Gestionar recomendaciones de particiones y clústeres
En este documento se describe cómo funciona el recomendador de particiones y clústeres, cómo ver las recomendaciones y las estadísticas, y cómo aplicar las recomendaciones de particiones y clústeres.
Cómo funciona el sistema de recomendaciones
El recomendador de particiones y clústeres de BigQuery genera recomendaciones de particiones o clústeres para optimizar tus tablas de BigQuery. El recomendador analiza los flujos de trabajo de tus tablas de BigQuery y ofrece recomendaciones para optimizar los flujos de trabajo y los costes de las consultas mediante la creación de particiones o clústeres de tablas.
Para obtener más información sobre el servicio Recommender, consulta la descripción general de Recommender.
El recomendador de particiones y clústeres usa los datos de ejecución de la carga de trabajo del proyecto de los últimos 30 días para analizar cada tabla de BigQuery en busca de configuraciones de particiones y clústeres que no sean óptimas. El recomendador también usa el aprendizaje automático para predecir cuánto se podría optimizar la ejecución de la carga de trabajo con diferentes configuraciones de partición o de clúster. Si el recomendador detecta que la partición o la agrupación en clústeres de una tabla supone un ahorro significativo, genera una recomendación. El recomendador de particiones y clústeres genera los siguientes tipos de recomendaciones:
| Tipo de tabla ya creada | Subtipo de recomendación | Ejemplo de recomendación |
|---|---|---|
| Sin particiones ni clústeres | Partición | "Ahorra unas 64 horas de ranura al mes creando particiones en column_C por DÍA" |
| Sin particiones ni clústeres | Clúster | "Ahorra unas 64 horas de ranura al mes agrupando por columna_C" |
| Particionada y no agrupada en clústeres | Clúster | "Ahorra unas 64 horas de ranura al mes agrupando por columna_C" |
Cada recomendación consta de tres partes:
- Orientación para particionar o agrupar una tabla específica
- La columna específica de una tabla que se va a particionar o agrupar en clústeres
- Ahorro mensual estimado al aplicar la recomendación
Para calcular el posible ahorro de carga de trabajo, la herramienta de recomendaciones asume que los datos históricos de carga de trabajo de ejecución de los últimos 30 días representan la carga de trabajo futura.
La API Recommender también devuelve información sobre la carga de trabajo de las tablas en forma de estadísticas. Las estadísticas son conclusiones que te ayudan a entender la carga de trabajo de tu proyecto y te proporcionan más contexto sobre cómo una partición o una recomendación de clúster puede mejorar los costes de la carga de trabajo.
Limitaciones
El recomendador de particiones y clústeres no admite tablas de BigQuery con SQL antiguo. Al generar una recomendación, el recomendador excluye las consultas de SQL antiguo de su análisis. Además, si se aplican recomendaciones de partición en tablas de BigQuery con SQL antiguo, se interrumpirán los flujos de trabajo de SQL antiguo de esa tabla.
Antes de aplicar las recomendaciones de partición, migra tus flujos de trabajo de SQL antiguo a GoogleSQL.
BigQuery no permite cambiar el esquema de partición de una tabla. Solo puedes cambiar el particionado de una tabla en una copia de la tabla. Para obtener más información, consulta Aplicar recomendaciones de partición.
Ubicaciones
La recomendación de partición y de creación de clústeres está disponible en las siguientes ubicaciones de procesamiento:
| Descripción de la región | Nombre de la región | Detalles | |
|---|---|---|---|
| Asia‑Pacífico | |||
| Deli | asia-south2 |
||
| Hong Kong | asia-east2 |
||
| Yakarta | asia-southeast2 |
||
| Bombay | asia-south1 |
||
| Osaka | asia-northeast2 |
||
| Seúl | asia-northeast3 |
||
| Singapur | asia-southeast1 |
||
| Sídney | australia-southeast1 |
||
| Taiwán | asia-east1 |
||
| Tokio | asia-northeast1 |
||
| Europa | |||
| Bélgica | europe-west1 |
|
|
| Berlín | europe-west10 |
||
| Multirregional de la UE | eu |
||
| Fráncfort | europe-west3 |
||
| Londres | europe-west2 |
|
|
| Países Bajos | europe-west4 |
|
|
| Zúrich | europe-west6 |
|
|
| América | |||
| Iowa | us-central1 |
|
|
| Las Vegas | us-west4 |
||
| Los Ángeles | us-west2 |
||
| Montreal | northamerica-northeast1 |
|
|
| Norte de Virginia | us-east4 |
||
| Oregón | us-west1 |
|
|
| Salt Lake City | us-west3 |
||
| São Paulo | southamerica-east1 |
|
|
| Toronto | northamerica-northeast2 |
|
|
| Multirregional de EE. UU. | us |
||
Antes de empezar
- Asegúrate de que Gemini en BigQuery esté habilitado en tu Google Cloud proyecto.
