BigQuery에서 Salesforce Data Cloud 데이터 작업
데이터 클라우드 사용자는 BigQuery에서 기본적으로 Data Cloud 데이터에 액세스할 수 있습니다. BigQuery Omni를 사용하여 Data Cloud 데이터를 분석하고 Google Cloud의 데이터로 교차 클라우드 분석을 수행할 수 있습니다. 이 문서에서는 Data Cloud 데이터 액세스에 대한 안내와 BigQuery에서 해당 데이터로 수행할 수 있는 몇 가지 분석 작업을 설명합니다.
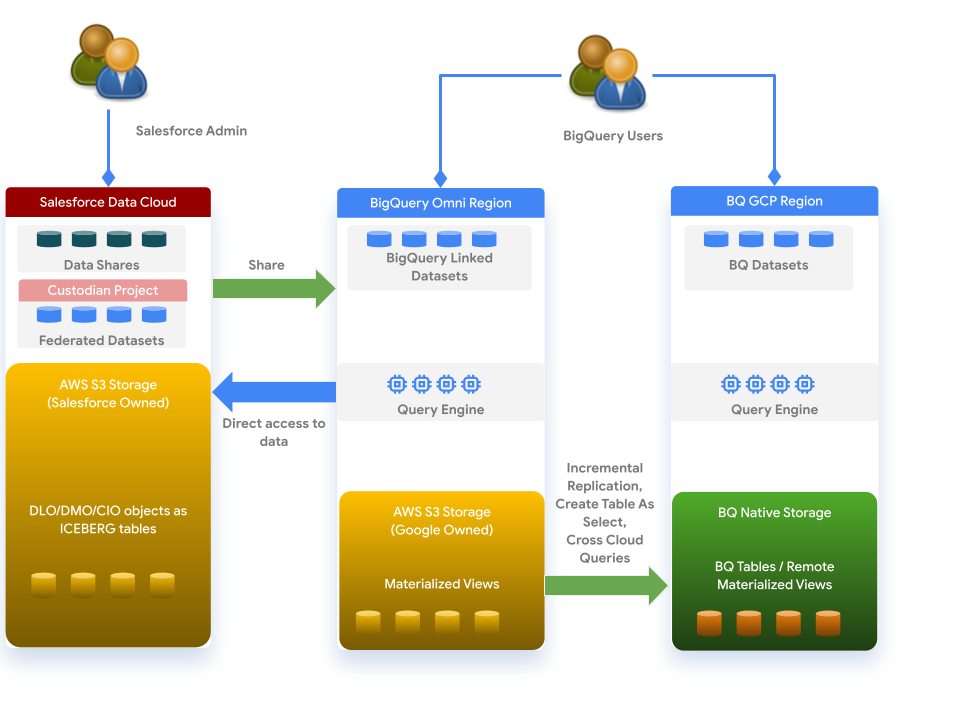
Data Cloud는 다음 아키텍처를 기반으로 BigQuery와 함께 작동합니다.
시작하기 전에
Data Cloud 데이터를 사용하려면 먼저 Data Cloud 사용자여야 합니다. 프로젝트에 VPC 서비스 제어가 사용 설정된 경우 추가 권한이 필요합니다.
필요한 역할
다음 역할 및 권한이 필요합니다.
- Analytics Hub 구독자(
roles/analyticshub.subscriber) - BigQuery 관리자(
roles/bigquery.admin)
Data Cloud에서 데이터 공유
이 문서에서는 Data Cloud에서 BigQuery로 데이터를 공유하는 방법을 보여줍니다(BYOL Data Shares - Zero-ETL Integration with BigQuery).
Data Cloud 데이터 세트를 BigQuery에 연결
BigQuery에서 Data Cloud 데이터 세트에 액세스하려면 먼저 다음 단계에 따라 데이터 세트를 BigQuery에 연결해야 합니다.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
Salesforce Data Cloud를 클릭합니다.
