运行查询
本文档介绍如何在 BigQuery 中运行查询,并通过执行试运行来了解查询在执行之前将处理多少数据。
查询类型
您可以使用以下查询作业类型之一来查询 BigQuery 数据:
交互式查询作业。默认情况下,BigQuery 会将查询作为交互式查询作业来运行,这类作业旨在尽快开始执行。
批量查询作业。批量查询的优先级低于交互式查询。当项目或预留在使用其所有可用计算资源时,批量查询更有可能被排入队列并保留在队列中。批量查询开始运行后,其运行方式与交互式查询相同。如需了解详情,请参阅查询队列。
持续查询作业。 借助这些作业,查询会持续运行,让您能够实时分析 BigQuery 中的传入数据,然后将结果写入 BigQuery 表,或将结果导出到 Bigtable 或 Pub/Sub。您可以使用此功能执行对时间敏感的任务,例如创建数据洞见并立即采取行动、应用实时机器学习 (ML) 推理,以及构建事件驱动型数据流水线。
您可以使用以下方法运行查询作业:
- 在Google Cloud 控制台中编写和运行查询。
- 在 bq 命令行工具中运行
bq query命令。 - 以编程方式调用 BigQuery REST API 中的
jobs.query或jobs.insert方法。 - 使用 BigQuery 客户端库。
BigQuery 会将查询结果保存到临时表(默认)或永久表中。指定永久表作为结果的目标表时,您可以选择是附加还是覆盖现有表,或者创建具有唯一名称的新表。
所需的角色
如需获得运行查询作业所需的权限,请让您的管理员为您授予以下 IAM 角色:
-
针对项目的 BigQuery Job User (
roles/bigquery.jobUser)。 -
针对查询引用的所有表和视图的 BigQuery Data Viewer (
roles/bigquery.dataViewer)。如需查询视图,您还需要在所有底层表和视图上使用此角色。如果您使用的是已获授权的视图或已获授权的数据集,则无需访问底层源数据。
如需详细了解如何授予角色,请参阅管理对项目、文件夹和组织的访问权限。
这些预定义角色可提供运行查询作业所需的权限。如需查看所需的确切权限,请展开所需权限部分:
所需权限
如需运行查询作业,您需要拥有以下权限:
问题排查
Access Denied: Project [project_id]: User does not have bigquery.jobs.create
permission in project [project_id].
如果主账号缺少在项目中创建查询作业的权限,则会发生此错误。
解决方法:管理员必须为您授予要查询的项目的 bigquery.jobs.create 权限。除了访问查询的数据所需的任何权限之外,还需要拥有此权限。
如需详细了解 BigQuery 权限,请参阅使用 IAM 进行访问权限控制。
运行交互式查询
如需运行交互式查询,请选择以下任一选项:
控制台
前往 BigQuery 页面。
点击 SQL 查询。
在查询编辑器中,输入有效的 GoogleSQL 查询。
例如,查询 BigQuery 公开数据集
usa_names,以确定 1910 年至 2013 年间美国人最常用的名字:SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;或者,您也可以使用参考面板来构建新查询。
可选:如需在您输入查询时自动显示代码建议,请点击 更多,然后选择 SQL 自动补全。如果您不需要自动补全建议,请取消选择 SQL 自动补全。这还会关闭项目名称自动填充建议。
可选:如需选择其他查询设置,请点击 更多,然后点击查询设置。
点击 运行。
如果未指定目标表,则查询作业会将输出写入临时(缓存)表。
现在,您可以在查询结果窗格的结果标签页中探索查询结果。
可选:如需按列对查询结果进行排序,请点击列名称旁边的 打开排序菜单,然后选择排序顺序。如果针对排序处理的估算字节数大于零,则菜单顶部会显示字节数。
可选:如需查看查询结果的可视化效果,请前往可视化图表标签页。您可以放大或缩小图表,将图片下载为 PNG 文件,也可以切换图例的可见性。
在可视化图表配置窗格中,您可以更改可视化图表类型,并配置可视化图表的测量和维度。此窗格中的字段预先填充了从查询的目标表架构推断的初始配置。在同一查询编辑器中的以下查询运行之间会保留配置。
对于折线图、条形图或散点图可视化图表,支持的维度数据类型为
INT64、FLOAT64、NUMERIC、BIGNUMERIC、TIMESTAMP、DATE、DATETIME、TIME和STRING,而支持的测量数据类型为INT64、FLOAT64、NUMERIC和BIGNUMERIC。如果查询结果包含
GEOGRAPHY类型,则默认的可视化图表类型为地图,您可以在互动式地图上直观呈现结果。可选:在 JSON 标签页中,您可以采用 JSON 格式探索查询结果,其中键是列名称,值是该列的结果。
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
使用
bq query命令。 在以下示例中,--use_legacy_sql=false标志可让您使用 GoogleSQL 语法。bq query \ --use_legacy_sql=false \ 'QUERY'
将 QUERY 替换为有效的 GoogleSQL 查询。例如,查询 BigQuery 公开数据集
