Organizar recursos do BigQuery
Tal como outros Google Cloud serviços, os recursos do BigQuery estão organizados numa hierarquia. Pode usar esta hierarquia para gerir aspetos das suas cargas de trabalho do BigQuery, como autorizações, quotas, reservas de slots e faturação.
Hierarquia de recursos
O BigQuery herda a Google Cloud hierarquia de recursos e adiciona um mecanismo de agrupamento adicional denominado conjuntos de dados, que são específicos do BigQuery. Esta secção descreve os elementos desta hierarquia.
Conjuntos de dados
Os conjuntos de dados são contentores lógicos usados para organizar e controlar o acesso aos seus recursos do BigQuery. Os conjuntos de dados são semelhantes aos esquemas noutros sistemas de bases de dados.
A maioria dos recursos do BigQuery que cria, incluindo tabelas, vistas, funções e procedimentos, são criados num conjunto de dados. As associações e os trabalhos são exceções. Estes estão associados a projetos e não a conjuntos de dados.
Um conjunto de dados tem uma localização. Quando cria uma tabela, os dados da tabela são armazenados na localização do conjunto de dados. Antes de criar tabelas para dados de produção, pense nos seus requisitos de localização. Não pode alterar a localização de um conjunto de dados depois de o criar.
Projetos
Cada conjunto de dados está associado a um projeto. Para usar o Google Cloud, tem de criar, pelo menos, um projeto. Os projetos formam a base para criar, ativar e usar todos os Google Cloud serviços. Para mais informações, consulte o artigo Hierarquia de recursos. Um projeto pode conter vários conjuntos de dados e podem existir conjuntos de dados com localizações diferentes no mesmo projeto.
Quando realiza operações nos seus dados do BigQuery, como executar uma consulta ou ingerir dados numa tabela, cria uma tarefa. Uma tarefa está sempre associada a um projeto, mas não tem de ser executada no mesmo projeto que contém os dados. Na verdade, um trabalho pode fazer referência a tabelas de conjuntos de dados em vários projetos. Uma tarefa de consulta, uma tarefa de carregamento ou uma tarefa de exportação é sempre executada na mesma localização que as tabelas a que faz referência.
Cada projeto tem uma conta do Cloud Billing anexada. Os custos acumulados de um projeto são faturados a essa conta. Se usar os preços a pedido, as suas consultas são faturadas ao projeto que executa a consulta. Se usar os preços baseados na capacidade, as suas reservas de slots são faturadas ao projeto de administração usado para comprar os slots. O armazenamento é cobrado ao projeto onde o conjunto de dados reside.
Pastas
As pastas são um mecanismo de agrupamento adicional acima dos projetos. Os projetos e as pastas dentro de uma pasta herdam automaticamente as políticas de acesso da respetiva pasta principal. As pastas podem ser usadas para modelar diferentes entidades legais, departamentos e equipas numa empresa.
Organizações
O recurso Organization representa uma organização (por exemplo, uma empresa) e é o nó de raiz na Google Cloud hierarquia de recursos.
Não precisa de um recurso de organização para começar a usar o BigQuery, mas recomendamos que crie um. A utilização de um recurso de organização permite que os administradores controlem centralmente os seus recursos do BigQuery, em vez de os utilizadores individuais controlarem os recursos que criam.
O diagrama seguinte mostra um exemplo da hierarquia de recursos. Neste exemplo, a organização tem um projeto numa pasta. O projeto está associado a uma conta de faturação e contém três conjuntos de dados.
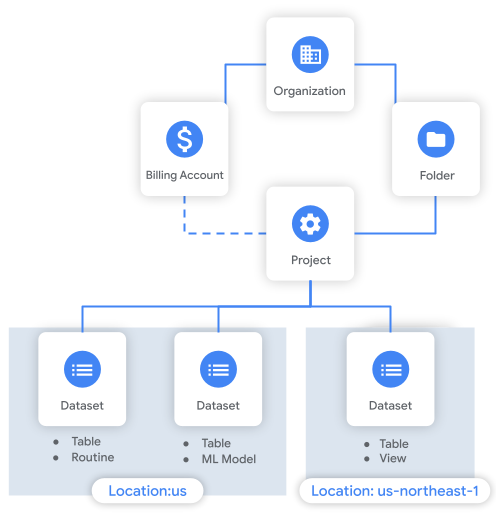
Considerações
Quando escolher como organizar os seus recursos do BigQuery, considere os seguintes pontos:
- Quotas. Muitas quotas do BigQuery são aplicadas ao nível do projeto. Algumas aplicam-se ao nível do conjunto de dados. As quotas ao nível do projeto que envolvem recursos de computação, como consultas e tarefas de carregamento, são contabilizadas em relação ao projeto que cria a tarefa, e não ao projeto de armazenamento.
