이 튜토리얼에서는 다음 BigQuery 공개 데이터 세트를 사용합니다.
이러한 공개 데이터 세트에 액세스하는 방법에 대한 자세한 내용은 Google Cloud 콘솔에서 공개 데이터 세트에 액세스를 참고하세요.
공개 데이터 세트를 사용하여 다음 시각화를 만듭니다.
- Ford GoBike Share 데이터 세트의 모든 자전거 공유 스테이션의 분산형 차트
- 샌프란시스코 지역 데이터 세트의 다각형
- 동네별 자전거 공유 스테이션 수를 나타내는 등치 지역도
- 샌프란시스코 경찰서 신고 데이터 세트의 사고 히트맵
목표
- Google Cloud 로, 그리고 선택적으로 Google 지도로 인증을 설정합니다.
- BigQuery에서 데이터를 쿼리하고 결과를 Colab에 다운로드합니다.
- Python 데이터 과학 도구를 사용하여 변환 및 분석을 실행합니다.
- 분산형 차트, 다각형, 등치 지역도, 히트맵 등 시각화 자료를 만듭니다.
비용
이 문서에서는 비용이 청구될 수 있는 Google Cloud구성요소( )를 사용합니다.
프로젝트 사용량을 기준으로 예상 비용을 산출하려면 가격 계산기를 사용합니다.
이 문서에 설명된 태스크를 완료했으면 만든 리소스를 삭제하여 청구가 계속되는 것을 방지할 수 있습니다. 자세한 내용은 삭제를 참조하세요.
시작하기 전에
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery and Google Maps JavaScript APIs.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery and Google Maps JavaScript APIs.
- 이 문서의 태스크를 수행하는 데 필요한 권한이 있는지 확인합니다.
- BigQuery User (
roles/bigquery.user) -
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
-
In the Principal column, find all rows that identify you or a group that you're included in. To learn which groups you're included in, contact your administrator.
- For all rows that specify or include you, check the Role column to see whether the list of roles includes the required roles.
-
In the Google Cloud console, go to the IAM page.
IAM으로 이동 - 프로젝트를 선택합니다.
- 액세스 권한 부여를 클릭합니다.
-
새 주 구성원 필드에 사용자 식별자를 입력합니다. 일반적으로 Google 계정의 이메일 주소입니다.
- 역할 선택 목록에서 역할을 선택합니다.
- 역할을 추가로 부여하려면 다른 역할 추가를 클릭하고 각 역할을 추가합니다.
- 저장을 클릭합니다.
Colab 열기
노트북 열기 대화상자에서 새 노트북을 클릭합니다.
Untitled0.ipynb를 클릭하고 노트북 이름을bigquery-geo.ipynb로 변경합니다.파일 > 저장을 선택합니다.
코드 셀을 삽입하려면 코드를 클릭합니다.
프로젝트로 인증하려면 다음 코드를 입력합니다.
# REQUIRED: Authenticate with your project. GCP_PROJECT_ID = "PROJECT_ID" #@param {type:"string"} from google.colab import auth from google.colab import userdata auth.authenticate_user(project_id=GCP_PROJECT_ID) # Set GMP_API_KEY to none GMP_API_KEY = None
PROJECT_ID를 프로젝트 ID로 바꿉니다.
셀 실행을 클릭합니다.
메시지가 표시되면 동의하는 경우 허용을 클릭하여 Colab에 사용자 인증 정보에 대한 액세스 권한을 부여합니다.
Google 계정으로 로그인 페이지에서 계정을 선택합니다.
서드 파티에서 작성한 노트북 코드에 로그인 페이지에서 계속을 클릭합니다.
서드 파티에서 작성한 노트북 코드에 액세스할 수 있는 항목 선택에서 모두 선택을 클릭한 다음 계속을 클릭합니다.
승인 흐름을 완료한 후에는 Colab 노트북에 출력이 생성되지 않습니다. 셀 옆의 체크표시는 코드가 성공적으로 실행되었음을 나타냅니다.
Google 지도 문서의 API 키 사용 페이지에 나온 안내에 따라 Google 지도 API 키를 가져옵니다.
Colab 노트북으로 전환한 다음 보안 비밀을 클릭합니다.
새 보안 비밀 추가를 클릭합니다.
