Organiser les ressources BigQuery
Comme les autres services, les ressources BigQuery sont organisées de façon hiérarchique. Google Cloud Vous pouvez utiliser cette hiérarchie pour gérer certains aspects de vos charges de travail BigQuery, tels que les autorisations, les quotas, les réservations d'emplacements et la facturation.
Hiérarchie des ressources
BigQuery hérite de la hiérarchie des ressourcesGoogle Cloud et ajoute un mécanisme de regroupement supplémentaire appelé ensembles de données, qui sont spécifiques à BigQuery. Cette section décrit les éléments de cette hiérarchie.
Ensembles de données
Les ensembles de données sont des conteneurs logiques utilisés pour organiser et contrôler l'accès à vos ressources BigQuery. Les ensembles de données sont semblables aux schémas d'autres systèmes de base de données.
La plupart des ressources BigQuery que vous créez (y compris les tables, les vues, les fonctions et les procédures) sont créées dans un ensemble de données. Les connexions et les tâches sont des exceptions. Elles sont associées à des projets plutôt qu'à des ensembles de données.
Un ensemble de données possède un emplacement. Lorsque vous créez une table, les données de la table sont stockées à l'emplacement de l'ensemble de données. Avant de créer des tables pour des données de production, pensez à vos exigences en matière d'emplacement. Il n'est pas possible de modifier l'emplacement d'un ensemble de données après sa création.
Projets
Chaque ensemble de données est associé à un projet. Pour utiliser Google Cloud, vous devez créer au moins un projet. Les projets constituent la base de la création, de l'activation et de l'utilisation de tous les services Google Cloud . Pour en savoir plus, consultez la section Hiérarchie des ressources. Un projet peut contenir plusieurs ensembles de données, et des ensembles de données avec différents emplacements peuvent exister dans le même projet.
Lorsque vous effectuez des opérations sur vos données BigQuery, telles que l'exécution d'une requête ou l'ingestion de données dans une table, vous créez une tâche. Une tâche est toujours associée à un projet, mais elle n'a pas besoin de s'exécuter dans le même projet qui contient les données. En fait, une tâche peut faire référence à des tables provenant d'ensembles de données de plusieurs projets. Une tâche de requête, de chargement ou d'exportation s'exécute toujours au même emplacement que les tables auxquelles elle fait référence.
Chaque projet est associé à un compte de facturation Cloud. Les coûts générés par un projet sont facturés sur ce compte. Si vous utilisez un tarif à la demande, vos requêtes sont facturées au projet qui les exécute. Si vous appliquez une tarification basée sur la capacité, vos réservations d'emplacements sont facturées au projet d'administration utilisé pour l'achat des emplacements. Le stockage est facturé dans le projet où réside l'ensemble de données.
Dossiers
Les dossiers sont un mécanisme de regroupement supplémentaire de niveau supérieur aux projets. Les projets et les dossiers d'un dossier héritent automatiquement des stratégies d'accès de son dossier parent. Les dossiers peuvent être utilisés pour modéliser différentes entités juridiques, services et équipes au sein d'une entreprise.
Organisations
La ressource Organisation représente une organisation (comme une entreprise) et constitue le nœud racine de la hiérarchie des ressourcesGoogle Cloud .
Vous n'avez pas besoin d'une ressource Organisation pour commencer à utiliser BigQuery, mais nous vous recommandons d'en créer une. L'utilisation d'une ressource Organisation permet aux administrateurs de contrôler de manière centralisée vos ressources BigQuery, plutôt que de laisser les utilisateurs individuels contrôler les ressources qu'ils créent.
Le schéma suivant montre un exemple de hiérarchie des ressources. Dans cet exemple, l'organisation possède un projet dans un dossier. Le projet est associé à un compte de facturation et contient trois ensembles de données.
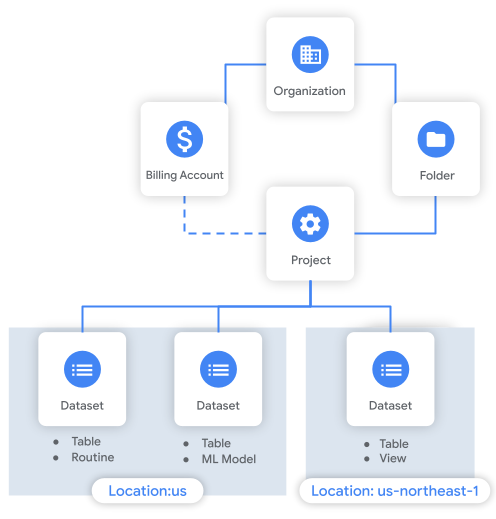
Remarques
Lorsque vous choisissez l'organisation des ressources BigQuery, tenez compte des points suivants :
- Quotas. De nombreux quotas BigQuery sont appliqués au niveau du projet. Quelques-uns s'appliquent au niveau de l'ensemble de données. Les quotas au niveau du projet qui impliquent des ressources de calcul, telles que les requêtes et les tâches de chargement, sont comptabilisés dans le projet qui crée la tâche, plutôt que dans le projet de stockage.
