Organizar los recursos de BigQuery
Al igual que otros Google Cloud servicios, los recursos de BigQuery están organizados en una jerarquía. Puedes usar esta jerarquía para administrar aspectos de las cargas de trabajo de BigQuery, como permisos, cuotas, reservas de ranuras y facturación.
Jerarquía de recursos
BigQuery hereda la jerarquía de recursos deGoogle Cloud y agrega un mecanismo de agrupación adicional llamado conjuntos de datos, que son específicos de BigQuery. En esta sección, se describen los elementos de esta jerarquía.
Conjuntos de datos
Los conjuntos de datos son contenedores lógicos que se usan para organizar y controlar el acceso a tus recursos de BigQuery. Los conjuntos de datos son similares a los esquemas en otros sistemas de bases de datos.
La mayoría de los recursos de BigQuery que creas, incluidas las tablas, las vistas, las funciones y los procedimientos, se crean dentro de un conjunto de datos. Las conexiones y los trabajos son excepciones. Estos están asociados con proyectos en lugar de conjuntos de datos.
Un conjunto de datos tiene una ubicación. Cuando creas una tabla, los datos de la tabla se almacenan en la ubicación del conjunto de datos. Antes de crear tablas para los datos de producción, piensa en los requisitos de ubicación. No puedes cambiar la ubicación de un conjunto de datos después de crearlo.
Proyectos
Cada conjunto de datos está asociado a un proyecto. Para usar Google Cloud, debes crear al menos un proyecto. Los proyectos constituyen la base para la creación, la habilitación y el uso de todos los Google Cloud servicios. Para obtener más información, consulta Jerarquía de recursos. Un proyecto puede contener varios conjuntos de datos, pueden existir conjuntos de datos con diferentes ubicaciones en el mismo proyecto.
Cuando realizas operaciones en tus datos de BigQuery, como ejecutar una consulta o transferir datos a una tabla, creas un trabajo. Un trabajo siempre está asociado con un proyecto, pero no tiene que ejecutarse en el mismo proyecto que contiene los datos. De hecho, un trabajo puede hacer referencia a tablas de conjuntos de datos en varios proyectos. Los trabajos de consulta, de carga o de extracción siempre se ejecutan en la misma ubicación que las tablas a las que hacen referencia.
Cada proyecto tiene una cuenta de Facturación de Cloud adjunta. Los costos acumulados en un proyecto se facturan a esa cuenta. Si usas precios a pedido, tus consultas se facturan al proyecto que ejecuta la consulta. Si usas precios basados en la capacidad, las reservas de ranuras se facturan al proyecto de administración que se usó para comprar las ranuras. El almacenamiento se cobra al proyecto en el que reside el conjunto de datos.
Carpetas
Las carpetas son un mecanismo de agrupación adicional por sobre los proyectos. Los proyectos y las carpetas dentro de una carpeta heredan de forma automática las políticas de acceso de su carpeta superior. Las carpetas se pueden usar para diferenciar distintas entidades legales, departamentos y equipos dentro de una empresa.
Organizaciones
El recurso de organización representa una organización (por ejemplo, una empresa) y es el nodo raíz en la jerarquía de recursos deGoogle Cloud .
No necesitas un recurso de organización para comenzar a usar BigQuery, pero te recomendamos crear uno. El uso de un recurso de organización permite a los administradores controlar de forma centralizada los recursos de BigQuery en lugar de los usuarios individuales que controlan los recursos que crean.
En el siguiente diagrama, se muestra un ejemplo de la jerarquía de recursos. En este ejemplo, la organización tiene un proyecto dentro de una carpeta. El proyecto está asociado con una cuenta de facturación y contiene tres conjuntos de datos.
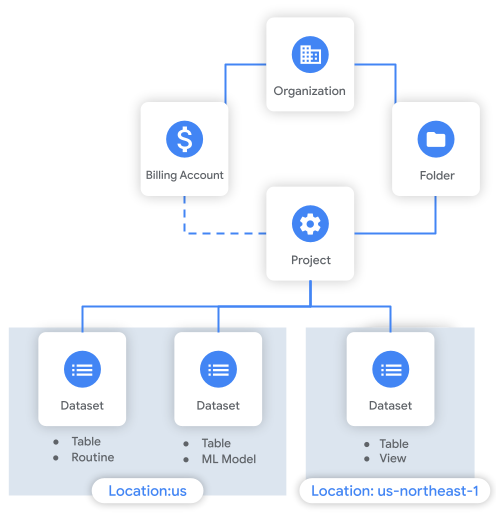
Consideraciones
Cuando elijas cómo organizar tus recursos de BigQuery, ten en cuenta los siguientes puntos:
- Cuotas. Muchas cuotas de BigQuery se aplican a nivel de proyecto. Algunas se aplican a nivel del conjunto de datos. Las cuotas a nivel de proyecto que involucran recursos de procesamiento, como consultas y trabajos de carga, se cuentan en el proyecto que crea el trabajo, en lugar del proyecto de almacenamiento.
