Effectuer une recherche sur des données indexées
Cette page fournit des exemples de recherche de données de table dans BigQuery.
Lorsque vous indexez vos données, BigQuery peut optimiser certaines requêtes qui utilisent la fonction SEARCH ou d'autres fonctions et opérateurs, par exemple =, IN, LIKE et STARTS_WITH.
Les requêtes SQL renvoient des résultats corrects à partir de toutes les données ingérées, même si certaines des données ne sont pas encore indexées. Toutefois, les performances des requêtes peuvent être considérablement améliorées avec un index. Les économies en octets traités et en millisecondes d'emplacement sont maximisées lorsque le nombre de résultats de recherche représente une fraction relativement faible du total de lignes dans votre table, car le volume de données analysées est moindre. Pour déterminer si un index a été utilisé pour une requête, consultez la section Utilisation des index de recherche.
créer un index de recherche ;
La table suivante, appelée Logs, permet de présenter différentes manières d'utiliser la fonction SEARCH. Cet exemple de table est assez petit, mais en pratique, les gains de performances obtenus avec SEARCH s'améliorent en fonction de la taille de la table.
CREATE TABLE my_dataset.Logs (Level STRING, Source STRING, Message STRING) AS ( SELECT 'INFO' as Level, '65.177.8.234' as Source, 'Entry Foo-Bar created' as Message UNION ALL SELECT 'WARNING', '132.249.240.10', 'Entry Foo-Bar already exists, created by 65.177.8.234' UNION ALL SELECT 'INFO', '94.60.64.181', 'Entry Foo-Bar deleted' UNION ALL SELECT 'SEVERE', '4.113.82.10', 'Entry Foo-Bar does not exist, deleted by 94.60.64.181' UNION ALL SELECT 'INFO', '181.94.60.64', 'Entry Foo-Baz created' );
La table ressemble à ceci :
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 65.177.8.234 | Entry Foo-Bar created | | WARNING | 132.249.240.10 | Entry Foo-Bar already exists, created by 65.177.8.234 | | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | | INFO | 181.94.60.64 | Entry Foo-Baz created | +---------+----------------+-------------------------------------------------------+
Créez un index de recherche sur la table Logs à l'aide de l'analyseur de texte par défaut :
CREATE SEARCH INDEX my_index ON my_dataset.Logs(ALL COLUMNS);
Pour en savoir plus sur les index de recherche, consultez la page Gérer les index de recherche.
Utiliser la fonction SEARCH
La fonction SEARCH fournit une recherche tokenisée sur les données.
SEARCH est conçu pour être utilisé avec un index, afin d'optimiser les recherches.
Vous pouvez utiliser la fonction SEARCH pour effectuer une recherche dans une table entière, ou limiter votre recherche à des colonnes spécifiques.
Effectuer des recherches dans une table entière
La requête suivante recherche la valeur bar dans toutes les colonnes de la table Logs et renvoie les lignes contenant cette valeur, quelle que soit l'utilisation des majuscules. Étant donné que l'index de recherche utilise l'analyseur de texte par défaut, vous n'avez pas besoin de le spécifier dans la fonction SEARCH.
SELECT * FROM my_dataset.Logs WHERE SEARCH(Logs, 'bar');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 65.177.8.234 | Entry Foo-Bar created | | WARNING | 132.249.240.10 | Entry Foo-Bar already exists, created by 65.177.8.234 | | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
La requête suivante recherche la valeur `94.60.64.181` dans toutes les colonnes de la table Logs et renvoie les lignes contenant cette valeur. Les accents graves permettent d'effectuer une recherche exacte. C'est pourquoi la dernière ligne de la table Logs contenant 181.94.60.64 est omise.
