Pesquisar dados indexados
Nesta página, você encontra exemplos de pesquisa de dados de tabelas no BigQuery.
Quando você indexa seus dados, o BigQuery pode otimizar algumas consultas
que usam a função SEARCH
ou outras funções e operadores
como =, IN, LIKE e STARTS_WITH.
As consultas SQL retornam resultados corretos de todos os dados ingeridos, mesmo que alguns dos dados ainda não tenham sido indexados. No entanto, o desempenho da consulta pode ser muito melhorado com um índice. As economias em bytes processados e milissegundos de slot são maximizadas quando o número de resultados da pesquisa constitui uma fração relativamente pequena do total de linhas na sua tabela, porque menos dados são verificados. Para determinar se um índice foi usado para uma consulta, consulte Uso do índice de pesquisa.
Criar um índice de pesquisa.
A tabela a seguir, chamada Logs, é usada para mostrar maneiras diferentes de usar a função SEARCH. Esta tabela de exemplo é bem pequena, mas, na
prática, os ganhos de desempenho que você consegue com SEARCH melhoram com o tamanho da tabela.
CREATE TABLE my_dataset.Logs (Level STRING, Source STRING, Message STRING) AS ( SELECT 'INFO' as Level, '65.177.8.234' as Source, 'Entry Foo-Bar created' as Message UNION ALL SELECT 'WARNING', '132.249.240.10', 'Entry Foo-Bar already exists, created by 65.177.8.234' UNION ALL SELECT 'INFO', '94.60.64.181', 'Entry Foo-Bar deleted' UNION ALL SELECT 'SEVERE', '4.113.82.10', 'Entry Foo-Bar does not exist, deleted by 94.60.64.181' UNION ALL SELECT 'INFO', '181.94.60.64', 'Entry Foo-Baz created' );
A tabela tem esta aparência:
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 65.177.8.234 | Entry Foo-Bar created | | WARNING | 132.249.240.10 | Entry Foo-Bar already exists, created by 65.177.8.234 | | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | | INFO | 181.94.60.64 | Entry Foo-Baz created | +---------+----------------+-------------------------------------------------------+
Crie um índice de pesquisa na tabela Logs usando o analisador de texto padrão:
CREATE SEARCH INDEX my_index ON my_dataset.Logs(ALL COLUMNS);
Saiba mais sobre índices de pesquisa em Gerenciar índices de pesquisa.
Usar a função SEARCH
A função SEARCH faz uma pesquisa tokenizada nos dados.
SEARCH foi projetado para ser usado com um índice para
otimizar as pesquisas.
Use a função SEARCH para pesquisar uma tabela inteira ou restringir sua pesquisa a colunas específicas.
Pesquisar uma tabela inteira
A consulta a seguir pesquisa o valor bar em todas as colunas
da tabela Logs e retorna as linhas que contêm esse valor, independentemente do
uso de letras maiúsculas. Como o índice de pesquisa usa o analisador de texto padrão, não
é necessário especificá-lo na função SEARCH.
SELECT * FROM my_dataset.Logs WHERE SEARCH(Logs, 'bar');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 65.177.8.234 | Entry Foo-Bar created | | WARNING | 132.249.240.10 | Entry Foo-Bar already exists, created by 65.177.8.234 | | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
A consulta a seguir procura o valor `94.60.64.181` em todas as colunas da tabela Logs e retorna as linhas que contêm esse valor. Os
acentos graves permitem uma pesquisa exata. Por isso, a última linha da tabela
Logs que contém 181.94.60.64 é omitida.
SELECT * FROM my_dataset.Logs WHERE SEARCH(Logs, '`94.60.64.181`');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
Pesquisar um subconjunto de colunas
SEARCH facilita a especificação de um subconjunto de colunas para a pesquisa de
dados. A consulta a seguir pesquisa a coluna Message da tabela Logs em busca do
valor 94.60.64.181 e retorna as linhas que contêm esse valor.
SELECT * FROM my_dataset.Logs WHERE SEARCH(Message, '`94.60.64.181`');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
A consulta a seguir pesquisa as colunas Source e Message da
tabela Logs. Ele retorna as linhas que contêm o valor 94.60.64.181 de
qualquer uma das colunas.
SELECT * FROM my_dataset.Logs WHERE SEARCH((Source, Message), '`94.60.64.181`');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
Excluir colunas de uma pesquisa
Se uma tabela de tabela tiver muitas colunas e você quiser pesquisar a maioria delas, talvez seja
mais fácil especificar apenas as colunas a serem excluídas da pesquisa. A consulta
a seguir pesquisa em todas as colunas da tabela Logs, exceto
na coluna Message. Ela retorna as linhas de qualquer coluna diferente de Message
que contenha o valor 94.60.64.181.