usa_names,以确定 1910 年至 2013 年间美国人最常用的名字:bq query \ --use_legacy_sql=false \ 'SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;'查询作业将输出写入临时(缓存)表。
(可选)您可以为查询结果指定目标表和位置。如需将结果写入现有表,请添加适当的标志以附加 (
--append_table=true) 或覆盖 (--replace=true) 表。bq query \ --location=LOCATION \ --destination_table=TABLE \ --use_legacy_sql=false \ 'QUERY'
请替换以下内容:
LOCATION:目标表的单区域或多区域,例如
US在此示例中,
usa_names数据集存储在美国多区域位置。如果您为此查询指定目标表,则包含目标表的数据集也必须位于美国多区域中。您无法查询一个位置的数据集而将结果写入另一个位置的表。您可以使用 .bigqueryrc 文件设置位置的默认值。
TABLE:目标表的名称,例如
myDataset.myTable如果目标表是新表,则 BigQuery 会在运行查询时创建表。但是,您必须指定现有数据集。
如果该表不在当前项目中,请使用
PROJECT_ID:DATASET.TABLE格式添加Google Cloud 项目 ID,例如myProject:myDataset.myTable。如果未指定--destination_table,系统会生成一个将输出写入临时表的查询作业。
API
如需使用 API 运行查询,请插入新作业,并填写 query 作业配置属性。(可选)在作业资源 jobReference 部分的 location 属性中指定您的位置。
通过调用 getQueryResults 提取结果,直到 jobComplete 等于 true。检查 errors 列表中是否存在错误和警告。
C#
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 C# 设置说明进行操作。 如需了解详情,请参阅 BigQuery C# API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
Go
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Go 设置说明进行操作。 如需了解详情,请参阅 BigQuery Go API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
Java
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Java 设置说明进行操作。 如需了解详情,请参阅 BigQuery Java API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
如需使用代理运行查询,请参阅配置代理。
Node.js
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Node.js 设置说明进行操作。 如需了解详情,请参阅 BigQuery Node.js API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
PHP
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 PHP 设置说明进行操作。 如需了解详情,请参阅 BigQuery PHP API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
Python
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Python 设置说明进行操作。 如需了解详情,请参阅 BigQuery Python API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
Ruby
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Ruby 设置说明进行操作。 如需了解详情,请参阅 BigQuery Ruby API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
运行批量查询
如需运行批量查询,请选择以下任一选项:
控制台
前往 BigQuery 页面。
点击 SQL 查询。
在查询编辑器中,输入有效的 GoogleSQL 查询。
例如,查询 BigQuery 公开数据集
usa_names,以确定 1910 年至 2013 年间美国人最常用的名字:SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;点击 更多,然后点击查询设置。
在资源管理部分,选择批量。
可选:调整查询设置。
点击保存。
点击 运行。
如果未指定目标表,则查询作业会将输出写入临时(缓存)表。
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
使用
bq query命令并指定--batch标志。在以下示例中,--use_legacy_sql=false标志可让您使用 GoogleSQL 语法。bq query \ --batch \ --use_legacy_sql=false \ 'QUERY'
将 QUERY 替换为有效的 GoogleSQL 查询。例如,查询 BigQuery 公开数据集
usa_names,以确定 1910 年至 2013 年间美国人最常用的名字:bq query \ --batch \ --use_legacy_sql=false \ 'SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;'查询作业将输出写入临时(缓存)表。
(可选)您可以为查询结果指定目标表和位置。如需将结果写入现有表,请添加适当的标志以附加 (
--append_table=true) 或覆盖 (--replace=true) 表。bq query \ --batch \ --location=LOCATION \ --destination_table=TABLE \ --use_legacy_sql=false \ 'QUERY'
请替换以下内容:
LOCATION:目标表的单区域或多区域,例如
US在此示例中,
usa_names数据集存储在美国多区域位置。如果您为此查询指定目标表,则包含目标表的数据集也必须位于美国多区域中。您无法查询一个位置的数据集而将结果写入另一个位置的表。您可以使用 .bigqueryrc 文件设置位置的默认值。
TABLE:目标表的名称,例如
myDataset.myTable如果目标表是新表,则 BigQuery 会在运行查询时创建表。但是,您必须指定现有数据集。
如果该表不在当前项目中,请使用
PROJECT_ID:DATASET.TABLE格式添加Google Cloud 项目 ID,例如myProject:myDataset.myTable。如果未指定--destination_table,系统会生成一个将输出写入临时表的查询作业。
API
如需使用 API 运行查询,请插入新作业,并填写 query 作业配置属性。(可选)在作业资源 jobReference 部分的 location 属性中指定您的位置。
填写查询作业属性时,请包含 configuration.query.priority 属性并将其值设置为 BATCH。
通过调用 getQueryResults 提取结果,直到 jobComplete 等于 true。检查 errors 列表中是否存在错误和警告。
Go
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Go 设置说明进行操作。 如需了解详情,请参阅 BigQuery Go API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
Java
如需运行批量查询,请在创建 QueryJobConfiguration 时将查询优先级设置为 QueryJobConfiguration.Priority.BATCH。
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Java 设置说明进行操作。 如需了解详情,请参阅 BigQuery Java API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
Node.js
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Node.js 设置说明进行操作。 如需了解详情,请参阅 BigQuery Node.js API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
Python
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Python 设置说明进行操作。 如需了解详情,请参阅 BigQuery Python API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
运行持续查询
运行持续查询作业需要额外的配置。如需了解详情,请参阅创建持续查询。
使用参考面板
在查询编辑器中,参考信息面板会动态显示有关表、快照、视图和物化视图的情境感知信息。您可以在该面板中预览这些资源的架构详细信息,或在新标签页中打开这些资源。您还可以使用参考面板,通过插入查询片段或字段名称来构建新查询或修改现有查询。
如需使用参考面板构建新查询,请按照以下步骤操作:
在 Google Cloud 控制台中,前往 BigQuery 页面。
点击 SQL 查询。
点击 quick_reference_all 参考。
点击最近使用或已加星标的表或视图。您还可以使用搜索栏查找表和视图。
点击 查看操作,然后点击插入查询片段。
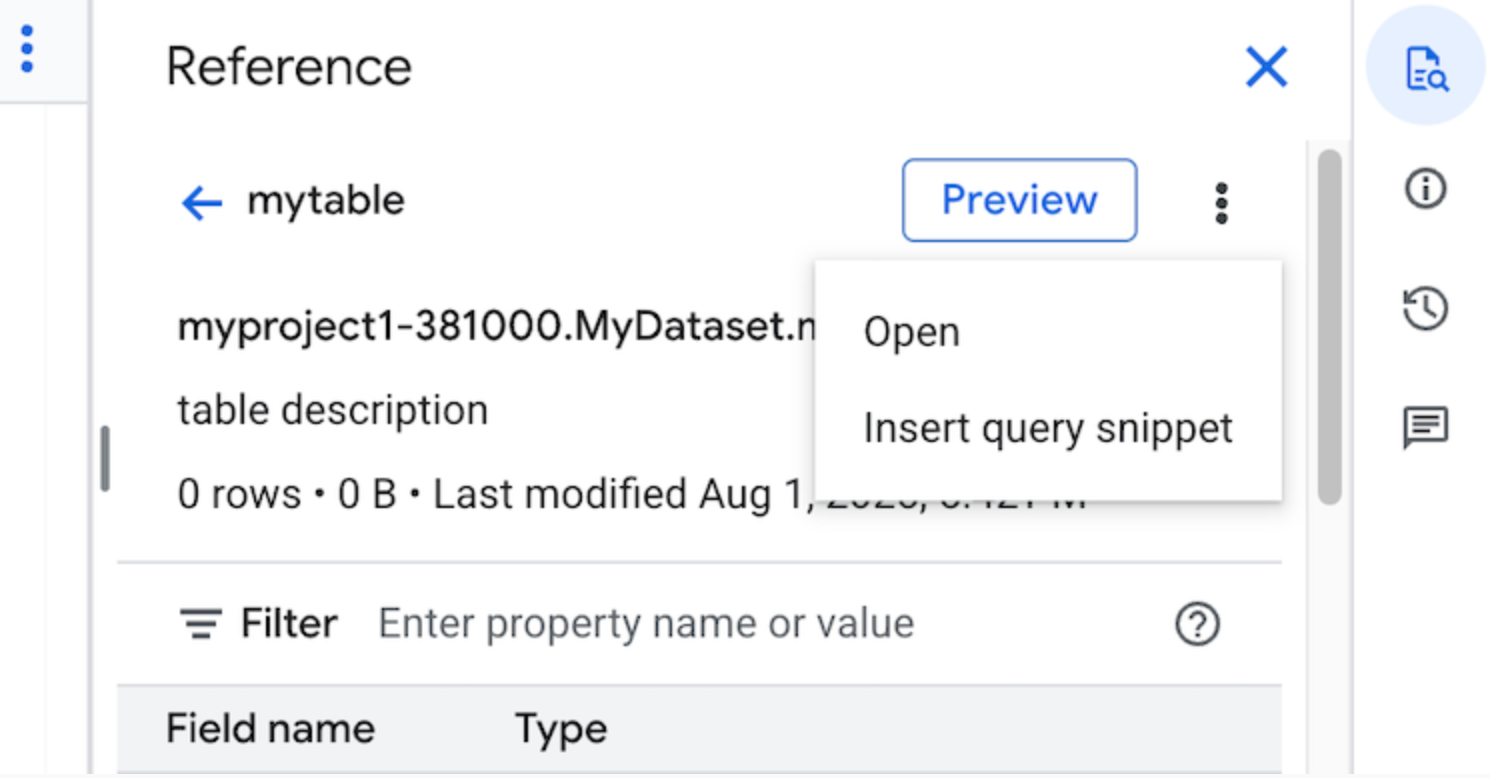
可选:您可以预览表或视图的架构详细信息,也可以在新标签页中打开它们。
现在,您可以手动修改查询,也可以直接在查询中插入字段名称。如需插入字段名称,请在查询编辑器中指向并点击要插入字段名称的位置,然后点击参考面板中的字段名称。
查询设置
运行查询时,您可以指定以下设置:
查询结果的目标表。
作业的优先级。
是否使用缓存的查询结果。
作业超时时长(以毫秒为单位)。
是否使用会话模式。
要使用的加密类型。
查询的收费字节数上限。
要使用的 SQL 方言。
要在其中运行查询的位置。查询的运行位置必须与查询中引用的任何表相同。
