Ejecutar código de PySpark en cuadernos de BigQuery Studio
En este documento se explica cómo ejecutar código de PySpark en un cuaderno de Python de BigQuery.
Antes de empezar
Si aún no lo has hecho, crea un Google Cloud proyecto y un contenedor de Cloud Storage.
Configurar un proyecto
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Crea un segmento de Cloud Storage en tu proyecto si no tienes ninguno que puedas usar.
Configurar un cuaderno
- Credenciales del cuaderno: de forma predeterminada, tu sesión del cuaderno usa tus credenciales de usuario. También puede usar las credenciales de la cuenta de servicio de sesión.
- Credenciales de usuario: tu cuenta de usuario debe tener los siguientes roles de gestión de identidades y accesos:
- Editor de Dataproc (rol
roles/dataproc.editor) - Usuario de BigQuery Studio (rol
roles/bigquery.studioUser) - Rol Usuario de cuenta de servicio (roles/iam.serviceAccountUser)
en la cuenta de servicio de sesión.
Este rol contiene el permiso
iam.serviceAccounts.actAsnecesario para suplantar la identidad de la cuenta de servicio.
- Editor de Dataproc (rol
- Credenciales de cuenta de servicio: si quieres especificar las credenciales de una cuenta de servicio en lugar de las de un usuario para tu sesión de cuaderno, la cuenta de servicio de la sesión debe tener el siguiente rol:
- Credenciales de usuario: tu cuenta de usuario debe tener los siguientes roles de gestión de identidades y accesos:
- Tiempo de ejecución del cuaderno: el cuaderno usa un tiempo de ejecución predeterminado de Vertex AI, a menos que selecciones otro. Si quieres definir tu propio tiempo de ejecución, créalo en la página Tiempos de ejecución de la consola Google Cloud . Nota: Cuando uses la biblioteca NumPy, usa la versión 1.26 de NumPy, que es compatible con Spark 3.5, en el tiempo de ejecución del cuaderno.