- Habilita la API Recommender.
Permisos obligatorios
Para obtener los permisos que necesitas para acceder a las recomendaciones de particiones y clústeres, pide a tu administrador que te asigne el rol de gestión de identidades y accesos Lector de recomendaciones de particiones y clústeres de BigQuery (roles/recommender.bigqueryPartitionClusterViewer).
Para obtener más información sobre cómo conceder roles, consulta el artículo Gestionar el acceso a proyectos, carpetas y organizaciones.
Este rol predefinido contiene los permisos necesarios para acceder a las recomendaciones de particiones y clústeres. Para ver los permisos exactos que se necesitan, despliega la sección Permisos necesarios:
Permisos obligatorios
Para acceder a las recomendaciones de particiones y clústeres, se necesitan los siguientes permisos:
-
recommender.bigqueryPartitionClusterRecommendations.get -
recommender.bigqueryPartitionClusterRecommendations.list
También puedes obtener estos permisos con roles personalizados u otros roles predefinidos.
Para obtener más información sobre los roles y permisos de gestión de identidades y accesos en BigQuery, consulta la introducción a la gestión de identidades y accesos.
Ver recomendaciones
En esta sección se describe cómo ver recomendaciones e estadísticas de particiones y clústeres mediante la Google Cloud consola, la CLI de Google Cloud o la API Recommender.
.Selecciona una de las opciones siguientes:
Consola
En la Google Cloud consola, ve a la página BigQuery.
En el menú de navegación, haga clic en Recomendaciones.
En la pestaña Recomendaciones se muestran todas las recomendaciones disponibles para tu proyecto.
En el panel Optimizar el coste de la carga de trabajo de BigQuery, haga clic en Ver todo.
En la tabla de recomendaciones de costes se muestran todas las recomendaciones generadas para el proyecto actual. Por ejemplo, en la siguiente captura de pantalla se muestra que el recomendador ha analizado la tabla
example_tabley, a continuación, ha recomendado agrupar la columnaexample_columnpara ahorrar una cantidad aproximada de bytes y ranuras.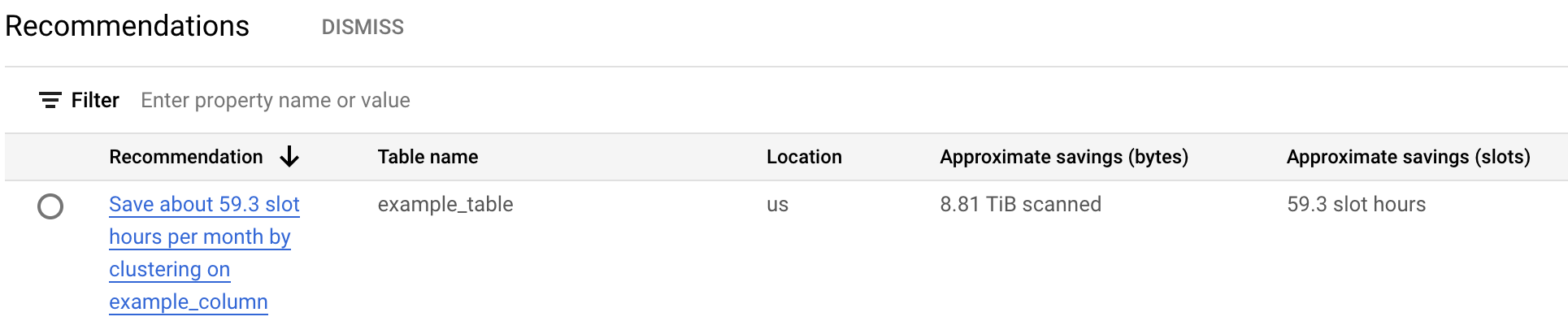
Para ver más información sobre la estadística y la recomendación de la tabla, haz clic en una recomendación.