SELECT * FROM my_dataset.Logs WHERE SEARCH( (SELECT AS STRUCT Logs.* EXCEPT (Message)), '`94.60.64.181`');
+---------+----------------+---------------------------------------------------+ | Level | Source | Message | +---------+----------------+---------------------------------------------------+ | INFO | 94.60.64.181 | Entry Foo-Bar deleted | +---------+----------------+---------------------------------------------------+
Usar um analisador de texto diferente
O exemplo a seguir cria uma tabela chamada contact_info com um índice que
usa o analisador de texto
NO_OP_ANALYZER:
CREATE TABLE my_dataset.contact_info (name STRING, email STRING) AS ( SELECT 'Kim Lee' AS name, 'kim.lee@example.com' AS email UNION ALL SELECT 'Kim' AS name, 'kim@example.com' AS email UNION ALL SELECT 'Sasha' AS name, 'sasha@example.com' AS email ); CREATE SEARCH INDEX noop_index ON my_dataset.contact_info(ALL COLUMNS) OPTIONS (analyzer = 'NO_OP_ANALYZER');
+---------+---------------------+ | name | email | +---------+---------------------+ | Kim Lee | kim.lee@example.com | | Kim | kim@example.com | | Sasha | sasha@example.com | +---------+---------------------+
A consulta a seguir pesquisa Kim na coluna name e kim
na coluna email.
Como o índice de pesquisa não usa o analisador de texto padrão, é necessário transmitir o
nome do analisador para a função SEARCH.
SELECT name, SEARCH(name, 'Kim', analyzer=>'NO_OP_ANALYZER') AS name_Kim, email, SEARCH(email, 'kim', analyzer=>'NO_OP_ANALYZER') AS email_kim FROM my_dataset.contact_info;
O NO_OP_ANALYZER não modifica o texto. Portanto, a função SEARCH retorna
apenas TRUE para correspondências exatas:
+---------+----------+---------------------+-----------+ | name | name_Kim | email | email_kim | +---------+----------+---------------------+-----------+ | Kim Lee | FALSE | kim.lee@example.com | FALSE | | Kim | TRUE | kim@example.com | FALSE | | Sasha | FALSE | sasha@example.com | FALSE | +---------+----------+---------------------+-----------+
Configurar opções do analisador de texto
Os analisadores de
texto LOG_ANALYZER e PATTERN_ANALYZER podem ser
personalizados adicionando uma string formatada em JSON às opções de configuração. É possível
configurar analisadores de texto na função
SEARCH, na instrução DDL
CREATE
SEARCH INDEX
e na TEXT_ANALYZE.
O exemplo a seguir cria uma tabela chamada complex_table com um índice que
usa o analisador de texto
LOG_ANALYZER: Ele usa uma string formatada em JSON para
configurar as opções do analisador:
CREATE TABLE dataset.complex_table( a STRING, my_struct STRUCT<string_field STRING, int_field INT64>, b ARRAY<STRING> ); CREATE SEARCH INDEX my_index ON dataset.complex_table(a, my_struct, b) OPTIONS (analyzer = 'LOG_ANALYZER', analyzer_options = '''{ "token_filters": [ { "normalization": {"mode": "NONE"} } ] }''');
As tabelas a seguir mostram exemplos de chamadas para a função SEARCH com
diferentes analisadores de texto e os respectivos resultados. A primeira tabela chama a função SEARCH
usando o analisador de texto padrão, o LOG_ANALYZER:
| Chamada de função | Retorna | Motivo |
|---|---|---|
| SEARCH('foobarexample', NULL) | ERRO | O search_terms é `NULL`. |
| SEARCH('foobarexample', '') | ERRO | O "search_terms" não contém tokens. |
| SEARCH('foobar-example', 'foobar example') | VERDADEIRO | "-" e " " são delimitadores. |
| SEARCH('foobar-example', 'foobarexample') | FALSO | Os search_terms não são divididos. |
| SEARCH('foobar-exemplo', 'foobar\\&example') | VERDADEIRO | A barra invertida dupla faz o escape do E comercial, que é um delimitador. |
| SEARCH('foobar-exemplo', R'foobar\&example') | VERDADEIRO | Essa barra invertida faz o escape do "e" comercial em uma string bruta. |
| SEARCH('foobar-exemplo', '`foobar&example`') | FALSO | Os acentos graves exigem uma correspondência exata para foobar&example. |
| SEARCH('foobar&example', '`foobar&example`') | VERDADEIRO | Uma correspondência exata é encontrada. |