이름에
GMP_API_KEY를 입력합니다.값에 이전에 생성한 Maps API 키 값을 입력합니다.
보안 비밀 패널을 닫습니다.
코드 셀을 삽입하려면 코드를 클릭합니다.
지도 API로 인증하려면 다음 코드를 입력합니다.
# Authenticate with the Google Maps JavaScript API. GMP_API_SECRET_KEY_NAME = "GMP_API_KEY" #@param {type:"string"} if GMP_API_SECRET_KEY_NAME: GMP_API_KEY = userdata.get(GMP_API_SECRET_KEY_NAME) if GMP_API_SECRET_KEY_NAME else None else: GMP_API_KEY = None
메시지가 표시되면 동의하는 경우 액세스 권한 부여를 클릭하여 노트북에 키에 대한 액세스 권한을 부여합니다.
셀 실행을 클릭합니다.
승인 흐름을 완료한 후에는 Colab 노트북에 출력이 생성되지 않습니다. 셀 옆의 체크표시는 코드가 성공적으로 실행되었음을 나타냅니다.
geopandas를 사용하여pandas에서 사용하는 데이터 유형을 확장하여 기하학적 유형에 대한 공간 작업을 허용합니다.shapely를 사용하여 개별 평면 기하학 객체를 조작하고 분석합니다.branca를 사용하여 HTML 및 JavaScript 컬러맵을 생성합니다.pydeck및earthengine-api을 통해geemap.deck을 사용해 시각화합니다.코드 셀을 삽입하려면 코드를 클릭합니다.
pydeck및h3패키지를 설치하려면 다음 코드를 입력합니다.# Install pydeck and h3. !pip install pydeck>=0.9 h3>=4.2
셀 실행을 클릭합니다.
설치를 완료한 후에는 Colab 노트북에 출력이 생성되지 않습니다. 셀 옆의 체크표시는 코드가 성공적으로 실행되었음을 나타냅니다.
코드 셀을 삽입하려면 코드를 클릭합니다.
Python 라이브러리를 가져오려면 다음 코드를 입력합니다.
# Import data science libraries. import branca import geemap.deck as gmdk import h3 import pydeck as pdk import geopandas as gpd import shapely
셀 실행을 클릭합니다.
코드를 실행해도 Colab 노트북에 출력이 생성되지 않습니다. 셀 옆의 체크표시는 코드가 성공적으로 실행되었음을 나타냅니다.
코드 셀을 삽입하려면 코드를 클릭합니다.
pandasDataFrame을 사용 설정하려면 다음 코드를 입력합니다.# Enable displaying pandas data frames as interactive tables by default. from google.colab import data_table data_table.enable_dataframe_formatter()
셀 실행을 클릭합니다.
코드를 실행해도 Colab 노트북에 출력이 생성되지 않습니다. 셀 옆의 체크표시는 코드가 성공적으로 실행되었음을 나타냅니다.
코드 셀을 삽입하려면 코드를 클릭합니다.
지도에 레이어를 렌더링하는 공유 루틴을 만들려면 다음 코드를 입력합니다.
# Set Google Maps as the base map provider. MAP_PROVIDER_GOOGLE = pdk.bindings.base_map_provider.BaseMapProvider.GOOGLE_MAPS.value # Shared routine for rendering layers on a map using geemap.deck. def display_pydeck_map(layers, view_state, **kwargs): deck_kwargs = kwargs.copy() # Use Google Maps as the base map only if the API key is provided. if GMP_API_KEY: deck_kwargs.update({ "map_provider": MAP_PROVIDER_GOOGLE, "map_style": pdk.bindings.map_styles.GOOGLE_ROAD, "api_keys": {MAP_PROVIDER_GOOGLE: GMP_API_KEY}, }) m = gmdk.Map(initial_view_state=view_state, ee_initialize=False, **deck_kwargs) for layer in layers: m.add_layer(layer) return m
셀 실행을 클릭합니다.
코드를 실행해도 Colab 노트북에 출력이 생성되지 않습니다. 셀 옆의 체크표시는 코드가 성공적으로 실행되었음을 나타냅니다.
코드 셀을 삽입하려면 코드를 클릭합니다.
