BigQuery-Ressourcen organisieren
Wie andere Google Cloud -Dienste sind BigQuery-Ressourcen in einer Hierarchie organisiert. Sie können diese Hierarchie zur Verwaltung von Aspekten Ihrer BigQuery-Arbeitslasten verwenden, z. B. Berechtigungen, Kontingente, Slot-Reservierungen und Abrechnungen.
Ressourcenhierarchie
BigQuery übernimmt die Google Cloud -Ressourcenhierarchie und fügt einen zusätzlichen BigQuery-Gruppierungsmechanismus namens Datasets hinzu. In diesem Abschnitt werden die Elemente dieser Hierarchie beschrieben.
Datasets
Datasets sind logische Container, mit denen Sie den Zugriff auf Ihre BigQuery-Ressourcen organisieren und steuern können. Datasets ähneln Schemas in anderen Datenbanksystemen.
Die meisten von Ihnen erstellten BigQuery-Ressourcen, einschließlich Tabellen, Ansichten, Funktionen und Verfahren, werden innerhalb eines Datasets erstellt. Verbindungen und Jobs sind Ausnahmen. Diese sind mit Projekten statt mit Datasets verknüpft.
Ein Dataset hat einen Standort. Wenn Sie eine Tabelle erstellen, werden die Tabellendaten am Speicherort des Datasets gespeichert. Berücksichtigen Sie vor dem Erstellen von Tabellen für Produktionsdaten Ihre Standortanforderungen. Sie können den Standort eines Datasets nach seiner Erstellung nicht mehr ändern.
Projekte
Jedes Dataset ist mit einem Projekt verknüpft. Sie müssen mindestens ein Projekt erstellen, um Google Cloudverwenden zu können. Projekte bilden die Grundlage zum Erstellen, Aktivieren und Verwenden aller Google Cloud -Dienste. Weitere Informationen finden Sie unter Ressourcenhierarchie. Ein Projekt kann mehrere Datasets enthalten. Im selben Projekt können sich Datasets mit unterschiedlichen Standorten befinden.
Wenn Sie Vorgänge mit Ihren BigQuery-Daten ausführen, z. B. eine Abfrage ausführen oder Daten in eine Tabelle aufnehmen, erstellen Sie einen Job. Ein Job ist immer mit einem Projekt verknüpft, muss aber nicht in demselben Projekt ausgeführt werden, das die Daten enthält. Ein Job kann tatsächlich auf Tabellen aus Datasets in mehreren Projekten verweisen. Ein Abfrage-, Lade- oder Extraktionsjob wird immer am selben Speicherort wie die Tabellen ausgeführt, auf die er verweist.
Jedem Projekt ist ein Cloud-Rechnungskonto zugeordnet. Die für ein Projekt angefallenen Kosten werden über dieses Konto abgerechnet. Wenn Sie On-Demand-Preise verwenden, werden Ihre Abfragen dem Projekt in Rechnung gestellt, in dem die Abfrage ausgeführt wird. Wenn Sie einen kapazitätsbasierten Preis verwenden, werden Ihre Slot-Reservierungen dem Administrationsprojekt in Rechnung gestellt, mit dem die Slots erworben wurden. Speicherplatz wird dem Projekt in Rechnung gestellt, in dem sich das Dataset befindet.
Ordner
Als weiterer Gruppierungsmechanismus sind Projekten Ordner übergeordnet. Projekte und Ordner innerhalb eines Ordners übernehmen automatisch die Zugriffsrichtlinien ihres übergeordneten Ordners. Ordner können verschiedene Rechtspersönlichkeiten, Abteilungen und Teams innerhalb eines Unternehmens darstellen.
Organisationen
Die Organisationsressource stellt eine Organisation (z. B. ein Unternehmen) dar und ist der Stammknoten in derGoogle Cloud -Ressourcenhierarchie.
