Vista geral do armazenamento do BigQuery
Esta página descreve o componente de armazenamento do BigQuery.
O armazenamento do BigQuery está otimizado para executar consultas analíticas em grandes conjuntos de dados. Também suporta o carregamento de streams de alto débito e leituras de alto débito. Compreender o armazenamento do BigQuery pode ajudar a otimizar as suas cargas de trabalho.
Vista geral
Uma das principais funcionalidades da arquitetura do BigQuery é a separação do armazenamento e da computação. Isto permite que o BigQuery ajuste a escala do armazenamento e da computação de forma independente, com base na procura.
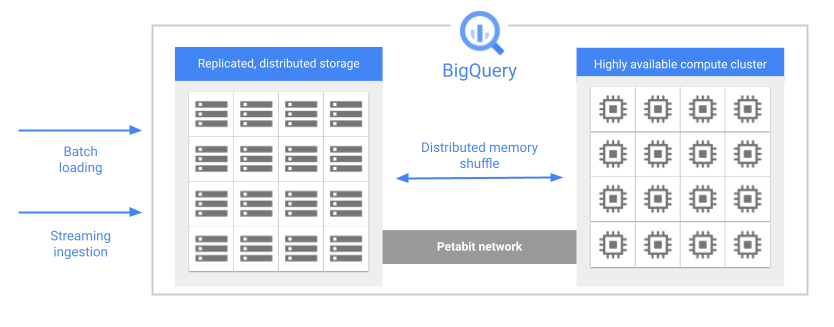
Quando executa uma consulta, o motor de consultas distribui o trabalho em paralelo por vários trabalhadores, que analisam as tabelas relevantes no armazenamento, processam a consulta e, em seguida, recolhem os resultados. O BigQuery executa consultas completamente na memória, usando uma rede de petabits para garantir que os dados se movem extremamente rápido para os nós de trabalho.
Seguem-se algumas funcionalidades principais do armazenamento do BigQuery:
Gerido. O armazenamento do BigQuery é um serviço totalmente gerido. Não precisa de aprovisionar recursos de armazenamento nem reservar unidades de armazenamento. O BigQuery atribui automaticamente armazenamento quando carrega dados para o sistema. Só paga a quantidade de armazenamento que usa. O modelo de preços do BigQuery cobra a computação e o armazenamento separadamente. Para ver detalhes dos preços, consulte os preços do BigQuery.
Durável. O armazenamento do BigQuery foi concebido para uma durabilidade anual de 99,999999999% (11 noves). O BigQuery replica os seus dados em várias zonas de disponibilidade para proteger contra a perda de dados devido a falhas ao nível da máquina ou falhas zonais. Para mais informações, consulte o artigo Fiabilidade: planeamento de desastres.
Encriptado. O BigQuery encripta automaticamente todos os dados antes de serem escritos no disco. Pode fornecer a sua própria chave de encriptação ou permitir que a Google faça a gestão da chave de encriptação. Para mais informações, consulte o artigo Encriptação em repouso.
Eficiente. O armazenamento do BigQuery usa um formato de codificação eficiente otimizado para cargas de trabalho analíticas. Se quiser saber mais acerca do formato de armazenamento do BigQuery, consulte a publicação no blogue Inside Capacitor, BigQuery's next-generation columnar storage format.
Dados da tabela
A maioria dos dados que armazena no BigQuery são dados de tabela. Os dados de tabelas incluem tabelas padrão, clones de tabelas, instantâneos de tabelas e vistas materializadas. O armazenamento que usa para estes recursos é-lhe cobrado. Para mais informações, consulte os preços de armazenamento.
As tabelas padrão contêm dados estruturados. Cada tabela tem um esquema e cada coluna no esquema tem um tipo de dados. O BigQuery armazena dados em formato de colunas. Consulte o esquema de armazenamento neste documento.
Os clones de tabelas são cópias leves e graváveis de tabelas padrão. O BigQuery só armazena a diferença entre um clone de uma tabela e a respetiva tabela base.
Os instantâneos de tabelas são cópias de tabelas num momento específico. Os instantâneos de tabelas são só de leitura, mas pode restaurar uma tabela a partir de um instantâneo de tabela. O BigQuery apenas armazena a diferença entre uma imagem instantânea da tabela e a respetiva tabela base.
As vistas materializadas são vistas pré-calculadas que armazenam periodicamente em cache os resultados da consulta de visualização. Os resultados em cache são armazenados no armazenamento do BigQuery.
Além disso, os resultados de consultas em cache são armazenados como tabelas temporárias. Os resultados de consultas em cache armazenados em tabelas temporárias não são cobrados.
As tabelas externas são um tipo especial de tabela, em que os dados residem num armazenamento de dados externo ao BigQuery, como o Cloud Storage. Uma tabela externa tem um esquema de tabela, tal como uma tabela padrão, mas a definição da tabela aponta para o armazenamento de dados externo. Neste caso, apenas os metadados da tabela são mantidos no armazenamento do BigQuery. O BigQuery não cobra pelo armazenamento de tabelas externas, embora o armazenamento de dados externo possa cobrar pelo armazenamento.
