Restez organisé à l'aide des collections
Enregistrez et classez les contenus selon vos préférences.
Présentation de la recherche vectorielle
Ce document présente la recherche vectorielle dans BigQuery. La recherche vectorielle est une technique permettant de comparer des objets similaires à l'aide d'embeddings. Elle est utilisée pour alimenter les produits Google, y compris la recherche Google, YouTube et Google Play. Vous pouvez utiliser la recherche vectorielle pour effectuer des recherches à grande échelle. Lorsque vous utilisez des index de vecteurs avec la recherche vectorielle, vous pouvez profiter de technologies fondamentales telles que l'indexation de fichiers inversés (IVF) et l'algorithme ScaNN.
La recherche vectorielle repose sur les embeddings. Les embeddings sont des vecteurs numériques de grande dimension qui représentent une entité donnée, comme un exemple de texte ou un fichier audio.
Les modèles de machine learning (ML) utilisent des embeddings pour encoder la sémantique concernant ces entités afin de faciliter leur raisonnement et leur comparaison. Par exemple, une opération courante dans les modèles de clustering, de classification et de recommandation consiste à mesurer la distance entre les vecteurs dans un espace de représentation vectorielle afin de trouver les éléments les plus sémantiquement similaires.
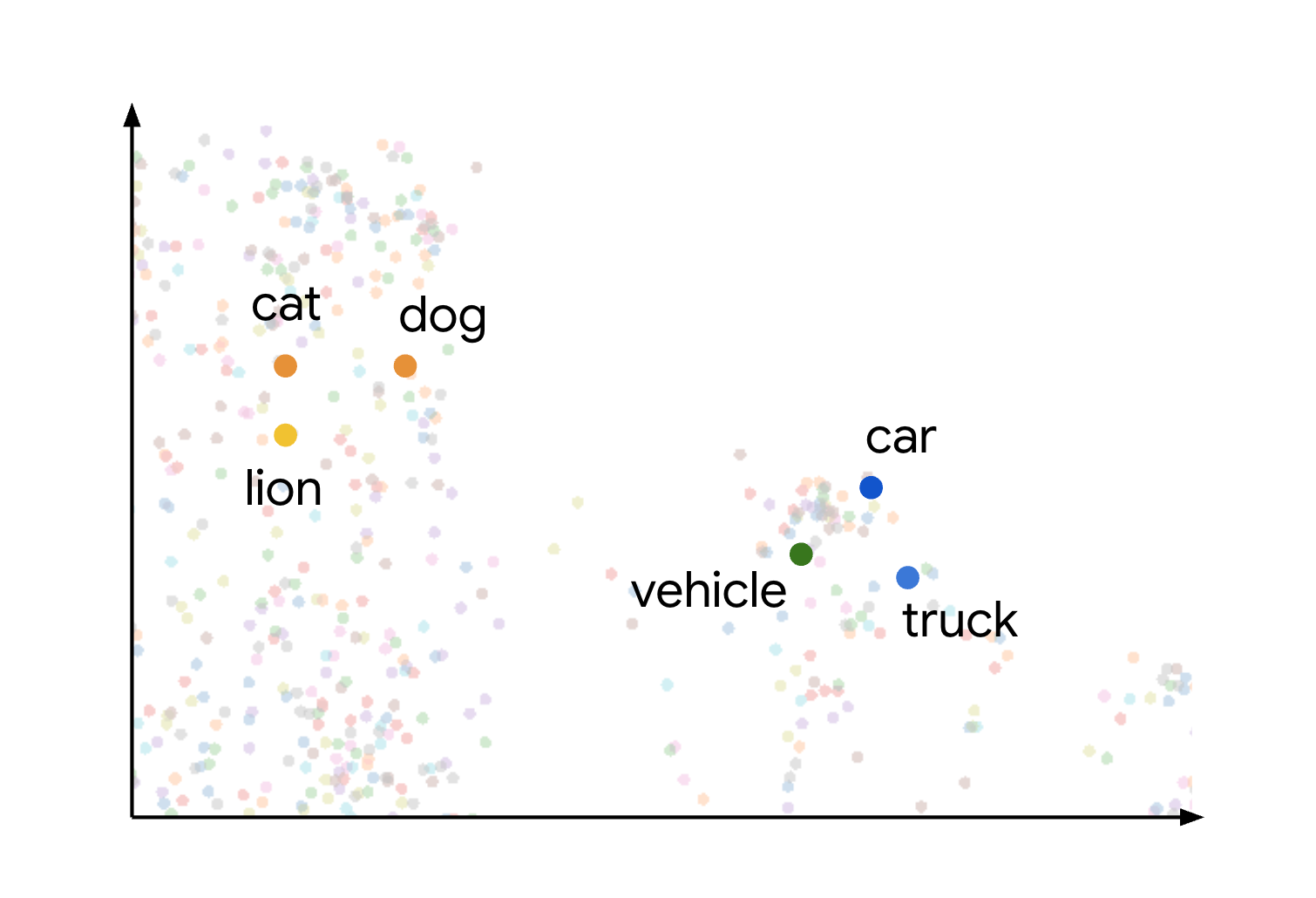
Ce concept de similarité et de distance sémantiques dans un espace de représentation vectorielle est illustré visuellement lorsque vous réfléchissez à la façon dont différents éléments peuvent être représentés.