| SEARCH('foobar-example', 'exemplo foobar') | VERDADEIRO | A ordem dosprefixos não importa. |
| SEARCH('foobar-example', 'foobar example') | VERDADEIRO | Os tokens ficam em letras minúsculas. |
| SEARCH('foobar-example', '`foobar-example`') | VERDADEIRO | Uma correspondência exata é encontrada. |
| SEARCH('foobar-example', '`foobar`') | FALSO | Acentos graves preservam as letras maiúsculas. |
| SEARCH('`foobar-example`', '`foobar-example`') | FALSO | Acentos graves não têm significado especial para data_to_search e |
| SEARCH('foobar@exemplo.com', '`exemplo.com`') | VERDADEIRO | É encontrada uma correspondência exata após o delimitador em data_to_search. |
| SEARCH('a foobar-example b', '`foobar-example`') | VERDADEIRO | Uma correspondência exata é encontrada entre os delimitadores de espaço. |
| SEARCH(['foobar', 'example'], 'foobar example') | FALSO | Nenhuma entrada de matriz corresponde a todos os termos de pesquisa. |
| SEARCH('foobar=', '`foobar\\=`') | FALSO | Search_terms é equivalente a foobar\=. |
| SEARCH('foobar=', R'`foobar\=`') | FALSO | Isso é equivalente ao exemplo anterior. |
| SEARCH('foobar=', 'foobar\\=') | VERDADEIRO | O sinal de igual é um delimitador nos dados e na consulta. |
| SEARCH('foobar=', R'foobar\=') | VERDADEIRO | Isso é equivalente ao exemplo anterior. |
| SEARCH('foobar.example', '`foobar`') | VERDADEIRO | Uma correspondência exata é encontrada. |
| SEARCH('foobar.example', '`foobar.`') | FALSO | `foobar.` não é analisado devido a acentos graves. não está |
| SEARCH('foobar..example', '`foobar.`') | VERDADEIRO | `foobar.` não é analisado devido a acentos graves. é seguido |
A tabela a seguir mostra exemplos de chamadas para a função SEARCH usando o
analisador de texto NO_OP_ANALYZER e os motivos de vários valores de retorno:
| Chamada de função | Retorna | Motivo |
|---|---|---|
| SEARCH('foobar', 'foobar', Analyzer=>'NO_OP_ANALYZER') | VERDADEIRO | Uma correspondência exata é encontrada. |
| SEARCH('foobar', '`foobar`', Analyzer=>'NO_OP_ANALYZER') | FALSO | Acentos graves não são caracteres especiais para NO_OP_ANALYZER. |
| SEARCH('Foobar', 'foobar', Analyzer=>'NO_OP_ANALYZER') | FALSO | As letras maiúsculas não correspondem. |
| SEARCH('exemplo de foobar', 'foobar', analyzer=>'NO_OP_ANALYZER') | FALSO | Não há delimitadores para NO_OP_ANALYZER. |
| SEARCH('', '', Analyzer=>'NO_OP_ANALYZER') | VERDADEIRO | Não há delimitadores para NO_OP_ANALYZER. |
Outros operadores e funções
É possível realizar otimizações de índice de pesquisa com vários operadores, funções e predicados.
Otimizar com operadores e funções de comparação
O BigQuery pode otimizar algumas consultas que usam o
operador igual
(=),
o operador IN,
o operador LIKE
ou a
função STARTS_WITH
para comparar literais de string com dados indexados.
Otimizar com predicados de string
Os seguintes predicados estão qualificados para otimização do índice de pesquisa:
column_name = 'string_literal''string_literal' = column_namestruct_column.nested_field = 'string_literal'string_array_column[OFFSET(0)] = 'string_literal'string_array_column[ORDINAL(1)] = 'string_literal'column_name IN ('string_literal1', 'string_literal2', ...)STARTS_WITH(column_name, 'prefix')column_name LIKE 'prefix%'
Otimizar com predicados numéricos
Se o índice de pesquisa tiver sido criado com tipos de dados numéricos, o BigQuery
poderá otimizar algumas consultas que usam o operador de igualdade (=) ou o operador IN
com dados indexados. Os seguintes predicados estão qualificados para otimização do índice de pesquisa:
INT64(json_column.int64_field) = 1int64_column = 1int64_array_column[OFFSET(0)] = 1int64_column IN (1, 2)struct_column.nested_int64_field = 1struct_column.nested_timestamp_field = TIMESTAMP "2024-02-15 21:31:40"timestamp_column = "2024-02-15 21:31:40"timestamp_column IN ("2024-02-15 21:31:40", "2024-02-16 21:31:40")
Otimizar funções que produzem dados indexados
O BigQuery oferece suporte à otimização do índice de pesquisa quando determinadas funções são aplicadas a dados indexados.
