Trabalhar com dados do Salesforce Data Cloud no BigQuery
Os usuários da nuvem de dados podem acessar os dados da nuvem de dados de maneira nativa no BigQuery. É possível analisar dados da nuvem de dados com o BigQuery Omni e fazer análises entre nuvens com os dados do Google Cloud. Neste documento, fornecemos instruções sobre como acessar seus dados do Data Cloud e várias tarefas analíticas que você pode realizar com esses dados no BigQuery.
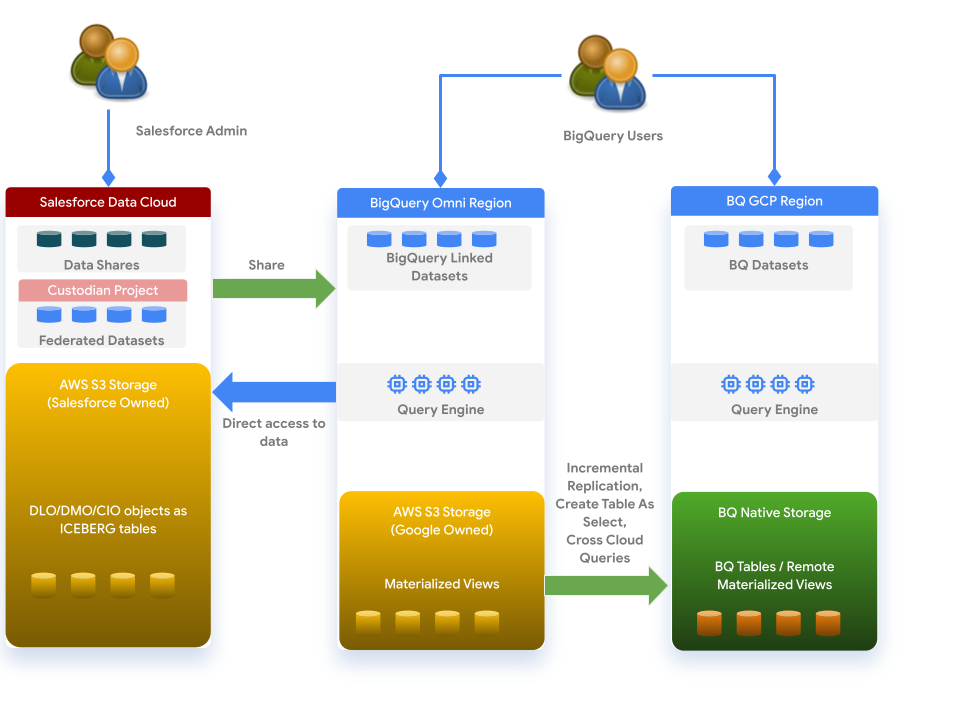
A nuvem de dados funciona com o BigQuery com base na arquitetura a seguir:
Antes de começar
Para trabalhar com dados da nuvem de dados, você precisa ser um usuário da nuvem de dados. Se o VPC Service Controls estiver ativado no projeto, outras permissões serão necessárias.
Funções exigidas
Os seguintes papéis e permissões são obrigatórios:
- Assinante do Analytics Hub (
roles/analyticshub.subscriber) - Administrador do BigQuery (
roles/bigquery.admin)
Compartilhar dados da nuvem de dados
Nesta documentação, demonstramos como compartilhar dados do Data Cloud com o BigQuery: Compartilhamentos de dados BYOL, integração zero-ETL com o BigQuery.
Vincular o conjunto de dados da nuvem de dados ao BigQuery
Para acessar um conjunto de dados da nuvem de dados no BigQuery, primeiro vincule o conjunto de dados ao BigQuery seguindo estas etapas:
No console do Google Cloud, acesse a página do BigQuery.
Clique em Salesforce Data Cloud
Os conjuntos de dados da nuvem de dados são exibidos. Você pode encontrar o conjunto de dados pelo nome usando o seguinte padrão de nomenclatura:
listing_DATA_SHARE_NAME_TARGET_NAME
DATA_SHARE_NAME: o nome do compartilhamento de dados na nuvem de dados.TARGET_NAME: o nome do destino do BigQuery na nuvem de dados.
Clique no conjunto de dados que você quer adicionar ao BigQuery.
Clique em Adicionar conjunto de dados ao projeto.
Especifique o nome do conjunto de dados vinculado.
Depois que o conjunto de dados vinculado é criado, é possível explorá-lo e as tabelas contidas nele. Todos os metadados das tabelas são recuperados da nuvem de dados dinamicamente. Todos os objetos dentro do conjunto de dados são visualizações mapeadas para os objetos da nuvem de dados. O BigQuery oferece suporte a três tipos de objetos de nuvem de dados:
- Objetos de data lake (DLO)
- Objetos de modelo de dados (DMO)
- Objetos de insights calculados (CIO)
Todos esses objetos são representados como visualizações no BigQuery. Essas visualizações apontam para tabelas ocultas armazenadas no Amazon S3.