SELECT * FROM my_dataset.Logs WHERE SEARCH(Logs, '`94.60.64.181`');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
Effectuer des recherches dans un sous-ensemble de colonnes
SEARCH facilite la spécification d'un sous-ensemble de colonnes dans lequel rechercher des données. La requête suivante recherche la valeur 94.60.64.181 dans la colonne Message de la table Logs et renvoie les lignes contenant cette valeur.
SELECT * FROM my_dataset.Logs WHERE SEARCH(Message, '`94.60.64.181`');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
La requête suivante effectue une recherche à la fois sur les colonnes Source et Message de la table Logs. Elle renvoie les lignes contenant la valeur 94.60.64.181 de l'une des colonnes.
SELECT * FROM my_dataset.Logs WHERE SEARCH((Source, Message), '`94.60.64.181`');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
Exclure des colonnes d'une recherche
Si une table comporte plusieurs colonnes et que vous souhaitez effectuer une recherche sur la plupart d'entre elles, il peut être plus facile de ne spécifier que les colonnes à exclure de la recherche. La requête ci-dessous recherche dans toutes les colonnes de la table Logs, à l'exception de la colonne Message. Elle renvoie les lignes de toutes les colonnes autres que Message contenant la valeur 94.60.64.181.
SELECT * FROM my_dataset.Logs WHERE SEARCH( (SELECT AS STRUCT Logs.* EXCEPT (Message)), '`94.60.64.181`');
+---------+----------------+---------------------------------------------------+ | Level | Source | Message | +---------+----------------+---------------------------------------------------+ | INFO | 94.60.64.181 | Entry Foo-Bar deleted | +---------+----------------+---------------------------------------------------+
Utiliser un autre analyseur de texte
L'exemple suivant crée une table appelée contact_info avec un index qui utilise l'analyseur de texte NO_OP_ANALYZER :
CREATE TABLE my_dataset.contact_info (name STRING, email STRING) AS ( SELECT 'Kim Lee' AS name, 'kim.lee@example.com' AS email UNION ALL SELECT 'Kim' AS name, 'kim@example.com' AS email UNION ALL SELECT 'Sasha' AS name, 'sasha@example.com' AS email ); CREATE SEARCH INDEX noop_index ON my_dataset.contact_info(ALL COLUMNS) OPTIONS (analyzer = 'NO_OP_ANALYZER');
+---------+---------------------+ | name | email | +---------+---------------------+ | Kim Lee | kim.lee@example.com | | Kim | kim@example.com | | Sasha | sasha@example.com | +---------+---------------------+
La requête suivante recherche Kim dans la colonne name et kim dans la colonne email.
Étant donné que l'index de recherche n'utilise pas l'analyseur de texte par défaut, vous devez transmettre le nom de l'analyseur à la fonction SEARCH.
SELECT name, SEARCH(name, 'Kim', analyzer=>'NO_OP_ANALYZER') AS name_Kim, email, SEARCH(email, 'kim', analyzer=>'NO_OP_ANALYZER') AS email_kim FROM my_dataset.contact_info;
NO_OP_ANALYZER ne modifie pas le texte. Par conséquent, la fonction SEARCH ne renvoie TRUE que pour les correspondances exactes :
+---------+----------+---------------------+-----------+ | name | name_Kim | email | email_kim | +---------+----------+---------------------+-----------+ | Kim Lee | FALSE | kim.lee@example.com | FALSE | | Kim | TRUE | kim@example.com | FALSE | | Sasha | FALSE | sasha@example.com | FALSE | +---------+----------+---------------------+-----------+
Configurer les options des analyseurs de texte
Les analyseurs de texte LOG_ANALYZER et PATTERN_ANALYZER peuvent être personnalisés en ajoutant une chaîne au format JSON aux options de configuration. Vous pouvez configurer des analyseurs de texte dans la fonction SEARCH, dans l'instruction LDD CREATE
SEARCH INDEX, et dans la fonction TEXT_ANALYZE.
