Lavorare con i dati di Salesforce Data Cloud in BigQuery
Gli utenti di Data Cloud possono accedere ai propri dati di Data Cloud in modo nativo in BigQuery. Puoi analizzare i dati di Data Cloud con BigQuery Omni ed eseguire analisi tra cloud con i dati in Google Cloud. In questo documento forniamo istruzioni per accedere ai dati di Data Cloud e a diverse attività di analisi che puoi eseguire con questi dati in BigQuery.
Data Cloud funziona con BigQuery in base alla seguente architettura:
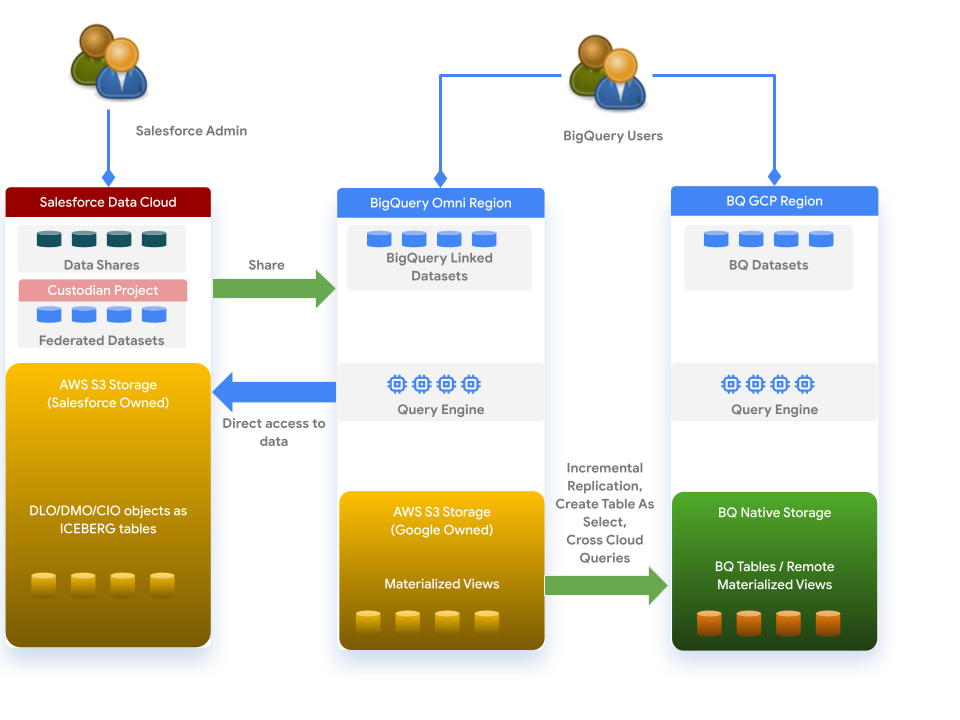
Prima di iniziare
Prima di utilizzare i dati di Data Cloud, devi essere un utente di Data Cloud. Se nel progetto sono abilitati i Controlli di servizio VPC, sono necessarie autorizzazioni aggiuntive.
Ruoli obbligatori
Sono richiesti i seguenti ruoli e autorizzazioni:
- Analytics Hub Subscriber (
roles/analyticshub.subscriber) - Amministratore BigQuery (
roles/bigquery.admin)
Condividere i dati da Data Cloud
Questa documentazione mostra come condividere i dati da Data Cloud a BigQuery - BYOL Data Shares - Zero-ETL Integration with BigQuery.
Collega il set di dati Data Cloud a BigQuery
Per accedere a un set di dati Data Cloud in BigQuery, devi prima collegarlo a BigQuery seguendo questi passaggi:
Nella Google Cloud console, vai alla pagina BigQuery.
Fai clic su Salesforce Data Cloud.
Vengono visualizzati i set di dati di Data Cloud. Puoi trovare il set di dati per nome utilizzando il seguente pattern di denominazione:
listing_DATA_SHARE_NAME_TARGET_NAME
DATA_SHARE_NAME: il nome della condivisione dei dati in Data Cloud.TARGET_NAME: il nome della destinazione BigQuery in Data Cloud.
Fai clic sul set di dati che vuoi aggiungere a BigQuery.
Fai clic su Aggiungi set di dati al progetto.
Specifica il nome del set di dati collegato.
Una volta creato il set di dati collegato, puoi esplorarlo e le tabelle al suo interno. Tutti i metadati delle tabelle vengono recuperati dinamicamente da Data Cloud. Tutti gli oggetti all'interno del set di dati sono visualizzazioni che mappano agli oggetti Data Cloud. BigQuery supporta tre tipi di oggetti Data Cloud:
- Oggetti data lake (DLO)
- Oggetti modello di dati (DMO)
- Oggetti di approfondimenti calcolati (CIO)
Tutti questi oggetti sono rappresentati come visualizzazioni in BigQuery. Queste viste rimandano a tabelle nascoste archiviate in Amazon S3.