Par exemple, les termes chat, chien et lion, qui représentent tous des types d'animaux, sont regroupés dans cet espace en raison de leurs caractéristiques sémantiques communes. De même, les termes voiture, camion et le terme plus générique véhicule formeraient un autre cluster. Ce processus est illustré dans l'image suivante :
Vous pouvez constater que les clusters d'animaux et de véhicules sont très éloignés les uns des autres. La séparation entre les groupes illustre le principe selon lequel plus les objets sont proches dans l'espace de représentation vectorielle, plus ils sont sémantiquement similaires. Plus les distances sont grandes, plus la dissimilarité sémantique est importante.
BigQuery offre une expérience de bout en bout pour générer des embeddings, indexer du contenu et effectuer des recherches vectorielles. Vous pouvez effectuer chacune de ces tâches de manière indépendante ou dans un seul parcours. Pour suivre un tutoriel qui vous explique comment effectuer toutes ces tâches, consultez Effectuer une recherche sémantique et une génération augmentée de récupération.
Pour effectuer une recherche vectorielle à l'aide de SQL, vous utilisez la fonction VECTOR_SEARCH.
Vous pouvez éventuellement créer un index vectoriel à l'aide de l'instruction CREATE VECTOR INDEX.
Lorsqu'un index vectoriel est utilisé, VECTOR_SEARCH utilise la technique de recherche approximative du voisin le plus proche pour améliorer les performances de la recherche vectorielle, avec le compromis consistant à réduire le rappel et ainsi renvoyer des résultats plus approximatifs. Sans index vectoriel, VECTOR_SEARCH utilise la recherche par force brute pour mesurer la distance de chaque enregistrement. Vous pouvez également choisir d'utiliser la force brute pour obtenir des résultats exacts, même lorsqu'un index vectoriel est disponible.
La combinaison de la génération d'embeddings et de la recherche vectorielle permet de nombreux cas d'utilisation intéressants. Voici quelques cas d'utilisation possibles :
Recommander des produits de substitution ou des produits correspondants : améliorez les applications d'e-commerce en suggérant des produits alternatifs en fonction du comportement des clients et de la similarité des produits.
Analyse des journaux : aidez les équipes à trier de manière proactive les anomalies dans les journaux et à accélérer les investigations. Vous pouvez également utiliser cette fonctionnalité pour enrichir le contexte des LLM afin d'améliorer les workflows de détection des menaces, d'analyse forensique et de dépannage. Pour obtenir un notebook illustrant ce scénario, consultez Détection et investigation des anomalies de journaux avec les embeddings de texte et BigQuery Vector Search.
Clustering et ciblage : segmentez les audiences avec précision. Par exemple, une chaîne d'hôpitaux peut regrouper des patients à l'aide de notes en langage naturel et de données structurées, ou un responsable marketing peut cibler des annonces en fonction de l'intention de la requête.
Pour obtenir un notebook illustrant ce scénario, consultez Create-Campaign-Customer-Segmentation.
Résolution d'entités et déduplication : nettoyez et consolidez les données.