Data Cloud 데이터 세트가 표시됩니다. 다음 이름 지정 패턴을 사용하여 이름으로 데이터 세트를 찾을 수 있습니다.
listing_DATA_SHARE_NAME_TARGET_NAME
DATA_SHARE_NAME: Data Cloud의 데이터 공유 이름입니다.TARGET_NAME: Data Cloud의 BigQuery 대상 이름입니다.
BigQuery에 추가할 데이터 세트를 클릭합니다.
프로젝트에 데이터 세트 추가를 클릭합니다.
연결된 데이터 세트의 이름을 지정합니다.
연결된 데이터 세트가 생성되면 데이터 세트와 데이터 세트의 테이블을 탐색할 수 있습니다. 모든 테이블의 메타데이터는 Data Cloud에서 동적으로 검색됩니다. 데이터 세트 내의 모든 객체는 Data Cloud 객체에 매핑되는 뷰입니다. BigQuery는 다음 세 가지 유형의 Data Cloud 객체를 지원합니다.
- 데이터 레이크 객체(DLO)
- 데이터 모델 객체(DMO)
- 계산된 통계 객체(CIO)
이러한 모든 객체는 BigQuery에서 뷰로 표시됩니다. 이러한 뷰는 Amazon S3에 저장된 숨겨진 테이블을 가리킵니다.
Data Cloud 데이터 작업
다음 예시에서는 Data Cloud에서 호스팅되는 Northwest Trail Outfitters(NTO)라는 데이터 세트를 사용합니다. 이 데이터 세트는 NTO 조직의 온라인 판매 데이터를 나타내는 3개의 테이블로 구성됩니다.
linked_nto_john.nto_customers__dlllinked_nto_john.nto_products__dlllinked_nto_john.nto_orders__dll
이 예시에 사용된 기타 데이터 세트는 오프라인 판매 시점 데이터입니다. 오프라인 판매를 다루며, 다음 3개의 테이블로 구성됩니다.
nto_pos.customersnto_pos.productsnto_pos.orders
다음 데이터 세트에는 추가 객체가 저장됩니다.
aws_dataus_data
임시 쿼리 실행
BigQuery Omni를 사용하면 구독한 데이터 세트를 통해 Data Cloud 데이터를 분석하는 임시 쿼리를 실행할 수 있습니다. 다음 예시는 Data Cloud에서 고객 테이블을 쿼리하는 간단한 쿼리를 보여줍니다.
SELECT name__c, age__c FROM `listing_nto_john.nto_customers__dll` WHERE age > 40 LIMIT 1000;
교차 클라우드 쿼리 실행
교차 클라우드 쿼리를 사용하면 BigQuery Omni 리전의 테이블과 BigQuery 리전의 테이블을 조인할 수 있습니다. 교차 클라우드 쿼리에 대한 자세한 내용은 이 블로그 게시물을 참조하세요.
이 예시에서는 이름이 john인 고객의 총 판매를 검색합니다.
-- Get combined sales for a customer from both offline and online sales USING ( SELECT total_price FROM `listing_nto_john.nto_orders__dll` WHERE customer_name = 'john' UNION ALL SELECT total_price FROM `listing_nto_john.nto_orders__dll` WHERE customer_name = 'john' ) a SELECT SUM(total_price);
CTAS를 통한 교차 Cloud Data Transfer
CTAS(Create Table As Select)를 사용하여 BigQuery Omni 리전의 Data Cloud 테이블에서 US 리전으로 데이터를 이동할 수 있습니다.
-- Move all the orders for March to the US region CREATE OR REPLACE TABLE us_data.online_orders_march AS SELECT * FROM listing_nto_john.nto_orders__dll WHERE EXTRACT(MONTH FROM order_time) = 3
대상 테이블은 US 리전의 BigQuery 관리형 테이블입니다. 이 테이블은 다른 테이블과 조인할 수 있습니다. 이 작업은 전송되는 데이터 양에 따라 AWS 이그레스 비용이 발생합니다.