gcloud
Para ver las recomendaciones de particiones o clústeres de un proyecto concreto, usa el comando gcloud recommender recommendations list:
gcloud recommender recommendations list \
--project=PROJECT_NAME \
--location=REGION_NAME \
--recommender=google.bigquery.table.PartitionClusterRecommender \
--format=FORMAT_TYPE \
Haz los cambios siguientes:
PROJECT_NAME: el nombre del proyecto que contiene tu tabla de BigQueryREGION_NAME: la región en la que se encuentra tu proyectoFORMAT_TYPE: un formato de salida de la CLI de gcloud compatible, como JSON
| Propiedad | Relevante para el subtipo | Descripción |
|---|---|---|
recommenderSubtype |
Partición o clúster | Indica el tipo de recomendación. |
content.overview.partitionColumn |
Partición | Nombre de la columna de partición recomendada. |
content.overview.partitionTimeUnit |
Partición | Unidad de tiempo de partición recomendada. Por ejemplo, DAY significa que la recomendación es tener particiones diarias en la columna recomendada. |
content.overview.clusterColumns |
Clúster | Nombres de columnas de clustering recomendados. |
- Para obtener más información sobre otros campos de la respuesta de la herramienta de recomendaciones, consulta Recurso REST:
projects.locations.recommendersrecommendation. - Para obtener más información sobre el uso de la API Recommender, consulta Usar la API: recomendaciones.
Para ver estadísticas de tablas con gcloud CLI, usa el comando gcloud recommender insights list:
gcloud recommender insights list \
--project=PROJECT_NAME \
--location=REGION_NAME \
--insight-type=google.bigquery.table.StatsInsight \
--format=FORMAT_TYPE \
Haz los cambios siguientes:
PROJECT_NAME: el nombre del proyecto que contiene tu tabla de BigQueryREGION_NAME: la región en la que se encuentra tu proyectoFORMAT_TYPE: un formato de salida de la CLI de gcloud compatible, como JSON
| Propiedad | Relevante para el subtipo | Descripción |
|---|---|---|
content.existingPartitionColumn |
Clúster | Columna de partición actual (si la hay) |
content.tableSizeTb |
Todo | Tamaño de la tabla en terabytes |
content.bytesReadMonthly |
Todo | Bytes leídos de la tabla al mes |
content.slotMsConsumedMonthly |
Todo | Milisegundos de ranura mensuales consumidos por la carga de trabajo que se ejecuta en la tabla. |
content.queryJobsCountMonthly |
Todo | Número mensual de tareas que se ejecutan en la tabla. |
- Para obtener más información sobre otros campos de la respuesta de estadísticas, consulta Recurso REST:
projects.locations.insightTypes.insights. - Para obtener más información sobre cómo usar las estadísticas, consulta el artículo Usar la API: Estadísticas.
API REST
Para ver las recomendaciones de particiones o clústeres de un proyecto específico, usa la API REST. Con cada comando, debes proporcionar un token de autenticación, que puedes obtener mediante la CLI de gcloud. Para obtener más información sobre cómo obtener un token de autenticación, consulta Métodos para obtener un token de ID.
Puedes usar la solicitud curl list para ver todas las recomendaciones de un proyecto específico:
curl
-H "Authorization: Bearer $GCLOUD_AUTH_TOKEN"
-H "x-goog-user-project: PROJECT_NAME" https://recommender.googleapis.com/v1/projects/my-project/locations/us/recommenders/google.bigquery.table.PartitionClusterRecommender/recommendations
Haz los cambios siguientes:
GCLOUD_AUTH_TOKEN: el nombre de un token de acceso de la CLI de gcloud válidoPROJECT_NAME: el nombre del proyecto que contiene tu tabla de BigQuery
| Propiedad | Relevante para el subtipo | Descripción |
|---|---|---|
recommenderSubtype |
Partición o clúster | Indica el tipo de recomendación. |
content.overview.partitionColumn |
Partición | Nombre de la columna de partición recomendada. |
content.overview.partitionTimeUnit |
Partición | Unidad de tiempo de partición recomendada. Por ejemplo, DAY significa que la recomendación es tener particiones diarias en la columna recomendada. |
content.overview.clusterColumns |
Clúster | Nombres de columnas de clustering recomendados. |
- Para obtener más información sobre otros campos de la respuesta de la herramienta de recomendaciones, consulta Recurso REST:
projects.locations.recommendersrecommendation. - Para obtener más información sobre el uso de la API Recommender, consulta Usar la API: recomendaciones.
