搜索编入索引的数据
本页面举例说明了如何在 BigQuery 中搜索表格数据。在将数据编入索引时,BigQuery 可以优化某些使用 SEARCH 函数或其他函数和运算符(例如 =、IN、LIKE 和 STARTS_WITH)的查询。
即使部分数据尚未编入索引,SQL 查询也会从所有注入的数据返回正确的结果。不过,使用索引可以显著提高查询性能。如果搜索结果数量占表中总行数的相对较小部分,则可以最大限度地减少处理字节数和槽毫秒数,因为扫描的数据较少。如需确定某一索引是否用于查询,请参阅搜索索引使用情况。
创建搜索索引
以下名为 Logs 表用于显示使用 SEARCH 函数的不同方式。此示例表非常小,但实际上表越大,使用 SEARCH 获得的性能提升幅度就越大。
CREATE TABLE my_dataset.Logs (Level STRING, Source STRING, Message STRING) AS ( SELECT 'INFO' as Level, '65.177.8.234' as Source, 'Entry Foo-Bar created' as Message UNION ALL SELECT 'WARNING', '132.249.240.10', 'Entry Foo-Bar already exists, created by 65.177.8.234' UNION ALL SELECT 'INFO', '94.60.64.181', 'Entry Foo-Bar deleted' UNION ALL SELECT 'SEVERE', '4.113.82.10', 'Entry Foo-Bar does not exist, deleted by 94.60.64.181' UNION ALL SELECT 'INFO', '181.94.60.64', 'Entry Foo-Baz created' );
该表如下所示:
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 65.177.8.234 | Entry Foo-Bar created | | WARNING | 132.249.240.10 | Entry Foo-Bar already exists, created by 65.177.8.234 | | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | | INFO | 181.94.60.64 | Entry Foo-Baz created | +---------+----------------+-------------------------------------------------------+
使用默认文本分析器在 Logs 表上创建搜索索引:
CREATE SEARCH INDEX my_index ON my_dataset.Logs(ALL COLUMNS);
如需详细了解搜索索引,请参阅管理搜索索引。
使用 SEARCH 函数
SEARCH 函数提供对数据的标记化搜索。SEARCH 旨在与索引搭配使用以优化查询。您可以使用 SEARCH 函数搜索整个表,也可以将搜索范围限制为特定列。
搜索整个表
以下查询会在 Logs 表的所有列中搜索 bar 值,并返回包含此值的行,而无论大小写如何。 由于搜索索引使用默认文本分析器,因此您无需在 SEARCH 函数中指定它。
SELECT * FROM my_dataset.Logs WHERE SEARCH(Logs, 'bar');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 65.177.8.234 | Entry Foo-Bar created | | WARNING | 132.249.240.10 | Entry Foo-Bar already exists, created by 65.177.8.234 | | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
以下查询会在 Logs 表的所有列中搜索 `94.60.64.181` 值,并返回包含此值的行。 反引号允许进行精确搜索,因此省略了包含 181.94.60.64 的 Logs 表的最后一行。
SELECT * FROM my_dataset.Logs WHERE SEARCH(Logs, '`94.60.64.181`');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
搜索列的子集
您可以使用 SEARCH 轻松指定要在其中搜索数据的列子集。以下查询会在 Logs 表的 Message 列中搜索值 94.60.64.181,并返回包含此值的行。
SELECT * FROM my_dataset.Logs WHERE SEARCH(Message, '`94.60.64.181`');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
以下查询会搜索 Logs 表的 Source 和 Message 列。它会返回任一列中包含值 94.60.64.181 的行。
SELECT * FROM my_dataset.Logs WHERE SEARCH((Source, Message), '`94.60.64.181`');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