샌프란시스코 Ford GoBike Share 공개 데이터 세트를 쿼리하려면 다음 코드를 입력합니다. 이 코드에서는
%%bigquery매직 함수를 사용하여 쿼리를 실행하고 결과를 DataFrame으로 반환합니다.# Query the station ID, station name, station short name, and station # geometry from the bike share dataset. # NOTE: In this tutorial, the denormalized 'lat' and 'lon' columns are # ignored. They are decomposed components of the geometry. %%bigquery gdf_sf_bikestations --project {GCP_PROJECT_ID} --use_geodataframe station_geom SELECT station_id, name, short_name, station_geom FROM `bigquery-public-data.san_francisco_bikeshare.bikeshare_station_info`
셀 실행을 클릭합니다.
출력은 다음과 비슷합니다.
Job ID 12345-1234-5678-1234-123456789 successfully executed: 100%코드 셀을 삽입하려면 코드를 클릭합니다.
열과 데이터 유형을 비롯한 DataFrame의 요약을 확인하려면 다음 코드를 입력합니다.
# Get a summary of the DataFrame gdf_sf_bikestations.info()
셀 실행을 클릭합니다.
다음과 유사하게 출력됩니다.
<class 'geopandas.geodataframe.GeoDataFrame'> RangeIndex: 472 entries, 0 to 471 Data columns (total 4 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 station_id 472 non-null object 1 name 472 non-null object 2 short_name 472 non-null object 3 station_geom 472 non-null geometry dtypes: geometry(1), object(3) memory usage: 14.9+ KB코드 셀을 삽입하려면 코드를 클릭합니다.
DataFrame의 처음 5개 행을 미리 보려면 다음 코드를 입력합니다.
# Preview the first five rows gdf_sf_bikestations.head()
셀 실행을 클릭합니다.
출력은 다음과 비슷합니다.

코드 셀을 삽입하려면 코드를 클릭합니다.
station_geom열에서 경도 및 위도 값을 추출하려면 다음 코드를 입력합니다.# Extract the longitude (x) and latitude (y) from station_geom. gdf_sf_bikestations["longitude"] = gdf_sf_bikestations["station_geom"].x gdf_sf_bikestations["latitude"] = gdf_sf_bikestations["station_geom"].y
셀 실행을 클릭합니다.
코드를 실행해도 Colab 노트북에 출력이 생성되지 않습니다. 셀 옆의 체크표시는 코드가 성공적으로 실행되었음을 나타냅니다.
코드 셀을 삽입하려면 코드를 클릭합니다.
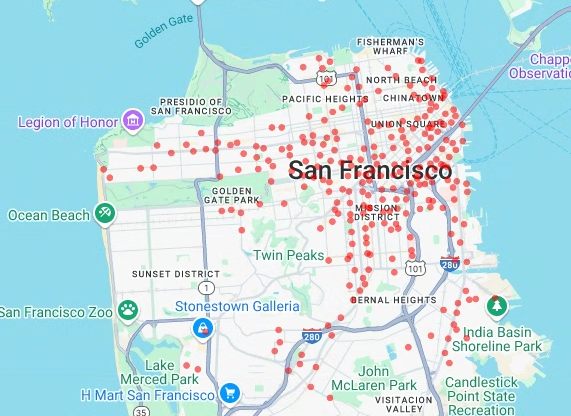
이전에 추출한 경도 및 위도 값을 기반으로 자전거 공유 정거장의 분산형 차트를 렌더링하려면 다음 코드를 입력합니다.
# Render a scatter plot using pydeck with the extracted longitude and # latitude columns in the gdf_sf_bikestations geopandas.GeoDataFrame. scatterplot_layer = pdk.Layer( "ScatterplotLayer", id="bike_stations_scatterplot", data=gdf_sf_bikestations, get_position=['longitude', 'latitude'], get_radius=100, get_fill_color=[255, 0, 0, 140], # Adjust color as desired pickable=True, ) view_state = pdk.ViewState(latitude=37.77613, longitude=-122.42284, zoom=12) display_pydeck_map([scatterplot_layer], view_state)
셀 실행을 클릭합니다.
출력은 다음과 비슷합니다.
- 포인트
- 선
- 다각형
- 여러 다각형
코드 셀을 삽입하려면 코드를 클릭합니다.