Sie benötigen keine Organisationsressource, um mit BigQuery zu arbeiten. Wir empfehlen jedoch, eine zu erstellen. Mit einer Organisationsressource können Administratoren Ihre BigQuery-Ressourcen zentral steuern. Nutzer steuern dann nicht die von ihnen erstellten Ressourcen.
Das folgende Diagramm zeigt ein Beispiel für die Ressourcenhierarchie. In diesem Beispiel hat die Organisation ein Projekt in einem Ordner. Das Projekt ist mit einem Rechnungskonto verknüpft und enthält drei Datasets.
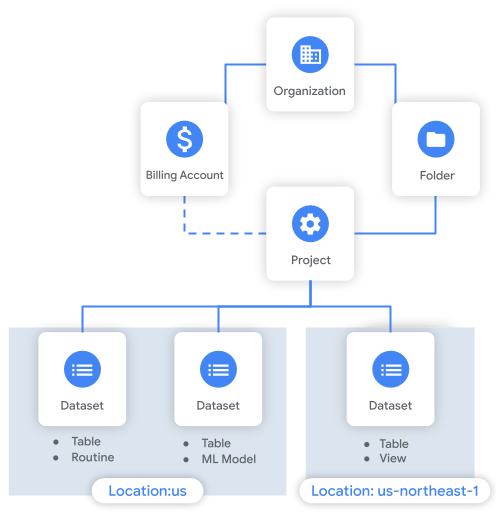
Hinweise
Beachten Sie die folgenden Punkte, wenn Sie auswählen, wie Sie Ihre BigQuery-Ressourcen organisieren:
- Kontingente. Viele BigQuery-Kontingente werden auf Projektebene angewendet. Einige gelten auf Dataset-Ebene. Kontingente auf Projektebene, die Rechenressourcen wie Abfragen und Ladejobs umfassen, werden auf das Projekt angerechnet, das den Job erstellt, nicht auf das Speicherprojekt.
- Abrechnung. Wenn verschiedene Abteilungen in Ihrer Organisation unterschiedliche Cloud-Rechnungskonten verwenden sollen, erstellen Sie für jedes Team unterschiedliche Projekte. Erstellen Sie die Cloud-Rechnungskonten auf Organisationsebene und verknüpfen Sie die Projekte mit ihnen.
- Slot-Reservierungen. Reservierte Slots sind auf die Organisationsressource beschränkt. Nachdem Sie reservierte Slotkapazität erworben haben, können Sie jedem Projekt oder Ordner innerhalb der Organisation einen Slot-Pool zuweisen oder der gesamten Organisationsressource Slots zuweisen. Projekte übernehmen Slotreservierungen vom übergeordneten Ordner oder von der übergeordneten Organisation. Reservierte Slots sind mit einem Administrationsprojekt verknüpft, das zum Verwalten der Slots verwendet wird. Weitere Informationen finden Sie unter Arbeitslastverwaltung mit Reservierungen.
Berechtigungen. Überlegen Sie, wie sich Ihre Berechtigungshierarchie auf die Personen in Ihrer Organisation auswirkt, die Zugriff auf die Daten brauchen. Wenn Sie beispielsweise einem gesamten Team Zugriff auf bestimmte Daten gewähren möchten, können Sie diese Daten in einem einzigen Projekt speichern, um die Zugriffsverwaltung zu vereinfachen.
Tabellen und andere Entitäten übernehmen die Berechtigungen des übergeordneten Datasets. Datasets übernehmen Berechtigungen von den übergeordneten Entitäten in der Ressourcenhierarchie (Projekte, Ordner, Organisationen). Zum Ausführen eines Vorgangs an einer Ressource benötigen Nutzer sowohl die relevanten Berechtigungen für die Ressource als auch die Berechtigung zum Erstellen eines BigQuery-Jobs. Die Berechtigung zum Erstellen eines Jobs ist mit dem Projekt verknüpft, das für diesen Job verwendet wird.