O BigQuery organiza as tabelas e outros recursos em contentores lógicos denominados conjuntos de dados. A forma como agrupa os recursos do BigQuery afeta as autorizações, as quotas, a faturação e outros aspetos das cargas de trabalho do BigQuery. Para mais informações e práticas recomendadas, consulte o artigo Organizar recursos do BigQuery.
A política de retenção de dados usada para uma tabela é determinada pela configuração do conjunto de dados que contém a tabela. Para mais informações, consulte o artigo Retenção de dados com viagem no tempo e à prova de falhas.
Metadados
O armazenamento do BigQuery também contém metadados sobre os seus recursos do BigQuery. O armazenamento de metadados não lhe é cobrado.
Quando cria qualquer entidade persistente no BigQuery, como uma tabela, uma vista ou uma função definida pelo utilizador (UDF), o BigQuery armazena metadados sobre a entidade. Isto é verdade mesmo para recursos que não contêm dados de tabelas, como UDFs e vistas lógicas.
Os metadados incluem informações como o esquema da tabela, as especificações de particionamento e agrupamento, os prazos de validade da tabela e outras informações. Este tipo de metadados é visível para o utilizador e pode ser configurado quando cria o recurso. Além disso, o BigQuery armazena metadados que usa internamente para otimizar as consultas. Estes metadados não são diretamente visíveis para os utilizadores.
Layout de armazenamento
Muitos sistemas de base de dados tradicionais armazenam os respetivos dados num formato orientado por linhas, o que significa que as linhas são armazenadas em conjunto, com os campos em cada linha a aparecerem sequencialmente no disco. As bases de dados orientadas por linhas são eficientes na procura de registos individuais. No entanto, podem ser menos eficientes na execução de funções analíticas em muitos registos, porque o sistema tem de ler todos os campos quando acede a um registo.
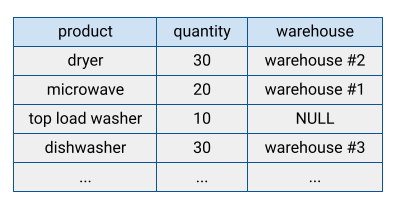
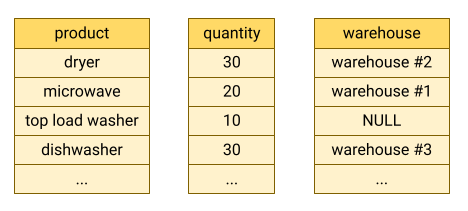
O BigQuery armazena os dados das tabelas no formato colunar, o que significa que armazena cada coluna separadamente. As bases de dados orientadas para colunas são particularmente eficientes na análise de colunas individuais num conjunto de dados completo.
As bases de dados orientadas por colunas são otimizadas para cargas de trabalho analíticas que agregam dados num número muito elevado de registos. Muitas vezes, uma consulta analítica só precisa de ler algumas colunas de uma tabela. Por exemplo, se quiser calcular a soma dos dados de uma coluna em milhões de linhas, o BigQuery pode ler os dados dessa coluna sem ler todos os campos de todas as linhas.
Outra vantagem das bases de dados orientadas para colunas é que os dados numa coluna têm normalmente mais redundância do que os dados numa linha. Esta característica permite uma maior compressão de dados através de técnicas como a codificação de comprimento de execução, o que pode melhorar o desempenho de leitura.
Modelos de faturação de armazenamento
Pode receber faturação pelo armazenamento de dados do BigQuery em bytes lógicos ou físicos (comprimidos) ou uma combinação de ambos. O modelo de faturação de armazenamento que escolher determina os seus preços de armazenamento. O modelo de faturação de armazenamento que escolhe não afeta o desempenho do BigQuery. Qualquer que seja o modelo de faturação que escolher, os seus dados são armazenados como bytes físicos.
Define o modelo de faturação de armazenamento ao nível do conjunto de dados. Se não especificar um modelo de faturação de armazenamento quando cria um conjunto de dados, este usa por predefinição a faturação de armazenamento lógico. No entanto, pode alterar o modelo de faturação de armazenamento de um conjunto de dados depois de o criar. Se alterar o modelo de faturação do armazenamento de um conjunto de dados, tem de aguardar 14 dias antes de poder alterar novamente o modelo de faturação do armazenamento.
Quando altera o modelo de faturação de um conjunto de dados, a alteração demora 24 horas a entrar em vigor. As tabelas ou as partições de tabelas no armazenamento a longo prazo não são repostas para o armazenamento ativo quando altera o modelo de faturação de um conjunto de dados. O desempenho e a latência das consultas não são afetados pela alteração do modelo de faturação de um conjunto de dados.