San Francisco Neighborhoods 데이터 세트의
bigquery-public-data.san_francisco_neighborhoods.boundaries테이블에서 지리 데이터를 쿼리하려면 다음 코드를 입력합니다. 이 코드에서는%%bigquery매직 함수를 사용하여 쿼리를 실행하고 결과를 DataFrame으로 반환합니다.# Query the neighborhood name and geometry from the San Francisco # neighborhoods dataset. %%bigquery gdf_sanfrancisco_neighborhoods --project {GCP_PROJECT_ID} --use_geodataframe geometry SELECT neighborhood, neighborhood_geom AS geometry FROM `bigquery-public-data.san_francisco_neighborhoods.boundaries`
셀 실행을 클릭합니다.
출력은 다음과 비슷합니다.
Job ID 12345-1234-5678-1234-123456789 successfully executed: 100%코드 셀을 삽입하려면 코드를 클릭합니다.
DataFrame의 요약을 가져오려면 다음 코드를 입력합니다.
# Get a summary of the DataFrame gdf_sanfrancisco_neighborhoods.info()
셀 실행을 클릭합니다.
다음과 같은 결과가 표시됩니다.
<class 'geopandas.geodataframe.GeoDataFrame'> RangeIndex: 117 entries, 0 to 116 Data columns (total 2 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 neighborhood 117 non-null object 1 geometry 117 non-null geometry dtypes: geometry(1), object(1) memory usage: 2.0+ KBDataFrame의 첫 번째 행을 미리 보려면 다음 코드를 입력합니다.
# Preview the first row gdf_sanfrancisco_neighborhoods.head(1)
셀 실행을 클릭합니다.
출력은 다음과 비슷합니다.

결과에서 데이터가 다각형임을 확인합니다.
코드 셀을 삽입하려면 코드를 클릭합니다.
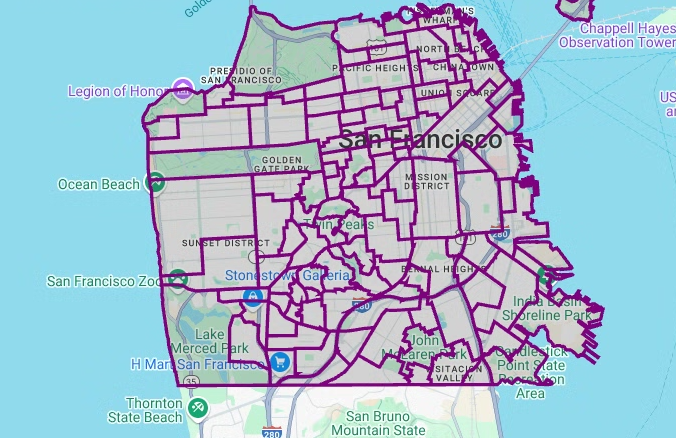
다각형을 시각화하려면 다음 코드를 입력합니다.
pydeck은 geometry 열의 각shapely객체 인스턴스를GeoJSON형식으로 변환하는 데 사용됩니다.# Visualize the polygons. geojson_layer = pdk.Layer( 'GeoJsonLayer', id="sf_neighborhoods", data=gdf_sanfrancisco_neighborhoods, get_line_color=[127, 0, 127, 255], get_fill_color=[60, 60, 60, 50], get_line_width=100, pickable=True, stroked=True, filled=True, ) view_state = pdk.ViewState(latitude=37.77613, longitude=-122.42284, zoom=12) display_pydeck_map([geojson_layer], view_state)
셀 실행을 클릭합니다.
출력은 다음과 비슷합니다.
코드 셀을 삽입하려면 코드를 클릭합니다.
지역별 스테이션 수를 집계하고 계산하고 포인트 배열이 포함된
polygon열을 만들려면 다음 코드를 입력합니다.# Aggregate and count the number of stations per neighborhood. gdf_count_stations = gdf_sanfrancisco_neighborhoods.sjoin(gdf_sf_bikestations, how='left', predicate='contains') gdf_count_stations = gdf_count_stations.groupby(by='neighborhood')['station_id'].count().rename('num_stations') gdf_stations_x_neighborhood = gdf_sanfrancisco_neighborhoods.join(gdf_count_stations, on='neighborhood', how='inner') # To simulate non-GeoJSON input data, create a polygon column that contains # an array of points by using the pandas.Series.map method. gdf_stations_x_neighborhood['polygon'] = gdf_stations_x_neighborhood['geometry'].map(lambda g: list(g.exterior.coords))
셀 실행을 클릭합니다.