L'exemple suivant crée une table appelée complex_table avec un index qui utilise l'analyseur de texte LOG_ANALYZER. Il utilise une chaîne au format JSON pour configurer les options de l'analyseur :
CREATE TABLE dataset.complex_table( a STRING, my_struct STRUCT<string_field STRING, int_field INT64>, b ARRAY<STRING> ); CREATE SEARCH INDEX my_index ON dataset.complex_table(a, my_struct, b) OPTIONS (analyzer = 'LOG_ANALYZER', analyzer_options = '''{ "token_filters": [ { "normalization": {"mode": "NONE"} } ] }''');
Le tableau suivant présente des exemples d'appels à la fonction SEARCH avec différents analyseurs de texte et leurs résultats. La première table appelle la fonction SEARCH à l'aide de l'analyseur de texte par défaut, LOG_ANALYZER :
| Appel de fonction | Renvoie | Motif |
|---|---|---|
| SEARCH('foobarexample', NULL) | ERREUR | La valeur du champ search_terms est "NULL". |
| SEARCH('foobarexample', '') | ERREUR | La variable search_terms ne contient aucun jeton. |
| SEARCH('foobar-example', 'foobar example') | TRUE | '-' et ' ' sont des délimiteurs. |
| SEARCH('foobar-example', 'foobarexample') | FAUX | La variable search_terms n'est pas séparée. |
| SEARCH('foobar-example', 'foobar\\&example') | TRUE | La double barre oblique inverse échappe l'esperluette, qui est un délimiteur. |
| SEARCH('foobar-example', R'foobar\&example') | TRUE | La barre oblique inverse unique échappe l'esperluette dans une chaîne brute. |
| SEARCH('foobar-example', '`foobar&example`') | FAUX | Les accents graves nécessitent une correspondance exacte pour foobar&example. |
| SEARCH('foobar&example', '`foobar&example`') | TRUE | Une correspondance exacte est trouvée. |
| SEARCH('foobar-example', 'example foobar') | TRUE | L'ordre des termes n'a pas d'importance. |
| SEARCH('foobar-example', 'foobar example') | TRUE | Les jetons sont mis en minuscules. |
| SEARCH('foobar-example', '`foobar-example`') | TRUE | Une correspondance exacte est trouvée. |
| SEARCH('foobar-example', '`foobar`') | FAUX | Les accents graves conservent la casse. |
| SEARCH('`foobar-example`', '`foobar-example`') | FAUX | Les accents graves n'ont pas de signification particulière pour data_to_search et |
| SEARCH('foobar@example.com', '`example.com`') | TRUE | Une correspondance exacte est trouvée après le délimiteur dans data_to_search. |
| SEARCH('a foobar-example b', '`foobar-example`') | TRUE | Une correspondance exacte est trouvée entre les délimiteurs d'espace. |
| SEARCH(['foobar', 'example'], 'foobar example') | FAUX | Aucune entrée du tableau ne correspond à tous les termes de recherche. |
| SEARCH('foobar=', '`foobar\\=`') | FAUX | La valeur de search_terms est équivalente à foobar\=. |
| SEARCH('foobar=', R'`foobar\=`') | FAUX | Cela équivaut à l'exemple précédent. |
| SEARCH('foobar=', 'foobar\\=') | TRUE | Le signe égal est un délimiteur dans les données et la requête. |
| SEARCH('foobar=', R'foobar\=') | TRUE | Cela équivaut à l'exemple précédent. |
| SEARCH('foobar.example', '`foobar`') | TRUE | Une correspondance exacte est trouvée. |
| SEARCH('foobar.example', '`foobar.`') | FAUX | "foobar." n'est pas analysé en raison d'accents graves, il n'est pas |
| SEARCH('foobar..example', '`foobar.`') | TRUE | "foobar." n'est pas analysé en raison d'accents graves, il est suivi |
Le tableau suivant présente des exemples d'appels à la fonction SEARCH à l'aide de l'analyseur de texte NO_OP_ANALYZER et les raisons de diverses valeurs de retour :
| Appel de fonction | Renvoie | Motif |
|---|---|---|
| SEARCH('foobar', 'foobar', analyzer=>'NO_OP_ANALYZER') | TRUE | Une correspondance exacte est trouvée. |
| SEARCH('foobar', '`foobar`', analyzer=>'NO_OP_ANALYZER') | FAUX | Les accents graves ne sont pas des caractères spéciaux pour NO_OP_ANALYZER. |
| SEARCH('Foobar', 'foobar', analyzer=>'NO_OP_ANALYZER') | FALSE | L'utilisation de la casse ne correspond pas. |
| SEARCH('foobar example', 'foobar', analyzer=>'NO_OP_ANALYZER') | FAUX | Il n'existe aucun délimiteur pour NO_OP_ANALYZER. |
| SEARCH('', '', analyzer=>'NO_OP_ANALYZER') | TRUE | Il n'existe aucun délimiteur pour NO_OP_ANALYZER. |
Autres opérateurs et fonctions
Vous pouvez effectuer des optimisations de l'index de recherche avec plusieurs opérateurs, fonctions et prédicats.
