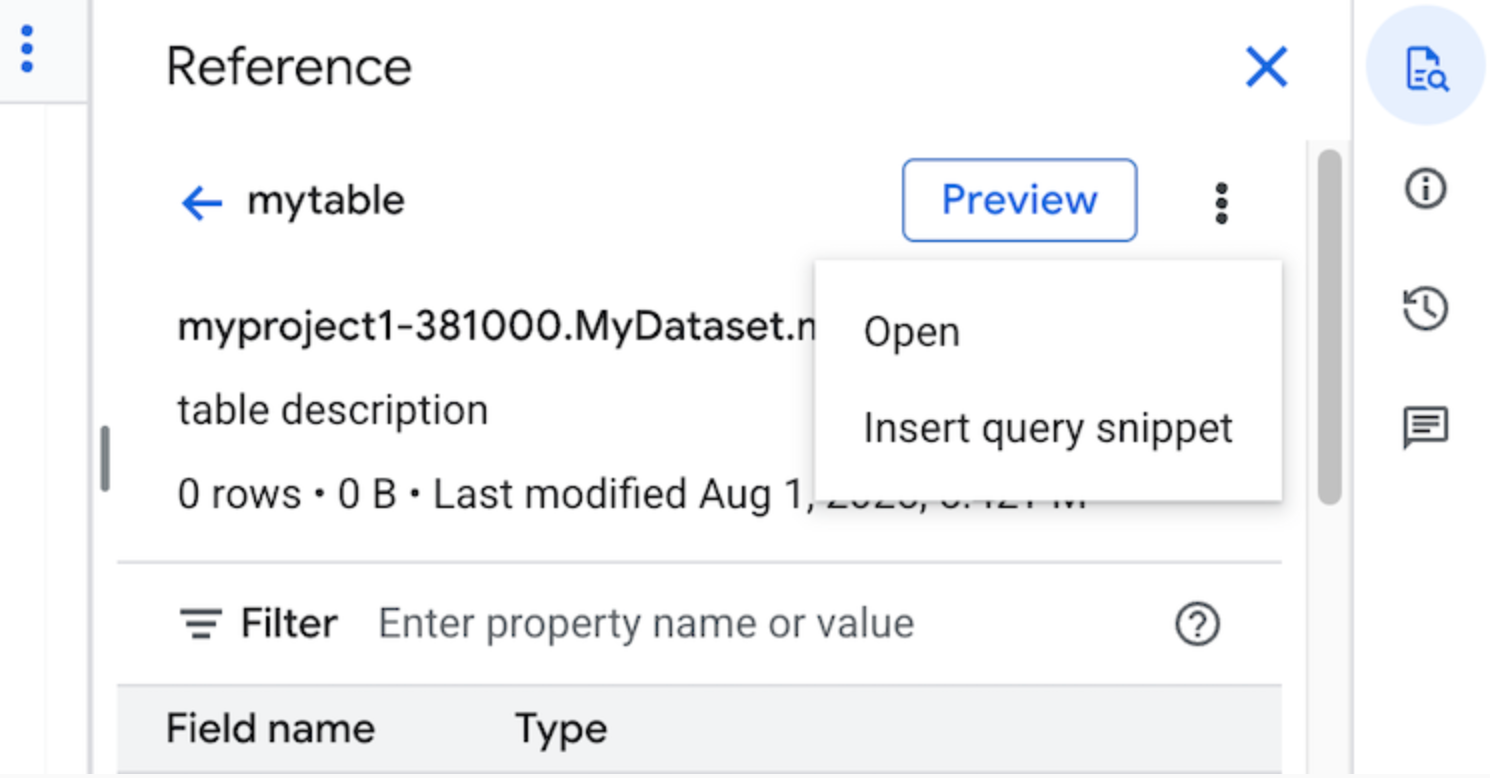
Opcional: pode pré-visualizar os detalhes do esquema da tabela ou da vista, ou abri-los num novo separador.
Agora, pode editar a consulta manualmente ou inserir nomes de campos diretamente na consulta. Para inserir um nome de campo, aponte e clique num local no editor de consultas onde quer inserir o nome de campo e, de seguida, clique no nome de campo no painel Referência.
Definições da consulta
Quando executa uma consulta, pode especificar as seguintes definições:
Uma tabela de destino para os resultados da consulta.
A prioridade da tarefa.
Se deve usar resultados de consultas em cache.