- Facturation. Si vous souhaitez que différents services de votre organisation utilisent des comptes de facturation Cloud différents, créez des projets différents pour chaque équipe. Créez les comptes de facturation Cloud au niveau de l'organisation et associez-les aux projets.
- Réservations d'emplacements. Les emplacements réservés sont limités à la ressource Organisation. Une fois que vous avez acheté une capacité d'emplacements réservée, vous pouvez attribuer un pool d'emplacements à tout projet ou dossier de l'organisation, ou attribuer des emplacements à l'ensemble de la ressource Organisation. Les projets héritent des réservations d'emplacements de leur organisation parente ou de leur dossier parent. Les emplacements réservés sont associés à un projet d'administration, qui permet de gérer les emplacements. Pour en savoir plus, consultez la section Gérer la charge de travail à l'aide de Reservations.
Autorisations. Examinez l'impact de votre hiérarchie d'autorisations sur les membres de votre organisation qui ont besoin d'accéder aux données. Par exemple, si vous souhaitez permettre à une équipe d'accéder à des données spécifiques, vous pouvez stocker ces données dans un seul projet pour simplifier la gestion des accès.
Les tables et autres entités héritent des autorisations de leur ensemble de données parent. Les ensembles de données héritent des autorisations de leurs entités parentes dans la hiérarchie des ressources (projets, dossiers, organisations). Pour effectuer une opération sur une ressource, un utilisateur doit disposer des autorisations pertinentes sur la ressource, et également des autorisations permettant de créer une tâche BigQuery. L'autorisation de créer une tâche est associée au projet utilisé pour cette tâche.
Modèles
Cette section présente deux modèles courants d'organisation des ressources BigQuery.
Lac de données central, magasins de données du service L'organisation crée un projet de stockage unifié pour stocker ses données brutes. Les services de l'organisation créent leurs propres projets de magasin de données à analyser.
Lacs de données du service, entrepôt de données central Chaque service crée et gère son propre projet de stockage pour stocker les données brutes de ce service. L'organisation crée ensuite un projet d'entrepôt de données central pour l'analyse.
Chaque approche présente des avantages et des compromis. De nombreuses organisations combinent des éléments des deux modèles.
Lac de données central, magasins de données du service
Dans ce modèle, vous créez un projet de stockage unifié pour stocker les données brutes de votre organisation. Votre pipeline d'ingestion de données peut également s'exécuter dans ce projet. Le projet de stockage unifié agit comme un lac de données pour votre organisation.
Chaque service dispose de son propre projet dédié, qui permet d'interroger les données, d'enregistrer les résultats de la requête et de créer des vues. Ces projets au niveau du service agissent comme des magasins de données. Ils sont associés au compte de facturation du service.
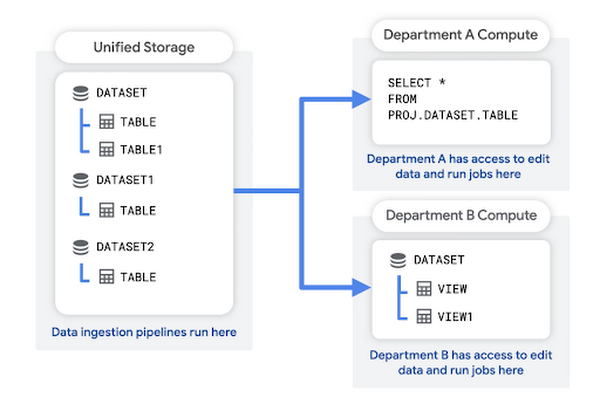
Les avantages de cette structure sont les suivants :
- Une équipe centralisée d'ingénierie des données peut gérer le pipeline d'ingestion de manière centralisée.
- Les données brutes sont isolées des projets au niveau du service.
- Avec la tarification à la demande, la facturation des requêtes en cours d'exécution est facturée au service qui les exécute.
- Avec la tarification basée sur la capacité, vous pouvez attribuer des emplacements à chaque service en fonction des besoins en calcul prévus.
- Chaque service est isolé des autres en termes de quotas au niveau du projet.
Lorsque vous utilisez cette structure, les autorisations suivantes sont typiques :
- L'équipe centrale d'ingénierie des données se voit attribuer les rôles "Éditeur de données BigQuery" et "Utilisateur de tâche BigQuery" pour le projet de stockage. Ils permettent d'ingérer et de modifier des données dans le projet de stockage.
- Le rôle de lecteur de données BigQuery est attribué aux analystes de services pour des ensembles de données spécifiques dans le projet de lac de données central. Cela leur permet d'interroger les données, mais pas de mettre à jour ni de supprimer les données brutes.
- Les analystes de service reçoivent également le rôle "Éditeur de données BigQuery" et "Utilisateur de tâche" pour le projet de magasin de données de leur service. Cela leur permet de créer et de mettre à jour des tables dans leur projet et d'exécuter des tâches de requête, afin de transformer et d'agréger les données en fonction de l'utilisation spécifique à un service.
Pour en savoir plus, consultez la page Rôles et autorisations de base.
Lacs de données du service, entrepôt de données central
Dans ce modèle, chaque service crée et gère son propre projet de stockage, qui contient les données brutes de ce service. Un projet d'entrepôt de données central stocke les agrégations ou les transformations des données brutes.
Les analystes peuvent interroger et lire les données agrégées du projet d'entrepôt de données. Le projet d'entrepôt de données fournit également une couche d'accès pour les outils d'informatique décisionnelle.
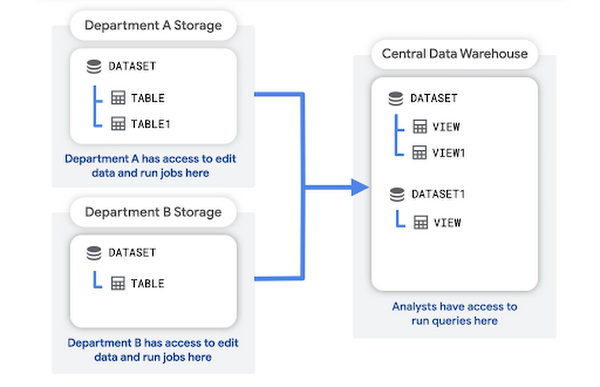
Les avantages de cette structure sont les suivants :
- Il est plus simple de gérer l'accès aux données au niveau du service en utilisant des projets distincts pour chaque service.
- Une équipe d'analyse centrale dispose d'un seul projet pour l'exécution des tâches d'analyse, ce qui facilite la surveillance des requêtes.
- Les utilisateurs peuvent accéder aux données à partir d'un outil d'informatique décisionnelle centralisé, qui est isolé des données brutes.
- Des emplacements peuvent être attribués au projet d'entrepôt de données pour gérer toutes les requêtes provenant d'analystes et d'outils externes.
Lorsque vous utilisez cette structure, les autorisations suivantes sont typiques :
- Les ingénieurs de données se voient attribuer des rôles "Éditeur de données BigQuery" et "Utilisateur de tâche BigQuery" dans le magasin de données de leur service. Ces rôles leur permettent d'ingérer et de transformer des données dans leur magasin de données.
- Les analystes se voient attribuer des rôles "Éditeur de données BigQuery" et "Utilisateur de tâche BigQuery" dans le projet d'entrepôt de données. Ces rôles leur permettent de créer des vues agrégées dans l'entrepôt de données et d'exécuter des tâches de requête.
- Les comptes de service qui connectent BigQuery aux outils d'informatique décisionnelle se voient attribuer le rôle de lecteur de données BigQuery pour des ensembles de données spécifiques, qui peuvent contenir des données brutes du lac de données ou des données transformées du projet de l'entrepôt de données.
Pour en savoir plus, consultez la page Rôles et autorisations de base.
Vous pouvez également utiliser des fonctionnalités de sécurité telles que les vues autorisées et les fonctions définies par l'utilisateur autorisées pour rendre les données agrégées disponibles à certains utilisateurs, sans leur accorder l'autorisation de consulter les données brutes dans les projets de magasin de données.
Cette structure de projet peut entraîner de nombreuses requêtes simultanées dans le projet d'entrepôt de données. Vous risquez donc d'atteindre la limite de requêtes simultanées. Si vous adoptez cette structure, envisagez d'augmenter cette limite de quota pour le projet. Pensez également à utiliser la facturation basée sur la capacité pour acheter un pool d'emplacements afin d'exécuter les requêtes.