Optimiser avec des opérateurs et des fonctions de comparaison
BigQuery peut optimiser certaines requêtes utilisant l'opérateur égal (=), l'opérateur IN, l'opérateur LIKE ou la fonction STARTS_WITH pour comparer des littéraux de chaîne à des données indexées.
Optimiser avec des prédicats de chaîne
Les prédicats suivants sont éligibles à l'optimisation de l'index de recherche :
column_name = 'string_literal''string_literal' = column_namestruct_column.nested_field = 'string_literal'string_array_column[OFFSET(0)] = 'string_literal'string_array_column[ORDINAL(1)] = 'string_literal'column_name IN ('string_literal1', 'string_literal2', ...)STARTS_WITH(column_name, 'prefix')column_name LIKE 'prefix%'
Optimiser avec des prédicats numériques
Si l'index de recherche a été créé avec des types de données numériques, BigQuery peut optimiser certaines requêtes qui utilisent l'opérateur égal (=) ou l'opérateur IN avec des données indexées. Les prédicats suivants sont éligibles à l'optimisation de l'index de recherche :
INT64(json_column.int64_field) = 1int64_column = 1int64_array_column[OFFSET(0)] = 1int64_column IN (1, 2)struct_column.nested_int64_field = 1struct_column.nested_timestamp_field = TIMESTAMP "2024-02-15 21:31:40"timestamp_column = "2024-02-15 21:31:40"timestamp_column IN ("2024-02-15 21:31:40", "2024-02-16 21:31:40")
Optimiser les fonctions qui produisent des données indexées
BigQuery permet l'optimisation de l'index de recherche lorsque certaines fonctions sont appliquées aux données indexées.
Si l'index de recherche utilise l'analyseur de texte LOG_ANALYZER par défaut, vous pouvez appliquer les fonctions UPPER ou LOWER à la colonne, par exemple UPPER(column_name) = 'STRING_LITERAL'.
Pour les données de type chaîne scalaire JSON, extraites d'une colonne JSON indexée, vous pouvez appliquer la fonction STRING, ou bien sa version sécurisée, SAFE.STRING.
Si la valeur JSON extraite n'est pas une chaîne, la fonction STRING génère une erreur et la fonction SAFE.STRING renvoie NULL.
