Indexierte Daten durchsuchen
Diese Seite enthält Beispiele für die Suche nach Tabellendaten in BigQuery.
Wenn Sie Ihre Daten indexieren, kann BigQuery einige Abfragen optimieren, die die Funktion SEARCH oder andere Funktionen und Operatoren wie z. B. =, IN, LIKE oder STARTS_WITH verwenden.
SQL-Abfragen geben korrekte Ergebnisse aus allen aufgenommenen Daten zurück, selbst wenn einige Daten noch nicht indexiert sind. Die Abfrageleistung kann jedoch mit einem Index erheblich verbessert werden. Einsparungen bei den verarbeiteten Byte und Slot-Millisekunden werden maximiert, wenn die Anzahl der Suchergebnisse einen relativ kleinen Teil der Gesamtzahl an Zeilen in Ihrer Tabelle ausmacht, da weniger Daten gescannt werden. Informationen dazu, ob ein Index für eine Abfrage verwendet wurde, finden Sie unter Nutzung des Suchindex.
Suchindex erstellen
Die folgende Tabelle mit dem Namen Logs wird verwendet, um verschiedene Möglichkeiten zur Verwendung der Funktion SEARCH zu zeigen. Diese Beispieltabelle ist ziemlich klein, aber in der Praxis erhöht sich die Leistungssteigerung durch SEARCH mit zunehmender Größe der Tabelle.
CREATE TABLE my_dataset.Logs (Level STRING, Source STRING, Message STRING) AS ( SELECT 'INFO' as Level, '65.177.8.234' as Source, 'Entry Foo-Bar created' as Message UNION ALL SELECT 'WARNING', '132.249.240.10', 'Entry Foo-Bar already exists, created by 65.177.8.234' UNION ALL SELECT 'INFO', '94.60.64.181', 'Entry Foo-Bar deleted' UNION ALL SELECT 'SEVERE', '4.113.82.10', 'Entry Foo-Bar does not exist, deleted by 94.60.64.181' UNION ALL SELECT 'INFO', '181.94.60.64', 'Entry Foo-Baz created' );
Die Tabelle sieht so aus:
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 65.177.8.234 | Entry Foo-Bar created | | WARNING | 132.249.240.10 | Entry Foo-Bar already exists, created by 65.177.8.234 | | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | | INFO | 181.94.60.64 | Entry Foo-Baz created | +---------+----------------+-------------------------------------------------------+
Erstellen Sie mit dem Standardtextanalysator einen Suchindex für die Tabelle Logs:
CREATE SEARCH INDEX my_index ON my_dataset.Logs(ALL COLUMNS);
Weitere Informationen zu Suchindexen finden Sie unter Suchindexe verwalten.
Funktion SEARCH verwenden
Die Funktion SEARCH bietet eine tokenisierte Suche nach Daten.
SEARCH ist für die Verwendung mit einem Index vorgesehen, um Abrufe zu optimieren.
Mit der Funktion SEARCH können Sie in einer ganzen Tabelle suchen oder die Suche auf bestimmte Spalten beschränken.
Gesamte Tabelle durchsuchen
Die folgende Abfrage durchsucht alle Spalten der Tabelle Logs nach dem Wert bar und gibt die Zeilen zurück, die diesen Wert enthalten, unabhängig von der Groß-/Kleinschreibung. Da der Suchindex den Standard-Text-Analysator verwendet, müssen Sie ihn nicht in der Funktion SEARCH angeben.
SELECT * FROM my_dataset.Logs WHERE SEARCH(Logs, 'bar');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 65.177.8.234 | Entry Foo-Bar created | | WARNING | 132.249.240.10 | Entry Foo-Bar already exists, created by 65.177.8.234 | | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
Folgende Abfrage durchsucht alle Spalten der Tabelle Logs nach dem Wert `94.60.64.181` und gibt die Zeilen zurück, die diesen Wert enthalten. Die Backticks ermöglichen eine genaue Suche, weshalb die letzte Zeile der Tabelle Logs, die 181.94.60.64 enthält, weggelassen wird.
