BigQuery-Speicher
Auf dieser Seite wird die Speicherkomponente von BigQuery beschrieben.
BigQuery-Speicher ist für die Ausführung analytischer Abfragen in großen Datasets optimiert. Außerdem werden die Streamingaufnahme mit hohem Durchsatz und Lesevorgänge mit hohem Durchsatz unterstützt. Wenn Sie BigQuery-Speicher verstehen, können Sie Ihre Arbeitslasten optimieren.
Übersicht
Eines der Hauptfeatures der BigQuery-Architektur ist die Trennung von Speicher und Computing. Dadurch kann BigQuery sowohl Speicher als auch Computing unabhängig nach Bedarf skalieren.
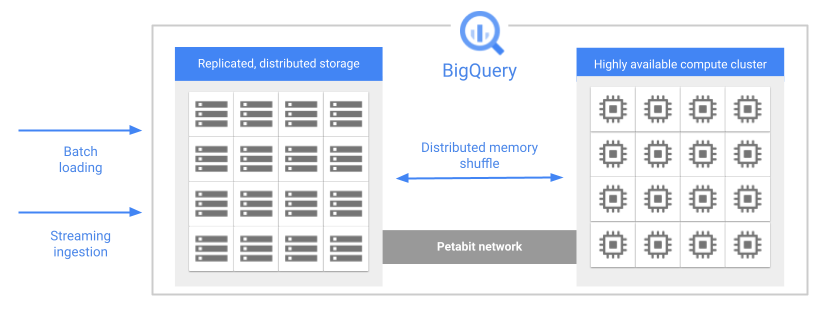
Wenn Sie eine Abfrage ausführen, verteilt die Abfrage-Engine die Arbeit parallel auf mehrere Worker, die die relevanten Tabellen im Speicher scannen, die Abfrage verarbeiten und dann die Ergebnisse erfassen. BigQuery führt Abfragen vollständig im Arbeitsspeicher mithilfe eines Petabit-Netzwerks aus, damit Daten extrem schnell zu den Worker-Knoten verschoben werden.
Hier einige der wichtigsten Features von BigQuery-Speicher:
Verwaltet. BigQuery-Speicher ist ein vollständig verwalteter Dienst. Sie müssen keine Speicherressourcen bereitstellen oder Speichereinheiten reservieren. BigQuery weist Ihnen automatisch Speicher zu, wenn Sie Daten in das System laden. Sie zahlen nur für den Speicherplatz, den Sie tatsächlich nutzen. Im BigQuery-Preismodell werden Gebühren für Computing und Speicher separat berechnet. Preisdetails finden Sie unter BigQuery-Preise.
Langlebig. Der BigQuery-Speicher ist auf eine jährliche Verfügbarkeit von 99,999999999 % ausgelegt. Das sind 11 Neuner. BigQuery repliziert Ihre Daten über mehrere Verfügbarkeitszonen, um sie vor Datenverlusten wegen Ausfällen auf Maschinenebene oder zonalen Ausfällen zu schützen. Weitere Informationen finden Sie unter Zuverlässigkeit: Notfallwiederherstellung.
Verschlüsselt. BigQuery verschlüsselt automatisch alle Daten, bevor sie auf ein Laufwerk geschrieben werden. Sie können Ihren eigenen Verschlüsselungsschlüssel bereitstellen oder den Verschlüsselungsschlüssel von Google verwalten lassen. Weitere Informationen finden Sie unter Verschlüsselung ruhender Daten.
Effizient. BigQuery-Speicher verwendet ein effizientes Codierungsformat, das für Analysearbeitslasten optimiert ist. Weitere Informationen zum Speicherformat von BigQuery finden Sie im Blogpost Inside Capacitor, BigQuery’s next-generation columnar storage format.
Tabellendaten
Die meisten Daten, die Sie in BigQuery speichern, sind Tabellendaten. Tabellendaten umfassen Standardtabellen, Tabellenklone, Tabellen-Snapshots und materialisierte Ansichten. Ihnen wird der Speicher in Rechnung gestellt, den Sie für diese Ressourcen verwenden. Weitere Informationen finden Sie unter Speicherpreise.
Standardtabellen enthalten strukturierte Daten. Jede Tabelle hat ein Schema und jede Spalte im Schema hat einen Datentyp. BigQuery speichert Daten im Spaltenformat. Siehe Speicherlayout in diesem Dokument.
Tabellenklone sind einfache, beschreibbare Kopien von Standardtabellen. BigQuery speichert nur den Unterschied zwischen einem Tabellenklon und dessen Basistabelle.