Par exemple, une entreprise publicitaire peut dédupliquer des enregistrements d'informations permettant d'identifier personnellement l'utilisateur (IPI), ou une entreprise immobilière peut identifier les adresses postales correspondantes.
Fonction VECTOR_SEARCH : la recherche par similarité vous est facturée selon la tarification à la demande ou par édition.
À la demande : vous êtes facturé en fonction du nombre d'octets analysés dans la table de base, l'index et la requête de recherche.
Tarification des éditions : les emplacements requis pour exécuter le job dans votre édition de réservation vous sont facturés. Les calculs de similarité plus volumineux et plus complexes entraînent des frais plus élevés.
Déclaration CREATE VECTOR INDEX : le traitement requis pour créer et actualiser vos index vectoriels est sans frais tant que la taille totale des données de table indexées est inférieure à votre limite par organisation. Pour accepter l'indexation au-delà de cette limite, vous devez fournir votre propre réservation pour la gestion des jobs de gestion des index.
Le stockage est également un facteur à prendre en compte pour les embeddings et les index. La quantité d'octets stockés sous forme d'intégrations et d'index est soumise aux coûts de stockage actif.
Les index vectoriels entraînent des coûts de stockage lorsqu'ils sont actifs.
Vous pouvez trouver la taille de stockage de l'index à l'aide de la vue INFORMATION_SCHEMA.VECTOR_INDEXES.
Si l'index vectoriel n'est pas encore à 100 % de la couverture, vous êtes toujours facturé pour ce qui a été indexé. Vous pouvez vérifier la couverture de l'index à l'aide de la vue INFORMATION_SCHEMA.VECTOR_INDEXES.
Effectuer une recherche vectorielle avec les embeddings pour rechercher du texte similaire.
Effectuer une génération augmentée de récupération (RAG) en utilisant les résultats de la recherche vectorielle pour augmenter la saisie de la requête et améliorer les résultats.
Sauf indication contraire, le contenu de cette page est régi par une licence Creative Commons Attribution 4.0, et les échantillons de code sont régis par une licence Apache 2.0. Pour en savoir plus, consultez les Règles du site Google Developers. Java est une marque déposée d'Oracle et/ou de ses sociétés affiliées.
Dernière mise à jour le 2025/09/04 (UTC).
[[["Facile à comprendre","easyToUnderstand","thumb-up"],["J'ai pu résoudre mon problème","solvedMyProblem","thumb-up"],["Autre","otherUp","thumb-up"]],[["Difficile à comprendre","hardToUnderstand","thumb-down"],["Informations ou exemple de code incorrects","incorrectInformationOrSampleCode","thumb-down"],["Il n'y a pas l'information/les exemples dont j'ai besoin","missingTheInformationSamplesINeed","thumb-down"],["Problème de traduction","translationIssue","thumb-down"],["Autre","otherDown","thumb-down"]],["Dernière mise à jour le 2025/09/04 (UTC)."],[[["\u003cp\u003eVector search in BigQuery allows searching embeddings to identify semantically similar entities, using high-dimensional numerical vectors that represent data like text or audio.\u003c/p\u003e\n"],["\u003cp\u003eThe \u003ccode\u003eVECTOR_SEARCH\u003c/code\u003e function, optionally enhanced by a vector index, enables this search, with the index improving performance through Approximate Nearest Neighbor search, and brute force offering an alternative to get exact results.\u003c/p\u003e\n"],["\u003cp\u003eEmbedding generation combined with vector search powers use cases like retrieval-augmented generation (RAG), resolving similar support cases, patient profile matching, and analyzing sensor data.\u003c/p\u003e\n"],["\u003cp\u003ePricing for \u003ccode\u003eCREATE VECTOR INDEX\u003c/code\u003e and \u003ccode\u003eVECTOR_SEARCH\u003c/code\u003e falls under BigQuery compute pricing, with free indexing up to a per-organization limit, after which users need to use their own reservations to index.\u003c/p\u003e\n"],["\u003cp\u003e\u003ccode\u003eVECTOR_SEARCH\u003c/code\u003e queries aren't supported by BigQuery BI Engine, and BigQuery's data security and governance rules apply to its use.\u003c/p\u003e\n"]]],[],null,["# Introduction to vector search\n=============================\n\nThis document provides an overview of\n[vector search](/bigquery/docs/vector-search) in BigQuery. Vector\nsearch is a technique to compare similar objects using embeddings, and it\nis used to power Google products, including Google Search,\nYouTube, and Google Play. You can use vector search to perform\nsearches at scale. When you use [vector indexes](/bigquery/docs/vector-index)\nwith vector search, you can take advantage of foundational technologies like\ninverted file indexing (IVF) and the\n[ScaNN algorithm](https://research.google/blog/announcing-scann-efficient-vector-similarity-search/).\n\nVector search is built on embeddings. Embeddings are high-dimensional numerical\nvectors that represent a given entity, like a piece of text or an audio file.\nMachine learning (ML) models use embeddings to encode semantics about such\nentities to make it easier to reason about and compare them. For example, a\ncommon operation in clustering, classification, and recommendation models is to\nmeasure the distance between vectors in an\n[embedding space](https://en.wikipedia.org/wiki/Latent_space) to find items\nthat are most semantically similar.\n\nThis concept of semantic similarity and distance in an embedding space is\nvisually demonstrated when you consider how different items might be plotted.\nFor example, terms like *cat* , *dog* , and *lion* , which all represent types of\nanimals, are grouped close together in this space due to their shared semantic\ncharacteristics. Similarly, terms like *car* , *truck* , and the more generic term\n*vehicle* would form another cluster. This is shown in the following image:\n\nYou can see that the animal and vehicle clusters are positioned far apart\nfrom each other. The separation between the groups illustrates the principle\nthat the closer objects are in the embedding space, the more semantically\nsimilar they are, and greater distances indicate greater semantic dissimilarity.\n\nBigQuery provides an end-to-end experience for generating\nembeddings, indexing content, and performing vector searches. You can complete\neach of these tasks independently, or in a single journey. For a tutorial\nthat shows how to complete all of these tasks, see\n[Perform semantic search and retrieval-augmented generation](/bigquery/docs/vector-index-text-search-tutorial).\n\nTo perform a vector search by using SQL, you use the\n[`VECTOR_SEARCH` function](/bigquery/docs/reference/standard-sql/search_functions#vector_search).\nYou can optionally create a [vector index](/bigquery/docs/vector-index) by\nusing the\n[`CREATE VECTOR INDEX` statement](/bigquery/docs/reference/standard-sql/data-definition-language#create_vector_index_statement).\nWhen a vector index is used, `VECTOR_SEARCH` uses the\n[Approximate Nearest Neighbor](https://en.wikipedia.org/wiki/Nearest_neighbor_search#Approximation_methods)\nsearch technique to improve vector search performance, with the\ntrade-off of reducing\n[recall](https://developers.google.com/machine-learning/crash-course/classification/precision-and-recall#recallsearch_term_rules)\nand so returning more approximate results. Without a vector index,\n`VECTOR_SEARCH` uses\n[brute force search](https://en.wikipedia.org/wiki/Brute-force_search)\nto measure distance for every record. You can also choose to use brute\nforce to get exact results even when a vector index is available.\n\nThis document focuses on the SQL approach, but you can also perform\nvector searches by using BigQuery DataFrames in Python. For a notebook\nthat illustrates the Python approach, see\n[Build a Vector Search application using BigQuery DataFrames](https://github.com/googleapis/python-bigquery-dataframes/blob/main/notebooks/generative_ai/bq_dataframes_llm_vector_search.ipynb).\n\nUse cases\n---------\n\nThe combination of embedding generation and vector search enables many\ninteresting use cases. Some possible use cases are as follows:\n\n- **[Retrieval-augmented generation (RAG)](/use-cases/retrieval-augmented-generation):** Parse documents, perform vector search on content, and generate summarized answers to natural language questions using Gemini models, all within BigQuery. For a notebook that illustrates this scenario, see [Build a Vector Search application using BigQuery DataFrames](https://github.com/googleapis/python-bigquery-dataframes/blob/main/notebooks/generative_ai/bq_dataframes_llm_vector_search.ipynb).\n- **Recommending product substitutes or matching products:** Enhance ecommerce applications by suggesting product alternatives based on customer behavior and product similarity.\n- **Log analytics:** Help teams proactively triage anomalies in logs and accelerate investigations. You can also use this capability to enrich context for LLMs, in order to improve threat detection, forensics, and troubleshooting workflows. For a notebook that illustrates this scenario, see [Log Anomaly Detection \\& Investigation with Text Embeddings + BigQuery Vector Search](https://github.com/GoogleCloudPlatform/generative-ai/blob/main/embeddings/use-cases/outlier-detection/bq-vector-search-outlier-detection-audit-logs.ipynb).\n- **Clustering and targeting:** Segment audiences with precision. For example, a hospital chain could cluster patients using natural language notes and structured data, or a marketer could target ads based on query intent. For a notebook that illustrates this scenario, see [Create-Campaign-Customer-Segmentation](https://github.com/GoogleCloudPlatform/chocolate-ai/blob/main/colab-enterprise/Create-Campaign-Customer-Segmentation.ipynb).\n- **Entity resolution and deduplication:** Cleanse and consolidate data. For example, an advertising company could deduplicate personally identifiable information (PII) records, or a real estate company could identify matching mailing addresses.\n\nPricing\n-------\n\nThe `VECTOR_SEARCH` function and the `CREATE VECTOR INDEX` statement use\n[BigQuery compute pricing](/bigquery/pricing#analysis_pricing_models).\n\n- `VECTOR_SEARCH` function: You are charged for similarity search, using\n on-demand or editions pricing.\n\n - On-demand: You are charged for the amount of bytes scanned in the base table, the index, and the search query.\n - Editions pricing: You are charged for the slots required to complete\n the job within your reservation edition. Larger, more complex\n similarity calculations incur more charges.\n\n | **Note:** Using an index isn't supported in [Standard editions](/bigquery/docs/editions-intro).\n- `CREATE VECTOR INDEX` statement: There is no charge for the processing\n required to build and refresh your vector indexes as long as the total\n size of the indexed table data is below your per-organization\n [limit](/bigquery/quotas#vector_index_maximum_table_size). To\n support indexing beyond this limit, you must\n [provide your own reservation](/bigquery/docs/vector-index#use_your_own_reservation)\n for handling the index management jobs.\n\nStorage is also a consideration for embeddings and indexes. The amount of bytes\nstored as embeddings and indexes are subject to\n[active storage costs](/bigquery/pricing#storage).\n\n- Vector indexes incur storage costs when they are active.\n- You can find the index storage size by using the [`INFORMATION_SCHEMA.VECTOR_INDEXES` view](/bigquery/docs/information-schema-vector-indexes). If the vector index is not yet at 100% coverage, you are still charged for whatever has been indexed. You can check index coverage by using the `INFORMATION_SCHEMA.VECTOR_INDEXES` view.\n\nQuotas and limits\n-----------------\n\nFor more information, see\n[Vector index limits](/bigquery/quotas#vector_index_limits).\n\nLimitations\n-----------\n\nQueries that contain the `VECTOR_SEARCH` function aren't accelerated by\n[BigQuery BI Engine](/bigquery/docs/bi-engine-intro).\n\nWhat's next\n-----------\n\n- Learn more about [creating a vector index](/bigquery/docs/vector-index).\n- Learn how to perform a vector search using the [`VECTOR_SEARCH`\n function](/bigquery/docs/reference/standard-sql/search_functions#vector_search).\n- Try the [Search embeddings with vector search](/bigquery/docs/vector-search) tutorial to learn how to create a vector index, and then do a vector search for embeddings both with and without the index.\n- Try the [Perform semantic search and retrieval-augmented generation](/bigquery/docs/vector-index-text-search-tutorial)\n tutorial to learn how to do the following tasks:\n\n - Generate text embeddings.\n - Create a vector index on the embeddings.\n - Perform a vector search with the embeddings to search for similar text.\n - Perform retrieval-augmented generation (RAG) by using vector search results to augment the prompt input and improve results.\n- Try the [Parse PDFs in a retrieval-augmented generation pipeline](/bigquery/docs/rag-pipeline-pdf)\n tutorial to learn how to create a RAG pipeline based on parsed PDF content."]]