Para ver estadísticas de tablas mediante la API REST, ejecuta el siguiente comando:
curl -H "Authorization: Bearer $GCLOUD_AUTH_TOKEN" -H "x-goog-user-project: PROJECT_NAME" https://recommender.googleapis.com/v1/projects/my-project/locations/us/insightTypes/google.bigquery.table.StatsInsight/insights
Haz los cambios siguientes:
GCLOUD_AUTH_TOKEN: el nombre de un token de acceso de la CLI de gcloud válidoPROJECT_NAME: el nombre del proyecto que contiene tu tabla de BigQuery
| Propiedad | Relevante para el subtipo | Descripción |
|---|---|---|
content.existingPartitionColumn |
Clúster | Columna de partición actual (si la hay) |
content.tableSizeTb |
Todo | Tamaño de la tabla en terabytes |
content.bytesReadMonthly |
Todo | Bytes leídos de la tabla al mes |
content.slotMsConsumedMonthly |
Todo | Milisegundos de ranura mensuales consumidos por la carga de trabajo que se ejecuta en la tabla. |
content.queryJobsCountMonthly |
Todo | Número mensual de tareas que se ejecutan en la tabla. |
- Para obtener más información sobre otros campos de la respuesta de estadísticas, consulta Recurso REST:
projects.locations.insightTypes.insights. - Para obtener más información sobre cómo usar las estadísticas, consulta el artículo Usar la API: Estadísticas.
Ver recomendaciones con INFORMATION_SCHEMA
También puedes ver tus recomendaciones y estadísticas con las INFORMATION_SCHEMAvistas. Por ejemplo, puedes usar la vista INFORMATION_SCHEMA.RECOMMENDATIONS para ver las tres recomendaciones principales en función del ahorro de espacios publicitarios, como se muestra en el siguiente ejemplo:
SELECT
recommender,
target_resources,
LAX_INT64(additional_details.overview.bytesSavedMonthly) / POW(1024, 3) as est_gb_saved_monthly,
LAX_INT64(additional_details.overview.slotMsSavedMonthly) / (1000 * 3600) as slot_hours_saved_monthly,
last_updated_time
FROM
`region-us`.INFORMATION_SCHEMA.RECOMMENDATIONS
WHERE
primary_impact.category = 'COST'
AND
state = 'ACTIVE'
ORDER by
slot_hours_saved_monthly DESC
LIMIT 3;
El resultado es similar al siguiente:
+---------------------------------------------------+--------------------------------------------------------------------------------------------------+ | recommender | target_resources | est_gb_saved_monthly | slot_hours_saved_monthly | last_updated_time +---------------------------------------------------+--------------------------------------------------------------------------------------------------+ | google.bigquery.materializedview.Recommender | ["project_resource"] | 140805.38289248943 | 9613.139166666666 | 2024-07-01 13:00:00 | google.bigquery.table.PartitionClusterRecommender | ["table_resource_1"] | 4393.7416711859405 | 56.61476777777777 | 2024-07-01 13:00:00 | google.bigquery.table.PartitionClusterRecommender | ["table_resource_2"] | 3934.07264107652 | 10.499466666666667 | 2024-07-01 13:00:00 +---------------------------------------------------+--------------------------------------------------------------------------------------------------+
Para obtener más información, consulta los siguientes recursos:
INFORMATION_SCHEMA.RECOMMENDATIONSverINFORMATION_SCHEMA.RECOMMENDATIONS_BY_ORGANIZATIONverINFORMATION_SCHEMA.INSIGHTSver
Aplicar recomendaciones de clústeres
Para aplicar las recomendaciones de clústeres, haz una de las siguientes acciones:
- Aplicar clústeres directamente a la tabla original
- Aplicar clústeres a una tabla copiada
- Aplicar clústeres en una vista materializada
Aplicar clústeres directamente a la tabla original
Puedes aplicar recomendaciones de clústeres directamente a una tabla de BigQuery. Este método es más rápido que aplicar recomendaciones a una tabla copiada, pero no conserva una tabla de copia de seguridad.
