Daten laden und abfragen
Erstellen Sie zuerst ein Dataset, laden Sie Daten in eine Tabelle und fragen Sie die Tabelle ab.
Eine detaillierte Anleitung dazu finden Sie direkt in der Google Cloud Console. Klicken Sie dazu einfach auf Anleitung:
Hinweise
Bevor Sie sich BigQuery genauer ansehen können, müssen Sie sich in derGoogle Cloud Console anmelden und ein Projekt erstellen. Wenn Sie die Abrechnung in Ihrem Projekt nicht aktivieren, befinden sich alle hochgeladenen Daten in der BigQuery-Sandbox. Mithilfe der Sandbox können Sie sich kostenlos mit BigQuery vertraut machen, während Sie mit einer begrenzten Anzahl von BigQuery-Features arbeiten. Weitere Informationen finden Sie unter BigQuery-Sandbox aktivieren.- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
- Optional: Wenn Sie ein vorhandenes Projekt auswählen, müssen Sie die BigQuery API aktivieren. Die BigQuery-API wird in neuen Projekten automatisch aktiviert.
- Öffnen Sie in der Google Cloud Console die Seite „BigQuery“. BigQuery aufrufen
- Klicken Sie im linken Bereich auf Explorer.
- Klicken Sie im Bereich
Explorer auf den Namen Ihres Projekts. - Klicken Sie auf Aktionen ansehen.
- Wählen Sie Dataset erstellen aus.
- Führen Sie auf der Seite Dataset erstellen die folgenden Schritte aus:
- Geben Sie unter Dataset-ID
babynamesein. - Wählen Sie als Standorttyp die Option Mehrere Regionen und dann USA (mehrere Regionen in den USA) aus. Die öffentlichen Datasets sind am multiregionalen Standort
usgespeichert. Der Einfachheit halber sollten Sie Ihr Dataset am selben Speicherort speichern. - Übernehmen Sie die verbleibenden Standardeinstellungen unverändert und klicken Sie auf
Dataset erstellen . Laden Sie die Daten der US-amerikanischen Sozialversicherungsbehörde herunter. Öffnen Sie dazu die folgende URL in einem neuen Browsertab:
https://www.ssa.gov/OACT/babynames/names.zipExtrahieren Sie die Datei.
Weitere Informationen zum Dataset-Schema finden Sie in der Datei
NationalReadMe.pdfin der ZIP-Datei.Um sich die Daten anzusehen, öffnen Sie die Datei
yob2024.txt. Diese Datei enthält kommagetrennte Werte für den Namen, das bei der Geburt zugewiesene Geschlecht und die Anzahl der Kinder mit diesem Namen. Die Datei hat keine Kopfzeile.Notieren Sie sich den Speicherort der Datei
yob2024.txt, damit Sie sie später wiederfinden.- Klicken Sie im linken Bereich auf Explorer.
- Maximieren Sie im Bereich
Explorer den Namen Ihres Projekts. - Klicken Sie auf Datasets und dann neben dem Dataset babynames auf Aktionen ansehen und wählen Sie Öffnen aus.
- Klicken Sie auf Tabelle erstellen.
Sofern nicht anders angegeben, verwenden Sie für alle Einstellungen die Standardwerte.
- Führen Sie auf der Seite Tabelle erstellen die folgenden Schritte aus:
- Wählen Sie im Abschnitt Quelle unter
Tabelle erstellen aus die Option Hochladen aus der Liste aus. - Klicken Sie im Feld Datei auswählen auf Durchsuchen.
- Öffnen Sie Ihre lokale Datei
yob2024.txtund klicken Sie auf Öffnen. - Wählen Sie in der Liste
Dateiformat die Option CSV aus. - Geben Sie im Abschnitt Ziel im Feld
Tabelle den Wertnames_2024ein. - Klicken Sie im Abschnitt Schema auf die Ein/Aus-Schaltfläche
Als Text bearbeiten und fügen Sie die folgende Schemadefinition in das Textfeld ein: - Klicken Sie auf
Tabelle erstellen .Warten Sie, bis BigQuery die Tabelle erstellt und die Daten geladen hat.
- Klicken Sie im linken Bereich auf Explorer.
- Maximieren Sie im Bereich
Explorer Ihr Projekt und klicken Sie auf Datasets (Datasets). - Klicken Sie auf das Dataset
babynamesund wählen Sie dann die Tabellenames_2024aus. - Klicken Sie auf den Tab
Vorschau . BigQuery zeigt die ersten Zeilen der Tabelle an. - Klicken Sie neben dem Tab names_2024 auf die Option SQL-Abfrage. Ein neuer Editor-Tab wird geöffnet.