- Credenciales del cuaderno: de forma predeterminada, tu sesión del cuaderno usa tus credenciales de usuario. También puede usar las credenciales de la cuenta de servicio de sesión.
En la Google Cloud consola, ve a la página BigQuery.
En la barra de pestañas del panel de detalles, haz clic en la flecha + y, a continuación, en Cuaderno.
- Configurar y crear una sola sesión en el cuaderno.
- Configura una sesión de Spark en una plantilla de sesión interactiva y, a continuación, usa la plantilla para configurar y crear una sesión en el cuaderno.
BigQuery ofrece una función
Query using Sparkque te ayuda a empezar a codificar la sesión basada en plantillas, tal como se explica en la pestaña Sesión de Spark basada en plantillas. En la barra de pestañas del panel del editor, haz clic en el menú desplegable + y, a continuación, en Notebook.
Copia y ejecuta el siguiente código en una celda de un cuaderno para configurar y crear una sesión básica de Spark.
- APP_NAME: nombre opcional de la sesión.
- Configuración de sesión opcional: puede añadir ajustes de la API Dataproc
Sessionpara personalizar su sesión. Estos son algunos ejemplos:RuntimeConfig: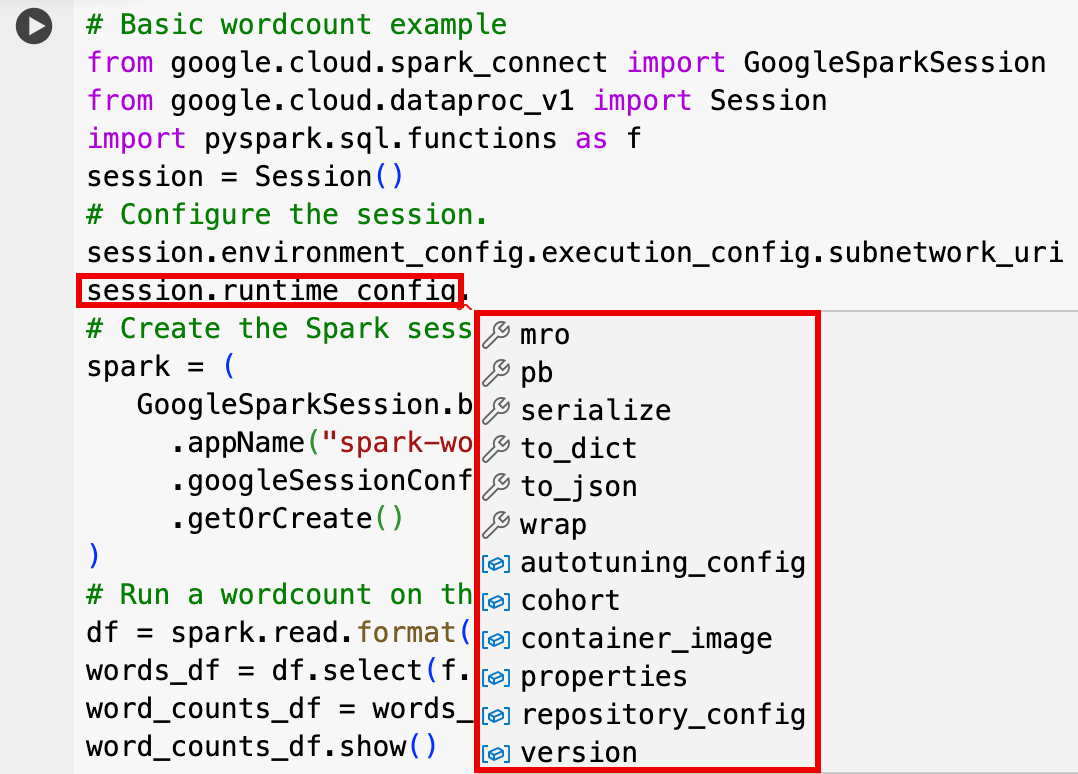
session.runtime_config.properties={spark.property.key1:VALUE_1,...,spark.property.keyN:VALUE_N}session.runtime_config.container_image = path/to/container/image
EnvironmentConfig: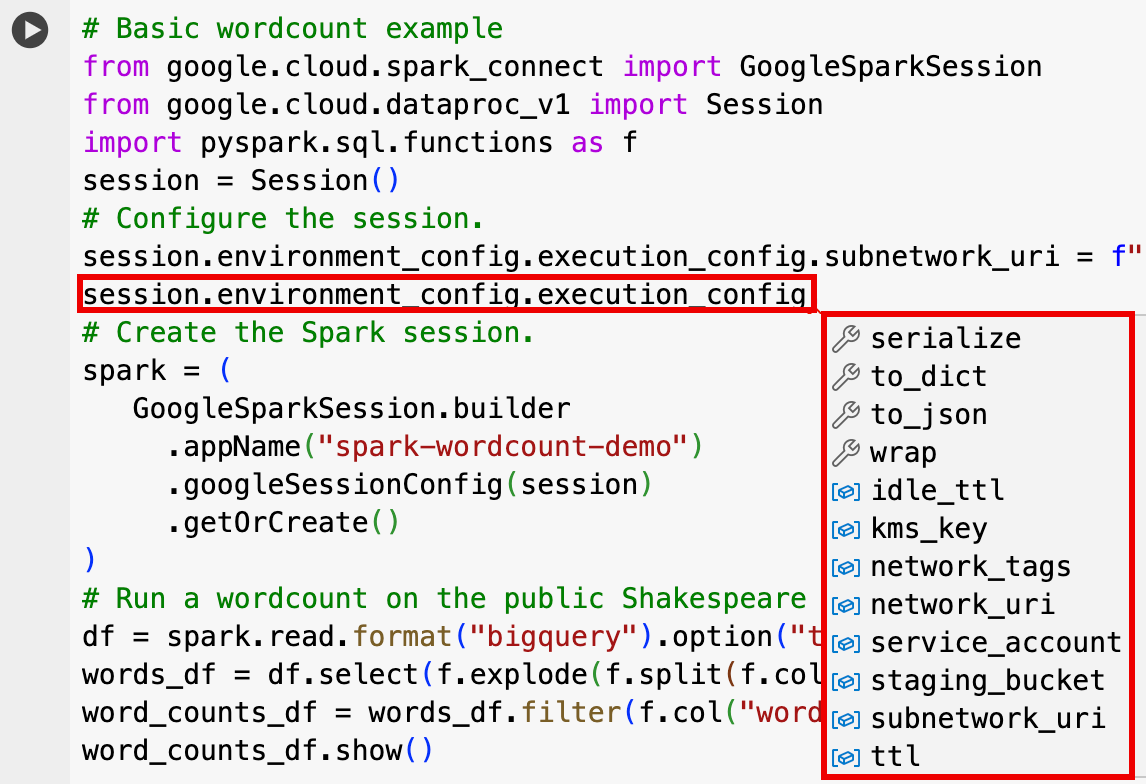
- session.environment_config.execution_config.subnetwork_uri = "SUBNET_NAME"
session.environment_config.execution_config.ttl = {"seconds": VALUE}session.environment_config.execution_config.service_account = SERVICE_ACCOUNT
- En la barra de pestañas del panel del editor, haz clic en el menú desplegable
+ y, a continuación, en Notebook.
- En Empezar con una plantilla, haz clic en Consulta con Spark y, a continuación, en Usar plantilla para insertar el código en tu cuaderno.
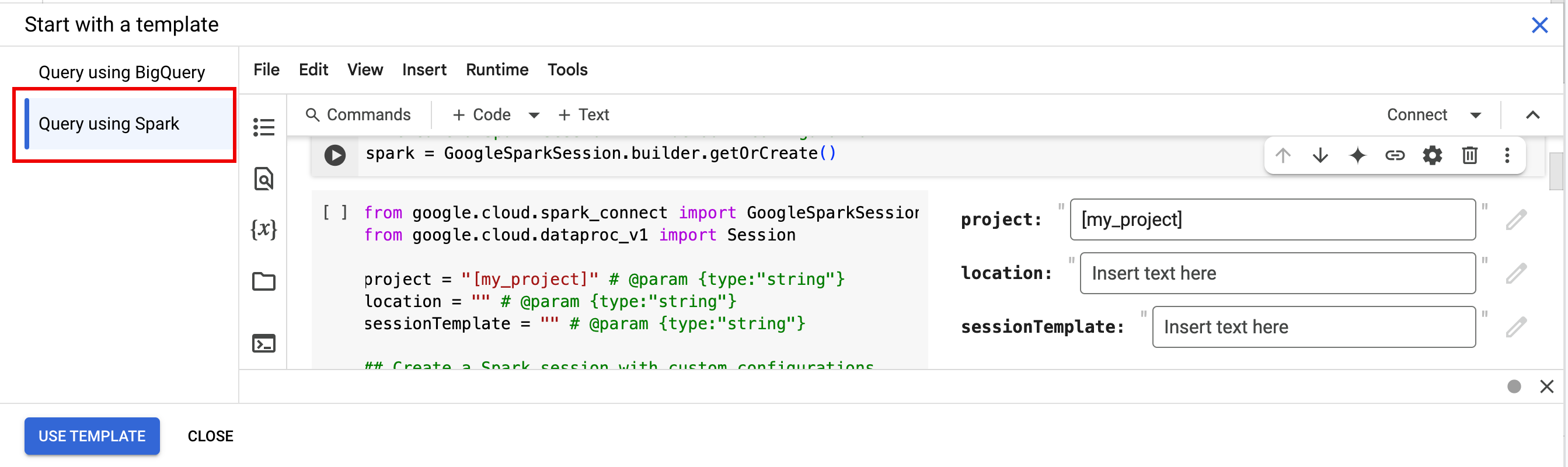
- Especifique las variables tal como se explica en las notas.
- Puedes eliminar las celdas de código de ejemplo adicionales que se hayan insertado en el cuaderno.
- PROJECT: tu ID de proyecto, que se indica en la sección Información del proyecto del Google Cloud panel de control de la consola.
- LOCATION: la región de Compute Engine en la que se ejecutará tu sesión del cuaderno. Si no se proporciona, la ubicación predeterminada es la región de la VM que crea el cuaderno.
SESSION_TEMPLATE: el nombre de una plantilla de sesión interactiva. Los ajustes de configuración de la sesión se obtienen de la plantilla. La plantilla también debe especificar los siguientes ajustes:
- Versión del tiempo de ejecución:
2.3+ Tipo de cuaderno:
Spark ConnectEjemplo:

- Versión del tiempo de ejecución:
APP_NAME: nombre opcional de la sesión.
- Ejecuta un recuento de palabras en un conjunto de datos público de Shakespeare.
- Crea una tabla de Iceberg con los metadatos guardados en el metastore de BigLake.
- APP_NAME: nombre opcional de la sesión.
- PROJECT: tu ID de proyecto, que se indica en la sección Información del proyecto del Google Cloud panel de control de la consola.
- REGION y SUBNET_NAME: especifica la región de Compute Engine y el nombre de una subred de la región de la sesión. Serverless para Apache Spark habilita Acceso privado de Google (PGA) en la subred especificada.
- LOCATION: el valor predeterminado
BigQuery_metastore_config.locationyspark.sql.catalog.{catalog}.gcp_locationesUS, pero puede elegir cualquier ubicación de BigQuery admitida. - BUCKET y WAREHOUSE_DIRECTORY: el segmento y la carpeta de Cloud Storage que se usan para el directorio del almacén de Iceberg.
- CATALOG_NAME y NAMESPACE: el nombre del catálogo de Iceberg y el espacio de nombres se combinan para identificar la tabla de Iceberg (
catalog.namespace.table_name). - APP_NAME: nombre opcional de la sesión.
En la Google Cloud consola, ve a la página BigQuery.
En el panel de recursos del proyecto, haz clic en tu proyecto y, a continuación, en tu espacio de nombres para ver la tabla
sample_iceberg_table. Haz clic en la tabla Detalles para ver la información de Abrir configuración de tabla de catálogo.Los formatos de entrada y salida son los formatos de clase estándar de Hadoop
InputFormatyOutputFormatque usa Iceberg.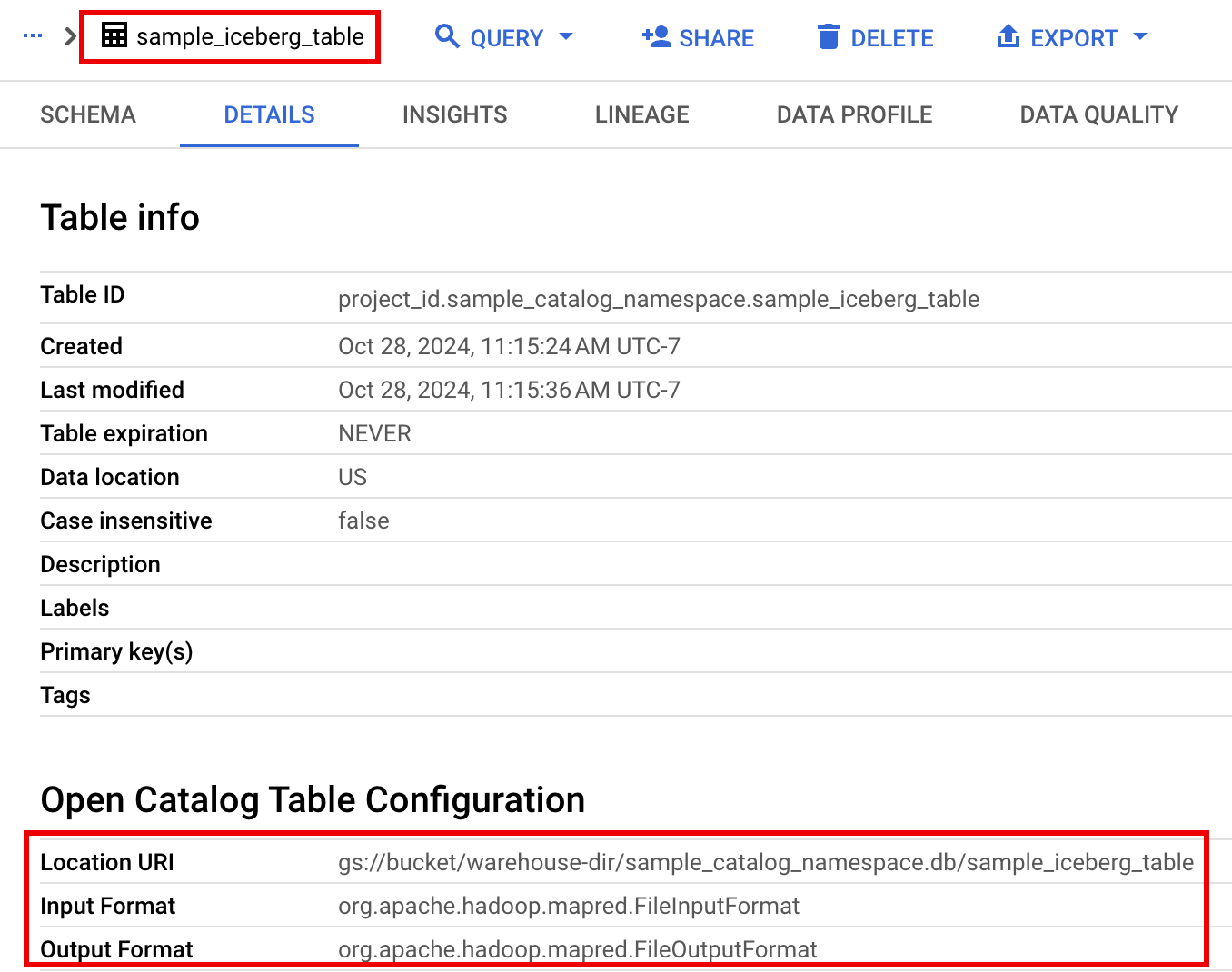
Inserta una celda de código haciendo clic en + Código en la barra de herramientas. La nueva celda de código muestra
Start coding or generate with AI. Haz clic en Generar.En el editor Generar, escribe una petición en lenguaje natural y haz clic en
enter. No olvides incluir la palabra clavesparkopysparken tu petición.Petición de ejemplo:
create a spark dataframe from order_items and filter to orders created in 2024
Ejemplo de salida:
spark.read.format("bigquery").option("table", "sqlgen-testing.pysparkeval_ecommerce.order_items").load().filter("year(created_at) = 2024").createOrReplaceTempView("order_items") df = spark.sql("SELECT * FROM order_items")Para permitir que Gemini Code Assist obtenga las tablas y los esquemas pertinentes, activa la sincronización de Data Catalog en las instancias de Dataproc Metastore.
Asegúrate de que tu cuenta de usuario tenga acceso a Data Catalog las tablas de consulta. Para ello, asigna el rol
DataCatalog.Viewer.- Ejecuta
spark.stop()en una celda del cuaderno. - Finaliza el tiempo de ejecución en el cuaderno:
- Haz clic en el selector de tiempo de ejecución y, a continuación, en Gestionar sesiones.
- En el cuadro de diálogo Sesiones activas, haz clic en el icono de finalizar y, a continuación, en Finalizar.
- Haz clic en el selector de tiempo de ejecución y, a continuación, en Gestionar sesiones.
Programar código de cuaderno desde la Google Cloud consola (se aplican los precios de los cuadernos).
Ejecutar código de cuaderno como una carga de trabajo por lotes (se aplican los precios de Serverless para Apache Spark).
- Programa el cuaderno.
- Si la ejecución del código del cuaderno forma parte de un flujo de trabajo, programa el cuaderno como parte de una pipeline.
Descarga el código del cuaderno en un archivo de un terminal local o en Cloud Shell.
Abre el cuaderno en el panel Explorador de la página BigQuery Studio de la Google Cloud consola.
Descarga el código del cuaderno seleccionando Descargar en el menú Archivo y, a continuación, elige
Download .py.
Generar
requirements.txt.- Instala
pipreqsen el directorio en el que hayas guardado el archivo.py.pip install pipreqs
Ejecuta
pipreqspara generarrequirements.txt.pipreqs filename.py
Usa la CLI de Google Cloud para copiar el archivo local
requirements.txten un segmento de Cloud Storage.gcloud storage cp requirements.txt gs://BUCKET/
- Instala
Actualiza el código de la sesión de Spark editando el archivo
.pydescargado.Elimina o comenta los comandos de la secuencia de comandos del shell.
Elimina el código que configura la sesión de Spark y, a continuación, especifica los parámetros de configuración como parámetros de envío de la carga de trabajo por lotes. Consulta Enviar una carga de trabajo por lotes de Spark.
Ejemplo:
Elimina la siguiente línea de configuración de la subred de la sesión del código:
session.environment_config.execution_config.subnetwork_uri = "{subnet_name}"Cuando ejecutes tu carga de trabajo por lotes, usa la marca
--subnetpara especificar la subred.gcloud dataproc batches submit pyspark \ --subnet=SUBNET_NAME
Usa un fragmento de código sencillo para crear sesiones.
Código de cuaderno de muestra descargado antes de simplificarlo.
from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session
session = Session() spark = DataprocSparkSession \ .builder \ .appName("CustomSparkSession") .dataprocSessionConfig(session) \ .getOrCreate()
Código de carga de trabajo de Batch después de la simplificación.
from pyspark.sql import SparkSession
spark = SparkSession \ .builder \ .getOrCreate()
Ejecuta la carga de trabajo por lotes.
Consulta las instrucciones en Enviar la carga de trabajo por lotes de Spark.
Asegúrate de incluir la marca --deps-bucket para que apunte al segmento de Cloud Storage que contiene el archivo
requirements.txt.Ejemplo:
gcloud dataproc batches submit pyspark FILENAME.py \ --region=REGION \ --deps-bucket=BUCKET \ --version=2.3
Notas:
- FILENAME: el nombre del archivo de código del cuaderno que has descargado y editado.
- REGION: la región de Compute Engine en la que se encuentra tu clúster.
- BUCKET El nombre del segmento de Cloud Storage
que contiene el archivo
requirements.txt. --version: se ha seleccionado la versión 2.3 del tiempo de ejecución de Spark para ejecutar la carga de trabajo por lotes.
Confirma tu código.
- Después de probar el código de la carga de trabajo por lotes, puedes confirmar el archivo
.ipynbo.pyen tu repositorio con tu clientegit, como GitHub, GitLab o Bitbucket, como parte de tu flujo de trabajo de CI/CD.
- Después de probar el código de la carga de trabajo por lotes, puedes confirmar el archivo
Programa tu carga de trabajo por lotes con Cloud Composer.
- Consulta las instrucciones en el artículo Ejecutar cargas de trabajo de Serverless para Apache Spark con Cloud Composer.
- Vídeo de demostración de YouTube: Aprovechar la potencia de Apache Spark integrado con BigQuery.
- Usar el metastore de BigLake con Dataproc
- Usar BigLake Metastore con Serverless para Apache Spark
Precios
Para obtener información sobre los precios, consulta los precios del tiempo de ejecución de los cuadernos de BigQuery.
Abrir un cuaderno de Python de BigQuery Studio
Crear una sesión de Spark en un cuaderno de BigQuery Studio
Puedes usar un cuaderno de Python de BigQuery Studio para crear una sesión interactiva de Spark Connect. Cada cuaderno de BigQuery Studio solo puede tener una sesión de Spark activa asociada.
Puedes crear una sesión de Spark en un cuaderno de Python de BigQuery Studio de las siguientes formas:
Sesión única
Para crear una sesión de Spark en un cuaderno nuevo, sigue estos pasos:
from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session import pyspark.sql.functions as f session = Session() # Create the Spark session. spark = ( DataprocSparkSession.builder .appName("APP_NAME") .dataprocSessionConfig(session) .getOrCreate() )Haz los cambios siguientes:
Sesión de Spark con plantilla
Puedes introducir y ejecutar el código en una celda de cuaderno para crear una sesión de Spark basada en una plantilla de sesión. Cualquier ajuste de configuración de
sessionque proporciones en el código de tu cuaderno anulará los mismos ajustes que se hayan definido en la plantilla de sesión.Para empezar rápidamente, usa la
Query using Sparkplantilla para rellenar previamente tu cuaderno con código de plantilla de sesión de Spark:from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session import pyspark.sql.functions as f session = Session() # Configure the session with an existing session template. session_template = "SESSION_TEMPLATE" session.session_template = f"projects/{project}/locations/{location}/sessionTemplates/{session_template}" # Create the Spark session. spark = ( DataprocSparkSession.builder .appName("APP_NAME") .dataprocSessionConfig(session) .getOrCreate() )Escribir y ejecutar código de PySpark en un cuaderno de BigQuery Studio
Después de crear una sesión de Spark en tu cuaderno, úsala para ejecutar código de cuaderno de Spark en el cuaderno.
Compatibilidad con la API PySpark de Spark Connect: tu sesión de cuaderno de Spark Connect es compatible con la mayoría de las APIs de PySpark, incluidas DataFrame, Functions y Column, pero no con SparkContext, RDD ni otras APIs de PySpark. Para obtener más información, consulta Qué se admite en Spark 3.5.
Escrituras directas en cuadernos de Spark Connect: las sesiones de Spark en un cuaderno de BigQuery Studio preconfiguran el conector de Spark BigQuery para hacer escrituras de datos DIRECTAS. El método de escritura DIRECT usa la API Storage Write de BigQuery, que escribe datos directamente en BigQuery. El método de escritura INDIRECT, que es el predeterminado para los lotes de Apache Spark sin servidor, escribe datos en un bucket de Cloud Storage intermedio y, a continuación, escribe los datos en BigQuery (para obtener más información sobre las escrituras INDIRECT, consulta Leer y escribir datos en BigQuery).
APIs específicas de Dataproc: Dataproc simplifica la adición dinámica de paquetes
PyPIa tu sesión de Spark ampliando el métodoaddArtifacts. Puedes especificar la lista en formatoversion-scheme(similar apip install). De esta forma, se indica al servidor de Spark Connect que instale los paquetes y sus dependencias en todos los nodos del clúster, lo que hará que estén disponibles para los trabajadores de tus FDU.Ejemplo que instala la versión de
textdistanceespecificada y las bibliotecas derandom2compatibles más recientes en el clúster para permitir que las funciones definidas por el usuario que utilizantextdistanceyrandom2se ejecuten en los nodos de trabajador.spark.addArtifacts("textdistance==4.6.1", "random2", pypi=True)Ayuda con el código de los cuadernos: el cuaderno de BigQuery Studio ofrece ayuda con el código cuando colocas el puntero sobre el nombre de una clase o un método, y proporciona ayuda para completar el código a medida que lo introduces.
En el siguiente ejemplo, se introduce
DataprocSparkSession. y, si mantienes el puntero sobre este nombre de clase, se mostrará la función de autocompletar código y la ayuda de la documentación.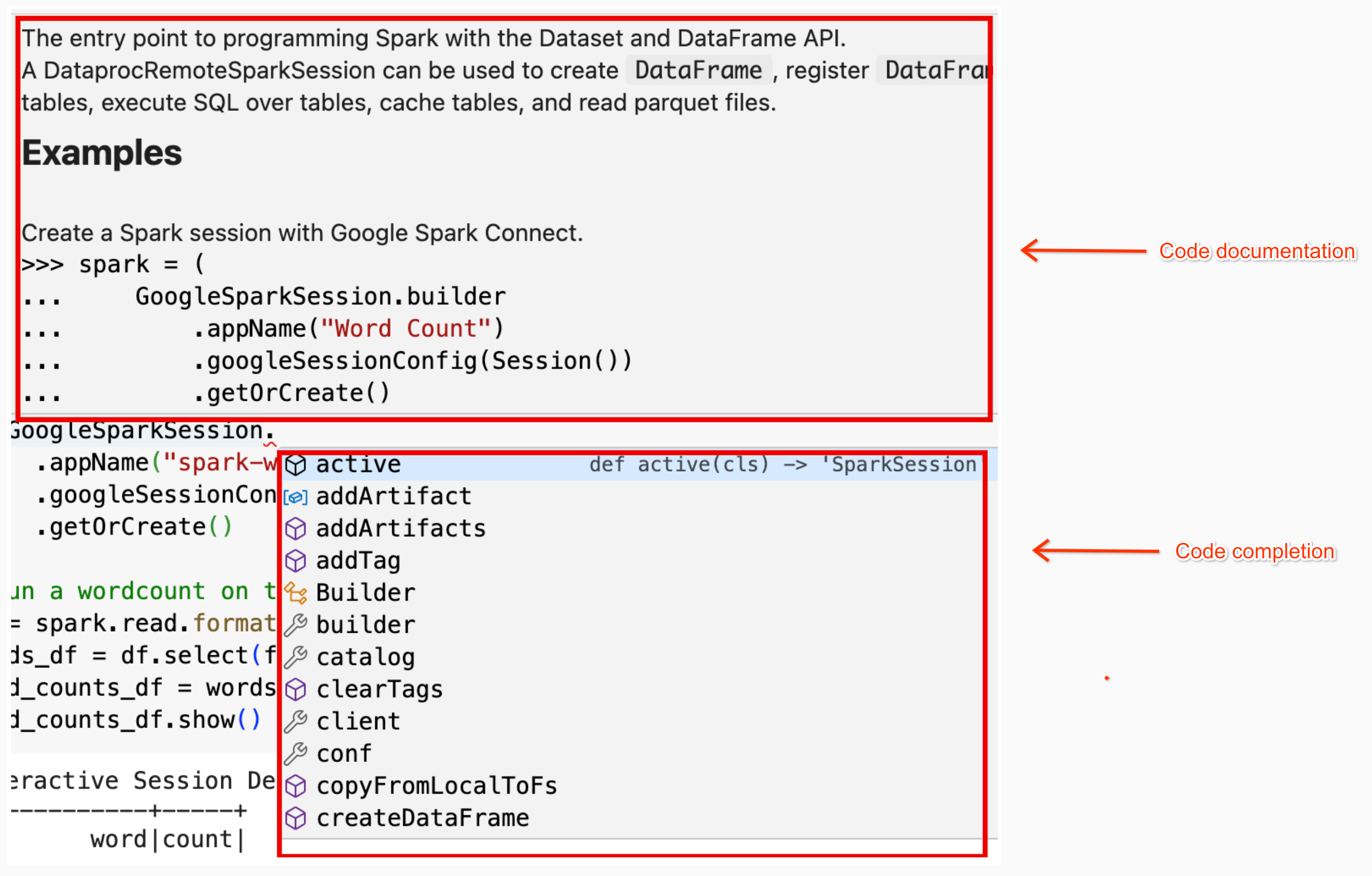
Ejemplos de PySpark en cuadernos de BigQuery Studio
En esta sección se proporcionan ejemplos de cuadernos de Python de BigQuery Studio con código de PySpark para realizar las siguientes tareas:
Recuento de palabras
En el siguiente ejemplo de Pyspark se crea una sesión de Spark y, a continuación, se cuentan las apariciones de palabras en un
bigquery-public-data.samples.shakespeareconjunto de datos público.# Basic wordcount example from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session import pyspark.sql.functions as f session = Session() # Create the Spark session. spark = ( DataprocSparkSession.builder .appName("APP_NAME") .dataprocSessionConfig(session) .getOrCreate() ) # Run a wordcount on the public Shakespeare dataset. df = spark.read.format("bigquery").option("table", "bigquery-public-data.samples.shakespeare").load() words_df = df.select(f.explode(f.split(f.col("word"), " ")).alias("word")) word_counts_df = words_df.filter(f.col("word") != "").groupBy("word").agg(f.count("*").alias("count")).orderBy("word") word_counts_df.show()Haz los cambios siguientes:
Salida:
En la salida de la celda se muestra un ejemplo de la salida del recuento de palabras. Para ver los detalles de la sesión en la consola Google Cloud , haz clic en el enlace Vista detallada de la sesión interactiva. Para monitorizar tu sesión de Spark, haz clic en Ver interfaz de usuario de Spark en la página de detalles de la sesión.