코드를 실행해도 Colab 노트북에 출력이 생성되지 않습니다. 셀 옆의 체크표시는 코드가 성공적으로 실행되었음을 나타냅니다.
코드 셀을 삽입하려면 코드를 클릭합니다.
각 다각형에
fill_color열을 추가하려면 다음 코드를 입력합니다.# Create a color map gradient using the branch library, and add a fill_color # column for each of the polygons. colormap = branca.colormap.LinearColormap( colors=["lightblue", "darkred"], vmin=0, vmax=gdf_stations_x_neighborhood['num_stations'].max(), ) gdf_stations_x_neighborhood['fill_color'] = gdf_stations_x_neighborhood['num_stations'] \ .map(lambda c: list(colormap.rgba_bytes_tuple(c)[:3]) + [0.7 * 255]) # force opacity of 0.7
셀 실행을 클릭합니다.
코드를 실행해도 Colab 노트북에 출력이 생성되지 않습니다. 셀 옆의 체크표시는 코드가 성공적으로 실행되었음을 나타냅니다.
코드 셀을 삽입하려면 코드를 클릭합니다.
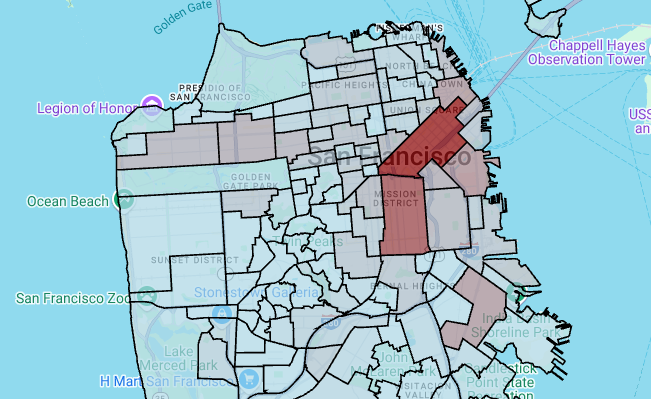
다각형 레이어를 렌더링하려면 다음 코드를 입력합니다.
# Render the polygon layer. polygon_layer = pdk.Layer( 'PolygonLayer', id="bike_stations_choropleth", data=gdf_stations_x_neighborhood, get_polygon='polygon', get_fill_color='fill_color', get_line_color=[0, 0, 0, 255], get_line_width=50, pickable=True, stroked=True, filled=True, ) view_state = pdk.ViewState(latitude=37.77613, longitude=-122.42284, zoom=12) display_pydeck_map([polygon_layer], view_state)
셀 실행을 클릭합니다.
출력은 다음과 비슷합니다.
코드 셀을 삽입하려면 코드를 클릭합니다.
샌프란시스코 경찰서(SFPD) 신고 데이터 세트의 데이터를 쿼리하려면 다음 코드를 입력합니다. 이 코드에서는
%%bigquery매직 함수를 사용하여 쿼리를 실행하고 결과를 DataFrame으로 반환합니다.# Query the incident key and location data from the SFPD reports dataset. %%bigquery gdf_incidents --project {GCP_PROJECT_ID} --use_geodataframe location_geography SELECT unique_key, location_geography FROM ( SELECT unique_key, SAFE.ST_GEOGFROMTEXT(location) AS location_geography, # WKT string to GEOMETRY EXTRACT(YEAR FROM timestamp) AS year, FROM `bigquery-public-data.san_francisco_sfpd_incidents.sfpd_incidents` incidents ) WHERE year = 2015
셀 실행을 클릭합니다.
출력은 다음과 비슷합니다.
Job ID 12345-1234-5678-1234-123456789 successfully executed: 100%코드 셀을 삽입하려면 코드를 클릭합니다.
각 사건의 위도와 경도에 대한 셀을 계산하려면 각 셀의 사건을 집계하고
geopandasDataFrame을 구성하고 히트맵 레이어의 각 육각형 중심을 추가하려면 다음 코드를 입력합니다.# Compute the cell for each incident's latitude and longitude. H3_RESOLUTION = 9 gdf_incidents['h3_cell'] = gdf_incidents.geometry.apply( lambda geom: h3.latlng_to_cell(geom.y, geom.x, H3_RESOLUTION) ) # Aggregate the incidents for each hexagon cell. count_incidents = gdf_incidents.groupby(by='h3_cell')['unique_key'].count().rename('num_incidents') # Construct a new geopandas.GeoDataFrame with the aggregate results. # Add the center of each hexagon for the HeatmapLayer to render. gdf_incidents_x_cell = gpd.GeoDataFrame(data=count_incidents).reset_index() gdf_incidents_x_cell['h3_center'] = gdf_incidents_x_cell['h3_cell'].apply(h3.cell_to_latlng) gdf_incidents_x_cell.info()
셀 실행을 클릭합니다.
