Présentation du stockage BigQuery
Cette page décrit le composant de stockage de BigQuery.
Le stockage BigQuery est optimisé pour l'exécution de requêtes analytiques sur de grands ensembles de données. Il est également compatible avec l'ingestion par flux et les lectures à haut débit. Le fait de bien comprendre le stockage BigQuery peut vous aider à optimiser vos charges de travail.
Présentation
La séparation du stockage et du calcul est l'une des principales caractéristiques de l'architecture de BigQuery. Cela permet à BigQuery de faire évoluer le stockage et le calcul indépendamment, en fonction de la demande.
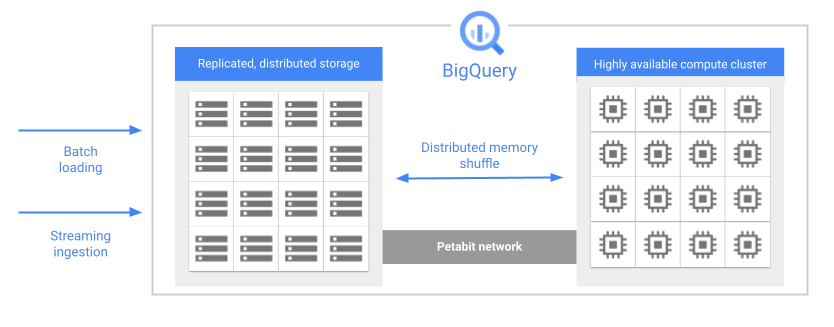
Lorsque vous exécutez une requête, le moteur de requête répartit le travail en parallèle sur plusieurs nœuds de calcul qui analysent les tables pertinentes dans l'espace de stockage, traitent la requête, puis collectent les résultats. BigQuery exécute les requêtes entièrement en mémoire, en utilisant un réseau de 1 pétaoctet pour garantir un transfert rapide des données vers les nœuds de calcul.
Voici quelques fonctionnalités clés du stockage BigQuery :
Géré. Le stockage BigQuery est un service entièrement géré. Vous n'avez pas besoin de provisionner des ressources de stockage ou de réserver des unités de stockage. BigQuery alloue automatiquement l'espace de stockage lorsque vous chargez des données dans le système. Vous ne payez que pour l'espace de stockage utilisé. Le modèle de tarification de BigQuery facture séparément les ressources de calcul et de stockage. Pour en savoir plus sur les tarifs, consultez la page Tarifs de BigQuery.
Durable. Le stockage BigQuery est conçu pour offrir une durabilité annuelle de 99,999999999 % (onze fois le chiffre 9). BigQuery réplique vos données sur plusieurs zones de disponibilité pour vous protéger contre la perte de données due aux défaillances au niveau de la machine ou aux défaillances zonales. Pour en savoir plus, consultez la section Fiabilité : planification des sinistres.
Chiffré. BigQuery chiffre automatiquement toutes les données avant qu'elles ne soient écrites sur le disque. Vous pouvez fournir votre propre clé de chiffrement ou laisser Google gérer la clé de chiffrement pour vous. Pour en savoir plus, consultez la page Chiffrement au repos.
Efficace. Le stockage BigQuery utilise un format d'encodage efficace et optimisé pour les charges de travail analytiques. Si vous souhaitez en savoir plus sur le format de stockage de BigQuery, consultez l'article de blog Présentation de Capacitor, le format de stockage en colonnes nouvelle génération de BigQuery.
Données de la table
La majorité des données que vous stockez dans BigQuery sont des données de table. Les données de table incluent des tables standards, des clones de table, des instantanés de table et des vues matérialisées. Le stockage que vous utilisez pour ces ressources vous est facturé. Pour en savoir plus, consultez les tarifs de stockage.
Les tables standards contiennent des données structurées. Chaque table possède un schéma, et chaque colonne du schéma possède un type de données. BigQuery stocke les données sous forme de colonnes. Consultez la section Configuration de l'espace de stockage de ce document.