데이터가 이동되면 online_orders_march 테이블에서 실행되는 쿼리에 대해 더 이상 이그레스 요금을 지불할 필요가 없습니다.
교차 클라우드 구체화된 뷰
교차 클라우드 구체화된 뷰(CCMV)는 BigQuery Omni 리전에서 BigQuery Omni 이외의 BigQuery 리전으로 데이터를 점진적으로 전송합니다.
온라인 트랜잭션의 총 판매 요약을 전송하고 해당 데이터를 US 리전에 복제하는 새로운 CCMV를 설정합니다.
Ads Data Hub에서 CCMV에 액세스하여 다른 Ads Data Hub 데이터와 조인할 수 있습니다. CCMV는 대부분 일반 BigQuery 관리형 테이블과 같은 역할을 수행합니다.
로컬 구체화된 뷰 만들기
로컬 구체화된 뷰를 만들려면 다음 예시를 참조하세요.
-- Create a local materialized view that keeps track of total sales by day CREATE MATERIALIZED VIEW `aws_data.total_sales` OPTIONS (enable_refresh = true, refresh_interval_minutes = 60) AS SELECT EXTRACT(DAY FROM order_time) AS date, SUM(order_total) as sales FROM `listing_nto_john.nto_orders__dll` GROUP BY 1;
구체화된 뷰 승인
CCMV를 만들려면 구체화된 뷰를 승인해야 합니다. 뷰(aws_data.total_sales) 또는 데이터 세트(aws_data)를 승인할 수 있습니다. 구체화된 뷰를 승인하려면 다음 안내를 따르세요.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
소스 데이터 세트
listing_nto_john을 엽니다.공유를 클릭한 다음 데이터 세트 승인을 클릭합니다.
데이터 세트 이름(이 경우
listing_nto_john)을 입력한 다음 확인을 클릭합니다.
복제본 구체화된 뷰 만들기
US 리전에 새 복제본 구체화된 뷰를 만듭니다. 구체화된 뷰는 소스 데이터가 변경될 때마다 주기적으로 복제하여 복제본을 최신 상태로 유지합니다.
-- Create a replica MV in the us region. CREATE MATERIALIZED VIEW `us_data.total_sales_replica` AS REPLICA OF `aws_data.total_sales`;
복제본 구체화된 뷰에서 쿼리 실행
다음 예시에서는 복제본 구체화된 뷰에서 쿼리를 실행합니다.
-- Find total sales for the current month for the dashboard SELECT EXTRACT(MONTH FROM CURRENT_DATE()) as month, SUM(sales) FROM us_data.total_sales_replica WHERE month = EXTRACT(MONTH FROM date) GROUP BY 1
INFORMATION_SCHEMA에서 Data Cloud 데이터 사용
Data Cloud 데이터 세트는 BigQuery INFORMATION_SCHEMA 뷰를 지원합니다. INFORMATION_SCHEMA 뷰의 데이터는 Data Cloud에서 정기적으로 동기화되며 비활성 상태일 수 있습니다. TABLES 및 SCHEMATA 뷰의 SYNC_STATUS 열에는 마지막으로 완료된 동기화 시간, BigQuery가 새 데이터를 제공하지 못하게 모든 오류, 오류를 해결하는 데 필요한 단계가 표시됩니다.
INFORMATION_SCHEMA 쿼리는 초기 동기화 전에 최근에 생성된 데이터 세트를 반영하지 않습니다.
데이터 클라우드 데이터 세트에는, 데이터 세트 범위 쿼리에서 INFORMATION_SCHEMA에서만 액세스 가능처럼, 연결된 다른 데이터 세트와 동일한 제한사항이 적용됩니다.
다음 단계
BigQuery Omni 알아보기
교차 클라우드 조인에 대해 알아보세요.
구체화된 뷰에 대해 알아보세요.