SELECT * FROM my_dataset.Logs WHERE SEARCH(Logs, '`94.60.64.181`');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
In einer Teilmenge von Spalten suchen
Mit SEARCH können Sie einfach eine Teilmenge der Spalten angeben, in denen nach Daten gesucht werden soll. Die folgende Abfrage durchsucht die Spalte Message der Tabelle Logs nach dem Wert 94.60.64.181 und gibt die Zeilen zurück, die diesen Wert enthalten.
SELECT * FROM my_dataset.Logs WHERE SEARCH(Message, '`94.60.64.181`');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
Mit der folgenden Abfrage werden die Spalten Source und Message der Tabelle Logs durchsucht. Sie gibt die Zeilen zurück, die den Wert 94.60.64.181 in einer der Spalten enthalten.
SELECT * FROM my_dataset.Logs WHERE SEARCH((Source, Message), '`94.60.64.181`');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
Spalten aus einer Suche ausschließen
Wenn eine Tabelle viele Spalten enthält und Sie die meisten davon durchsuchen möchten, ist es möglicherweise einfacher, nur die Spalten anzugeben, die von der Suche ausgeschlossen werden sollen. Mit der folgenden Abfrage wird in allen Spalten der Tabelle Logs mit Ausnahme der Spalte Message gesucht. Sie gibt die Zeilen aller Spalten außer Message zurück, die den Wert 94.60.64.181 enthalten.
SELECT * FROM my_dataset.Logs WHERE SEARCH( (SELECT AS STRUCT Logs.* EXCEPT (Message)), '`94.60.64.181`');
+---------+----------------+---------------------------------------------------+ | Level | Source | Message | +---------+----------------+---------------------------------------------------+ | INFO | 94.60.64.181 | Entry Foo-Bar deleted | +---------+----------------+---------------------------------------------------+
Anderen Textanalysator verwenden
Im folgenden Beispiel wird eine Tabelle namens contact_info mit einem Index erstellt, der die Textanalyse NO_OP_ANALYZER verwendet:
CREATE TABLE my_dataset.contact_info (name STRING, email STRING) AS ( SELECT 'Kim Lee' AS name, 'kim.lee@example.com' AS email UNION ALL SELECT 'Kim' AS name, 'kim@example.com' AS email UNION ALL SELECT 'Sasha' AS name, 'sasha@example.com' AS email ); CREATE SEARCH INDEX noop_index ON my_dataset.contact_info(ALL COLUMNS) OPTIONS (analyzer = 'NO_OP_ANALYZER');
+---------+---------------------+ | name | email | +---------+---------------------+ | Kim Lee | kim.lee@example.com | | Kim | kim@example.com | | Sasha | sasha@example.com | +---------+---------------------+
Mit der folgenden Abfrage wird in der Spalte name nach Kim und in der Spalte email nach kim gesucht.
Da der Suchindex nicht den Standardtextanalysator verwendet, müssen Sie den Namen des Analysetools an die Funktion SEARCH übergeben.
SELECT name, SEARCH(name, 'Kim', analyzer=>'NO_OP_ANALYZER') AS name_Kim, email, SEARCH(email, 'kim', analyzer=>'NO_OP_ANALYZER') AS email_kim FROM my_dataset.contact_info;
NO_OP_ANALYZER ändert den Text nicht, sodass die Funktion SEARCH nur TRUE für genaue Übereinstimmungen zurückgibt:
+---------+----------+---------------------+-----------+ | name | name_Kim | email | email_kim | +---------+----------+---------------------+-----------+ | Kim Lee | FALSE | kim.lee@example.com | FALSE | | Kim | TRUE | kim@example.com | FALSE | | Sasha | FALSE | sasha@example.com | FALSE | +---------+----------+---------------------+-----------+
Optionen des Textanalysators konfigurieren
Die Textanalysatoren LOG_ANALYZER und PATTERN_ANALYZER können angepasst werden, indem den Konfigurationsoptionen ein JSON-formatierter String hinzugefügt wird. Sie können Textanalysatoren in der SEARCH-Funktion, der CREATE
SEARCH INDEX-DDL-Anweisung und der TEXT_ANALYZE-Funktion konfigurieren.
Im folgenden Beispiel wird eine Tabelle namens complex_table mit einem Index erstellt, der den Textanalysator LOG_ANALYZER verwendet. Die Analysatoroptionen werden in einem JSON-formatierten String konfiguriert:
CREATE TABLE dataset.complex_table( a STRING, my_struct STRUCT<string_field STRING, int_field INT64>, b ARRAY<STRING> ); CREATE SEARCH INDEX my_index ON dataset.complex_table(a, my_struct, b) OPTIONS (analyzer = 'LOG_ANALYZER', analyzer_options = '''{ "token_filters": [ { "normalization": {"mode": "NONE"} } ] }''');
Die folgenden Tabellen enthalten Beispiele für Aufrufe der Funktion SEARCH mit verschiedenen Textanalysatoren und die entsprechenden Ergebnisse. In der ersten Tabelle wird die Funktion SEARCH mit dem Standard-Textanalysator LOG_ANALYZER aufgerufen:
| Funktionsaufruf | Gibt Folgendes zurück: | Grund |
|---|---|---|
| SEARCH('foobarexample', NULL) | FEHLER | Die search_terms sind `NULL`. |
| SEARCH('foobarexample', '') | FEHLER | Die search_terms enthalten keine Tokens. |
| SEARCH('foobar-example', 'foobar example') | TRUE | „–“ und „ “ sind Trennzeichen. |
| SEARCH('foobar-example', 'foobarexample') | FALSE | Die search_terms werden nicht aufgeteilt. |
| SEARCH('foobar-example', 'foobar\\&example') | TRUE | Mit dem doppelten umgekehrten Schrägstrich wird das Et-Zeichen, das ein Trennzeichen ist, maskiert. |
| SEARCH('foobar-example', R'foobar\&example') | TRUE | Mit dem einzelnen umgekehrten Schrägstrich wird das & in einem Rohstring maskiert. |
| SEARCH('foobar-example', '`foobar&example`') | FALSE | Die Backticks erfordern eine genaue Übereinstimmung für foobar&beispiel. |
| SEARCH('foobar&example', '`foobar&example`') | TRUE | Es wird eine genaue Übereinstimmung gefunden. |
| SEARCH('foobar-example', 'example foobar') | TRUE | Die Reihenfolge der Begriffe spielt keine Rolle. |
| SEARCH('foobar-example', 'foobar example') | TRUE | Tokens werden in Kleinbuchstaben umgewandelt. |
| SEARCH('foobar-example', '`foobar-example`') | TRUE | Es wird eine genaue Übereinstimmung gefunden. |
| SEARCH('foobar-example', '`foobar`') | FALSE | Bei Backticks wird die Groß-/Kleinschreibung beibehalten. |
| SEARCH('`foobar-example`', '`foobar-example`') | FALSE | Graviszeichen haben keine spezielle Bedeutung für data_to_search und |
| SEARCH('foobar@example.com', '`example.com`') | TRUE | Nach dem Trennzeichen in data_to_search wird eine genaue Übereinstimmung gefunden. |
| SEARCH('a foobar-example b', '`foobar-example`') | TRUE | Zwischen den Leerzeichen-Trennzeichen wird eine genaue Übereinstimmung gefunden. |
| SEARCH(['foobar', 'example'], 'foobar example') | FALSE | Kein einzelner Arrayeintrag stimmt mit allen Suchbegriffen überein. |
| SEARCH('foobar=', '`foobar\\=`') | FALSE | Die search_terms entsprechen foobar\=. |
| SEARCH('foobar=', R'`foobar\=`') | FALSE | Das entspricht dem vorherigen Beispiel. |
| SEARCH('foobar=', 'foobar\\=') | TRUE | Das Gleichheitszeichen ist ein Trennzeichen in den Daten und in der Abfrage. |
| SEARCH('foobar=', R'foobar\=') | TRUE | Das entspricht dem vorherigen Beispiel. |
| SEARCH('foobar.example', '`foobar`') | TRUE | Es wird eine genaue Übereinstimmung gefunden. |
| SEARCH('foobar.example', '`foobar.`') | FALSE | "foobar." wird aufgrund von Graviszeichen nicht analysiert; es ist nicht |
| SEARCH('foobar..example', '`foobar.`') | TRUE | `foobar.` wird aufgrund von Graviszeichen nicht analysiert; ihm folgt |
Die folgende Tabelle zeigt Beispiele für Aufrufe der Funktion SEARCH mit dem NO_OP_ANALYZER-Textanalysator und Gründe für verschiedene Rückgabewerte:
| Funktionsaufruf | Gibt Folgendes zurück: | Begründung |
|---|---|---|
| SEARCH('foobar', 'foobar', analyzer=>'NO_OP_ANALYZER') | TRUE | Es wird eine genaue Übereinstimmung gefunden. |
| SEARCH('foobar', '`foobar`', analyzer=>'NO_OP_ANALYZER') | FALSE | Graviszeichen sind keine Sonderzeichen für NO_OP_ANALYZER. |
| SEARCH('Foobar', 'foobar', analyzer=>'NO_OP_ANALYZER') | FALSE | Die Großschreibung stimmt nicht überein. |
| SEARCH('foobar example', 'foobar', analyzer=>'NO_OP_ANALYZER') | FALSE | Für NO_OP_ANALYZER gibt es keine Trennzeichen. |
| SEARCH('', '', analyzer=>'NO_OP_ANALYZER') | TRUE | Für NO_OP_ANALYZER gibt es keine Trennzeichen. |
Weitere Operatoren und Funktionen
Sie können Suchindexoptimierungen mit mehreren Operatoren, Funktionen und Prädikaten ausführen.
Mit Operatoren und Vergleichsfunktionen optimieren
BigQuery kann einige Abfragen optimieren, die den Gleichheitsoperator (=), IN-Operator, LIKE-Operator oder die STARTS_WITH-Funktion verwenden, um Stringliterale mit indexierten Daten zu vergleichen.
Mit Stringprädikaten optimieren
Die folgenden Prädikate können für die Optimierung des Suchindex verwendet werden:
column_name = 'string_literal''string_literal' = column_namestruct_column.nested_field = 'string_literal'string_array_column[OFFSET(0)] = 'string_literal'string_array_column[ORDINAL(1)] = 'string_literal'column_name IN ('string_literal1', 'string_literal2', ...)STARTS_WITH(column_name, 'prefix')column_name LIKE 'prefix%'
Mit numerischen Prädikaten optimieren
Wenn der Suchindex mit numerischen Datentypen erstellt wurde, kann BigQuery einige Abfragen mit dem Gleichheitsoperator (=) oder dem IN-Operator mit indexierten Daten optimieren. Die folgenden Prädikate können für die Optimierung des Suchindex verwendet werden:
INT64(json_column.int64_field) = 1int64_column = 1int64_array_column[OFFSET(0)] = 1int64_column IN (1, 2)struct_column.nested_int64_field = 1struct_column.nested_timestamp_field = TIMESTAMP "2024-02-15 21:31:40"timestamp_column = "2024-02-15 21:31:40"timestamp_column IN ("2024-02-15 21:31:40", "2024-02-16 21:31:40")
Funktionen optimieren, die indexierte Daten generieren
BigQuery unterstützt die Optimierung des Suchindexes, wenn bestimmte Funktionen auf indexierte Daten angewendet werden.
Wenn der Suchindex den Standard-Text-Analysator LOG_ANALYZER verwendet, können Sie die Funktionen UPPER oder LOWER auf die Spalte anwenden, z. B. UPPER(column_name) = 'STRING_LITERAL'.
Für JSON-Skalarstringdaten, die aus einer indexierten JSON-Spalte extrahiert wurden, können Sie die Funktion STRING oder ihre sichere Version SAFE.STRING anwenden.
Wenn der extrahierte JSON-Wert kein String ist, gibt die STRING-Funktion einen Fehler zurück und die SAFE.STRING-Funktion gibt NULL zurück.
Bei indexierten STRING-Daten im JSON-Format (nicht JSON-Daten) können Sie die folgenden Funktionen anwenden:
Angenommen, Sie haben die folgende indexierte Tabelle namens dataset.person_data mit einer JSON- und einer STRING-Spalte:
+----------------------------------------------------------------+-----------------------------------------+
| json_column | string_column |
+----------------------------------------------------------------+-----------------------------------------+
| { "name" : "Ariel", "email" : "cloudysanfrancisco@gmail.com" } | { "name" : "Ariel", "job" : "doctor" } |
+----------------------------------------------------------------+-----------------------------------------+
Für die folgenden Abfragen kann die Optimierung in Anspruch genommen werden:
SELECT * FROM dataset.person_data WHERE SAFE.STRING(json_column.email) = 'cloudysanfrancisco@gmail.com';
SELECT * FROM dataset.person_data WHERE JSON_VALUE(string_column, '$.job') IN ('doctor', 'lawyer', 'teacher');
Auch Kombinationen dieser Funktionen werden optimiert, z. B. UPPER(JSON_VALUE(json_string_expression)) = 'FOO'.
Nutzung des Suchindex
Ob ein Suchindex für eine Abfrage verwendet wurde, können Sie anhand der Jobdetails oder durch Abfragen einer der INFORMATION_SCHEMA.JOBS*-Ansichten feststellen.
Auftragsdetails aufrufen
In den Jobinformationen der Abfrageergebnisse enthalten die Felder Nutzungsmodus für Indexe und Nicht verwendete Gründe für Indexe detaillierte Informationen zur Verwendung des Suchindex.
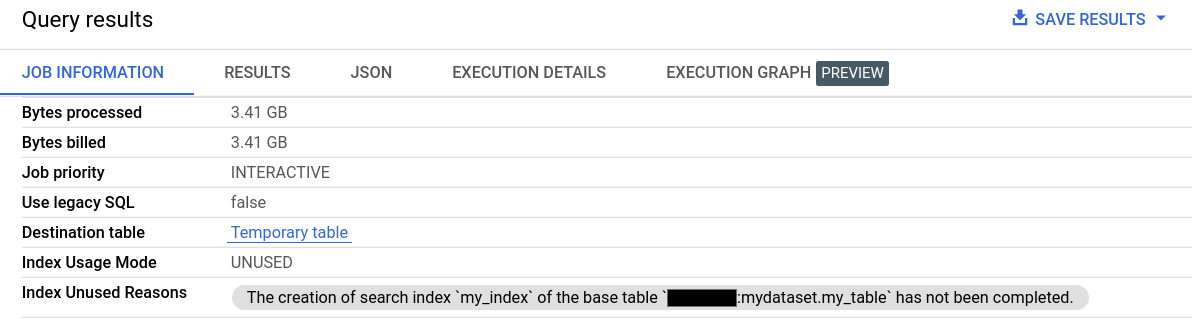
Informationen zur Verwendung des Suchindex finden Sie auch im Feld searchStatistics in der API-Methode Jobs.Get. Das Feld indexUsageMode in searchStatistics gibt an, ob ein Suchindex mit den folgenden Werten verwendet wurde:
UNUSED: Es wurde kein Suchindex verwendet.PARTIALLY_USED: Ein Teil der Abfrage wurde Suchindexe verwendet und ein Teil nicht.FULLY_USED: JedeSEARCH-Funktion in der Abfrage hat einen Suchindex verwendet.
Wenn indexUsageMode UNUSED oder PARTIALLY_USED ist, enthält das Feld indexUnusuedReasons Informationen dazu, warum Suchindexe nicht in der Abfrage verwendet wurden.
Führen Sie den Befehl bq show aus, um searchStatistics für eine Abfrage aufzurufen.
bq show --format=prettyjson -j JOB_ID
Beispiel
Angenommen, Sie führen eine Abfrage aus, die die Funktion SEARCH für Daten in einer Tabelle aufruft. In den Jobdetails der Abfrage finden Sie die Job-ID. Führen Sie dann den Befehl bq show aus, um weitere Informationen zu erhalten:
bq show --format=prettyjson --j my_project:US.bquijob_123x456_789y123z456c
Die Ausgabe enthält zahlreiche Felder, einschließlich searchStatistics, was in etwa so aussieht. In diesem Beispiel gibt indexUsageMode an, dass der Index nicht verwendet wurde. Der Grund dafür ist, dass die Tabelle keinen Suchindex hat. Erstellen Sie einen Suchindex für die Tabelle, um dieses Problem zu lösen. Eine Liste aller Gründe, aus denen ein Suchindex möglicherweise nicht in einer Abfrage verwendet wird, finden Sie im indexUnusedReason-Feld code.