从搜索中排除列
如果一个表包含许多列,并且您想要搜索其中的大部分列,则可以更轻松地指定要从搜索中排除的列。以下查询会搜索 Logs 表中 Message 列除外的所有列。它会返回任何列(包含值 94.60.64.181 的 Message 列除外)的行。
SELECT * FROM my_dataset.Logs WHERE SEARCH( (SELECT AS STRUCT Logs.* EXCEPT (Message)), '`94.60.64.181`');
+---------+----------------+---------------------------------------------------+ | Level | Source | Message | +---------+----------------+---------------------------------------------------+ | INFO | 94.60.64.181 | Entry Foo-Bar deleted | +---------+----------------+---------------------------------------------------+
使用其他文本分析器
以下示例会创建一个名为 contact_info 的表,其索引使用 NO_OP_ANALYZER 文本分析器:
CREATE TABLE my_dataset.contact_info (name STRING, email STRING) AS ( SELECT 'Kim Lee' AS name, 'kim.lee@example.com' AS email UNION ALL SELECT 'Kim' AS name, 'kim@example.com' AS email UNION ALL SELECT 'Sasha' AS name, 'sasha@example.com' AS email ); CREATE SEARCH INDEX noop_index ON my_dataset.contact_info(ALL COLUMNS) OPTIONS (analyzer = 'NO_OP_ANALYZER');
+---------+---------------------+ | name | email | +---------+---------------------+ | Kim Lee | kim.lee@example.com | | Kim | kim@example.com | | Sasha | sasha@example.com | +---------+---------------------+
以下查询会在 name 列中搜索 Kim,在 email 列中搜索 kim。
由于搜索索引不使用默认文本分析器,因此您必须将该分析器的名称传递给 SEARCH 函数。
SELECT name, SEARCH(name, 'Kim', analyzer=>'NO_OP_ANALYZER') AS name_Kim, email, SEARCH(email, 'kim', analyzer=>'NO_OP_ANALYZER') AS email_kim FROM my_dataset.contact_info;
NO_OP_ANALYZER 不会修改文本,因此 SEARCH 函数只会返回 TRUE 以找到完全匹配项:
+---------+----------+---------------------+-----------+ | name | name_Kim | email | email_kim | +---------+----------+---------------------+-----------+ | Kim Lee | FALSE | kim.lee@example.com | FALSE | | Kim | TRUE | kim@example.com | FALSE | | Sasha | FALSE | sasha@example.com | FALSE | +---------+----------+---------------------+-----------+
配置文本分析器选项
LOG_ANALYZER 和 PATTERN_ANALYZER 文本分析器可以通过向配置选项添加 JSON 格式的字符串来自定义。您可以在 SEARCH 函数、CREATE
SEARCH INDEX DDL 语句 和 TEXT_ANALYZE 函数。
以下示例会创建一个名为 complex_table 的表,其索引使用 LOG_ANALYZER 文本分析器。它使用 JSON 格式的字符串来配置分析器选项:
CREATE TABLE dataset.complex_table( a STRING, my_struct STRUCT<string_field STRING, int_field INT64>, b ARRAY<STRING> ); CREATE SEARCH INDEX my_index ON dataset.complex_table(a, my_struct, b) OPTIONS (analyzer = 'LOG_ANALYZER', analyzer_options = '''{ "token_filters": [ { "normalization": {"mode": "NONE"} } ] }''');