Sigue estos pasos para aplicar una nueva especificación de clustering a tablas sin particiones o con particiones.
En la herramienta bq, actualiza la especificación de clustering de tu tabla para que coincida con el nuevo clustering:
bq update --clustering_fields=CLUSTER_COLUMN DATASET.ORIGINAL_TABLE
Haz los cambios siguientes:
CLUSTER_COLUMN: la columna en la que se basa la agrupación. Por ejemplo,mycolumn.DATASET: el nombre del conjunto de datos que contiene la tabla (por ejemplo,mydatasetORIGINAL_TABLE: el nombre de la tabla original (por ejemplo,mytable)
También puedes llamar al método de API
tables.updateotables.patchpara modificar la especificación de la agrupación en clústeres.Para agrupar todas las filas según la nueva especificación de clustering, ejecuta la siguiente instrucción
UPDATE:UPDATE DATASET.ORIGINAL_TABLE SET CLUSTER_COLUMN=CLUSTER_COLUMN WHERE true
Aplicar clústeres a una tabla copiada
Cuando apliques recomendaciones de clústeres a una tabla de BigQuery, primero puedes copiar la tabla original y, después, aplicar la recomendación a la tabla copiada. De esta forma, tus datos originales se conservarán si necesitas deshacer el cambio en la configuración de la agrupación en clústeres.
Puedes usar este método para aplicar recomendaciones de clústeres a tablas con y sin particiones.
En la Google Cloud consola, ve a la página BigQuery.
En el editor de consultas, crea una tabla vacía con los mismos metadatos (incluidas las especificaciones de clúster) que la tabla original mediante el operador
LIKE:CREATE TABLE DATASET.COPIED_TABLE LIKE DATASET.ORIGINAL_TABLE
Haz los cambios siguientes:
DATASET: el nombre del conjunto de datos que contiene la tabla (por ejemplo,mydatasetCOPIED_TABLE: el nombre de la tabla copiada. Por ejemplo:copy_mytableORIGINAL_TABLE: el nombre de la tabla original. Por ejemplo:mytable
En la Google Cloud consola, abre el editor de Cloud Shell.
En el editor de Cloud Shell, actualiza la especificación de clustering de la tabla copiada para que coincida con el clustering recomendado mediante el comando
bq update:bq update --clustering_fields=CLUSTER_COLUMN DATASET.COPIED_TABLE
Sustituye
CLUSTER_COLUMNpor la columna por la que quieres agrupar los datos (por ejemplo,mycolumn).También puedes llamar al método de API
tables.updateotables.patchpara modificar la especificación de la agrupación en clústeres.En el editor de consultas, recupera el esquema de la tabla con la configuración de partición y clustering de la tabla original, si existe alguna partición o clustering. Para recuperar el esquema, consulta la vista
INFORMATION_SCHEMA.TABLESde la tabla original:SELECT ddl FROM DATASET.INFORMATION_SCHEMA.TABLES WHERE table_name = 'DATASET.ORIGINAL_TABLE;'
El resultado es la instrucción completa del lenguaje de definición de datos (DDL) de ORIGINAL_TABLE, incluida la cláusula
PARTITION BY. Para obtener más información sobre los argumentos de la salida de DDL, consulta la instrucciónCREATE TABLE.El resultado de DDL indica el tipo de partición de la tabla original:
Tipo de partición Ejemplo de salida Sin particiones Falta la cláusula PARTITION BY.Particiones por columna de tabla PARTITION BY c0PARTITION BY DATE(c0)PARTITION BY DATETIME_TRUNC(c0, MONTH)Particionadas por hora de ingestión PARTITION BY _PARTITIONDATEPARTITION BY DATETIME_TRUNC(_PARTITIONTIME, MONTH)Ingiere datos en la tabla copiada. El proceso que utilices dependerá del tipo de partición.