Os conjuntos de dados usam a viagem no tempo e o armazenamento à prova de falhas para a retenção de dados. A viagem no tempo e o armazenamento à prova de falhas são cobrados separadamente às taxas de armazenamento ativo quando usa a faturação de armazenamento físico, mas estão incluídos na taxa base que lhe é cobrada quando usa a faturação de armazenamento lógico. Pode modificar o período de deslocação no tempo que usa para um conjunto de dados de forma a equilibrar os custos de armazenamento físico com a retenção de dados. Não pode modificar o período de segurança. Para mais informações acerca da retenção de dados do conjunto de dados, consulte Retenção de dados com a funcionalidade de viagem no tempo e à prova de falhas. Para mais informações sobre a previsão dos custos de armazenamento, consulte o artigo Preveja a faturação do armazenamento.
Não pode inscrever um conjunto de dados na faturação de armazenamento físico se a sua organização tiver compromissos de slots de taxa fixa antigos localizados na mesma região que o conjunto de dados. Isto não se aplica a compromissos comprados com uma edição do BigQuery.
Otimize o armazenamento
A otimização do armazenamento do BigQuery melhora o desempenho das consultas e
controla os custos. Para ver os metadados de armazenamento de tabelas, consulte as seguintes
vistas INFORMATION_SCHEMA:
Para informações sobre a otimização do armazenamento, consulte o artigo Otimize o armazenamento no BigQuery.
Carregue dados
Existem vários padrões básicos para carregar dados para o BigQuery.
Carregamento em lote: carregue os seus dados de origem numa tabela do BigQuery numa única operação em lote. Esta pode ser uma operação única ou pode automatizá-la para ocorrer de acordo com um horário. Uma operação de carregamento em lote pode criar uma nova tabela ou anexar dados a uma tabela existente.
Streaming: transmita continuamente lotes de dados mais pequenos para que os dados estejam disponíveis para consulta quase em tempo real.
Dados gerados: use declarações SQL para inserir linhas numa tabela existente ou escrever os resultados de uma consulta numa tabela.
Para mais informações sobre quando escolher cada um destes métodos de carregamento, consulte o artigo Introdução ao carregamento de dados. Para ver informações de preços, consulte o artigo Preços do carregamento de dados.
Ler dados do armazenamento do BigQuery
Na maioria das vezes, armazena dados no BigQuery para executar consultas analíticas nesses dados. No entanto, por vezes, pode querer ler registos diretamente de uma tabela. O BigQuery oferece várias formas de ler dados de tabelas:
API BigQuery: acesso paginado síncrono com o método
tabledata.list. Os dados são lidos de forma serial, uma página por invocação. Para mais informações, consulte o artigo Navegar nos dados de tabelas.API BigQuery Storage: acesso de streaming de elevado débito que também suporta projeção e filtragem de colunas do lado do servidor. As leituras podem ser paralelizadas em vários leitores segmentando-as em vários fluxos disjuntos.
Exportação: Cópia assíncrona de elevado débito para o Google Cloud Storage, com tarefas de extração ou a
EXPORT DATAdeclaração. Se precisar de copiar dados no Cloud Storage, exporte os dados com uma tarefa de extração ou uma declaraçãoEXPORT DATA.Cópia: Cópia assíncrona de conjuntos de dados no BigQuery. A cópia é feita logicamente quando a localização de origem e destino é a mesma.
Para ver informações de preços, consulte o artigo Preços da extração de dados.
Com base nos requisitos da aplicação, pode ler os dados da tabela:
- Ler e copiar: se precisar de uma cópia em repouso no Cloud Storage, exporte os dados com uma tarefa de extração ou uma declaração
EXPORT DATA. Se só quiser ler os dados, use a API BigQuery Storage. Se quiser fazer uma cópia no BigQuery, use uma tarefa de cópia. - Escala: a API BigQuery é o método menos eficiente e não deve ser usado para leituras de grande volume. Se precisar de exportar mais de 50 TB de dados por dia, use a declaração
EXPORT DATAou a API BigQuery Storage. - Tempo para devolver a primeira linha: a API BigQuery é o método mais rápido para devolver a primeira linha, mas só deve ser usada para ler pequenas quantidades de dados. A API BigQuery Storage é mais lenta a devolver a primeira linha, mas tem um débito muito mais elevado. As exportações e as cópias têm de terminar antes de se poderem ler quaisquer linhas. Por isso, o tempo até à primeira linha para estes tipos de tarefas pode ser da ordem dos minutos.
Eliminação
Quando elimina uma tabela, os dados persistem, pelo menos, durante o período da janela de viagem no tempo. Após este período, os dados são limpos do disco no prazo de Google Cloud .
Algumas operações de eliminação, como a declaração DROP COLUMN, são operações apenas de metadados. Neste caso, o armazenamento é libertado da próxima vez que modificar as linhas afetadas. Se não modificar a tabela, não existe um tempo garantido dentro do qual o armazenamento é libertado. Para mais informações, consulte o artigo
Eliminação de dados no Google Cloud.
O que se segue?
- Saiba como trabalhar com tabelas.
- Saiba como otimizar o armazenamento.
- Saiba como consultar dados no BigQuery.
- Saiba mais sobre a segurança e a governação de dados.