Les clones de table sont des copies légères et accessibles en écriture de tables standards. BigQuery ne stocke que le delta entre un clone de table et sa table de base.
Les instantanés de table sont des copies de tables à un moment précis. Les instantanés de table sont en lecture seule, mais vous pouvez restaurer une table à partir d'un instantané de table. BigQuery ne stocke que le delta entre un instantané de table et sa table de base.
Les vues matérialisées sont des vues précalculées qui mettent régulièrement en cache les résultats d'une requête de vue. Les résultats mis en cache sont stockés dans l'espace de stockage BigQuery.
De plus, les résultats de requêtes mis en cache sont stockés sous forme de tables temporaires. Le stockage des résultats de requête mis en cache dans des tables temporaires ne vous est pas facturé.
Les tables externes sont un type spécial de table dans lequel les données résident dans un datastore externe à BigQuery, tel que Cloud Storage. Une table externe possède un schéma de table, exactement comme une table standard, mais la définition de la table pointe vers le datastore externe. Dans ce cas, seules les métadonnées de la table sont conservées dans l'espace de stockage BigQuery. BigQuery ne facture pas le stockage de tables externes, mais le datastore externe peut facturer des frais de stockage.
BigQuery organise les tables et autres ressources dans des conteneurs logiques appelés ensembles de données. La manière dont vous regroupez vos ressources BigQuery affecte les autorisations, les quotas, la facturation et d'autres aspects de vos charges de travail BigQuery. Pour en savoir plus et connaître les bonnes pratiques, consultez la page Organiser les ressources BigQuery.
La règle de conservation des données utilisée pour une table est déterminée par la configuration de l'ensemble de données qui contient la table. Pour en savoir plus, consultez la page Conservation des données avec la fonctionnalité temporelle et de sécurité.
Métadonnées
Le stockage BigQuery contient également des métadonnées sur vos ressources BigQuery. Le stockage des métadonnées ne vous est pas facturé.
Lorsque vous créez une entité persistante dans BigQuery, telle qu'une table, une vue ou une fonction définie par l'utilisateur, BigQuery stocke les métadonnées relatives à l'entité. Cela est valable même pour les ressources qui ne contiennent aucune donnée de table, telle que des fonctions définies par l'utilisateur ou les vues logiques.
Les métadonnées incluent des informations telles que le schéma de la table, les spécifications de partitionnement et de clustering, les délais d'expiration des tables ainsi que d'autres informations. Ce type de métadonnées est visible par l'utilisateur et peut être configuré au moment de la création de la ressource. De plus, BigQuery stocke des métadonnées utilisées en interne pour optimiser les requêtes. Ces métadonnées ne sont pas directement visibles par les utilisateurs.
Interface de stockage
De nombreux systèmes de base de données traditionnels stockent leurs données dans un format orienté lignes, ce qui signifie que les lignes sont stockées ensemble, les champs de chaque ligne apparaissant de manière séquentielle sur le disque. Les bases de données orientées ligne sont efficaces pour rechercher des enregistrements individuels. Toutefois, elles peuvent s'avérer moins efficaces pour mettre en œuvre des fonctions d'analyse sur de nombreux enregistrements car le système doit lire chaque champ lorsqu'il accède à un enregistrement.
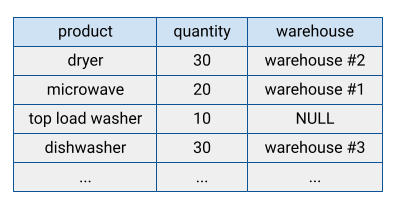
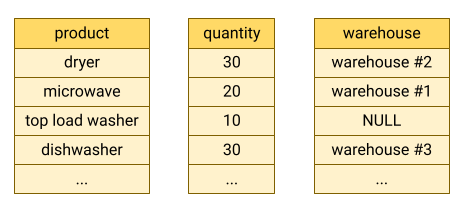
BigQuery stocke les données de table dans un format en colonnes, ce qui signifie qu'il stocke chaque colonne séparément. Les bases de données orientées colonnes sont particulièrement efficaces pour analyser des colonnes individuelles sur un ensemble de données complet.