可选作业创建模式
可选作业创建模式可以减少短时间运行的查询(例如来自信息中心或数据探索工作负载的查询)的总体延迟时间。此模式会执行查询,并针对 SELECT 语句返回内嵌结果,而无需使用 jobs.getQueryResults 提取结果。使用可选作业创建模式的查询在执行时不会创建作业,除非 BigQuery 确定需要创建作业才能完成查询。
如需启用可选作业创建模式,请在 jobs.query 请求正文中将 QueryRequest 实例的 jobCreationMode 字段设置为 JOB_CREATION_OPTIONAL。
当此字段的值设置为 JOB_CREATION_OPTIONAL 时,BigQuery 会确定查询是否可以使用可选作业创建模式。如果可以,BigQuery 会执行查询并在响应的 rows 字段中返回所有结果。由于未为此查询创建作业,因此 BigQuery 不会在响应正文中返回 jobReference。BigQuery 会返回 queryId 字段,您可以通过该字段使用 INFORMATION_SCHEMA.JOBS 视图获取有关查询的数据分析。由于系统不会创建任何作业,因此没有 jobReference 可传递给 jobs.get 和 jobs.getQueryResults API 来查找这些查询。
如果 BigQuery 确定需要某项作业才能完成查询,则系统会返回 jobReference。您可以检查 INFORMATION_SCHEMA.JOBS 视图中的 job_creation_reason 字段,以确定为查询创建作业的原因。在这种情况下,您应在查询完成后使用 jobs.getQueryResults 提取结果。
使用 JOB_CREATION_OPTIONAL 值时,响应中可能不存在 jobReference 字段。请在访问之前检查该字段是否存在。
为多语句查询(脚本)指定 JOB_CREATION_OPTIONAL 时,BigQuery 可能会优化执行过程。作为此优化的一部分,BigQuery 可能会确定,它可以通过创建少于语句数量的作业资源来完成脚本,甚至可能根本不创建任何作业即可执行整个脚本。此优化取决于 BigQuery 对脚本的评估,可能不会在所有情况下都应用此优化。优化完全由系统自动实现。无需用户控制或操作。
如需使用可选作业创建模式运行查询,请选择以下选项之一:
控制台
前往 BigQuery 页面。
点击 SQL 查询。
在查询编辑器中,输入有效的 GoogleSQL 查询。
例如,查询 BigQuery 公开数据集
usa_names,以确定 1910 年至 2013 年间美国人最常用的名字:SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;点击 更多,然后选择可选作业创建模式查询模式。如需确认此选择,请点击确认。
点击 运行。
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
使用
bq query命令并指定--job_creation_mode=JOB_CREATION_OPTIONAL标志。在以下示例中,--use_legacy_sql=false标志可让您使用 GoogleSQL 语法。bq query \ --rpc=true \ --use_legacy_sql=false \ --job_creation_mode=JOB_CREATION_OPTIONAL \ --location=LOCATION \ 'QUERY'
将 QUERY 替换为有效的 GoogleSQL 查询,并将 LOCATION 替换为数据集所在的有效区域。例如,查询 BigQuery 公开数据集
usa_names,以确定 1910 年至 2013 年期间美国最常用的名字:bq query \ --rpc=true \ --use_legacy_sql=false \ --job_creation_mode=JOB_CREATION_OPTIONAL \ --location=us \ 'SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;'查询作业会在响应中返回内嵌的输出。
API
如需使用 API 在可选作业创建模式下运行查询,请同步运行查询并填充 QueryRequest 属性。添加属性 jobCreationMode,并将其值设置为 JOB_CREATION_OPTIONAL。
检查响应。如果 jobComplete 等于 true 且 jobReference 为空,请从 rows 字段中读取结果。您也可以从响应中获取 queryId。
如果存在 jobReference,您可以检查 jobCreationReason 以了解 BigQuery 创建作业的原因。通过调用 getQueryResults 轮询结果,直到 jobComplete 等于 true。检查 errors 列表中是否存在错误和警告。
Java
可用版本:2.51.0 及更高版本
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Java 设置说明进行操作。 如需了解详情,请参阅 BigQuery Java API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
如需使用代理运行查询,请参阅配置代理。
Python
可用版本:3.34.0 及更高版本