Interactive Session Detail View: LINK +------------+-----+ | word|count| +------------+-----+ | '| 42| | ''All| 1| | ''Among| 1| | ''And| 1| | ''But| 1| | ''Gamut'| 1| | ''How| 1| | ''Lo| 1| | ''Look| 1| | ''My| 1| | ''Now| 1| | ''O| 1| | ''Od's| 1| | ''The| 1| | ''Tis| 4| | ''When| 1| | ''tis| 1| | ''twas| 1| | 'A| 10| |'ARTEMIDORUS| 1| +------------+-----+ only showing top 20 rows
Mesa Iceberg
Ejecutar código de PySpark para crear una tabla de Iceberg con metadatos de BigLake Metastore
El siguiente código de ejemplo crea un
sample_iceberg_tablecon metadatos de tabla almacenados en BigLake Metastore y, a continuación, consulta la tabla.from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session import pyspark.sql.functions as f # Create the Dataproc Serverless session. session = Session() # Set the session configuration for BigLake Metastore with the Iceberg environment. project_id = "PROJECT" region = "REGION" subnet_name = "SUBNET_NAME" location = "LOCATION" session.environment_config.execution_config.subnetwork_uri = f"{subnet_name}" warehouse_dir = "gs://BUCKET/WAREHOUSE_DIRECTORY" catalog = "CATALOG_NAME" namespace = "NAMESPACE" session.runtime_config.properties[f"spark.sql.catalog.{catalog}"] = "org.apache.iceberg.spark.SparkCatalog" session.runtime_config.properties[f"spark.sql.catalog.{catalog}.catalog-impl"] = "org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog" session.runtime_config.properties[f"spark.sql.catalog.{catalog}.gcp_project"] = f"{project_id}" session.runtime_config.properties[f"spark.sql.catalog.{catalog}.gcp_location"] = f"{location}" session.runtime_config.properties[f"spark.sql.catalog.{catalog}.warehouse"] = f"{warehouse_dir}" # Create the Spark Connect session. spark = ( DataprocSparkSession.builder .appName("APP_NAME") .dataprocSessionConfig(session) .getOrCreate() ) # Create the namespace in BigQuery. spark.sql(f"USE `{catalog}`;") spark.sql(f"CREATE NAMESPACE IF NOT EXISTS `{namespace}`;") spark.sql(f"USE `{namespace}`;") # Create the Iceberg table. spark.sql("DROP TABLE IF EXISTS `sample_iceberg_table`"); spark.sql("CREATE TABLE sample_iceberg_table (id int, data string) USING ICEBERG;") spark.sql("DESCRIBE sample_iceberg_table;") # Insert table data and query the table. spark.sql("INSERT INTO sample_iceberg_table VALUES (1, \"first row\");") # Alter table, then query and display table data and schema. spark.sql("ALTER TABLE sample_iceberg_table ADD COLUMNS (newDoubleCol double);") spark.sql("DESCRIBE sample_iceberg_table;") df = spark.sql("SELECT * FROM sample_iceberg_table") df.show() df.printSchema()Notas:
En la salida de la celda se muestra el
sample_iceberg_tablecon la columna añadida y un enlace a la página Detalles de la sesión interactiva de la consola Google Cloud . Puedes hacer clic en Ver interfaz de usuario de Spark en la página de detalles de la sesión para monitorizar tu sesión de Spark.
Interactive Session Detail View: LINK +---+---------+------------+ | id| data|newDoubleCol| +---+---------+------------+ | 1|first row| NULL| +---+---------+------------+ root |-- id: integer (nullable = true) |-- data: string (nullable = true) |-- newDoubleCol: double (nullable = true)
Ver los detalles de una tabla en BigQuery
Sigue estos pasos para consultar los detalles de una tabla Iceberg en BigQuery:
Otros ejemplos
Crea un Spark
DataFrame(sdf) a partir de un DataFrame de Pandas (df).sdf = spark.createDataFrame(df) sdf.show()Ejecuta agregaciones en Spark
DataFrames.from pyspark.sql import functions as F sdf.groupby("segment").agg( F.mean("total_spend_per_user").alias("avg_order_value"), F.approx_count_distinct("user_id").alias("unique_customers") ).show()Lee datos de BigQuery con el conector Spark-BigQuery.
spark.conf.set("viewsEnabled","true") spark.conf.set("materializationDataset","my-bigquery-dataset") sdf = spark.read.format('bigquery') \ .load(query)Escribir código de Spark con Gemini Code Assist
Puedes pedirle a Gemini Code Assist que genere código de PySpark en tu cuaderno. Gemini Code Assist obtiene y usa las tablas de BigQuery y Dataproc Metastore relevantes, así como sus esquemas, para generar una respuesta de código.
Para generar código de Gemini Code Assist en tu cuaderno, haz lo siguiente:
Consejos para generar código con Gemini Code Assist
Finalizar la sesión de Spark
Puedes hacer cualquiera de las siguientes acciones para detener tu sesión de Spark Connect en tu cuaderno de BigQuery Studio:
Orquestar código de cuadernos de BigQuery Studio
Puedes orquestar el código de los cuadernos de BigQuery Studio de las siguientes formas:
Programar código de cuaderno desde la consola de Google Cloud
Puedes programar el código de un cuaderno de las siguientes formas:
Ejecutar código de cuaderno como una carga de trabajo por lotes
Sigue estos pasos para ejecutar el código de un cuaderno de BigQuery Studio como una carga de trabajo por lotes.
Solucionar errores de cuadernos
Si se produce un error en una celda que contiene código de Spark, puedes solucionar el problema haciendo clic en el enlace Vista de detalles de la sesión interactiva en el resultado de la celda (consulta los ejemplos de recuento de palabras y de tabla de Iceberg).
Problemas conocidos y soluciones
Error: Un entorno de ejecución de cuaderno creado con la versión
3.10de Python puede provocar un errorPYTHON_VERSION_MISMATCHcuando intenta conectarse a la sesión de Spark.Solución: vuelve a crear el tiempo de ejecución con la versión
3.11de Python.Siguientes pasos