Les bases de données orientées colonnes sont optimisées pour les charges de travail analytiques qui agrègent les données sur un très grand nombre d'enregistrements. Souvent, une requête analytique n'a besoin que de lire quelques colonnes d'une table. Par exemple, si vous souhaitez calculer la somme d'une colonne sur des millions de lignes, BigQuery peut renvoyer les données de colonne sans avoir à lire chaque champ de chaque ligne.
Un autre avantage des bases de données orientées colonnes est que les données d'une colonne ont généralement plus de redondance que les données d'une ligne. Cette caractéristique permet d'améliorer la compression des données en utilisant des techniques telles que l'encodage de longueur d'exécution, ce qui peut améliorer les performances de lecture.
Modèles de facturation du stockage
Vous pouvez être facturé pour le stockage de données BigQuery en octets logiques ou physiques (compressés), ou une combinaison des deux. Le modèle de facturation du stockage que vous choisissez détermine vos tarifs de stockage. Le modèle de facturation du stockage que vous choisissez n'a pas d'impact sur les performances de BigQuery. Quel que soit le modèle de facturation choisi, vos données sont stockées en octets physiques.
Vous définissez le modèle de facturation du stockage au niveau de l'ensemble de données. Si vous ne spécifiez pas de modèle de facturation du stockage lorsque vous créez un ensemble de données, le modèle de facturation du stockage logique est utilisé par défaut. Toutefois, vous pouvez modifier le modèle de facturation du stockage d'un ensemble de données après l'avoir créé. Une fois que vous avez modifié le modèle de facturation du stockage d'un ensemble de données, vous devez attendre 14 jours avant de pouvoir le modifier à nouveau.
Lorsque vous modifiez le modèle de facturation d'un ensemble de données, la prise en compte de la modification prend 24 heures. Les tables ou les partitions de tables du stockage à long terme ne sont pas réinitialisées sur le stockage actif lorsque vous modifiez le modèle de facturation d'un ensemble de données. Les performances et la latence des requêtes ne sont pas affectées par la modification du modèle de facturation d'un ensemble de données.
Les ensembles de données utilisent la fonctionnalité temporelle et le stockage préventif pour la conservation des données. Les fonctionnalités temporelles et le stockage de sécurité sont facturés séparément au tarif de stockage actif lorsque vous utilisez la facturation du stockage physique, mais sont inclus dans le tarif de base qui vous est facturé lorsque vous utilisez la facturation du stockage logique. Vous pouvez modifier la fenêtre de fonctionnalité temporelle que vous utilisez pour un ensemble de données afin d'équilibrer les coûts de stockage physique et la conservation des données. Vous ne pouvez pas modifier l'intervalle de prévention des défaillances. Pour en savoir plus sur la conservation des données des ensembles de données, consultez la page Conservation des données avec la fonctionnalité temporelle et de sécurité. Pour en savoir plus sur la prévision des coûts de stockage, consultez la page Prévoir la facturation du stockage.
Vous ne pouvez pas inscrire un ensemble de données à la facturation du stockage physique si votre organisation dispose d'anciens engagements d'emplacements à tarifs forfaitaires situés dans la même région que cet ensemble de données. Cela ne s'applique pas aux engagements souscrits avec une édition BigQuery.
Optimiser le stockage
L'optimisation du stockage BigQuery permet d'améliorer les performances des requêtes et de contrôler les coûts. Pour afficher les métadonnées de stockage des tables, interrogez les vues INFORMATION_SCHEMA suivantes :
Pour en savoir plus sur l'optimisation du stockage, consultez la page Optimiser le stockage dans BigQuery.
Charger les données
Il existe plusieurs modèles de base pour ingérer des données dans BigQuery.