下表举例说明了使用不同文本分析器及其结果调用 SEARCH 函数的过程。第一个表使用默认文本分析器 LOG_ANALYZER 调用 SEARCH 函数:
| 函数调用 | 返回值 | 原因 |
|---|---|---|
| SEARCH('foobarexample', NULL) | 错误 | search_terms 为 `NULL`。 |
| SEARCH('foobarexample', '') | 错误 | search_terms 不包含令牌。 |
| SEARCH('foobar-example', 'foobar example') | TRUE | “-”和“ ”是分隔符。 |
| SEARCH('foobar-example', 'foobarexample') | FALSE | search_terms 并未拆分。 |
| SEARCH('foobar-example', 'foobar\\&example') | TRUE | 双反斜杠会对“&”符号进行转义,后者是分隔符。 |
| SEARCH('foobar-example', R'foobar\&example') | TRUE | 单反斜杠会对原始字符串中的“&”符号进行转义。 |
| SEARCH('foobar-example', '`foobar&example`') | FALSE | 反引号需要与 foobar&example 完全匹配。 |
| SEARCH('foobar&example', '`foobar&example`') | TRUE | 找到完全匹配的结果。 |
| SEARCH('foobar-example', 'example foobar') | TRUE | 字词的顺序无关紧要。 |
| SEARCH('foobar-example', 'foobar example') | TRUE | 词法单元设置为小写。 |
| SEARCH('foobar-example', '`foobar-example`') | TRUE | 找到完全匹配的结果。 |
| SEARCH('foobar-example', '`foobar`') | FALSE | 反引号保留大小写。 |
| SEARCH('`foobar-example`', '`foobar-example`') | FALSE | 反引号对于 data_to_search 和 |
| SEARCH('foobar@example.com', '`example.com`') | TRUE | 在 data_to_search 中的分隔符后面找到完全匹配项。 |
| SEARCH('a foobar-example b', '`foobar-example`') | TRUE | 可在空格分隔符之间找到完全匹配的内容。 |
| SEARCH(['foobar', 'example'], 'foobar example') | FALSE | 没有与所有搜索字词相匹配的单个数组条目。 |
| SEARCH('foobar=', '`foobar\\=`') | FALSE | search_terms 等同于 foobar\=。 |
| SEARCH('foobar=', R'`foobar\=`') | FALSE | 这等同于上一个示例。 |
| SEARCH('foobar=', 'foobar\\=') | TRUE | 等号是数据和查询中的分隔符。 |
| SEARCH('foobar=', R'foobar\=') | TRUE | 这等同于上一个示例。 |
| SEARCH('foobar.example', '`foobar`') | TRUE | 找到完全匹配的结果。 |
| SEARCH('foobar.example', '`foobar.`') | FALSE | 由于存在反引号,因此不会分析 `foobar.`;这不是 |
| SEARCH('foobar..example', '`foobar.`') | TRUE | 由于存在反引号,因此不会分析 `foobar.`;其后接 |
下表举例说明了使用 NO_OP_ANALYZER 文本分析器调用 SEARCH 函数以及各种返回值的原因:
| 函数调用 | 返回值 | 原因 |
|---|---|---|
| SEARCH('foobar', 'foobar', analyzer=>'NO_OP_ANALYZER') | TRUE | 找到完全匹配的结果。 |
| SEARCH('foobar', '`foobar`', analyzer=>'NO_OP_ANALYZER') | FALSE | 反引号不是 NO_OP_ANALYZER 的特殊字符。 |
| SEARCH('Foobar', 'foobar', analyzer=>'NO_OP_ANALYZER') | FALSE | 大小写不匹配。 |
| SEARCH('foobar example', 'foobar', analyzer=>'NO_OP_ANALYZER') | FALSE | NO_OP_ANALYZER 没有分隔符。 |
| SEARCH('', '', analyzer=>'NO_OP_ANALYZER') | TRUE | NO_OP_ANALYZER 没有分隔符。 |
其他运算符和函数
您可以使用多个运算符、函数和谓词执行搜索索引优化。
使用运算符和比较函数进行优化
BigQuery 可以优化某些使用等号运算符 (=)、IN 运算符、LIKE 运算符或 STARTS_WITH 函数的查询,以将字符串字面量与编入索引的数据进行比较。
使用字符串谓词进行优化
以下谓词符合搜索索引优化的条件:
column_name = 'string_literal''string_literal' = column_namestruct_column.nested_field = 'string_literal'string_array_column[OFFSET(0)] = 'string_literal'string_array_column[ORDINAL(1)] = 'string_literal'column_name IN ('string_literal1', 'string_literal2', ...)STARTS_WITH(column_name, 'prefix')column_name LIKE 'prefix%'
使用数字谓词进行优化
如果搜索索引是使用数字数据类型创建的,BigQuery 可以优化某些使用等号运算符 (=) 或 IN 运算符与编入索引的数据的查询。以下谓词符合搜索索引优化的条件:
INT64(json_column.int64_field) = 1int64_column = 1int64_array_column[OFFSET(0)] = 1int64_column IN (1, 2)struct_column.nested_int64_field = 1struct_column.nested_timestamp_field = TIMESTAMP "2024-02-15 21:31:40"timestamp_column = "2024-02-15 21:31:40"timestamp_column IN ("2024-02-15 21:31:40", "2024-02-16 21:31:40")
优化生成索引数据的函数
当某些函数应用于编入索引的数据时,BigQuery 支持搜索索引优化。如果搜索索引使用默认的 LOG_ANALYZER 文本分析器,则可以将 UPPER 或 LOWER 函数应用于列,例如 UPPER(column_name) = 'STRING_LITERAL'。
对于从编入索引的 JSON 列中提取的 JSON 标量字符串数据,您可以应用 STRING 函数或其安全版本 SAFE.STRING。如果提取的 JSON 值不是字符串,则 STRING 函数会产生错误,并且 SAFE.STRING 函数会返回 NULL。
对于编入索引的 JSON 格式的 STRING(非 JSON)数据,您可以应用以下函数:
例如,假设您有以下名为 dataset.person_data 的编入索引表,其中包含 JSON 和 STRING 列:
+----------------------------------------------------------------+-----------------------------------------+
| json_column | string_column |
+----------------------------------------------------------------+-----------------------------------------+
| { "name" : "Ariel", "email" : "cloudysanfrancisco@gmail.com" } | { "name" : "Ariel", "job" : "doctor" } |
+----------------------------------------------------------------+-----------------------------------------+
以下查询符合优化条件:
SELECT * FROM dataset.person_data WHERE SAFE.STRING(json_column.email) = 'cloudysanfrancisco@gmail.com';
SELECT * FROM dataset.person_data WHERE JSON_VALUE(string_column, '$.job') IN ('doctor', 'lawyer', 'teacher');
这些函数的组合也进行了优化,例如 UPPER(JSON_VALUE(json_string_expression)) = 'FOO'。
搜索索引使用情况
如需确定某一搜索索引是否用于查询,您可以查看作业详情或查询其中一个 INFORMATION_SCHEMA.JOBS* 视图。
查看作业详情
在查询结果的作业信息中,索引使用模式和索引未使用的原因字段提供有关搜索索引使用情况的详细信息。
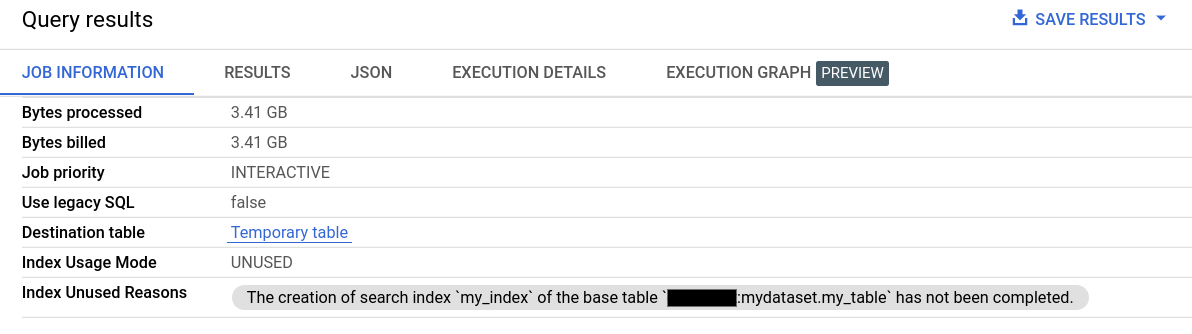
您还可以通过 Jobs.Get API 方法中的 searchStatistics 字段获取有关搜索索引使用情况的信息。searchStatistics 中的 indexUsageMode 字段通过以下值指示是否已使用某一搜索索引:
UNUSED:未使用搜索索引。PARTIALLY_USED:部分查询使用了搜索索引,而部分则未使用搜索索引。FULLY_USED:查询中的每个SEARCH函数都使用了一个搜索索引。
当 indexUsageMode 为 UNUSED 或 PARTIALLY_USED 时,indexUnusuedReasons 字段包含有关未在查询中使用搜索索引的原因的信息。
如需查看查询的 searchStatistics,请运行 bq show 命令。
bq show --format=prettyjson -j JOB_ID
示例
假设您运行一个查询来对表中的数据调用 SEARCH 函数。那么您可以查看查询的作业详情以查找作业 ID,然后运行 bq show 命令来查看更多信息:
bq show --format=prettyjson --j my_project:US.bquijob_123x456_789y123z456c
输出包含许多字段,包括 searchStatistics,如下所示。在此示例中,indexUsageMode 表示未使用索引。这是因为该表没有搜索索引。如需解决此问题,请在该表上创建搜索索引。请查看 indexUnusedReason code 字段,获取未在查询中使用搜索索引的所有可能原因的列表。
"searchStatistics": {
"indexUnusedReasons": [
{
"baseTable": {
"datasetId": "my_dataset",
"projectId": "my_project",
"tableId": "my_table"
},
"code": "INDEX_CONFIG_NOT_AVAILABLE",
"message": "There is no search index configuration for the base table `my_project:my_dataset.my_table`."
}
],
"indexUsageMode": "UNUSED"
},
查询 INFORMATION_SCHEMA 视图
您还可以在以下视图中查看某个区域中多个作业的搜索索引用量:
INFORMATION_SCHEMA.JOBSINFORMATION_SCHEMA.JOBS_BY_USERINFORMATION_SCHEMA.JOBS_BY_FOLDERINFORMATION_SCHEMA.JOBS_BY_ORGANIZATION
以下查询显示过去 7 天内所有可优化搜索索引的查询的索引用法信息:
SELECT job_id, search_statistics.index_usage_mode, index_unused_reason.code, index_unused_reason.base_table.table_id, index_unused_reason.index_name FROM `region-REGION_NAME`.INFORMATION_SCHEMA.JOBS, UNNEST(search_statistics.index_unused_reasons) AS index_unused_reason WHERE end_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY) AND CURRENT_TIMESTAMP();
结果类似于以下内容:
+-----------+----------------------------------------+-----------------------+ | job_id | index_usage_mode | code | table_id | index_name | +-----------+------------------+---------------------+-----------------------+ | bquxjob_1 | UNUSED | BASE_TABLE_TOO_SMALL| my_table | my_index | | bquxjob_2 | FULLY_USED | NULL | my_table | my_index | +-----------+----------------------------------------+-----------------------+
最佳做法
以下部分介绍了搜索的最佳实践。
选择性搜索
当搜索结果较少时,搜索的效果最佳。尽可能具体地进行搜索。
ORDER BY LIMIT 优化
在对分区字段使用 ORDER BY 子句以及 LIMIT 子句时,对非常大的分区表使用 SEARCH、=、IN、LIKE 或 STARTS_WITH 的查询可以优化。对于不包含 SEARCH 函数的查询,您可以使用其他运算符和函数来利用优化。无论表是否编入索引,都会应用优化。这在您搜索常用字词时效果良好。例如,假设之前创建的 Logs 表基于其他名为 day 的 DATE 类型列进行分区。以下查询经过了优化:
SELECT Level, Source, Message FROM my_dataset.Logs WHERE SEARCH(Message, "foo") ORDER BY day LIMIT 10;
限定搜索范围
使用 SEARCH 函数时,请仅搜索您希望包含搜索字词的表列。这可以提高性能并减少需要扫描的字节数。
使用英文反引号
将 SEARCH 函数与 LOG_ANALYZER 文本分析器结合使用时,用英文反引号将搜索查询括起来会强制执行完全匹配。如果搜索区分大小写,或包含不应解读为分隔符的字符,则此方法非常有用。例如,如需搜索 IP 地址 192.0.2.1,请使用 `192.0.2.1`。如果没有英文反引号,搜索会返回包含各个令牌 192、0、2 和 1(任意顺序)的任何行。