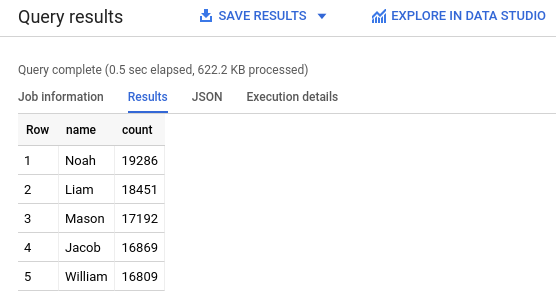
- Fügen Sie die folgende Abfrage in den Abfrageeditor ein. Mit dieser Abfrage werden die fünf beliebtesten Namen für Babys abgerufen, die 2024 in den USA geboren wurden und denen bei der Geburt das männliche Geschlecht zugewiesen wurde.
SELECT name, count FROM `babynames.names_2024` WHERE assigned_sex_at_birth = 'M' ORDER BY count DESC LIMIT 5; - Klicken Sie auf
Ausführen . Die Ergebnisse werden im Abschnitt Abfrageergebnisse angezeigt.
- Öffnen Sie in der Google Cloud Console die Seite „BigQuery“. BigQuery aufrufen
- Klicken Sie im linken Bereich auf Explorer.
- Klicken Sie im Bereich Explorer auf Datasets und dann auf das von Ihnen erstellte Dataset
babynames. - Maximieren Sie die Option Aktionen ansehen und klicken Sie auf Löschen.
- Bestätigen Sie im Dialogfeld Dataset löschen den Löschbefehl: Geben Sie dafür das Wort
deleteein und klicken Sie auf Löschen. - Daten in BigQuery laden
- Weitere Informationen zum Abfragen von Daten finden Sie unter BigQuery-Analysen – Übersicht.
- Weitere Informationen zum Laden einer JSON-Datei mit verschachtelten und wiederholten Daten finden Sie in Verschachtelte und wiederholte JSON-Daten laden.
- Weitere Informationen zum programmgesteuerten Zugriff auf BigQuery finden Sie in der Referenz zur REST API oder auf der Seite BigQuery-Clientbibliotheken.
BigQuery-Dataset erstellen
Erstellen Sie mit der Google Cloud Console ein Dataset zum Speichern der Daten. Sie erstellen Ihr Dataset am multiregionalen Standort "US". Informationen zu BigQuery-Regionen und ‑Multiregionen finden Sie unter Standorte.
Datei mit den Quelldaten herunterladen
Die heruntergeladene Datei enthält ca. 7 MB an Daten zu beliebten Babynamen. Sie wird von der US-amerikanischen Sozialversicherungsbehörde bereitgestellt.Weitere Informationen zu den Daten finden Sie auf der Seite Hintergrundinformation für populäre Namen der US-amerikanischen Sozialversicherungsbehörde.
Daten in eine Tabelle laden
Als Nächstes laden Sie die Daten in eine neue Tabelle.
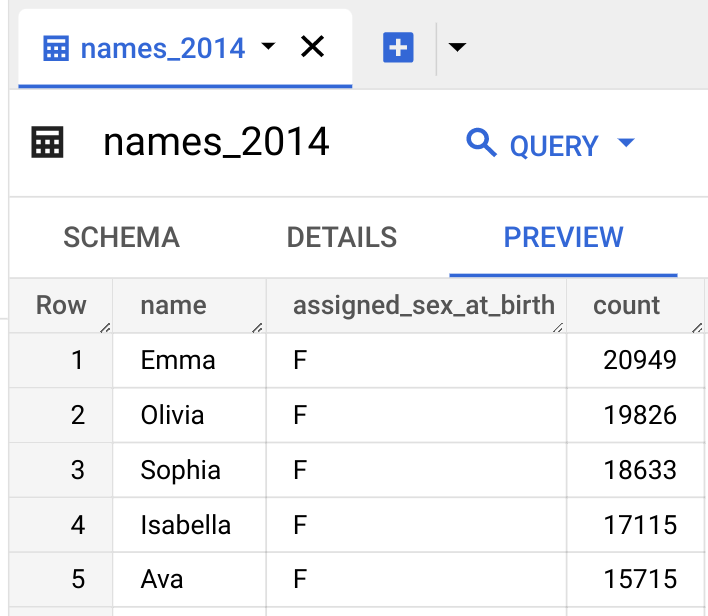
name:string,assigned_sex_at_birth:string,count:integerVorschau von Tabellendaten
So rufen Sie die Tabellendaten in der Vorschau auf:
Tabellendaten abfragen
Fragen Sie als Nächstes die Tabelle ab.
Sie haben erfolgreich eine Tabelle in einem öffentlichen Dataset abgefragt und dann Ihre Beispieldaten mit der Google Cloud Console in BigQuery geladen.
Bereinigen
Mit den folgenden Schritten vermeiden Sie, dass Ihrem Google Cloud -Konto die auf dieser Seite verwendeten Ressourcen in Rechnung gestellt werden: