색인이 생성된 데이터 검색
이 페이지에서는 BigQuery에서 테이블 데이터를 검색하는 예시를 제공합니다.
데이터 색인을 생성하면 BigQuery에서 SEARCH 함수 또는 =, IN, LIKE, STARTS_WITH 등의 기타 함수 및 연산자를 사용하는 일부 쿼리를 최적화할 수 있습니다.
SQL 쿼리는 일부 데이터가 아직 색인이 생성되지 않았더라도 수집된 모든 데이터에서 올바른 결과를 반환합니다. 하지만 색인으로 쿼리 성능을 크게 높일 수 있습니다. 처리된 바이트 및 슬롯 밀리초의 절감 효과는 스캔되는 데이터가 적어서 검색 결과 수가 테이블의 총 행 수에서 상대적으로 적은 비율을 차지할 때 극대화됩니다. 색인이 쿼리에 사용되었는지 확인하려면 검색 색인 사용량을 참조하세요.
검색 색인 만들기
Logs라는 다음 표에서는 SEARCH 함수를 사용하는 다양한 방법을 보여줍니다. 이 예시 테이블은 매우 작지만 실무에서 SEARCH로 얻는 성능 개선 효과는 테이블의 크기에 따라 커집니다.
CREATE TABLE my_dataset.Logs (Level STRING, Source STRING, Message STRING) AS ( SELECT 'INFO' as Level, '65.177.8.234' as Source, 'Entry Foo-Bar created' as Message UNION ALL SELECT 'WARNING', '132.249.240.10', 'Entry Foo-Bar already exists, created by 65.177.8.234' UNION ALL SELECT 'INFO', '94.60.64.181', 'Entry Foo-Bar deleted' UNION ALL SELECT 'SEVERE', '4.113.82.10', 'Entry Foo-Bar does not exist, deleted by 94.60.64.181' UNION ALL SELECT 'INFO', '181.94.60.64', 'Entry Foo-Baz created' );
이 테이블은 다음과 같습니다.
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 65.177.8.234 | Entry Foo-Bar created | | WARNING | 132.249.240.10 | Entry Foo-Bar already exists, created by 65.177.8.234 | | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | | INFO | 181.94.60.64 | Entry Foo-Baz created | +---------+----------------+-------------------------------------------------------+
기본 텍스트 분석기를 사용하여 Logs 테이블에 검색 색인을 만듭니다.
CREATE SEARCH INDEX my_index ON my_dataset.Logs(ALL COLUMNS);
검색 색인에 관한 자세한 내용은 검색 색인 관리를 참조하세요.
SEARCH 함수 사용
SEARCH 함수는 데이터에 대한 토큰화된 검색을 제공합니다.
SEARCH는 조회를 최적화하기 위해 색인과 함께 사용하도록 설계되었습니다.
SEARCH 함수를 사용하여 전체 테이블을 검색하거나 검색을 특정 열로 제한할 수 있습니다.
전체 테이블 검색
다음 쿼리는 Logs 테이블의 모든 열에서 bar 값을 검색하고 대소문자 구분 없이 이 값이 포함된 행을 반환합니다. 검색 색인은 기본 텍스트 분석기를 사용하므로 SEARCH 함수에서 지정할 필요가 없습니다.
SELECT * FROM my_dataset.Logs WHERE SEARCH(Logs, 'bar');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 65.177.8.234 | Entry Foo-Bar created | | WARNING | 132.249.240.10 | Entry Foo-Bar already exists, created by 65.177.8.234 | | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
다음 쿼리는 Logs 테이블의 모든 열에서 `94.60.64.181` 값을 검색하고 이 값이 포함된 행을 반환합니다. 백틱은 정확한 검색을 지원합니다. 따라서 181.94.60.64가 포함된 Logs 테이블의 마지막 행이 생략됩니다.
SELECT * FROM my_dataset.Logs WHERE SEARCH(Logs, '`94.60.64.181`');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
열 하위 집합 검색
SEARCH를 사용하면 데이터를 검색할 열 하위 집합을 쉽게 지정할 수 있습니다. 다음 쿼리는 Logs 테이블의 Message 열에서 94.60.64.181 값을 검색하고 이 값이 포함된 행을 반환합니다.
SELECT * FROM my_dataset.Logs WHERE SEARCH(Message, '`94.60.64.181`');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
다음 쿼리는 Logs 테이블의 Source 열과 Message 열을 모두 검색하여 두 열에서 값 94.60.64.181가 포함된 행을 반환합니다.
SELECT * FROM my_dataset.Logs WHERE SEARCH((Source, Message), '`94.60.64.181`');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
검색에서 열 제외
테이블의 열이 많은데 대부분의 열을 검색하려는 경우 검색에서 제외할 열만 쉽게 지정할 수 있습니다. 다음 쿼리는 Message 열을 제외한 Logs 테이블의 모든 열을 검색합니다. 이 쿼리는 94.60.64.181 값이 포함된 Message 외의 모든 열 행을 반환합니다.
SELECT * FROM my_dataset.Logs WHERE SEARCH( (SELECT AS STRUCT Logs.* EXCEPT (Message)), '`94.60.64.181`');
+---------+----------------+---------------------------------------------------+ | Level | Source | Message | +---------+----------------+---------------------------------------------------+ | INFO | 94.60.64.181 | Entry Foo-Bar deleted | +---------+----------------+---------------------------------------------------+
다른 텍스트 분석기 사용
다음 예시에서는 NO_OP_ANALYZER 텍스트 분석기를 사용하는 색인을 사용하여 contact_info라는 테이블을 만듭니다.
CREATE TABLE my_dataset.contact_info (name STRING, email STRING) AS ( SELECT 'Kim Lee' AS name, 'kim.lee@example.com' AS email UNION ALL SELECT 'Kim' AS name, 'kim@example.com' AS email UNION ALL SELECT 'Sasha' AS name, 'sasha@example.com' AS email ); CREATE SEARCH INDEX noop_index ON my_dataset.contact_info(ALL COLUMNS) OPTIONS (analyzer = 'NO_OP_ANALYZER');
+---------+---------------------+ | name | email | +---------+---------------------+ | Kim Lee | kim.lee@example.com | | Kim | kim@example.com | | Sasha | sasha@example.com | +---------+---------------------+
다음 쿼리는 name 열에서 Kim을 검색하고 email 열에서 kim을 검색합니다.
검색 색인은 기본 텍스트 분석기를 사용하지 않으므로 분석기 이름을 SEARCH 함수에 전달해야 합니다.
SELECT name, SEARCH(name, 'Kim', analyzer=>'NO_OP_ANALYZER') AS name_Kim, email, SEARCH(email, 'kim', analyzer=>'NO_OP_ANALYZER') AS email_kim FROM my_dataset.contact_info;
NO_OP_ANALYZER는 텍스트를 수정하지 않으므로 SEARCH 함수가 정확한 일치 항목에 대해서만 TRUE를 반환합니다.
+---------+----------+---------------------+-----------+ | name | name_Kim | email | email_kim | +---------+----------+---------------------+-----------+ | Kim Lee | FALSE | kim.lee@example.com | FALSE | | Kim | TRUE | kim@example.com | FALSE | | Sasha | FALSE | sasha@example.com | FALSE | +---------+----------+---------------------+-----------+
텍스트 분석기 구성 옵션
구성 옵션에 JSON 형식의 문자열을 추가하여 LOG_ANALYZER 및 PATTERN_ANALYZER 텍스트 분석기를 맞춤설정할 수 있습니다. 텍스트 분석기는 SEARCH 함수, CREATE
SEARCH INDEX DDL 문, TEXT_ANALYZE 함수에서 구성할 수 있습니다.
다음 예시에서는 LOG_ANALYZER 텍스트 분석기를 사용하는 색인을 사용하여 complex_table이라는 테이블을 만듭니다. 이는 JSON 형식 문자열을 사용하여 분석기 옵션을 구성합니다.
CREATE TABLE dataset.complex_table( a STRING, my_struct STRUCT<string_field STRING, int_field INT64>, b ARRAY<STRING> ); CREATE SEARCH INDEX my_index ON dataset.complex_table(a, my_struct, b) OPTIONS (analyzer = 'LOG_ANALYZER', analyzer_options = '''{ "token_filters": [ { "normalization": {"mode": "NONE"} } ] }''');
다음 표에서는 다양한 텍스트 분석기를 사용하는 SEARCH 함수 호출과 그 결과의 예시를 보여줍니다. 첫 번째 테이블은 기본 텍스트 분석기인 LOG_ANALYZER를 사용하여 SEARCH 함수를 호출합니다.
| 함수 호출 | 반환 | 이유 |
|---|---|---|
| SEARCH('foobarexample', NULL) | 오류 | search_terms가 `NULL`입니다. |
| SEARCH('foobarexample', '') | 오류 | search_terms에 토큰이 없습니다. |
| SEARCH('foobar-example', 'foobar example') | TRUE | '-' 및 ' '가 구분 기호입니다. |
| SEARCH('foobar-example', 'foobarexample') | FALSE | search_terms가 분할되지 않습니다. |
| SEARCH('foobar-example', 'foobar\\&example') | TRUE | 이중 백슬래시가 구분 기호인 앰퍼샌드를 이스케이프 처리합니다. |
| SEARCH('foobar-example', R'foobar\&example') | TRUE | 단일 백슬래시가 원시 문자열에서 앰퍼샌드를 이스케이프 처리합니다. |
| SEARCH('foobar-example', '`foobar&example`') | FALSE | 백틱은 foobar&example에 대한 정확한 일치 항목이 필요합니다. |
| SEARCH('foobar&example', '`foobar&example`') | TRUE | 정확한 일치 항목이 발견되었습니다. |
| SEARCH('foobar-example', 'example foobar') | TRUE | 용어의 순서는 중요하지 않습니다. |
| SEARCH('foobar-example', 'foobar example') | TRUE | 토큰이 소문자로 바뀝니다. |
| SEARCH('foobar-example', '`foobar-example`') | TRUE | 정확한 일치 항목이 발견되었습니다. |
| SEARCH('foobar-example', '`foobar`') | FALSE | 백틱이 대소문자를 유지합니다. |
| SEARCH('`foobar-example`', '`foobar-example`') | FALSE | 백틱이 data_to_search에 특별한 의미가 없습니다. |
| SEARCH('foobar@example.com', '`example.com`') | TRUE | data_to_search의 구분 기호 다음에 정확한 일치 항목이 발견되었습니다. |
| SEARCH('a foobar-example b', '`foobar-example`') | TRUE | 공백 구분 기호 사이에 정확한 일치 항목이 발견되었습니다. |
| SEARCH(['foobar', 'example'], 'foobar example') | FALSE | 모든 검색어와 일치하는 단일 배열 항목이 없습니다. |
| SEARCH('foobar=', '`foobar\\=`') | FALSE | search_terms가 foobar\=와 같습니다. |
| SEARCH('foobar=', R'`foobar\=`') | FALSE | 이전 예시와 같습니다. |
| SEARCH('foobar=', 'foobar\\=') | TRUE | 등호가 데이터 및 쿼리의 구분 기호입니다. |
| SEARCH('foobar=', R'foobar\=') | TRUE | 이전 예시와 같습니다. |
| SEARCH('foobar.example', '`foobar`') | TRUE | 정확한 일치 항목이 발견되었습니다. |
| SEARCH('foobar.example', '`foobar.`') | FALSE | 백틱으로 인해 `foobar.`가 분석되지 않습니다. |
| SEARCH('foobar..example', '`foobar.`') | TRUE | 백틱으로 인해 `foobar.` 가 분석되지 않습니다. |
다음 표에서는 NO_OP_ANALYZER 텍스트 분석기를 사용하는 SEARCH 함수 호출 예시와 여러 반환 값의 이유를 보여줍니다.
| 함수 호출 | 반환 | 이유 |
|---|---|---|
| SEARCH('foobar', 'foobar', analyzer=>'NO_OP_ANALYZER') | TRUE | 정확한 일치 항목이 발견되었습니다. |
| SEARCH('foobar', '`foobar`', analyzer=>'NO_OP_ANALYZER') | FALSE | 백틱이 NO_OP_ANALYZER의 특수 문자가 아닙니다. |
| SEARCH('Foobar', 'foobar', analyzer=>'NO_OP_ANALYZER') | FALSE | 대소문자가 일치하지 않습니다. |
| SEARCH('foobar example', 'foobar', analyzer=>'NO_OP_ANALYZER') | FALSE | NO_OP_ANALYZER에 대한 구분 기호가 없습니다. |
| SEARCH('', '', analyzer=>'NO_OP_ANALYZER') | TRUE | NO_OP_ANALYZER에 대한 구분 기호가 없습니다. |
기타 연산자 및 함수
여러 연산자, 함수, 조건자를 사용하여 검색 색인 최적화를 수행할 수 있습니다.
연산자 및 비교 함수로 최적화
BigQuery는 등호 연산자(=), IN 연산자, LIKE 연산자 또는 STARTS_WITH 함수를 사용하는 일부 쿼리를 최적화하여 문자열 리터럴을 색인이 생성된 데이터와 비교합니다.
문자열 조건자를 통한 최적화
다음 조건자는 검색 색인 최적화를 사용할 수 있습니다.
column_name = 'string_literal''string_literal' = column_namestruct_column.nested_field = 'string_literal'string_array_column[OFFSET(0)] = 'string_literal'string_array_column[ORDINAL(1)] = 'string_literal'column_name IN ('string_literal1', 'string_literal2', ...)STARTS_WITH(column_name, 'prefix')column_name LIKE 'prefix%'
숫자 조건자를 통한 최적화
검색 색인이 숫자 데이터 유형으로 생성된 경우 BigQuery는 색인이 생성된 데이터에 등호 연산자(=) 또는 IN 연산자를 사용하는 일부 쿼리를 최적화할 수 있습니다. 다음 조건자는 검색 색인 최적화를 사용할 수 있습니다.
INT64(json_column.int64_field) = 1int64_column = 1int64_array_column[OFFSET(0)] = 1int64_column IN (1, 2)struct_column.nested_int64_field = 1struct_column.nested_timestamp_field = TIMESTAMP "2024-02-15 21:31:40"timestamp_column = "2024-02-15 21:31:40"timestamp_column IN ("2024-02-15 21:31:40", "2024-02-16 21:31:40")
색인이 생성된 데이터가 생성되는 함수 최적화
BigQuery는 색인이 생성된 데이터에 특정 함수가 적용되는 경우 검색 색인 최적화를 지원합니다.
검색 색인이 기본 LOG_ANALYZER 텍스트 분석기를 사용하는 경우 UPPER(column_name) = 'STRING_LITERAL'과 같이 열에 UPPER 또는 LOWER 함수를 적용할 수 있습니다.
색인이 생성된 JSON 열에서 추출된 JSON 스칼라 문자열 데이터에 STRING 함수 또는 안전 버전인 SAFE.STRING을 적용할 수 있습니다.
추출된 JSON 값이 문자열이 아니면 STRING 함수에서 오류가 발생하고 SAFE.STRING 함수가 NULL을 반환합니다.
색인이 생성된 JSON 형식의 STRING(JSON 아님) 데이터의 경우 다음 함수를 적용할 수 있습니다.
예를 들어 JSON 및 STRING 열이 있는 dataset.person_data라는 색인이 생성된 테이블이 있다고 가정해 보겠습니다.
+----------------------------------------------------------------+-----------------------------------------+
| json_column | string_column |
+----------------------------------------------------------------+-----------------------------------------+
| { "name" : "Ariel", "email" : "cloudysanfrancisco@gmail.com" } | { "name" : "Ariel", "job" : "doctor" } |
+----------------------------------------------------------------+-----------------------------------------+
다음 쿼리는 최적화 대상입니다.
SELECT * FROM dataset.person_data WHERE SAFE.STRING(json_column.email) = 'cloudysanfrancisco@gmail.com';
SELECT * FROM dataset.person_data WHERE JSON_VALUE(string_column, '$.job') IN ('doctor', 'lawyer', 'teacher');
이러한 함수의 조합도 최적화됩니다(예: UPPER(JSON_VALUE(json_string_expression)) = 'FOO').
검색 색인 사용
검색 색인이 쿼리에 사용되었는지 확인하려면 작업 세부정보를 보거나 INFORMATION_SCHEMA.JOBS* 뷰 중 하나를 쿼리하면 됩니다.
작업 세부정보 보기
쿼리 결과의 작업 정보에서 색인 사용 모드 및 색인 미사용 이유 필드에 검색 색인 사용에 대한 자세한 정보가 제공됩니다.
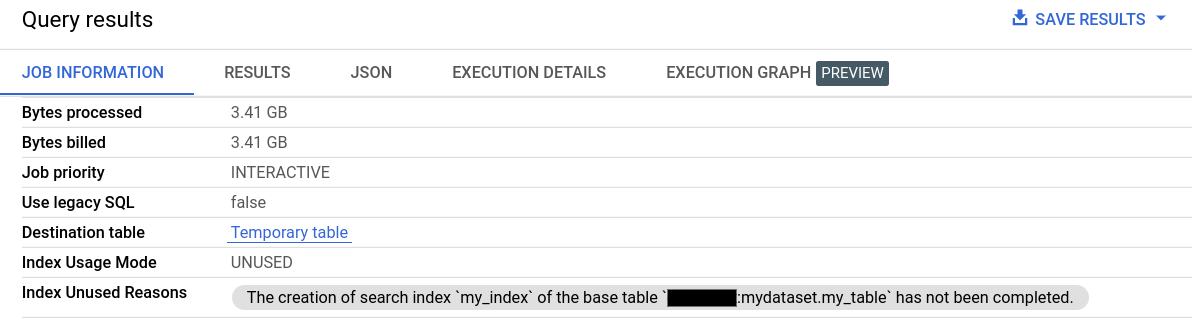
검색 색인 사용에 대한 정보는 Jobs.Get API 메서드의 searchStatistics 필드를 통해서도 제공됩니다. searchStatistics의 indexUsageMode 필드는 검색 색인이 다음 값으로 사용되었는지 여부를 나타냅니다.
UNUSED: 사용된 검색 색인이 없습니다.PARTIALLY_USED: 쿼리의 일부에 검색 색인이 사용되었고 일부는 사용되지 않았습니다.FULLY_USED: 쿼리의 모든SEARCH함수에 검색 색인이 사용되었습니다.
indexUsageMode가 UNUSED 또는 PARTIALLY_USED인 경우 indexUnusuedReasons 필드에 쿼리에 검색 색인이 사용되지 않은 이유에 대한 정보가 포함되어 있습니다.
쿼리의 searchStatistics를 보려면 bq show 명령어를 실행합니다.
bq show --format=prettyjson -j JOB_ID
예
테이블의 데이터에 대해 SEARCH 함수를 호출하는 쿼리를 실행한다고 가정해 보세요. 쿼리의 작업 세부정보를 보고 작업 ID를 찾은 다음 bq show 명령어를 실행하여 자세한 정보를 확인할 수 있습니다.
bq show --format=prettyjson --j my_project:US.bquijob_123x456_789y123z456c
출력에는 다음과 비슷하게 searchStatistics를 포함하여 많은 필드가 포함됩니다. 이 예시에서 indexUsageMode는 색인이 사용되지 않았음을 나타냅니다. 테이블에 검색 색인이 없기 때문입니다. 이 문제를 해결하려면 테이블에서 검색 색인을 만듭니다. 쿼리에서 검색 색인을 사용할 수 없는 모든 이유 목록은 indexUnusedReason code 필드를 참조하세요.
"searchStatistics": {
"indexUnusedReasons": [
{
"baseTable": {
"datasetId": "my_dataset",
"projectId": "my_project",
"tableId": "my_table"
},
"code": "INDEX_CONFIG_NOT_AVAILABLE",
"message": "There is no search index configuration for the base table `my_project:my_dataset.my_table`."
}
],
"indexUsageMode": "UNUSED"
},
INFORMATION_SCHEMA 뷰 쿼리
다음 뷰에서 리전의 여러 작업에 대한 검색 색인 사용량을 확인할 수도 있습니다.
INFORMATION_SCHEMA.JOBSINFORMATION_SCHEMA.JOBS_BY_USERINFORMATION_SCHEMA.JOBS_BY_FOLDERINFORMATION_SCHEMA.JOBS_BY_ORGANIZATION
다음 쿼리는 지난 7일 동안 모든 검색 색인 최적화 가능 쿼리의 색인 사용량에 관한 정보를 보여줍니다.
SELECT job_id, search_statistics.index_usage_mode, index_unused_reason.code, index_unused_reason.base_table.table_id, index_unused_reason.index_name FROM `region-REGION_NAME`.INFORMATION_SCHEMA.JOBS, UNNEST(search_statistics.index_unused_reasons) AS index_unused_reason WHERE end_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY) AND CURRENT_TIMESTAMP();
결과는 다음과 비슷합니다.
+-----------+----------------------------------------+-----------------------+ | job_id | index_usage_mode | code | table_id | index_name | +-----------+------------------+---------------------+-----------------------+ | bquxjob_1 | UNUSED | BASE_TABLE_TOO_SMALL| my_table | my_index | | bquxjob_2 | FULLY_USED | NULL | my_table | my_index | +-----------+----------------------------------------+-----------------------+
권장사항
다음 섹션에서는 검색에 대한 권장사항을 설명합니다.
선택적으로 검색
검색은 검색 결과가 거의 없을 때 가장 효과적입니다. 검색을 최대한 구체적으로 수행하세요.
ORDER BY LIMIT 최적화
파티션을 나눈 필드의 ORDER BY 절 및 LIMIT 절을 사용하면 파티션을 나눈 매우 큰 테이블에서 SEARCH, =, IN, LIKE 또는 STARTS_WITH를 사용하는 쿼리를 최적화할 수 있습니다.
쿼리에 SEARCH 함수가 포함되지 않은 경우 기타 연산자 및 함수를 사용하여 최적화를 활용할 수 있습니다. 테이블의 색인 생성 여부에 관계없이 최적화가 적용됩니다. 이 최적화는 일반적인 용어를 검색할 때 효과적입니다.
예를 들어 앞에서 만든 Logs 테이블이 day라는 추가 DATE 유형 열로 파티션을 나눈다고 가정해 보겠습니다. 다음 쿼리가 최적화됩니다.
SELECT Level, Source, Message FROM my_dataset.Logs WHERE SEARCH(Message, "foo") ORDER BY day LIMIT 10;
검색 범위 지정
SEARCH 함수를 사용할 경우 테이블에서 검색어가 포함될 것으로 예상되는 열만 검색하세요. 이렇게 하면 성능이 향상되고 스캔해야 할 바이트 수가 줄어듭니다.
백틱 사용
LOG_ANALYZER 텍스트 분석기와 함께 SEARCH 함수를 사용하는 경우 검색어를 백틱으로 묶으면 일치검색이 적용됩니다. 백틱은 검색이 대소문자를 구분하거나 구분 기호로 해석해서는 안 되는 문자가 있을 때 유용합니다. 예를 들어 IP 주소 192.0.2.1을 검색하려면 `192.0.2.1`을 사용합니다. 백틱이 없으면 검색에서 개별 토큰 192, 0, 2, 1이 포함된 모든 행을 임의의 순서로 반환합니다.