Lavorare con i dati di Data Cloud
Gli esempi seguenti utilizzano un set di dati denominato Northwest Trail Outfitters (NTO) ospitato in Data Cloud. Questo set di dati è costituito da tre tabelle che rappresentano i dati sulle vendite online dell'organizzazione NTO:
linked_nto_john.nto_customers__dlllinked_nto_john.nto_products__dlllinked_nto_john.nto_orders__dll
L'altro set di dati utilizzato in questi esempi è costituito da dati offline dei punti di vendita. Copre le vendite offline e si compone di tre tabelle:
nto_pos.customersnto_pos.productsnto_pos.orders
I seguenti set di dati memorizzano oggetti aggiuntivi:
aws_dataus_data
Esegui query ad hoc
Con BigQuery Omni puoi eseguire query ad hoc per analizzare i dati di Data Cloud tramite il set di dati a cui hai effettuato l'iscrizione. L'esempio riportato di seguito mostra una query semplice che esegue query sulla tabella customers di Data Cloud.
SELECT name__c, age__c FROM `listing_nto_john.nto_customers__dll` WHERE age > 40 LIMIT 1000;
Esegui query cross-cloud
Le query tra cloud ti consentono di unire qualsiasi tabella nella regione BigQuery Omni e le tabelle nelle regioni BigQuery. Per ulteriori informazioni sulle query tra cloud, consulta questo post del blog.
In questo esempio, recuperiamo le vendite totali per un cliente denominato john.
-- Get combined sales for a customer from both offline and online sales USING ( SELECT total_price FROM `listing_nto_john.nto_orders__dll` WHERE customer_name = 'john' UNION ALL SELECT total_price FROM `listing_nto_john.nto_orders__dll` WHERE customer_name = 'john' ) a SELECT SUM(total_price);
Trasferimento dati cross-cloud tramite CTAS
Puoi utilizzare Crea tabella come selezione (CTAS) per spostare i dati dalle tabelle Data Cloud nella regione BigQuery Omni alla regione US.
-- Move all the orders for March to the US region CREATE OR REPLACE TABLE us_data.online_orders_march AS SELECT * FROM listing_nto_john.nto_orders__dll WHERE EXTRACT(MONTH FROM order_time) = 3
La tabella di destinazione è una tabella gestita BigQuery nella regione US. Questa tabella può essere unita ad altre tabelle. Questa operazione comporta costi di esportazione AWS in base alla quantità di dati trasferiti.
Una volta spostati i dati, non dovrai più pagare le tariffe di uscita per le query eseguite nella tabella online_orders_march.
Viste materializzate cross-cloud
Le viste materializzate cross cloud
(CCMV)
trasferiscono i dati in modo incrementale da una regione BigQuery Omni a una regione BigQuery non Omni.
Configura un nuovo CCMV che trasferisca un riepilogo delle vendite totali dalle transazioni online e replica questi dati nella regione US.
Puoi accedere ai CCMV da Ads Data Hub e unirli ad altri dati di Ads Data Hub. Per la maggior parte, le VM con controllo dei costi si comportano come le normali tabelle gestite BigQuery.
Creare una vista materializzata locale
Per creare una vista materializzata locale:
-- Create a local materialized view that keeps track of total sales by day CREATE MATERIALIZED VIEW `aws_data.total_sales` OPTIONS (enable_refresh = true, refresh_interval_minutes = 60) AS SELECT EXTRACT(DAY FROM order_time) AS date, SUM(order_total) as sales FROM `listing_nto_john.nto_orders__dll` GROUP BY 1;
Autorizza la vista materializzata
Per creare una vista combinata con misure personalizzate, devi autorizzare le viste materializzate. Puoi autorizzare la visualizzazione (aws_data.total_sales) o il set di dati (aws_data). Per autorizzare la vista materializzata:
Nella Google Cloud console, vai alla pagina BigQuery.
Apri il set di dati di origine
listing_nto_john.Fai clic su Condivisione e poi su Autorizza set di dati.
Inserisci il nome del set di dati (in questo caso
listing_nto_john) e fai clic su Ok.
Creare una vista materializzata della replica
Crea una nuova vista materializzata replica nella regione US. La vista materializzata viene replicata periodicamente ogni volta che si verifica una modifica dei dati di origine per mantenere aggiornata la replica.
-- Create a replica MV in the us region. CREATE MATERIALIZED VIEW `us_data.total_sales_replica` AS REPLICA OF `aws_data.total_sales`;
Eseguire una query su una vista materializzata della replica
L'esempio seguente esegue una query su una vista materializzata della replica:
-- Find total sales for the current month for the dashboard SELECT EXTRACT(MONTH FROM CURRENT_DATE()) as month, SUM(sales) FROM us_data.total_sales_replica WHERE month = EXTRACT(MONTH FROM date) GROUP BY 1
Utilizzo dei dati di Data Cloud con INFORMATION_SCHEMA
I set di dati Data Cloud supportano le visteINFORMATION_SCHEMA BigQuery. I dati nelle visualizzazioni INFORMATION_SCHEMA vengono
sincronizzati regolarmente da Data Cloud e potrebbero non essere aggiornati. La colonna SYNC_STATUS nelle visualizzazioni TABLES e SCHEMATA mostra l'ora dell'ultima sincronizzazione completata, eventuali errori che impediscono a BigQuery di fornire dati aggiornati e i passaggi necessari per correggere l'errore.
Le query INFORMATION_SCHEMA non riflettono i set di dati creati di recente prima della sincronizzazione iniziale.
I set di dati di Data Cloud sono soggetti alle stesse
limitazioni degli altri
set di dati collegati, ad esempio sono accessibili solo in INFORMATION_SCHEMA nelle
query basate sui set di dati.
Passaggi successivi
Scopri di più su BigQuery Omni.
Scopri di più sulle unioni tra cloud.
Scopri di più sulle viste con dati memorizzati in memoria.