Se o índice de pesquisa usar o analisador de texto LOG_ANALYZER padrão, será possível
aplicar as funções
UPPER
ou LOWER à coluna, como UPPER(column_name) = 'STRING_LITERAL'.
Nos dados de string JSON escalar extraídos de uma coluna JSON indexada, é possível
aplicar a função STRING
ou a versão segura dela,
SAFE.STRING.
Se o valor JSON extraído não for uma string, a função STRING
vai produzir um erro e a função SAFE.STRING retornará NULL.
Para dados STRING (e não JSON) formatados em JSON indexados, é possível aplicar as seguintes funções:
Por exemplo, suponha que você tenha a seguinte tabela indexada chamada
dataset.person_data com uma coluna JSON e uma STRING:
+----------------------------------------------------------------+-----------------------------------------+
| json_column | string_column |
+----------------------------------------------------------------+-----------------------------------------+
| { "name" : "Ariel", "email" : "cloudysanfrancisco@gmail.com" } | { "name" : "Ariel", "job" : "doctor" } |
+----------------------------------------------------------------+-----------------------------------------+
As seguintes consultas estão qualificadas para otimização:
SELECT * FROM dataset.person_data WHERE SAFE.STRING(json_column.email) = 'cloudysanfrancisco@gmail.com';
SELECT * FROM dataset.person_data WHERE JSON_VALUE(string_column, '$.job') IN ('doctor', 'lawyer', 'teacher');
As combinações dessas funções também são otimizadas, como
UPPER(JSON_VALUE(json_string_expression)) = 'FOO'.
Uso do índice de pesquisa
Para determinar se um índice de pesquisa foi usado para uma consulta, acesse os
detalhes do job ou consulte uma das visualizações INFORMATION_SCHEMA.JOBS*.
Mais detalhes do job
Em Informações do job dos resultados da consulta, os campos Modo de uso do índice e Motivos não usados do índice fornecem informações detalhadas sobre o uso do índice de pesquisa.
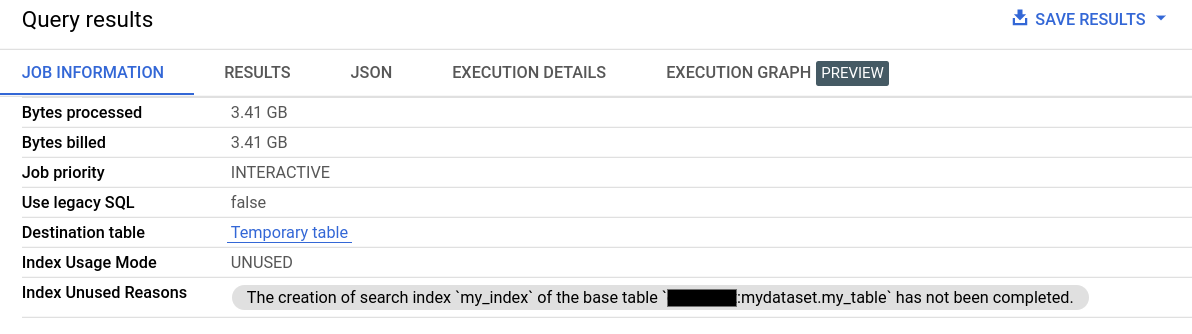
As informações sobre o uso do índice de pesquisa também estão disponíveis no
campo searchStatistics
no método da API Jobs.Get. O
campo indexUsageMode em searchStatistics indica se um índice de pesquisa
foi usado com os seguintes valores:
UNUSED: nenhum índice de pesquisa foi usado.PARTIALLY_USED: parte da consulta usou índices de pesquisa e parte não.FULLY_USED: cada funçãoSEARCHna consulta usou um índice de pesquisa.
Quando indexUsageMode é UNUSED ou PARTIALLY_USED, o campo indexUnusuedReasons
contém informações sobre por que os índices de pesquisa não foram usados na consulta.