출력은 다음과 비슷합니다.
<class 'geopandas.geodataframe.GeoDataFrame'> RangeIndex: 969 entries, 0 to 968 Data columns (total 3 columns): # Column Non-Null Count Dtype -- ------ -------------- ----- 0 h3_cell 969 non-null object 1 num_incidents 969 non-null Int64 2 h3_center 969 non-null object dtypes: Int64(1), object(2) memory usage: 23.8+ KB코드 셀을 삽입하려면 코드를 클릭합니다.
DataFrame의 처음 5개 행을 미리 보려면 다음 코드를 입력합니다.
# Preview the first five rows. gdf_incidents_x_cell.head()
셀 실행을 클릭합니다.
출력은 다음과 비슷합니다.

코드 셀을 삽입하려면 코드를 클릭합니다.
HeatmapLayer에서 사용할 수 있는 JSON 형식으로 데이터를 변환하려면 다음 코드를 입력합니다.# Convert to a JSON format recognized by the HeatmapLayer. def _make_heatmap_datum(row) -> dict: return { "latitude": row['h3_center'][0], "longitude": row['h3_center'][1], "weight": float(row['num_incidents']), } heatmap_data = gdf_incidents_x_cell.apply(_make_heatmap_datum, axis='columns').values.tolist()
셀 실행을 클릭합니다.
코드를 실행해도 Colab 노트북에 출력이 생성되지 않습니다. 셀 옆의 체크표시는 코드가 성공적으로 실행되었음을 나타냅니다.
코드 셀을 삽입하려면 코드를 클릭합니다.
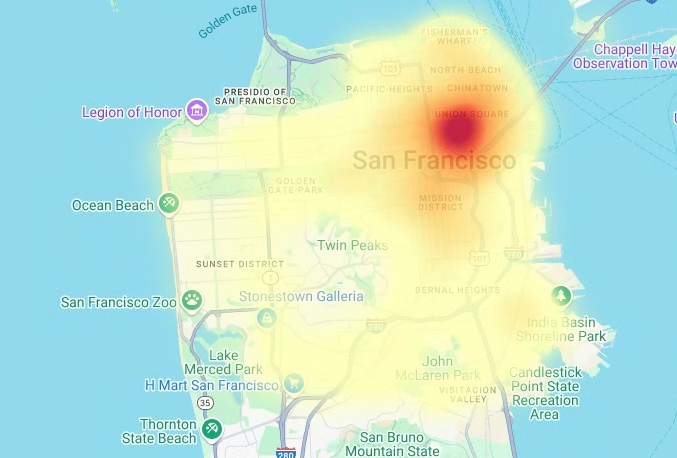
히트맵을 렌더링하려면 다음 코드를 입력합니다.
# Render the heatmap. heatmap_layer = pdk.Layer( "HeatmapLayer", id="sfpd_heatmap", data=heatmap_data, get_position=['longitude', 'latitude'], get_weight='weight', opacity=0.7, radius_pixels=99, # this limitation can introduce artifacts (see above) aggregation='MEAN', ) view_state = pdk.ViewState(latitude=37.77613, longitude=-122.42284, zoom=12) display_pydeck_map([heatmap_layer], view_state)
셀 실행을 클릭합니다.
출력은 다음과 비슷합니다.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Colab에서 보안 비밀을 클릭합니다.
GMP_API_KEY행 끝에서 삭제를 클릭합니다.선택사항: 노트북을 삭제하려면 파일 > 휴지통으로 이동을 클릭합니다.
- BigQuery의 지리 공간 분석에 대한 자세한 내용은 BigQuery의 지리 공간 분석 소개를 참고하세요.