- Si la tabla original no tiene particiones o tiene particiones por una columna de la tabla, ingiere los datos de la tabla original en la tabla copiada:
INSERT INTO DATASET.COPIED_TABLE SELECT * FROM DATASET.ORIGINAL_TABLE
Si la tabla original está particionada por hora de ingestión, sigue estos pasos:
Para obtener la lista de columnas que formarán la expresión de ingestión de datos, usa la vista
INFORMATION_SCHEMA.COLUMNS:SELECT ARRAY_TO_STRING(( SELECT ARRAY( SELECT column_name FROM DATASET.INFORMATION_SCHEMA.COLUMNS WHERE table_name = 'ORIGINAL_TABLE')), ", ")
El resultado es una lista de nombres de columnas separados por comas.
Ingiere los datos de la tabla original en la tabla copiada:
INSERT DATASET.COPIED_TABLE (COLUMN_NAMES, _PARTITIONTIME) SELECT *, _PARTITIONTIME FROM DATASET.ORIGINAL_TABLE
Sustituye
COLUMN_NAMESpor la lista de columnas que se ha generado en el paso anterior, separadas por comas (por ejemplo,col1, col2, col3).
Ahora tienes una tabla copiada en clúster con los mismos datos que la tabla original. En los pasos siguientes, sustituirá la tabla original por una tabla recién agrupada en clústeres.
- Si la tabla original no tiene particiones o tiene particiones por una columna de la tabla, ingiere los datos de la tabla original en la tabla copiada:
Cambia el nombre de la tabla original por el de una tabla de copia de seguridad:
ALTER TABLE DATASET.ORIGINAL_TABLE RENAME TO DATASET.BACKUP_TABLE
Sustituye
BACKUP_TABLEpor el nombre que quieras darle a la tabla de copia de seguridad (por ejemplo,backup_mytable).Cambia el nombre de la tabla copiada por el de la tabla original:
ALTER TABLE DATASET.COPIED_TABLE RENAME TO DATASET.ORIGINAL_TABLE
La tabla original ahora se agrupa en clústeres según la recomendación.
- Acceso y permisos, como permisos de gestión de identidades y accesos, acceso a nivel de fila o acceso a nivel de columna.
- Artefactos de tabla, como clones de tabla, instantáneas de tabla o índices de búsqueda.
- El estado de los procesos de tabla en curso, como las vistas materializadas o los trabajos que se ejecutaron al copiar la tabla.
- La posibilidad de acceder al historial de datos de las tablas mediante la función Viaje en el tiempo.
- Los metadatos asociados a la tabla original, como
table_option_listocolumn_option_list. Para obtener más información, consulta Instrucciones del lenguaje de definición de datos.
Si surge algún problema, debe migrar manualmente los artefactos afectados a la nueva tabla.
Después de revisar la tabla agrupada, puedes eliminar la tabla de copia de seguridad con el siguiente comando:DROP TABLE DATASET.BACKUP_TABLE
Aplicar clústeres en una vista materializada
Puedes crear una vista materializada de la tabla para almacenar los datos de la tabla original con la recomendación aplicada. Si usas vistas materializadas para aplicar recomendaciones, te aseguras de que los datos agrupados se mantengan actualizados mediante actualizaciones automáticas. Hay aspectos relacionados con los precios que debes tener en cuenta al consultar, mantener y almacenar vistas materializadas. Para saber cómo crear una vista materializada agrupada, consulta Vistas materializadas agrupadas.Aplicar recomendaciones de partición
Para aplicar las recomendaciones de partición, debes hacerlo en una copia de la tabla original. BigQuery no admite el cambio in situ del esquema de partición de una tabla, como convertir una tabla sin particiones en una tabla con particiones, cambiar el esquema de partición de una tabla o crear una vista materializada con un esquema de partición diferente al de la tabla base. Solo puedes cambiar el particionado de una tabla en una copia de la tabla.
Aplicar recomendaciones de particiones a una tabla copiada
Cuando apliques recomendaciones de partición a una tabla de BigQuery, primero debes copiar la tabla original y, a continuación, aplicar la recomendación a la tabla copiada. De este modo, se conservarán los datos originales si necesitas restaurar una partición.