- Facturación. Si deseas que diferentes departamentos de tu organización usen diferentes cuentas de Facturación de Cloud, crea proyectos diferentes para cada equipo. Crea las cuentas de Facturación de Cloud a nivel de organización y asocia los proyectos a ellas.
- Reservas de ranuras. Las ranuras reservadas se limitan al recurso de organización. Después de comprar capacidad de ranuras reservadas, puedes asignar un grupo de ranuras a cualquier proyecto o carpeta dentro de la organización o asignar ranuras a todo el recurso de organización. Los proyectos heredan las reservas de ranuras de su organización o carpeta superior. Las ranuras reservadas están asociadas con un proyecto de administración, que se usa para administrar las ranuras. Para obtener más información, consulta Administración de cargas de trabajo mediante reservas.
Permisos. Considera cómo tu jerarquía de permisos afecta a las personas de tu organización que necesitan acceder a los datos. Por ejemplo, si deseas otorgar a un equipo completo acceso a datos específicos, puedes almacenar esos datos en un solo proyecto para simplificar la administración de accesos.
Las tablas y otras entidades heredan los permisos de su conjunto de datos superior. Los conjuntos de datos heredan los permisos de sus entidades principales en la jerarquía de recursos (proyectos, carpetas, organizaciones). Para realizar una operación en un recurso, un usuario necesita tanto los permisos relevantes en el recurso como los permisos para crear un trabajo de BigQuery. El permiso de creación de un trabajo se asocia con el proyecto que se usa para ese trabajo.
Patrones
En esta sección, se presentan dos patrones comunes para organizar los recursos de BigQuery.
Data lakes centrales, data marts de departamento. La organización crea un proyecto de almacenamiento unificado para contener sus datos sin procesar. Los departamentos dentro de la organización crean sus propios proyectos de data mart para su análisis.
Data lakes de departamento, almacén de datos central. Cada departamento crea y administra su propio proyecto de almacenamiento para almacenar sus datos sin procesar. Luego, la organización crea un proyecto central de almacén de datos para su análisis.
Cada enfoque tiene sus pros y contras. Muchas organizaciones combinan elementos de ambos patrones.
Data lakes centrales, data marts de departamento
En este patrón, se crea un proyecto de almacenamiento unificado para almacenar los datos sin procesar de tu organización. Tu canalización de transferencia de datos también puede ejecutarse en este proyecto. El proyecto de almacenamiento unificado actúa como un data lake para tu organización.
Cada departamento tiene su propio proyecto dedicado, que usa para consultar los datos, guardar los resultados de las consultas y crear vistas. Estos proyectos a nivel de departamento actúan como data marts. Están asociados con la cuenta de facturación del departamento.
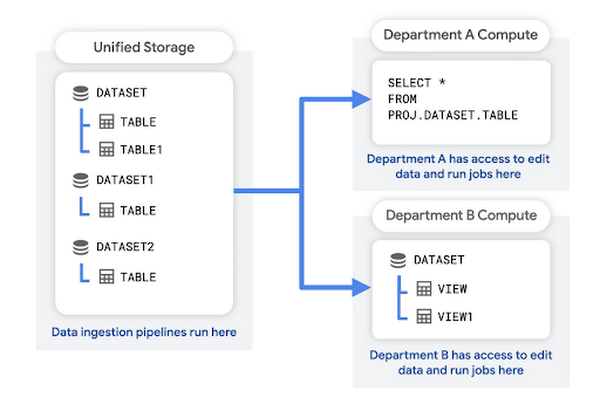
Las ventajas de esta estructura son las siguientes:
- Un equipo de ingeniería de datos centralizado puede administrar la canalización de transferencia en un solo lugar.
- Los datos sin procesar están aislados de los proyectos a nivel de departamento.
- Con los precios según demanda, la facturación por la ejecución de consultas se cobra al departamento que ejecuta la consulta.
- Con los precios basados en la capacidad, puedes asignar ranuras a cada departamento según los requisitos de procesamiento proyectados.
- Cada departamento está aislado de los demás en términos de cuotas a nivel de proyecto.
Cuando se usa esta estructura, los siguientes permisos son típicos:
- Al equipo central de ingeniería de datos se le otorgan los roles BigQuery Data Editor y BigQuery Job User para el proyecto de almacenamiento. Estos les permiten transferir y editar datos en el proyecto de almacenamiento.
- A los analistas de departamentos se les otorga el rol BigQuery Data Viewer para conjuntos de datos específicos en el proyecto del data lake central. Esto les permite consultar los datos, pero no actualizar ni borrar los datos sin procesar.
- A los analistas de departamentos también se les otorga el rol BigQuery Data Editor y Job User para el proyecto de data mart de su departamento. Esto les permite crear y actualizar tablas en su proyecto y ejecutar trabajos de consulta, a fin de transformar y agregar los datos para el uso específico de cada departamento.
Para obtener más información, consulta Funciones y permisos de IAM.
Data lakes de departamento, almacén de datos central
En este patrón, cada departamento crea y administra su propio proyecto de almacenamiento, que contiene los datos sin procesar de ese departamento. Un proyecto central de almacén de datos almacena agregaciones o transformaciones de los datos sin procesar.
Los analistas pueden consultar y leer los datos agregados del proyecto de almacén de datos. El proyecto del almacén de datos también proporciona una capa de acceso para las herramientas de inteligencia empresarial (IE).
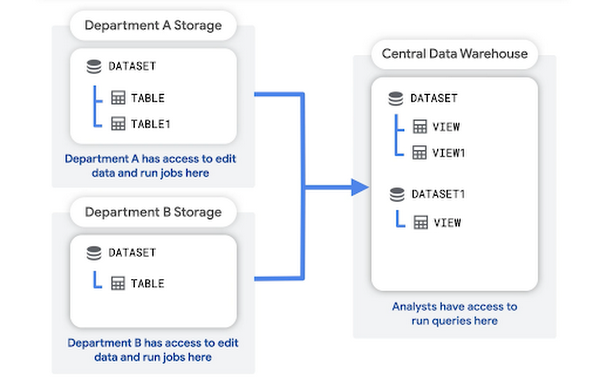
Las ventajas de esta estructura son las siguientes:
- Es más sencillo administrar el acceso a los datos a nivel de departamento mediante el uso de proyectos separados para cada departamento.
- Un equipo de análisis central tiene un solo proyecto para ejecutar trabajos de análisis, lo que facilita la supervisión de las consultas.
- Los usuarios pueden acceder a los datos desde una herramienta de IE centralizada, que se mantiene aislada de los datos sin procesar.
- Se pueden asignar ranuras al proyecto de almacén de datos para manejar todas las consultas de analistas y herramientas externas.
Cuando se usa esta estructura, los siguientes permisos son típicos:
- A los ingenieros de datos se les otorgan los roles BigQuery Data Editor y BigQuery Job User en el data mart de su departamento. Estas funciones les permiten transferir y transformar datos en su data mart.
- A los analistas se les otorgan los roles BigQuery Data Editor y BigQuery Job User en el proyecto de almacén de datos. Estas funciones les permiten crear vistas agregadas en el almacén de datos y ejecutar trabajos de consulta.
- Las cuentas de servicio que conectan BigQuery con las herramientas de IE tienen la función de visualizador de datos de BigQuery para conjuntos de datos específicos, que pueden contener datos sin procesar del data lake o datos transformados en el proyecto de almacén de datos.
Para obtener más información, consulta Funciones y permisos de IAM.
También puedes usar funciones de seguridad como vistas autorizadas y funciones definidas por el usuario autorizadas (UDF) a fin de que los datos agregados estén disponibles para ciertos usuarios, sin otorgarles permiso para ver los datos sin procesar en los proyectos de data mart.
Esta estructura de proyecto puede generar muchas consultas simultáneas en el proyecto de almacén de datos. Como resultado, puedes alcanzar el límite de consultas simultáneas. Si adoptas esta estructura, considera aumentar este límite de cuota para el proyecto. También considera usar la facturación basada en la capacidad, de modo que puedas comprar un grupo de ranuras para ejecutar las consultas.