Pour les données STRING indexées et au format JSON (et non pas les données JSON à proprement parler), vous pouvez appliquer les fonctions suivantes :
Par exemple, supposons que vous disposiez de la table indexée suivante, appelée dataset.person_data, avec une colonne JSON et une colonne STRING :
+----------------------------------------------------------------+-----------------------------------------+
| json_column | string_column |
+----------------------------------------------------------------+-----------------------------------------+
| { "name" : "Ariel", "email" : "cloudysanfrancisco@gmail.com" } | { "name" : "Ariel", "job" : "doctor" } |
+----------------------------------------------------------------+-----------------------------------------+
Les requêtes suivantes sont éligibles à l'optimisation :
SELECT * FROM dataset.person_data WHERE SAFE.STRING(json_column.email) = 'cloudysanfrancisco@gmail.com';
SELECT * FROM dataset.person_data WHERE JSON_VALUE(string_column, '$.job') IN ('doctor', 'lawyer', 'teacher');
Les combinaisons de ces fonctions, telles que UPPER(JSON_VALUE(json_string_expression)) = 'FOO', vont également être optimisées.
Utiliser l'index de recherche
Pour déterminer si un index de recherche a été utilisé pour une requête, vous pouvez afficher les détails du job ou interroger l'une des vues INFORMATION_SCHEMA.JOBS*.
Afficher les informations sur le job
Dans Informations sur le job des Résultats de la requête, les champs Mode d'utilisation de l'index et Motifs de non-utilisation de l'index fournissent des informations détaillées sur l'utilisation de l'index de recherche.
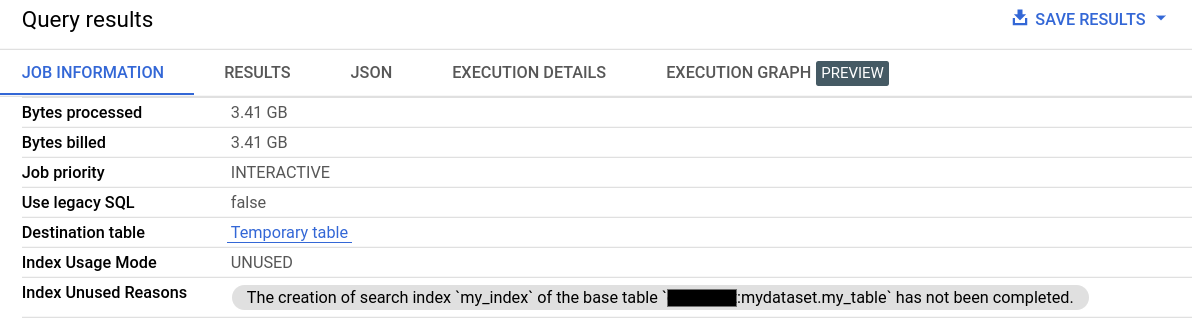
Des informations sur l'utilisation de l'index de recherche sont également disponibles via le champ searchStatistics dans la méthode API Jobs.Get. Le champ indexUsageMode dans searchStatistics indique si un index de recherche a été utilisé avec les valeurs suivantes :
UNUSED: aucun index de recherche n'a été utilisé.PARTIALLY_USED: une partie de la requête a utilisé les index de recherche.FULLY_USED: chaque fonctionSEARCHde la requête a utilisé un index de recherche.
Lorsque la valeur de indexUsageMode est définie sur UNUSED ou PARTIALLY_USED, le champ indexUnusuedReasons permet de comprendre pourquoi les index de recherche n'ont pas été utilisés dans la requête.
Pour afficher searchStatistics pour une requête, exécutez la commande bq show.
bq show --format=prettyjson -j JOB_ID
Exemple
Supposons que vous exécutiez une requête qui appelle la fonction SEARCH sur les données d'une table. Vous pouvez afficher les détails de la tâche de la requête pour trouver l'ID de tâche, puis exécuter la commande bq show pour afficher plus d'informations :
bq show --format=prettyjson --j my_project:US.bquijob_123x456_789y123z456c
Le résultat contient de nombreux champs, y compris searchStatistics, qui ressemble à ceci : Dans cet exemple, indexUsageMode indique que l'index n'a pas été utilisé. En effet, la table n'a pas d'index de recherche. Pour résoudre ce problème, créez un index de recherche sur la table. Consultez le champ code indexUnusedReason pour obtenir la liste de toutes les raisons pour lesquelles un index de recherche peut ne pas être utilisé dans une requête.
"searchStatistics": {
"indexUnusedReasons": [
{
"baseTable": {
"datasetId": "my_dataset",
"projectId": "my_project",
"tableId": "my_table"
},
"code": "INDEX_CONFIG_NOT_AVAILABLE",
"message": "There is no search index configuration for the base table `my_project:my_dataset.my_table`."
}
],
"indexUsageMode": "UNUSED"
},
Interroger les vues INFORMATION_SCHEMA
Vous pouvez également consulter l'utilisation de l'index de recherche pour plusieurs jobs dans une région dans les vues suivantes :
INFORMATION_SCHEMA.JOBSINFORMATION_SCHEMA.JOBS_BY_USERINFORMATION_SCHEMA.JOBS_BY_FOLDERINFORMATION_SCHEMA.JOBS_BY_ORGANIZATION
La requête suivante affiche des informations sur l'utilisation des index pour toutes les requêtes optimisables d'index de recherche au cours des sept derniers jours :
SELECT job_id, search_statistics.index_usage_mode, index_unused_reason.code, index_unused_reason.base_table.table_id, index_unused_reason.index_name FROM `region-REGION_NAME`.INFORMATION_SCHEMA.JOBS, UNNEST(search_statistics.index_unused_reasons) AS index_unused_reason WHERE end_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY) AND CURRENT_TIMESTAMP();
Le résultat ressemble à ce qui suit :
+-----------+----------------------------------------+-----------------------+ | job_id | index_usage_mode | code | table_id | index_name | +-----------+------------------+---------------------+-----------------------+ | bquxjob_1 | UNUSED | BASE_TABLE_TOO_SMALL| my_table | my_index | | bquxjob_2 | FULLY_USED | NULL | my_table | my_index | +-----------+----------------------------------------+-----------------------+
Bonnes pratiques
Les sections suivantes décrivent les bonnes pratiques concernant les recherches.
Rechercher de manière sélective
La recherche fonctionne mieux lorsque votre recherche renvoie peu de résultats. Effectuez des recherches aussi spécifiques que possible.
Optimisation ORDER BY LIMIT
Les requêtes qui utilisent SEARCH, =, IN, LIKE ou STARTS_WITH sur une très grande table partitionnée peuvent être optimisées lorsque vous utilisez une clause ORDER BY sur le champ partitionné et une clause LIMIT.
Pour les requêtes qui ne contiennent pas la fonction SEARCH, vous pouvez utiliser les autres opérateurs et fonctions pour tirer parti de l'optimisation. L'optimisation est appliquée, que la table soit indexée ou non. Cette méthode est adaptée si vous recherchez un terme commun.
Par exemple, supposons que la table Logs créée précédemment soit partitionnée sur une colonne de type DATE supplémentaire appelée day. La requête suivante est optimisée :
SELECT Level, Source, Message FROM my_dataset.Logs WHERE SEARCH(Message, "foo") ORDER BY day LIMIT 10;
Portée de la recherche
Lorsque vous utilisez la fonction SEARCH, faites porter la recherche sur les seules colonnes de la table qui sont susceptibles selon vous de contenir vos termes de recherche. Cela améliore les performances et réduit le nombre d'octets à analyser.
Utiliser des accents graves
Lorsque vous utilisez la fonction SEARCH avec l'analyseur de texte LOG_ANALYZER, le fait de placer votre requête de recherche entre accents graves force la recherche d'une correspondance exacte. Cela est utile si votre recherche est sensible à la casse ou contient des caractères qui ne doivent pas être interprétés comme des délimiteurs. Par exemple, pour rechercher l'adresse IP 192.0.2.1, utilisez `192.0.2.1`. Sans accents graves, la recherche va renvoyer toutes les lignes contenant les jetons individuels 192, 0, 2 et 1, dans n'importe quel ordre.