Trabalhar com dados da nuvem de dados
Os exemplos a seguir usam um conjunto de dados chamado Northwest Trail Outfitters (NTO) que está hospedado na nuvem de dados. Esse conjunto de dados consiste em três tabelas que representam os dados de vendas on-line da organização NTO:
linked_nto_john.nto_customers__dlllinked_nto_john.nto_products__dlllinked_nto_john.nto_orders__dll
O outro conjunto de dados usado nestes exemplos são os dados de ponto de venda off-line. Isso abrange as vendas off-line e consiste em três tabelas:
nto_pos.customersnto_pos.productsnto_pos.orders
Os seguintes conjuntos de dados armazenam objetos adicionais:
aws_dataus_data
Executar consultas ad hoc
Com o BigQuery Omni, é possível executar consultas ad hoc para analisar os dados da nuvem de dados por meio do conjunto de dados assinado. No exemplo a seguir, mostramos uma consulta simples que consulta a tabela de clientes do Data Cloud.
SELECT name__c, age__c FROM `listing_nto_john.nto_customers__dll` WHERE age > 40 LIMIT 1000;
Executar consultas entre nuvens
Com as consultas entre nuvens, é possível mesclar qualquer uma das tabelas na
região do BigQuery Omni e das tabelas nas regiões do
BigQuery. Para mais informações sobre consultas entre nuvens, confira esta postagem do
blog.
Neste exemplo, recuperamos o total de vendas de um cliente chamado john.
-- Get combined sales for a customer from both offline and online sales USING ( SELECT total_price FROM `listing_nto_john.nto_orders__dll` WHERE customer_name = 'john' UNION ALL SELECT total_price FROM `listing_nto_john.nto_orders__dll` WHERE customer_name = 'john' ) a SELECT SUM(total_price);
Transferência de dados entre nuvens por CTAS
É possível usar "Criar tabela como seleção" (CTAS, na sigla em inglês) para mover dados de
tabelas do Data Cloud na região do BigQuery Omni para
a região US.
-- Move all the orders for March to the US region CREATE OR REPLACE TABLE us_data.online_orders_march AS SELECT * FROM listing_nto_john.nto_orders__dll WHERE EXTRACT(MONTH FROM order_time) = 3
A tabela de destino é uma tabela gerenciada do BigQuery na região US. É possível mesclar essa tabela a outras. Essa operação gera custos de saída da AWS com base na quantidade de dados transferidos.
Depois que os dados são movidos, não é mais necessário pagar taxas de saída para as consultas executadas na tabela online_orders_march.
Visualizações materializadas entre nuvens
As visualizações materializadas entre nuvens
(CCMV, na sigla em inglês)
transferem dados de uma região do BigQuery Omni para uma
região do BigQuery que não seja do BigQuery Omni de maneira incremental.
Configure um novo CCMV que transfira um resumo do total de vendas de transações
on-line e replique esses dados na região US.
Você pode acessar CCMVs no Ads Data Hub e combiná-los a outros dados do ADH. Os CCMVs atuam como tabelas gerenciadas do BigQuery na maior parte.
Criar uma visualização materializada local
Para criar uma visualização materializada local:
-- Create a local materialized view that keeps track of total sales by day CREATE MATERIALIZED VIEW `aws_data.total_sales` OPTIONS (enable_refresh = true, refresh_interval_minutes = 60) AS SELECT EXTRACT(DAY FROM order_time) AS date, SUM(order_total) as sales FROM `listing_nto_john.nto_orders__dll` GROUP BY 1;
Autorizar a visualização materializada
Você precisa autorizar visualizações materializadas para criar uma CCMV. É possível
autorizar a visualização (aws_data.total_sales) ou o conjunto de dados (aws_data). Para autorizar a visualização materializada:
No console do Google Cloud, acesse a página do BigQuery.
Abra o conjunto de dados de origem
listing_nto_john.Clique em Compartilhamento e em Autorizar conjuntos de dados.
Insira o nome do conjunto de dados (neste caso,
listing_nto_john) e clique em Ok.
Criar uma réplica de visualização materializada
Crie uma nova visualização materializada de réplica na região US. A visualização materializada
é replicada periodicamente sempre que há uma alteração nos dados de origem para manter a
réplica atualizada.
-- Create a replica MV in the us region. CREATE MATERIALIZED VIEW `us_data.total_sales_replica` AS REPLICA OF `aws_data.total_sales`;
Executar uma consulta em uma visualização materializada de réplica
O exemplo a seguir executa uma consulta em uma visualização materializada de réplica:
-- Find total sales for the current month for the dashboard SELECT EXTRACT(MONTH FROM CURRENT_DATE()) as month, SUM(sales) FROM us_data.total_sales_replica WHERE month = EXTRACT(MONTH FROM date) GROUP BY 1
Como usar dados da nuvem de dados com INFORMATION_SCHEMA
Os conjuntos de dados da nuvem de dados são compatíveis com as visualizações INFORMATION_SCHEMA do BigQuery. Os dados nas visualizações INFORMATION_SCHEMA são
sincronizados regularmente com a nuvem de dados e podem estar desatualizados. A coluna SYNC_STATUS nas visualizações TABLES
e SCHEMATA mostra
o horário da última sincronização concluída, todos os erros que impedem o BigQuery de fornecer dados atualizados e as etapas necessárias para corrigir o erro.
As consultas INFORMATION_SCHEMA não refletem conjuntos de dados que foram criados recentemente antes da sincronização inicial.
Os conjuntos de dados da nuvem de dados estão sujeitos às mesmas
limitações que outros
conjuntos de dados vinculados, como só poder ser acessado em INFORMATION_SCHEMA em
consultas com escopo de conjunto de dados.
A seguir
Saiba mais sobre o BigQuery Omni.
Saiba mais sobre mesclagens entre nuvens.
Saiba mais sobre visualizações materializadas.