Tabellen-Snapshots sind Tabellenkopien zu einem bestimmten Zeitpunkt. Tabellen-Snapshots sind schreibgeschützt, aber Sie können eine Tabelle aus einem Tabellen-Snapshot wiederherstellen. BigQuery speichert nur den Unterschied zwischen einem Tabellen-Snapshot und dessen Basistabelle.
Materialisierte Ansichten sind vorausberechnete Ansichten, die die Ergebnisse der Ansichtsabfrage regelmäßig im Cache speichern. Die im Cache gespeicherten Ergebnisse werden im BigQuery-Speicher aufbewahrt.
Darüber hinaus werden im Cache gespeicherte Abfrageergebnisse als temporäre Tabellen gespeichert. Im Cache gespeicherte Abfrageergebnisse in temporären Tabellen werden nicht in Rechnung gestellt.
Externe Tabellen sind ein spezieller Tabellentyp, bei dem sich die Daten in einem Datenspeicher außerhalb von BigQuery befinden, z. B. Cloud Storage. Eine externe Tabelle hat genau wie eine Standardtabelle ein Tabellenschema. Die Tabellendefinition verweist jedoch auf den externen Datenspeicher. In diesem Fall werden nur die Tabellenmetadaten im BigQuery-Speicher gespeichert. In BigQuery fallen keine Kosten für den externen Tabellenspeicher an, der externe Datenspeicher kann jedoch Speicherung in Rechnung stellen.
BigQuery organisiert Tabellen und andere Ressourcen in logischen Containern, die Datasets genannt werden. Wie Sie Ihre BigQuery-Ressourcen gruppieren, wirkt sich auf Berechtigungen, Kontingente, Abrechnung und andere Aspekte Ihrer BigQuery-Arbeitslasten aus. Weitere Informationen und Best Practices finden Sie unter BigQuery-Ressourcen organisieren.
Die Datenaufbewahrungsrichtlinie, die für eine Tabelle verwendet wird, wird durch die Konfiguration des Datasets bestimmt, das die Tabelle enthält. Weitere Informationen finden Sie unter Datenaufbewahrung mit Zeitreisen und Ausfallsicherheit.
Metadaten
BigQuery-Speicher enthält auch Metadaten zu Ihren BigQuery-Ressourcen. Für die Speicherung von Metadaten fallen keine Gebühren an.
Wenn Sie eine nichtflüchtige Entität in BigQuery erstellen, z. B. eine Tabelle, eine Ansicht oder eine benutzerdefinierte Funktion (User-Defined Function, UDF), speichert BigQuery Metadaten zur Entität. Dies gilt auch für Ressourcen, die keine Tabellendaten enthalten, z. B. UDFs und logische Ansichten.
Metadaten enthalten Informationen wie das Tabellenschema, Partitionierungs- und Clustering-Spezifikationen sowie Tabellenablaufzeiten. Diese Art von Metadaten ist für den Nutzer sichtbar und kann beim Erstellen der Ressource konfiguriert werden. Außerdem speichert BigQuery Metadaten, die intern zur Optimierung von Abfragen verwendet werden. Diese Metadaten sind für die Nutzer nicht direkt sichtbar.
Speicherlayout
Viele traditionelle Datenbanksysteme speichern ihre Daten in einem zeilenorientierten Format, d. h., Zeilen werden zusammen gespeichert, wobei die Felder in jeder Zeile auf dem Laufwerk sequenziell angezeigt werden. Zeilenorientierte Datenbanken eignen sich für die effiziente Suche nach einzelnen Datensätzen. Sie sind jedoch möglicherweise weniger effizient, um Analysefunktionen über viele Datensätze hinweg auszuführen, da das System beim Zugriff auf einen Datensatz jedes Feld lesen muss.
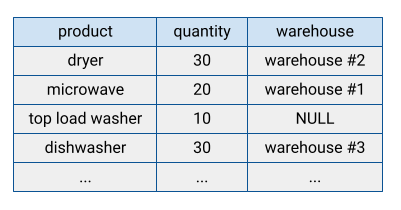
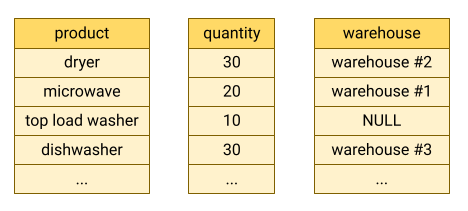
BigQuery speichert Tabellendaten im Spaltenformat, d. h., jede Spalte wird separat gespeichert. Spaltenorientierte Datenbanken sind besonders effizient beim Scannen einzelner Spalten über ein gesamtes Dataset hinweg.