- BigQuery에서 지리 공간 데이터를 시각화하는 방법을 알아보려면 지리 공간 데이터 시각화를 참고하세요.
pydeck및 기타deck.gl차트 유형에 대해 자세히 알아보려면pydeck갤러리,deck.gl레이어 카탈로그,deck.glGitHub 소스에서 예시를 확인하세요.- 데이터 프레임에서 지리 공간 데이터를 사용하는 방법에 관한 자세한 내용은 GeoPandas 시작하기 페이지 및 GeoPandas 사용자 가이드를 참고하세요.
- 기하학적 객체 조작에 관한 자세한 내용은 Shapely 사용자 설명서를 참고하세요.
- BigQuery에서 Google Earth Engine 데이터를 사용하는 방법을 알아보려면 Google Earth Engine 문서의 BigQuery로 내보내기를 참고하세요.
필요한 역할
새 프로젝트를 만드는 경우 프로젝트 소유자가 되며 이 튜토리얼을 완료하는 데 필요한 모든 필수 IAM 권한이 부여됩니다.
기존 프로젝트를 사용하는 경우 쿼리 작업을 실행하려면 다음 프로젝트 수준 역할이 필요합니다.
Make sure that you have the following role or roles on the project:
Check for the roles
Grant the roles
BigQuery의 역할에 대한 자세한 내용은 사전 정의된 IAM 역할을 참조하세요.
Colab 노트북 만들기
이 튜토리얼에서는 지리정보 분석 데이터를 시각화하는 Colab 노트북을 빌드합니다. 튜토리얼의 GitHub 버전 상단에 있는 링크(Colab의 BigQuery 지리 공간 시각화)를 클릭하여 Colab, Colab Enterprise 또는 BigQuery Studio에서 사전 빌드된 노트북 버전을 열 수 있습니다.
Google Cloud 및 Google 지도로 인증
이 튜토리얼에서는 BigQuery 데이터 세트를 쿼리하고 Google Maps JavaScript API를 사용합니다. 이러한 리소스를 사용하려면 Google Cloud 및 지도 API로 Colab 런타임을 인증합니다.
Google Cloud로 인증
선택사항: Google 지도로 인증
Google Maps Platform을 기본 지도용 지도 제공업체로 사용하는 경우 Google Maps Platform API 키를 제공해야 합니다. 노트북이 Colab 보안 비밀에서 키를 가져옵니다.
이 단계는 지도 API를 사용하는 경우에만 필요합니다. Google Maps Platform으로 인증하지 않으면 pydeck에서 carto 지도를 대신 사용합니다.
Python 패키지 설치 및 데이터 과학 라이브러리 가져오기
이 튜토리얼에서는 colabtools(google.colab) Python 모듈 외에도 여러 Python 패키지와 데이터 과학 라이브러리를 사용합니다.
이 섹션에서는 pydeck 및 h3 패키지를 설치합니다. pydeck은 deck.gl을 기반으로 Python에서 대규모 공간 렌더링을 제공합니다.
h3-py는 Python에서 Uber의 H3 육각형 계층적 지리공간 색인 시스템을 제공합니다.
그런 다음 h3 및 pydeck 라이브러리와 다음 Python 지리공간 라이브러리를 가져옵니다.
라이브러리를 가져온 후 Colab의 pandas DataFrame에 대화형 테이블을 사용 설정합니다.
pydeck 및 h3 패키지 설치
Python 라이브러리 가져오기
pandas DataFrames의 대화형 테이블 사용 설정
공유 루틴 만들기
이 섹션에서는 기본 지도에 레이어를 렌더링하는 공유 루틴을 만듭니다.
분산형 차트 만들기
이 섹션에서는 bigquery-public-data.san_francisco_bikeshare.bikeshare_station_info 테이블에서 데이터를 가져와 샌프란시스코 Ford GoBike Share 공개 데이터 세트의 모든 자전거 공유 정거장의 분산형 차트를 만듭니다. 분산형 차트는 deck.gl 프레임워크의 레이어와 분산형 차트 레이어를 사용하여 만들어집니다.
분산형 차트는 개별 포인트의 하위 집합(스팟 확인이라고도 함)을 검토해야 할 때 유용합니다.
다음 예에서는 레이어와 분산형 차트 레이어를 사용하여 개별 점을 원으로 렌더링하는 방법을 보여줍니다.