En el siguiente procedimiento se usa una recomendación de ejemplo para particionar una tabla por la unidad de tiempo de partición DAY.
Para crear una tabla copiada con las recomendaciones de partición, sigue estos pasos:
CREATE TABLE DATASET.COPIED_TABLE PARTITION BY DATE_TRUNC(PARTITION_COLUMN, DAY) AS SELECT * FROM DATASET.ORIGINAL_TABLE
Haz los cambios siguientes:
DATASET: el nombre del conjunto de datos que contiene la tabla (por ejemplo,mydatasetCOPIED_TABLE: el nombre de la tabla copiada (por ejemplo,copy_mytable)PARTITION_COLUMN: la columna por la que se va a particionar. Por ejemplo,mycolumn.
Para obtener más información sobre cómo crear tablas con particiones, consulta el artículo Crear tablas con particiones.
Cambia el nombre de la tabla original por el de una tabla de copia de seguridad:
ALTER TABLE DATASET.ORIGINAL_TABLE RENAME TO DATASET.BACKUP_TABLE
Sustituye
BACKUP_TABLEpor el nombre que quieras darle a la tabla de copia de seguridad (por ejemplo,backup_mytable).Cambia el nombre de la tabla copiada por el de la tabla original:
ALTER TABLE DATASET.COPIED_TABLE RENAME TO DATASET.ORIGINAL_TABLE
La tabla original ahora está particionada según la recomendación de partición.
- Acceso y permisos, como permisos de gestión de identidades y accesos, acceso a nivel de fila o acceso a nivel de columna.
- Artefactos de tabla, como clones de tabla, instantáneas de tabla o índices de búsqueda.
- El estado de los procesos de tabla en curso, como las vistas materializadas o los trabajos que se ejecutaron al copiar la tabla.
- La posibilidad de acceder al historial de datos de las tablas mediante la función Viaje en el tiempo.
- Los metadatos asociados a la tabla original, como
table_option_listocolumn_option_list. Para obtener más información, consulta Instrucciones del lenguaje de definición de datos. - Posibilidad de usar SQL antiguo para escribir los resultados de las consultas en tablas con particiones. El uso de SQL antiguo no se admite completamente en las tablas con particiones. Una solución es migrar tus flujos de trabajo de SQL antiguo a GoogleSQL antes de aplicar una recomendación de partición.
Si surge algún problema, debe migrar manualmente los artefactos afectados a la nueva tabla.
Después de revisar la tabla particionada, puedes eliminar la tabla de copia de seguridad con el siguiente comando:DROP TABLE DATASET.BACKUP_TABLE
Precios
Cuando aplicas una recomendación a una tabla, puedes incurrir en los siguientes costes:
- Costes de procesamiento. Cuando aplicas una recomendación, ejecutas una consulta del lenguaje de definición de datos (DDL) o del lenguaje de manipulación de datos (DML) en tu proyecto de BigQuery.
- Costes de almacenamiento. Si usas el método de copiar una tabla, usarás almacenamiento adicional para la tabla copiada (o de copia de seguridad).
Se aplican cargos estándar por procesamiento y almacenamiento en función de la cuenta de facturación asociada al proyecto. Para obtener más información, consulta los precios de BigQuery.
Solución de problemas
Problema: No aparecen recomendaciones para una tabla específica.
Es posible que no aparezcan recomendaciones de partición para las tablas que cumplan estos criterios:
- La tabla tiene un tamaño inferior a 100 GB.
- La tabla ya tiene particiones o está agrupada en clústeres.
Es posible que no aparezcan recomendaciones de clústeres para las tablas que cumplan estos criterios:
- La tabla tiene un tamaño inferior a 10 GB.
- La tabla ya está agrupada en clústeres.
Es posible que se supriman las recomendaciones de particiones y clústeres en los siguientes casos:
- La tabla tiene un coste de escritura elevado debido a las operaciones del lenguaje de manipulación de datos (DML).
- No se ha leído la tabla en los últimos 30 días.
- El ahorro mensual estimado es demasiado insignificante (menos de una hora de ahorro).