O limite de tempo da tarefa em milissegundos.
Se deve usar o modo de sessão.
O tipo de encriptação a usar.
O número máximo de bytes faturados para a consulta.
O dialeto de SQL a usar.
A localização na qual executar a consulta. A consulta tem de ser executada na mesma localização que as tabelas referenciadas na consulta.
A reserva para executar a consulta em (pré-visualização).
Modo de criação de tarefas opcional
O modo de criação de tarefas opcional pode melhorar a latência geral das consultas executadas durante um curto período, como as provenientes de painéis de controlo ou cargas de trabalho de exploração de dados. Este modo executa a consulta e devolve os resultados inline para declarações SELECT sem exigir a utilização de jobs.getQueryResults para obter os resultados. As consultas que usam o modo de criação de tarefas opcional não criam uma tarefa quando são executadas, a menos que o BigQuery determine que é necessária uma criação de tarefas para concluir a consulta.
Para ativar o modo de criação de tarefas opcional, defina o campo jobCreationMode da instância QueryRequest como JOB_CREATION_OPTIONAL no corpo do pedido jobs.query.
Quando o valor deste campo está definido como JOB_CREATION_OPTIONAL, o BigQuery determina se a consulta pode usar o modo de criação de tarefas opcional. Se for o caso, o BigQuery executa a consulta e devolve todos os resultados no campo rows da resposta. Uma vez que não é criada uma tarefa para esta consulta, o BigQuery não devolve um jobReference no corpo da resposta. Em alternativa, devolve um campo queryId, que pode usar para obter
estatísticas sobre a consulta através da INFORMATION_SCHEMA.JOBS
vista. Uma vez que não é criado nenhum trabalho, não existe nenhum jobReference que possa ser transmitido às APIs jobs.get e jobs.getQueryResults para procurar estas consultas.
Se o BigQuery determinar que é necessária uma tarefa para concluir a consulta, é devolvido um jobReference. Pode inspecionar o campo job_creation_reason
na INFORMATION_SCHEMA.JOBS
vista para determinar o motivo pelo qual foi criado um trabalho para a consulta. Neste caso, deve usar
jobs.getQueryResults
para obter os resultados quando a consulta estiver concluída.
Quando usa o valor JOB_CREATION_OPTIONAL, o campo jobReference pode não estar presente na resposta. Verifique se o campo existe antes de aceder ao mesmo.
Quando JOB_CREATION_OPTIONAL é especificado para consultas com várias declarações (scripts),
o BigQuery pode otimizar o processo de execução. Como parte desta otimização, o BigQuery pode determinar que consegue concluir o script criando menos recursos de tarefas do que o número de declarações individuais, podendo até executar todo o script sem criar nenhuma tarefa.
Esta otimização depende da avaliação do script por parte do BigQuery e a otimização pode não ser aplicada em todos os casos. A otimização é totalmente
automatizada pelo sistema. Não são necessários controlos nem ações do utilizador.
Para executar uma consulta usando o modo de criação de tarefas opcional, selecione uma das seguintes opções:
Consola
Aceda à página do BigQuery.
Clique em Consulta SQL.
No editor de consultas, introduza uma consulta GoogleSQL válida.
Por exemplo, consulte o conjunto de dados públicos do BigQuery
usa_namespara determinar os nomes mais comuns nos Estados Unidos entre os anos de 1910 e 2013:SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;Clique em Mais e, de seguida, escolha o modo de consulta Criação de tarefas opcional. Para confirmar esta escolha, clique em Confirmar.
Clique em Executar.
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Use o
bq querycomando e especifique a flag--job_creation_mode=JOB_CREATION_OPTIONAL. No exemplo seguinte, a flag--use_legacy_sql=falsepermite-lhe usar a sintaxe do GoogleSQL.bq query \ --rpc=true \ --use_legacy_sql=false \ --job_creation_mode=JOB_CREATION_OPTIONAL \ --location=LOCATION \ 'QUERY'
Substitua QUERY por uma consulta GoogleSQL válida e substitua LOCATION por uma região válida onde o conjunto de dados está localizado. Por exemplo, consulte o conjunto de dados público do BigQuery
usa_namespara determinar os nomes mais comuns nos Estados Unidos entre 1910 e 2013:bq query \ --rpc=true \ --use_legacy_sql=false \ --job_creation_mode=JOB_CREATION_OPTIONAL \ --location=us \ 'SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;'A tarefa de consulta devolve o resultado inline na resposta.
API
Para executar uma consulta no modo de criação de tarefas opcional através da API, execute uma consulta de forma síncrona
e preencha a propriedade QueryRequest. Inclua a propriedade jobCreationMode e defina o respetivo valor como JOB_CREATION_OPTIONAL.
Verifique a resposta. Se jobComplete for igual a true e jobReference estiver vazio, leia os resultados do campo rows. Também pode obter o queryId a partir da resposta.
Se jobReference estiver presente, pode verificar jobCreationReason para saber por que motivo o BigQuery criou uma tarefa. Sonde os resultados chamando
getQueryResults.
A sondagem até jobComplete é igual a true. Verifique se existem erros e avisos na lista errors.
Java
Versão disponível: 2.51.0 e superior
Antes de experimentar este exemplo, siga as Javainstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Java BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Para executar uma consulta com um proxy, consulte o artigo Configurar um proxy.
Python
Versão disponível: 3.34.0 e superior
Antes de experimentar este exemplo, siga as Pythoninstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Python BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Nó
Versão disponível: 8.1.0 e superior
Antes de experimentar este exemplo, siga as Node.jsinstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Node.js BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Go
Versão disponível: 1.69.0 e superior
Antes de experimentar este exemplo, siga as Goinstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Go BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Controlador JDBC
Versão disponível: JDBC v1.6.1 e superior
Requer a definição de JobCreationMode=2 na string de ligação.
jdbc:bigquery://https://www.googleapis.com/bigquery/v2:443;JobCreationMode=2;Location=US;
Controlador ODBC
Versão disponível: ODBC v3.0.7.1016 e superior
Requer a definição de JobCreationMode=2 no ficheiro .ini.
[ODBC Data Sources] Sample DSN=Simba Google BigQuery ODBC Connector 64-bit [Sample DSN] JobCreationMode=2
Quotas
Para informações sobre quotas relativas a consultas interativas e em lote, consulte o artigo Tarefas de consulta.
Monitorize consultas
Pode obter informações sobre as consultas à medida que são executadas através do
explorador de tarefas ou consultando a
vista INFORMATION_SCHEMA.JOBS_BY_PROJECT.
Execução de ensaio
Uma execução de teste no BigQuery fornece as seguintes informações:
- estimativa de encargos no modo a pedido
- validação da sua consulta
- bytes aproximados processados pela sua consulta no modo de capacidade
Os ensaios não usam espaços de consultas e não lhe é cobrado nenhum valor pela execução de um ensaio. Pode usar a estimativa devolvida por um teste de execução para calcular os custos das consultas na calculadora de preços.
Faça uma execução de ensaio
Para fazer um teste de execução, faça o seguinte:
Consola
Aceda à página do BigQuery.
Introduza a consulta no editor de consultas.
Se a consulta for válida, é apresentado automaticamente uma marca de verificação juntamente com a quantidade de dados que a consulta vai processar. Se a consulta for inválida, é apresentado um ponto de exclamação juntamente com uma mensagem de erro.
bq
Introduza uma consulta como a seguinte usando a flag --dry_run.
bq query \ --use_legacy_sql=false \ --dry_run \ 'SELECT COUNTRY, AIRPORT, IATA FROM `project_id`.dataset.airports LIMIT 1000'
Para uma consulta válida, o comando produz a seguinte resposta:
Query successfully validated. Assuming the tables are not modified, running this query will process 10918 bytes of data.
API
Para executar um teste simulado através da API, envie uma tarefa de consulta com o valor dryRun definido como true no tipo JobConfiguration.
Go
Antes de experimentar este exemplo, siga as Goinstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Go BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Java
Antes de experimentar este exemplo, siga as Javainstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Java BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Node.js
Antes de experimentar este exemplo, siga as Node.jsinstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Node.js BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
PHP
Antes de experimentar este exemplo, siga as PHPinstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API PHP BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Python
Defina a propriedade
QueryJobConfig.dry_run
como True.
Client.query()
devolve sempre um QueryJob concluído
quando é fornecida uma configuração de consulta de teste.
Antes de experimentar este exemplo, siga as Pythoninstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Python BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
O que se segue?
- Saiba como gerir tarefas de consulta.
- Saiba como ver o histórico de consultas.
- Saiba como guardar e partilhar consultas.
- Saiba mais acerca das filas de consultas.
- Saiba como escrever resultados de consultas.