포인트를 렌더링하려면 자전거 공유 데이터 세트의 station_geom 열에서 경도와 위도를 x 및 y 좌표로 추출해야 합니다.
gdf_sf_bikestations는 geopandas.GeoDataFrame이므로 좌표는 station_geom 형상 열에서 직접 액세스됩니다. 열의 .x 속성을 사용하여 경도를 가져오고 .y 속성을 사용하여 위도를 가져올 수 있습니다. 그런 다음 새 경도 및 위도 열에 저장할 수 있습니다.
다각형 시각화
지리정보 분석을 사용하면 GEOGRAPHY 데이터 유형과 GoogleSQL 지리 함수를 사용하여 BigQuery에서 지리공간 데이터를 분석하고 시각화할 수 있습니다.
지리정보 분석의 GEOGRAPHY 데이터 유형은 점의 집합으로 표시되는 점, 유도선, 다각형의 모음 또는 지구 표면의 하위 집합입니다. GEOGRAPHY 유형은 다음과 같은 객체를 포함할 수 있습니다.
지원되는 모든 객체 목록은 GEOGRAPHY 유형 문서를 참고하세요.
예상되는 모양을 모르는 상태에서 지리 공간 데이터를 제공받은 경우 데이터를 시각화하여 모양을 확인할 수 있습니다. 지리 데이터를 GeoJSON 형식으로 변환하여 도형을 시각화할 수 있습니다. 그런 다음 deck.gl 프레임워크의 GeoJSON 레이어를 사용하여 GeoJSON 데이터를 시각화할 수 있습니다.
이 섹션에서는 San Francisco Neighborhoods 데이터 세트의 지리 데이터를 쿼리한 다음 다각형을 시각화합니다.
등치 지역도 만들기
GeoJSON 형식으로 변환하기 어려운 다각형으로 데이터를 탐색하는 경우 deck.gl 프레임워크의 다각형 레이어를 대신 사용할 수 있습니다. 다각형 레이어는 점 배열과 같은 특정 유형의 입력 데이터를 처리할 수 있습니다.
이 섹션에서는 다각형 레이어를 사용하여 점 배열을 렌더링하고 결과를 사용하여 등치 지역도를 렌더링합니다. 등치 지역도는 샌프란시스코 지역 데이터 세트의 데이터를 샌프란시스코 Ford GoBike Share 데이터 세트와 결합하여 지역별 자전거 공유 스테이션의 밀도를 보여줍니다.
히트맵 만들기
의미 있는 경계를 알고 있는 경우 등치 지역도가 유용합니다. 의미 있는 경계가 알려지지 않은 데이터가 있는 경우 히트맵 레이어를 사용하여 연속 밀도를 렌더링할 수 있습니다.
다음 예에서는 샌프란시스코 경찰서(SFPD) 보고서 데이터 세트의 bigquery-public-data.san_francisco_sfpd_incidents.sfpd_incidents 테이블에서 데이터를 쿼리합니다. 이 데이터는 2015년의 사고 분포를 시각화하는 데 사용됩니다.
히트맵의 경우 렌더링하기 전에 데이터를 양자화하고 집계하는 것이 좋습니다. 이 예에서는 Carto H3 공간 색인을 사용하여 데이터를 양자화하고 집계합니다.
히트맵은 deck.gl 프레임워크의 히트맵 레이어를 사용하여 생성됩니다.
이 예에서는 h3 Python 라이브러리를 사용하여 인시던트 포인트를 육각형으로 집계하여 양자화합니다. h3.latlng_to_cell 함수는 인시던트의 위치(위도 및 경도)를 H3 셀 색인에 매핑하는 데 사용됩니다. H3 해상도 9는 히트맵에 충분한 집계된 육각형을 제공합니다.
h3.cell_to_latlng 함수는 각 육각형의 중심을 결정하는 데 사용됩니다.
삭제
이 튜토리얼에서 사용된 리소스 비용이 Google Cloud 계정에 청구되지 않도록 하려면 리소스가 포함된 프로젝트를 삭제하거나 프로젝트를 유지하고 개별 리소스를 삭제하세요.
프로젝트 삭제
콘솔
gcloud
Google 지도 API 키 및 노트북 삭제
Google Cloud 프로젝트를 삭제한 후 Google Maps API를 사용한 경우 Colab Secrets에서 Google Maps API 키를 삭제한 다음 원하는 경우 노트북을 삭제합니다.