Muster
In diesem Abschnitt werden zwei gängige Muster zum Organisieren von BigQuery-Ressourcen vorgestellt.
Zentraler Data Lake, Abteilungs-Data-Marts Die Organisation erstellt ein einheitliches Speicherprojekt für seine Rohdaten. Die Abteilungen innerhalb der Organisation erstellen eigene Data-Mart-Projekte für die Analyse.
Abteilungs-Data Lakes, zentrale Data Warehouses. Jede Abteilung erstellt und verwaltet ein eigenes Speicherprojekt für die Rohdaten dieser Abteilung. Die Organisation erstellt dann ein zentrales Data Warehouse-Projekt zur Analyse.
Jede Methode hat Vor- und Nachteile. Viele Organisationen kombinieren Elemente aus beiden Mustern.
Zentraler Data Lake, Abteilungs-Data-Marts
In diesem Muster erstellen Sie ein einheitliches Speicherprojekt für die Rohdaten Ihrer Organisation. Ihre Datenaufnahme-Pipeline kann auch in diesem Projekt ausgeführt werden. Das Unified Storage-Projekt dient als Data Lake für Ihre Organisation.
Jede Abteilung verfügt über ein eigenes Projekt, mit dem sie die Daten abfragen, Abfrageergebnisse speichern und Ansichten erstellen können. Diese Projekte auf Abteilungsebene fungieren als Data-Marts. Sie sind mit dem Rechnungskonto der Abteilung verknüpft.
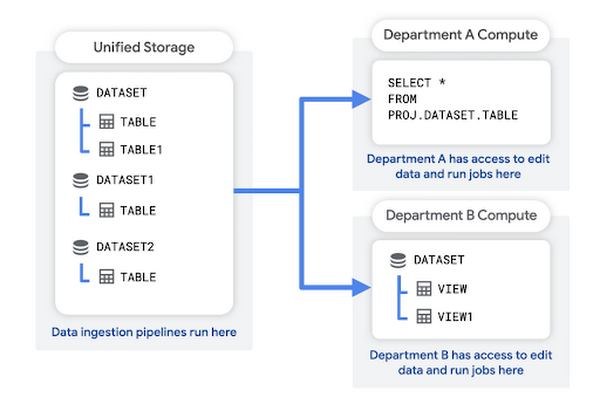
Vorteile dieser Struktur:
- Ein zentrales Data Engineering-Team kann die Datenaufnahme-Pipeline an einem Ort verwalten.
- Die Rohdaten werden von den Projekten auf Abteilungsebene isoliert.
- Bei der On-Demand-Abrechnung wird die Abrechnung für laufende Abfragen der Abteilung in Rechnung gestellt, die die Abfrage ausführt.
- Bei der kapazitätsbasierten Abrechnung können Sie jeder Abteilung je nach den prognostizierten Rechenanforderungen Slots zuweisen.
- Jede Abteilung ist in Bezug auf Kontingente auf Projektebene von den anderen getrennt.
Bei Verwendung dieser Struktur sind die folgenden Berechtigungen üblich:
- Das zentrale Data Engineering-Team erhält die Rollen „BigQuery-Datenbearbeiter“ und „BigQuery-Jobnutzer“ für das Speicherprojekt. Sie können damit Daten im Speicherprojekt aufnehmen und bearbeiten.
- Abteilungsanalysten wird die Rolle „BigQuery-Datenbetrachter“ für bestimmte Datasets im zentralen Data-Lake-Projekt gewährt. Sie können damit die Daten abfragen, die Rohdaten aber nicht aktualisieren oder löschen.
- Abteilungsanalysten wird auch die Rolle „BigQuery-Datenbearbeiter“ und die Rolle „Jobnutzer“ für das Data-Mart-Projekt ihrer Abteilung zugewiesen. Dadurch können sie Tabellen in ihrem Projekt erstellen und aktualisieren sowie Abfragejobs ausführen, um die Daten für die abteilungsspezifische Nutzung zu transformieren und zusammenzufassen.
Weitere Informationen finden Sie unter Einfache Rollen und Berechtigungen.
Abteilungs-Data Lakes, zentrales Data Warehouse
In diesem Muster erstellt und verwaltet jede Abteilung ihr eigenes Speicherprojekt, das die Rohdaten dieser Abteilung enthält. In einem zentralen Data Warehouse-Projekt werden Aggregationen oder Transformationen der Rohdaten gespeichert.
Die Analysten können die aggregierten Daten aus dem Data Warehouse-Projekt abfragen und lesen. Das Data Warehouse-Projekt bietet auch eine Zugriffsebene für Business Intelligence-Tools (BI).
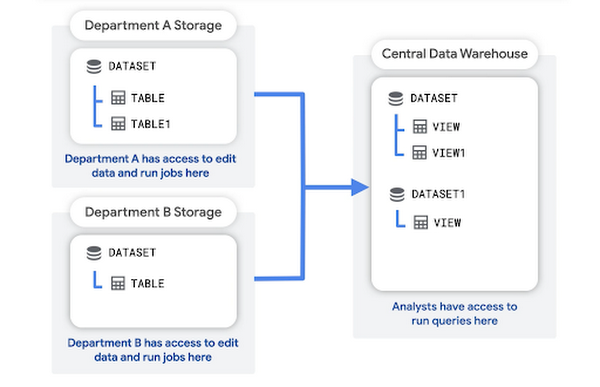
Vorteile dieser Struktur:
- Es ist einfacher, den Datenzugriff auf der Abteilungsebene zu verwalten, da separate Projekte für jede Abteilung verwendet werden.
- Ein zentrales Analyseteam hat ein einzelnes Projekt zum Ausführen von Analysejobs, was die Überwachung von Abfragen erleichtert.
- Nutzer können über ein zentralisiertes BI-Tool auf Daten zugreifen, die von den Rohdaten getrennt sind.
- Slots können dem Data Warehouse-Projekt zugewiesen werden, um alle Abfragen von Analysten und externen Tools zu verarbeiten.
Bei Verwendung dieser Struktur sind die folgenden Berechtigungen üblich:
- Data Engineers erhalten die Rollen „BigQuery-Datenbearbeiter“ und „BigQuery-Jobnutzer“ im Data-Mart ihrer Abteilung. Mit diesen Rollen können sie Daten in ihren Data-Mart aufnehmen und transformieren.
- Analysten erhalten die Rollen „BigQuery Datenbearbeiter“ und „BigQuery-Jobnutzer“ im Data Warehouse-Projekt. Mit diesen Rollen können sie aggregierte Ansichten im Data Warehouse erstellen und Abfragejobs ausführen.
- Dienstkonten, die BigQuery mit BI-Tools verbinden, wird die Rolle „BigQuery-Datenbetrachter“ für bestimmte Datasets zugewiesen, die entweder Rohdaten aus dem Data Lake oder transformierte Daten im Data Warehouse-Projekt enthalten können.
Weitere Informationen finden Sie unter Einfache Rollen und Berechtigungen.
Sie können auch Sicherheitsfunktionen wie autorisierte Ansichten und autorisierte benutzerdefinierte Funktionen (User-Defined Functions, UDFs) verwenden, um aggregierte Daten für bestimmte Nutzer verfügbar zu machen. ohne ihnen die Berechtigung zu erteilen, die Rohdaten in den Data-Mart-Projekten zu sehen.
Diese Projektstruktur kann zu vielen gleichzeitigen Abfragen im Data Warehouse-Projekt führen. Infolgedessen können Sie das Limit für gleichzeitige Abfragen erreichen. Wenn Sie diese Struktur übernehmen, sollten Sie dieses Kontingentlimit für das Projekt erhöhen. Ziehen Sie auch die kapazitätsbasierte Abrechnung in Betracht, sodass Sie einen Slot-Pool für die Ausführung der Abfragen erwerben können.