- Faturação. Se quiser que diferentes departamentos na sua organização usem contas de faturação do Google Cloud diferentes, crie projetos diferentes para cada equipa. Crie as contas do Cloud Billing ao nível da organização e associe-lhes os projetos.
- Reservas de horários disponíveis. Os slots reservados estão no âmbito do recurso da organização. Depois de comprar capacidade de espaço reservado, pode: atribuir um conjunto de espaços a qualquer projeto ou pasta na organização, ou atribuir espaços ao recurso de organização inteiro. Os projetos herdam as reservas de slots da respetiva pasta ou organização principal. Os slots reservados estão associados a um projeto de administração, que é usado para gerir os slots. Para mais informações, consulte o artigo Gestão de cargas de trabalho com reservas.
Autorizações. Considere como a hierarquia de autorizações afeta as pessoas na sua organização que precisam de aceder aos dados. Por exemplo, se quiser conceder acesso a dados específicos a uma equipa inteira, pode armazenar esses dados num único projeto para simplificar a gestão de acessos.
As tabelas e outras entidades herdam as autorizações do respetivo conjunto de dados principal. Os conjuntos de dados herdam autorizações das respetivas entidades principais na hierarquia de recursos (projetos, pastas e organizações). Para realizar uma operação num recurso, um utilizador precisa das autorizações relevantes no recurso e também da autorização para criar uma tarefa do BigQuery. A autorização para criar uma tarefa está associada ao projeto usado para essa tarefa.
Padrões
Esta secção apresenta dois padrões comuns para organizar recursos do BigQuery.
Lago de dados central, data marts de departamentos. A organização cria um projeto de armazenamento unificado para armazenar os respetivos dados não processados. Os departamentos da organização criam os seus próprios projetos de data mart para análise.
Lagos de dados de departamentos, armazém de dados central. Cada departamento cria e gere o seu próprio projeto de armazenamento para guardar os dados não processados desse departamento. Em seguida, a organização cria um projeto de armazém de dados central para análise.
Cada abordagem tem vantagens e desvantagens. Muitas organizações combinam elementos de ambos os padrões.
Lago de dados central, repositórios de dados departamentais
Neste padrão, cria um projeto de armazenamento unificado para conter os dados não processados da sua organização. O pipeline de carregamento de dados também pode ser executado neste projeto. O projeto de armazenamento unificado funciona como um lago de dados para a sua organização.
Cada departamento tem o seu próprio projeto dedicado, que usa para consultar os dados, guardar os resultados das consultas e criar vistas. Estes projetos ao nível do departamento atuam como data marts. Estão associados à conta de faturação do departamento.
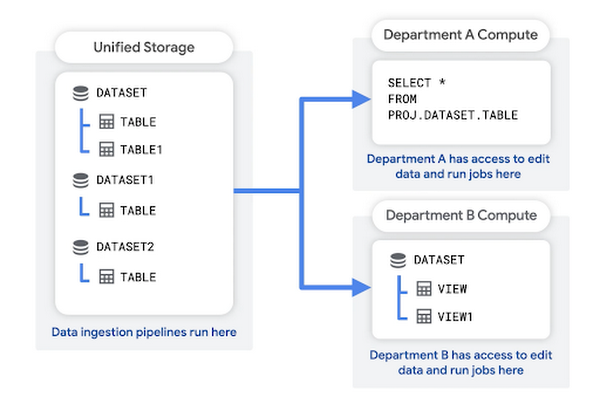
As vantagens desta estrutura incluem:
- Uma equipa de engenharia de dados centralizada pode gerir o pipeline de carregamento num único local.
- Os dados não processados estão isolados dos projetos ao nível do departamento.
- Com os preços a pedido, a faturação da execução de consultas é cobrada ao departamento que executa a consulta.
