矢量搜索简介
本文档简要介绍了 BigQuery 中的矢量搜索。向量搜索是一种使用嵌入式技术比较类似对象的技术,用于为 Google 产品(包括 Google 搜索、YouTube 和 Google Play)提供支持。您可以使用向量搜索来大规模执行搜索。将向量索引与向量搜索结合使用时,您可以利用倒排文件索引 (IVF) 和 ScaNN 算法等基础技术。
向量搜索基于嵌入式搜索。嵌入是表示给定实体(如一段文本或音频文件)的高维数字向量。机器学习 (ML) 模型使用嵌入对此类实体的语义进行编码,以便更轻松地推断和比较实体。例如,聚类、分类和推荐模型中的常见操作是测量嵌入空间中矢量之间的距离,以查找语义上最相似的项。
当您考虑如何绘制不同项时,就可以直观地理解嵌入空间中的语义相似性和距离的概念。例如,cat、dog 和 lion 等字词都代表动物类型,由于它们具有共享的语义特征,因此会在此空间中紧密分组。同样,car、truck 和更通用的字词vehicle 也会形成另一个集群。具体可见以下图片:
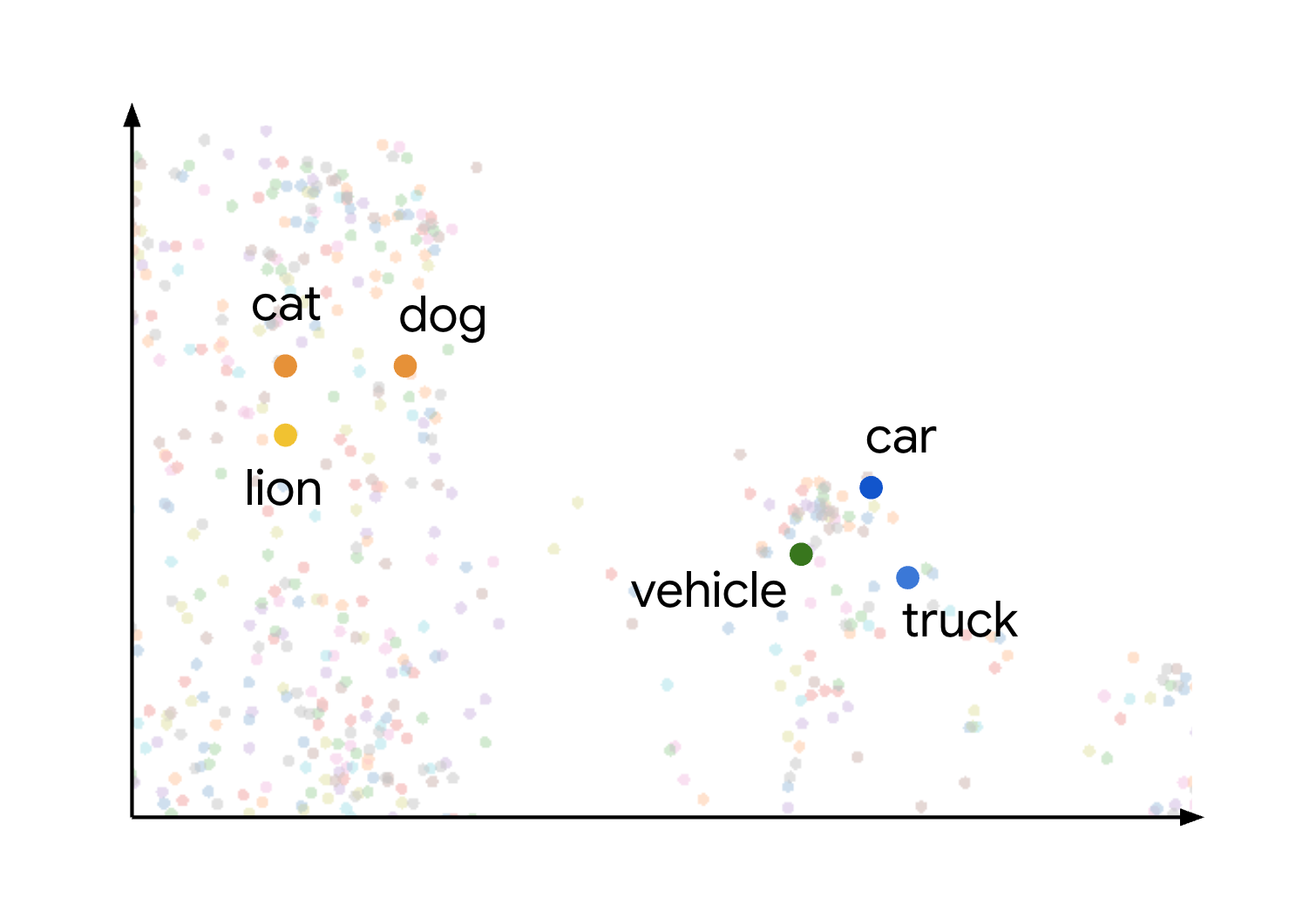
您可以看到,动物和车辆集群彼此相距甚远。各组之间的分隔说明了这样一个原则:在嵌入空间中,对象越靠近,语义就越相似;距离越大,语义就越不相似。
BigQuery 提供端到端体验,用于生成嵌入、编制索引内容和执行向量搜索。您可以单独完成每项任务,也可以在单次历程中完成。如需查看有关如何完成所有这些任务的教程,请参阅执行语义搜索和检索增强生成。
如需使用 SQL 执行矢量搜索,您可以使用 VECTOR_SEARCH 函数。您可以选择使用 CREATE VECTOR INDEX 语句创建矢量索引。当使用矢量索引时,VECTOR_SEARCH 会使用近似最近邻搜索技术来提高矢量搜索性能,虽然降低召回率,但可返回更接近的结果。如果没有向量索引,VECTOR_SEARCH 会使用暴力搜索来衡量每个记录的距离。即使在矢量索引可用时,您也可以选择使用暴力破解来获得精确的结果。
本文档主要介绍 SQL 方法,但您也可以在 Python 中使用 BigQuery DataFrames 执行矢量搜索。如需查看演示 Python 方法的笔记本,请参阅使用 BigQuery DataFrames 构建矢量搜索应用。
使用场景
通过结合使用嵌入生成和向量搜索,可以实现许多有趣的用例。一些可能的用例如下:
- 检索增强生成 (RAG):在 BigQuery 中解析文档、对内容执行向量搜索,并使用 Gemini 模型生成对自然语言问题的摘要答案。如需查看说明此场景的笔记本,请参阅使用 BigQuery DataFrames 构建矢量搜索应用。
- 推荐替代商品或匹配商品:根据客户行为和商品相似性建议替代商品,从而提升电子商务应用的效果。
- 日志分析:帮助团队主动对日志中的异常进行分类,并加快调查进度。您还可以使用此功能来丰富 LLM 的上下文,以改进威胁检测、取证和问题排查工作流。如需查看演示此场景的笔记本,请参阅使用文本嵌入 + BigQuery Vector Search 对日志进行异常检测和调查。
- 聚类和定位:精确细分受众群。例如,连锁医院可以使用自然语言备注和结构化数据对患者进行分组,营销人员可以根据查询意图定位广告。如需查看说明此场景的笔记本,请参阅 Create-Campaign-Customer-Segmentation。
- 实体解析和去重:清理和整合数据。例如,广告公司可以对个人身份信息 (PII) 记录进行去重,房地产公司可以识别匹配的邮寄地址。
价格
VECTOR_SEARCH 函数和 CREATE VECTOR INDEX 语句使用 BigQuery 计算价格。
VECTOR_SEARCH函数:您需要使用按需价格或版本价格支付相似度搜索费用。- 按需:您需要为在基本表、索引和搜索查询中扫描的字节数付费。
版本价格:您需要为在预留版本中完成作业所需的槽付费。规模更大、更复杂的相似度计算会产生更多费用。
CREATE VECTOR INDEX声明:只要编入索引的表数据的总大小低于每个组织的限制,构建和刷新矢量索引所需的处理就无需付费。为支持超出此限制的索引,您必须提供自己的预留来处理索引管理作业。
存储空间也是嵌入和索引需要考虑的因素。以嵌入和索引形式存储的字节数会产生活跃存储费用。
- 矢量索引在处于活跃状态时会产生存储费用。
- 您可以使用
INFORMATION_SCHEMA.VECTOR_INDEXES视图查找索引存储空间大小。如果矢量索引尚未达到 100% 覆盖率,您仍需要为已编入索引的所有内容付费。您可以使用INFORMATION_SCHEMA.VECTOR_INDEXES视图检查索引涵盖范围。
配额和限制
如需了解详情,请参阅矢量索引限制。
限制
BigQuery BI Engine 无法加速包含 VECTOR_SEARCH 函数的查询。
后续步骤
- 详细了解如何创建矢量索引。
- 了解如何使用
VECTOR_SEARCH函数执行向量搜索。 - 完成使用向量搜索来搜索嵌入教程,了解如何创建向量索引,然后分别使用和不使用索引来执行嵌入的向量搜索。
完成执行语义搜索和检索增强生成教程,了解如何执行以下任务:
- 生成文本嵌入。
- 在嵌入上创建向量索引。
- 使用嵌入执行向量搜索,以搜索类似文本。
- 使用向量搜索结果执行检索增强生成 (RAG),以增强提示输入并改善结果。
请尝试在检索增强生成流水线中解析 PDF 教程,了解如何根据解析的 PDF 内容创建 RAG 流水线。