"searchStatistics": {
"indexUnusedReasons": [
{
"baseTable": {
"datasetId": "my_dataset",
"projectId": "my_project",
"tableId": "my_table"
},
"code": "INDEX_CONFIG_NOT_AVAILABLE",
"message": "There is no search index configuration for the base table `my_project:my_dataset.my_table`."
}
],
"indexUsageMode": "UNUSED"
},
INFORMATION_SCHEMA-Ansichten abfragen
In den folgenden Ansichten können Sie auch die Suchindexnutzung für mehrere Jobs in einer Region sehen:
INFORMATION_SCHEMA.JOBSINFORMATION_SCHEMA.JOBS_BY_USERINFORMATION_SCHEMA.JOBS_BY_FOLDERINFORMATION_SCHEMA.JOBS_BY_ORGANIZATION
Die folgende Abfrage enthält Informationen zur Indexnutzung für alle Abfragen, die in den letzten sieben Tagen für den Suchindex optimiert werden konnten:
SELECT job_id, search_statistics.index_usage_mode, index_unused_reason.code, index_unused_reason.base_table.table_id, index_unused_reason.index_name FROM `region-REGION_NAME`.INFORMATION_SCHEMA.JOBS, UNNEST(search_statistics.index_unused_reasons) AS index_unused_reason WHERE end_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY) AND CURRENT_TIMESTAMP();
Das Ergebnis sieht etwa so aus:
+-----------+----------------------------------------+-----------------------+ | job_id | index_usage_mode | code | table_id | index_name | +-----------+------------------+---------------------+-----------------------+ | bquxjob_1 | UNUSED | BASE_TABLE_TOO_SMALL| my_table | my_index | | bquxjob_2 | FULLY_USED | NULL | my_table | my_index | +-----------+----------------------------------------+-----------------------+
Best Practices
In den folgenden Abschnitten werden Best Practices für die Suche beschrieben.
Selektiv suchen
Die Suche funktioniert am besten, wenn sie nur wenige Ergebnisse liefert. Machen Sie Suchanfragen daher so spezifisch wie möglich.
ORDER BY LIMIT-Optimierung
Abfragen, die SEARCH, =, IN, LIKE oder STARTS_WITH für eine sehr große partitionierte Tabelle verwenden, können optimiert werden, wenn Sie eine ORDER BY-Klausel für das partitionierte Feld und eine LIMIT-Klausel verwenden.
Bei Abfragen, die die Funktion SEARCH nicht enthalten, können Sie die anderen Operatoren und Funktionen verwenden, um die Optimierung zu nutzen. Die Optimierung wird unabhängig davon angewendet, ob die Basistabelle indexiert ist oder nicht. Dies funktioniert gut, wenn Sie nach einem häufig verwendeten Begriff suchen.
Angenommen, die zuvor erstellte Tabelle Logs ist nach einer zusätzlichen Spalte vom Typ DATE mit dem Namen day partitioniert. Die folgende Abfrage ist optimiert:
SELECT Level, Source, Message FROM my_dataset.Logs WHERE SEARCH(Message, "foo") ORDER BY day LIMIT 10;
Suche eingrenzen
Wenn Sie die Funktion SEARCH verwenden, suchen Sie nur in den Spalten der Tabelle, bei denen Sie davon ausgehen, dass Ihre Suchbegriffe enthalten sein werden. Dies verbessert die Leistung und die Anzahl der Byte, die gescannt werden müssen, wird verringert.
Backticks verwenden
Wenn Sie die Funktion SEARCH mit dem Textanalysator LOG_ANALYZER verwenden, erzwingt das Einschließen Ihrer Suchanfrage in Backticks eine genaue Übereinstimmung. Dies ist hilfreich, wenn bei Ihrer Suche zwischen Groß- und Kleinschreibung unterschieden wird oder Zeichen enthalten sind, die nicht als Begrenzungszeichen interpretiert werden sollten. Wenn Sie beispielsweise nach der IP-Adresse 192.0.2.1 suchen möchten, verwenden Sie `192.0.2.1`. Ohne Graviszeichen gibt die Suche jede Zeile zurück, die die einzelnen Tokens 192, 0, 2 und 1 in beliebiger Reihenfolge enthält.