Chargement par lot : chargez les données source dans une table BigQuery lors d'une seule opération par lot. Il peut s'agir d'une opération unique ou vous pouvez l'automatiser pour qu'elle s'effectue selon un calendrier. Une opération de chargement par lot peut créer une table ou ajouter des données à une table existante.
Streaming : diffusez de plus petits lots de données en continu, afin que les données soient disponibles pour des requêtes en quasi-temps réel.
Données générées : utilisez des instructions SQL pour insérer des lignes dans une table existante ou écrire les résultats d'une requête dans une table.
Pour savoir quand choisir chacune de ces méthodes d'ingestion, consultez la page Présentation du chargement des données. Pour connaître les tarifs, consultez la section Tarifs de l'ingestion de données.
Lire les données de l'espace de stockage BigQuery
La plupart du temps, vous stockez des données dans BigQuery afin d'exécuter des requêtes analytiques sur ces données. Toutefois, vous souhaiterez peut-être parfois lire les enregistrements directement à partir d'une table. BigQuery propose plusieurs méthodes pour lire les données d'une table :
API BigQuery : accès paginé synchrone à l'aide de la méthode
tabledata.list. Les données sont lues en série, une page par appel. Pour en savoir plus, consultez la page Parcourir les données d'une table.API BigQuery Storage : accès haut débit en streaming compatible avec la projection et le filtrage des colonnes côté serveur. Les lectures peuvent être chargées en parallèle sur plusieurs lecteurs en les segmentant en plusieurs flux disjoints.
Exportation : copie asynchrone à haut débit vers Google Cloud Storage, à l'aide de jobs d'extraction ou de l'instruction
EXPORT DATA. Si vous devez copier des données dans Cloud Storage, exportez-les à l'aide d'un job d'extraction ou d'une instructionEXPORT DATA.Copie : copie asynchrone des ensembles de données dans BigQuery. La copie est effectuée de manière logique lorsque l'emplacement source et la destination sont identiques.
Pour en savoir plus sur la tarification, consultez la page Tarifs de l'extraction des données.
En fonction des exigences de l'application, vous pouvez lire les données de la table :
- Lecture et copie : si vous avez besoin d'une copie au repos dans Cloud Storage, exportez les données à l'aide d'une tâche d'extraction ou d'une instruction
EXPORT DATA. Si vous souhaitez uniquement lire les données, utilisez l'API BigQuery Storage. Si vous souhaitez créer une copie dans BigQuery, utilisez une tâche de copie. - Scaling : l'API BigQuery est la méthode la moins efficace et ne doit pas être utilisée pour les lectures de gros volumes. Si vous devez exporter plus de 50 To de données par jour, utilisez l'instruction
EXPORT DATAou l'API BigQuery Storage. - Délai de retour de la première ligne : l'API BigQuery est la méthode la plus rapide pour renvoyer la première ligne, mais elle ne doit être utilisée que pour lire de petites quantités de données. L'API BigQuery Storage est plus lente à renvoyer la première ligne, mais son débit est beaucoup plus élevé. Les exportations et les copies doivent être terminées avant que les lignes ne puissent être lues. Le temps écoulé jusqu'à la première ligne pour ces types de tâches peut donc être de l'ordre de quelques minutes.
Suppression
Lorsque vous supprimez une table, les données sont conservées pendant au moins la durée de votre fenêtre de fonctionnalité temporelle. Ensuite, les données sont nettoyées du disque selon le délai de suppression deGoogle Cloud .
Certaines opérations de suppression, telles que l'instruction DROP COLUMN, sont des opérations exclusivement de métadonnées. Dans ce cas, l'espace de stockage est libéré la prochaine fois que vous modifiez les lignes concernées. Si vous ne les modifiez pas, il n'y a pas de délai garanti pendant lequel l'espace de stockage est libéré. Pour en savoir plus, consultez Suppression des données sur Google Cloud.
Étapes suivantes
- Découvrez comment utiliser des tables.
- Découvrez comment optimiser le stockage.
- Découvrez comment interroger des données dans BigQuery.
- Apprenez-en davantage sur la sécurité et la gouvernance des données.