Para ver searchStatistics de uma consulta, execute o comando bq show.
bq show --format=prettyjson -j JOB_ID
Exemplo
Imagine que você execute uma consulta que chama a função SEARCH nos dados de uma tabela. É possível
visualizar os
detalhes do job da consulta para
encontrar o ID do job e, em seguida, executar o comando bq show para ver mais informações:
bq show --format=prettyjson --j my_project:US.bquijob_123x456_789y123z456c
A saída contém muitos campos, incluindo searchStatistics, que é
parecido com o seguinte. Neste exemplo, indexUsageMode indica que o
índice não foi usado. Isso acontece quando a tabela não tem um índice de pesquisa. Para
resolver esse problema, crie um índice de pesquisa na
tabela. Consulte o
indexUnusedReason campo code
para ver uma lista de todos os motivos pelos quais um índice de pesquisa pode não ser usado em uma consulta.
"searchStatistics": {
"indexUnusedReasons": [
{
"baseTable": {
"datasetId": "my_dataset",
"projectId": "my_project",
"tableId": "my_table"
},
"code": "INDEX_CONFIG_NOT_AVAILABLE",
"message": "There is no search index configuration for the base table `my_project:my_dataset.my_table`."
}
],
"indexUsageMode": "UNUSED"
},
Consultar visualizações INFORMATION_SCHEMA
Também é possível conferir o uso do índice de pesquisa para vários jobs em uma região nas seguintes visualizações:
INFORMATION_SCHEMA.JOBSINFORMATION_SCHEMA.JOBS_BY_USERINFORMATION_SCHEMA.JOBS_BY_FOLDERINFORMATION_SCHEMA.JOBS_BY_ORGANIZATION
A consulta a seguir mostra informações sobre o uso do índice para todas as consultas otimizadas do índice de pesquisa nos últimos sete dias:
SELECT job_id, search_statistics.index_usage_mode, index_unused_reason.code, index_unused_reason.base_table.table_id, index_unused_reason.index_name FROM `region-REGION_NAME`.INFORMATION_SCHEMA.JOBS, UNNEST(search_statistics.index_unused_reasons) AS index_unused_reason WHERE end_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY) AND CURRENT_TIMESTAMP();
O resultado será semelhante ao seguinte:
+-----------+----------------------------------------+-----------------------+ | job_id | index_usage_mode | code | table_id | index_name | +-----------+------------------+---------------------+-----------------------+ | bquxjob_1 | UNUSED | BASE_TABLE_TOO_SMALL| my_table | my_index | | bquxjob_2 | FULLY_USED | NULL | my_table | my_index | +-----------+----------------------------------------+-----------------------+
Práticas recomendadas
As seções a seguir descrevem as práticas recomendadas para pesquisar.
Pesquisar seletivamente
A pesquisa funciona melhor quando a pesquisa tem poucos resultados. Torne as pesquisas o mais específicas possível.
Otimização da função ORDER BY LIMIT
As consultas que usam SEARCH, =, IN, LIKE ou STARTS_WITH em uma tabela
particionada muito grande podem ser otimizadas
quando você vai usar uma cláusula ORDER BY no campo particionado e uma cláusula LIMIT.
Para consultas que não contêm a função SEARCH, é possível usar os
outros operadores e funções para
aproveitar a otimização. A otimização será aplicada mesmo que a tabela base
não seja indexada. Isso funciona bem se você estiver procurando um termo comum.
Por exemplo, suponha que a tabela Logs criada anteriormente
seja particionada em uma coluna do tipo DATE adicional
chamada day. A consulta a seguir é otimizada:
SELECT Level, Source, Message FROM my_dataset.Logs WHERE SEARCH(Message, "foo") ORDER BY day LIMIT 10;
Defina o escopo da sua pesquisa
Quando você usar a função SEARCH, pesquise somente as colunas da tabela que devem conter os termos de pesquisa. Isso melhora o desempenho e
reduz o número de bytes que precisam ser verificados.
Use crase
Quando você usa a função SEARCH com o analisador de texto LOG_ANALYZER,
incluir a consulta de pesquisa entre crases
força uma correspondência exata. Isso é útil
quando a pesquisa diferencia maiúsculas de minúsculas ou contém caracteres que não devem ser
interpretados como delimitadores. Por exemplo, para pesquisar o endereço IP
192.0.2.1, use `192.0.2.1`. Sem as crases, a pesquisa retorna qualquer linha que
contenha os tokens individuais 192, 0, 2 e 1, em qualquer ordem.