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Python 设置说明进行操作。 如需了解详情,请参阅 BigQuery Python API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
节点
可用版本:8.1.0 及更高版本
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Node.js 设置说明进行操作。 如需了解详情,请参阅 BigQuery Node.js API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
Go
可用版本:1.69.0 及更高版本
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Go 设置说明进行操作。 如需了解详情,请参阅 BigQuery Go API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
JDBC 驱动程序
可用版本:JDBC v1.6.1 及更高版本
需要在连接字符串中设置 JobCreationMode=2。
jdbc:bigquery://https://www.googleapis.com/bigquery/v2:443;JobCreationMode=2;Location=US;
ODBC 驱动程序
可用版本:ODBC v3.0.7.1016 及更高版本
需要在 .ini 文件中设置 JobCreationMode=2。
[ODBC Data Sources] Sample DSN=Simba Google BigQuery ODBC Connector 64-bit [Sample DSN] JobCreationMode=2
配额
如需了解交互式查询和批量查询的配额,请参阅查询作业。
监控查询
您可以使用 Jobs Explorer 或查询 INFORMATION_SCHEMA.JOBS_BY_PROJECT 视图,从而在查询执行时获取有关查询的信息。
试运行
BigQuery 中的试运行提供以下信息:
试运行不使用查询槽,您不需要为执行试运行支付费用。您可以使用试运行返回的估算值在价格计算器中计算查询费用。
执行试运行
如需执行试运行,请执行以下操作:
控制台
转到 BigQuery 页面。
在查询编辑器中输入查询。
如果查询有效,则会自动显示一个对勾标记以及查询将处理的数据量。如果查询无效,则会显示一个感叹号,并会显示错误消息。
bq
使用 --dry_run 标志输入如下所示的查询。
bq query \ --use_legacy_sql=false \ --dry_run \ 'SELECT COUNTRY, AIRPORT, IATA FROM `project_id`.dataset.airports LIMIT 1000'
对于有效查询,该命令会生成以下响应:
Query successfully validated. Assuming the tables are not modified, running this query will process 10918 bytes of data.
API
如需使用 API 执行试运行,请提交一项查询作业,并在 JobConfiguration 类型中将 dryRun 设置为 true。
Go
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Go 设置说明进行操作。 如需了解详情,请参阅 BigQuery Go API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
Java
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Java 设置说明进行操作。 如需了解详情,请参阅 BigQuery Java API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
Node.js
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Node.js 设置说明进行操作。 如需了解详情,请参阅 BigQuery Node.js API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
PHP
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 PHP 设置说明进行操作。 如需了解详情,请参阅 BigQuery PHP API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
Python
将 QueryJobConfig.dry_run 属性设置为 True。如果提供了试运行查询配置,Client.query() 将始终返回已完成的 QueryJob。
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Python 设置说明进行操作。 如需了解详情,请参阅 BigQuery Python API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。