Spaltenorientierte Datenbanken sind für Analysearbeitslasten optimiert, die Daten aus einer sehr großen Anzahl von Datensätzen aggregieren. Häufig muss eine Analyseabfrage nur wenige Spalten aus einer Tabelle lesen. Wenn Sie beispielsweise die Summe einer Spalte über Millionen von Zeilen berechnen möchten, kann BigQuery diese Spaltendaten lesen, ohne jedes Feld jeder Zeile zu lesen.
Ein weiterer Vorteil von spaltenorientierten Datenbanken besteht darin, dass Daten innerhalb einer Spalte in der Regel mehr Redundanz als Daten in einer Zeile haben. Diese Eigenschaft ermöglicht eine höhere Datenkomprimierung, indem Techniken wie die Laufzeitlängencodierung verwendet werden, die die Leseleistung verbessern kann.
Speicherabrechnungsmodelle
Die BigQuery-Datenspeicherung kann entweder in logischen oder physischen (komprimierten) Byte oder in einer Kombination aus beidem in Rechnung gestellt werden. Das von Ihnen ausgewählte Speicherabrechnungsmodell bestimmt Ihre Speicherpreise. Das von Ihnen ausgewählte Speicherabrechnungsmodell wirkt sich nicht auf die BigQuery-Leistung aus. Unabhängig vom ausgewählten Abrechnungsmodell werden Ihre Daten als physische Byte gespeichert.
Sie legen das Speicherabrechnungsmodell auf Dataset-Ebene fest. Wenn Sie beim Erstellen eines Datasets kein Speicherabrechnungsmodell angeben, wird standardmäßig die logische Speicherabrechnung verwendet. Sie können jedoch das Speicherabrechnungsmodell eines Datasets nach dem Erstellen ändern. Nachdem Sie das Speicherabrechnungsmodell eines Datasets geändert haben, müssen Sie 14 Tage warten, bevor Sie das Speicherabrechnungsmodell wieder ändern können.
Wenn Sie das Abrechnungsmodell eines Datasets ändern, dauert es 24 Stunden, bis die Änderung wirksam wird. Alle Tabellen oder Tabellenpartitionen im Langzeitspeicher werden nicht auf den aktiven Speicher zurückgesetzt, wenn Sie das Abrechnungsmodell eines Datasets ändern. Die Abfrageleistung und die Abfragelatenz werden durch eine Änderung des Abrechnungsmodells eines Datasets nicht beeinflusst.
Datasets verwenden Zeitreisen und Fail-Safe-Speicher für die Datenaufbewahrung. Zeitreisen und Fail-Safe-Speicher werden bei Verwendung der physischen Speicherabrechnung separat zu aktiven Speicherpreisen in Rechnung gestellt. Sie sind jedoch im Basispreis enthalten, der Ihnen in Rechnung gestellt wird, wenn Sie die logische Speicherabrechnung verwenden. Sie können das Zeitreisefenster für ein Dataset ändern, um die Kosten für physische Speicher mit der Datenaufbewahrung auszugleichen. Sie können das Fail-Safe-Fenster nicht ändern. Weitere Informationen zur Aufbewahrung von Dataset-Daten finden Sie unter Datenaufbewahrung mit Zeitreisen und Ausfallsicherheit. Weitere Informationen zur Prognose Ihrer Speicherkosten finden Sie unter Speicherabrechnung prognostizieren.
Sie können ein Dataset nicht für die physische Speicherabrechnung registrieren, wenn Ihre Organisation Legacy-Slot-Zusicherungen zum Pauschalpreis hat, die sich in derselben Region wie das Dataset befinden. Dies gilt nicht für Zusicherungen, die mit einer BigQuery-Version erworben wurden.
Speicher optimieren
Die Optimierung von BigQuery-Speicher verbessert die Abfrageleistung und kontrolliert die Kosten. Fragen Sie die folgenden INFORMATION_SCHEMA-Ansichten ab, um die Metadaten des Tabellenspeichers aufzurufen:
Informationen zum Optimieren des Speichers finden Sie unter Speicher in BigQuery optimieren.
Daten laden
Es gibt mehrere grundlegende Muster für die Aufnahme von Daten in BigQuery.