- Com os preços baseados na capacidade, pode atribuir slots a cada departamento com base nos respetivos requisitos de computação projetados.
- Cada departamento está isolado dos outros em termos de quotas ao nível do projeto.
Quando usa esta estrutura, as seguintes autorizações são típicas:
- A equipa central de engenharia de dados recebe as funções de editor de dados do BigQuery e utilizador da tarefa do BigQuery para o projeto de armazenamento. Estas permitem-lhes carregar e editar dados no projeto de armazenamento.
- Os analistas do departamento têm a função de visualizador de dados do BigQuery para conjuntos de dados específicos no projeto central do data lake. Isto permite-lhes consultar os dados, mas não atualizar nem eliminar os dados não processados.
- Os analistas do departamento também recebem a função de editor de dados do BigQuery e a função de utilizador de tarefas para o projeto de data mart do respetivo departamento. Isto permite-lhes criar e atualizar tabelas no respetivo projeto e executar tarefas de consulta, de modo a transformar e agregar os dados para utilização específica do departamento.
Para mais informações, consulte o artigo Funções e autorizações básicas.
Lagos de dados departamentais, armazém de dados central
Neste padrão, cada departamento cria e gere o seu próprio projeto de armazenamento, que contém os dados não processados desse departamento. Um projeto de data warehouse central armazena agregações ou transformações dos dados não processados.
Os analistas podem consultar e ler os dados agregados do projeto de armazém de dados. O projeto de armazém de dados também fornece uma camada de acesso para ferramentas de Business Intelligence (BI).
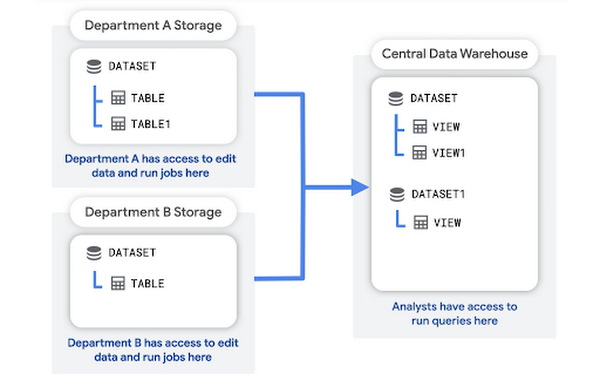
As vantagens desta estrutura incluem:
- É mais simples gerir o acesso aos dados ao nível do departamento, usando projetos separados para cada departamento.
- Uma equipa de estatísticas central tem um único projeto para executar tarefas de estatísticas, o que facilita a monitorização das consultas.
- Os utilizadores podem aceder a dados a partir de uma ferramenta de BI centralizada, que é mantida isolada dos dados não processados.
- Pode atribuir slots ao projeto do armazém de dados para processar todas as consultas de analistas e ferramentas externas.
Quando usa esta estrutura, as seguintes autorizações são típicas:
- Os engenheiros de dados têm as funções de editor de dados do BigQuery e utilizador de tarefas do BigQuery no data mart do respetivo departamento. Estas funções permitem-lhes carregar e transformar dados no respetivo data mart.
- Os analistas recebem as funções de editor de dados do BigQuery e utilizador de tarefas do BigQuery no projeto do armazém de dados. Estas funções permitem-lhes criar vistas agregadas no data warehouse e executar tarefas de consulta.
- As contas de serviço que ligam o BigQuery a ferramentas de BI recebem a função de visualizador de dados do BigQuery para conjuntos de dados específicos, que podem conter dados não processados do data lake ou dados transformados no projeto do armazém de dados.
Para mais informações, consulte o artigo Funções e autorizações básicas.
Também pode usar funcionalidades de segurança, como vistas autorizadas e funções definidas pelo utilizador autorizadas (UDFs) para disponibilizar dados agregados a determinados utilizadores sem lhes conceder autorização para ver os dados não processados nos projetos de data mart.
Esta estrutura do projeto pode resultar em muitas consultas simultâneas no projeto do data warehouse. Como tal, pode atingir o limite de consultas simultâneas. Se adotar esta estrutura, considere aumentar este limite de quota para o projeto. Considere também usar a faturação baseada na capacidade para poder comprar um conjunto de slots para executar as consultas.