Batchladevorgang: Laden Sie Ihre Quelldaten in einem einzelnen Batchvorgang in eine BigQuery-Tabelle. Dabei kann es sich um einen einmaligen Vorgang handeln oder Sie können ihn nach einem Zeitplan automatisieren. Beim Batchladevorgang kann eine neue Tabelle erstellt werden oder die Daten können an eine vorhandene Tabelle angefügt werden.
Streaming: Streamen Sie kontinuierlich kleinere Batches von Daten, damit die Daten nahezu in Echtzeit für Abfragen verfügbar sind.
Generierte Daten: Verwenden Sie SQL-Anweisungen, um Zeilen in eine vorhandene Tabelle einzufügen oder die Ergebnisse einer Abfrage in eine Tabelle zu schreiben.
Weitere Informationen zur Auswahl der einzelnen Aufnahmemethoden finden Sie unter Einführung in das Laden von Daten. Preisinformationen finden Sie unter Preise für die Datenaufnahme.
Daten aus dem BigQuery-Speicher lesen
In den meisten Fällen speichern Sie Daten in BigQuery, um analytische Abfragen für diese Daten auszuführen. Manchmal möchten Sie Datensätze aber möglicherweise direkt aus einer Tabelle lesen. BigQuery bietet mehrere Möglichkeiten zum Lesen von Tabellendaten:
BigQuery API: Synchroner paginierter Zugriff mit der Methode
tabledata.list. Daten werden seriell gelesen, eine Seite pro Aufruf. Weitere Informationen finden Sie unter Tabellendaten durchsuchen.BigQuery Storage API: Streaming-Zugriff mit hohem Durchsatz, der auch die serverseitige Spaltenprojektion und -filterung unterstützt. Lesevorgänge können für viele Leser parallelisiert werden, indem sie in mehrere disjunkte Streams segmentiert werden.
Exportieren Für Asynchrones Kopieren mit hohem Durchsatz in Google Cloud Storage, entweder mit Extrahierjobs oder mit der
EXPORT DATA-Anweisung Wenn Sie Daten in Cloud Storage kopieren müssen, exportieren Sie die Daten entweder mit einem Extrahierjob oder mit einerEXPORT DATA-Anweisung.Kopieren: Asynchrones Kopieren von Datasets in BigQuery. Die Kopie wird logisch erstellt, wenn der Quell- und der Zielspeicherort identisch sind.
Preisinformationen finden Sie unter Preise für die Datenextraktion.
Je nach Anwendungsanforderungen können Sie die Tabellendaten auf folgende Weise lesen:
- Lesen und kopieren: Wenn Sie eine inaktive Kopie in Cloud Storage benötigen, exportieren Sie die Daten entweder mit einem Extrahierjob oder mit einer
EXPORT DATA-Anweisung. Wenn Sie nur die Daten lesen möchten, verwenden Sie die BigQuery Storage API. Wenn Sie eine Kopie in BigQuery erstellen möchten, sollten Sie einen Kopierjob verwenden. - Skalierung: Die BigQuery API ist die am wenigsten effiziente Methode und sollte nicht für Lesevorgänge mit hohem Volumen verwendet werden. Wenn Sie mehr als 50 TB Daten pro Tag exportieren müssen, verwenden Sie die Anweisung
EXPORT DATAoder die BigQuery Storage API. - Zeit bis zur Rückgabe der ersten Zeile: Die BigQuery API ist die schnellste Methode, um die erste Zeile zurückzugeben. Sie sollte jedoch nur zum Lesen kleiner Datenmengen verwendet werden. Die BigQuery Storage API ist langsamer bei der Rückgabe der ersten Zeile, hat jedoch einen viel höheren Durchsatz. Exporte und Kopien müssen abgeschlossen sein, bevor Zeilen gelesen werden können. Daher kann die Zeit bis zur ersten Zeile für diese Arten von Jobs innerhalb von Minuten liegen.
Löschen
Wenn Sie eine Tabelle löschen, bleiben die Daten mindestens für die Dauer Ihres Zeitreisefensters erhalten. Danach werden die Daten innerhalb des Google Cloud Löschzeitplans vom Laufwerk gelöscht.
Einige Löschvorgänge, darunter die DROP COLUMN-Anweisung, sind reine Metadatenvorgänge. In diesem Fall wird der Speicherplatz beim nächsten Ändern der betroffenen Zeilen freigegeben. Wenn Sie die Tabelle nicht ändern, kann nicht garantiert werden, dass der Speicherplatz innerhalb einer bestimmten Zeit freigegeben wird. Weitere Informationen finden Sie unter Datenlöschung auf Google Cloud.