Carregar e consultar dados
Comece a usar o BigQuery criando um conjunto de dados, carregando dados em uma tabela e consultando a tabela.
Para seguir as instruções detalhadas desta tarefa diretamente no console do Google Cloud , clique em Orientação:
Antes de começar
Antes de explorar o BigQuery, faça login no consoleGoogle Cloud e crie um projeto. Se você não ativar o faturamento no projeto, todos os dados de upload estarão no sandbox do BigQuery. O sandbox permite que você aprenda o BigQuery sem custos financeiros e trabalhe com um conjunto limitado de recursos do BigQuery. Para mais informações, consulte Ativar o sandbox do BigQuery.- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
- Opcional: se você selecionar um projeto já existente, ative a API BigQuery. A API BigQuery é ativada automaticamente em novos projetos.
- No console do Google Cloud , abra a página do BigQuery. Acessar o BigQuery
- No painel à esquerda, clique em Explorer.
- No painel
Explorador, , clique no nome do seu projeto. - Clique em Ver ações.
- Selecione Criar conjunto de dados.
- Na página Criar conjunto de dados, faça o seguinte:
- Para o código do conjunto de dados, insira
babynames. - Em Tipo de local, selecione Multirregião e escolha
EUA (várias regiões nos Estados Unidos). Os conjuntos de dados públicos são armazenados no local multirregional
us. Para simplificar, armazene seus conjuntos de dados no mesmo local. - Mantenha as configurações padrão restantes e clique em
Criar conjunto de dados . Faça o download dos dados da Administração de Previdência Social dos EUA abrindo o URL a seguir em uma nova guia do navegador:
https://www.ssa.gov/OACT/babynames/names.zipExtraia o arquivo.
Para mais informações sobre o esquema do conjunto de dados, consulte o arquivo zip
NationalReadMe.pdf.Para conferir os dados, abra o arquivo
yob2024.txt. Esse arquivo contém valores separados por vírgula para nome, sexo atribuído no nascimento e número de crianças com esse nome. O arquivo não tem linha de cabeçalho.Observe o local do arquivo
yob2024.txtpara encontrá-lo mais tarde.- No painel à esquerda, clique em Explorer.
- No painel
Explorer selecione o nome do seu projeto. - Clique em Conjuntos de dados e, ao lado do conjunto babynames, clique em Ver ações e selecione Abrir.
- Clique em
Criar
tabela.
A menos que indicado de outra forma, use os valores padrão para todas as configurações.
- Na página Criar tabela, faça o seguinte:
- Na seção Origem, em
Criar tabela de , escolha Fazer upload na lista. - No campo Selecionar arquivo, clique em Procurar.
- Navegue até o arquivo
yob2024.txtlocal e clique em Abrir. - Na lista
Formato do arquivo , selecione CSV. - Na seção Destino, no campo
Tabela , insiranames_2024. - Na seção Esquema, clique no botão ativar/desativar
Editar como texto e cole a seguinte definição de esquema no campo de texto: - Clique em
Criar tabela .Aguarde o BigQuery criar a tabela e carregar os dados.
- No painel à esquerda, clique em Explorer.
- No painel
Explorer , expanda o projeto e clique em Conjuntos de dados. - Clique no conjunto de dados
babynamese selecione a tabelanames_2024. - Clique na guia
Visualização . O BigQuery mostra as primeiras linhas da tabela. - Ao lado da guia names_2024, clique na opção Consulta SQL. Uma nova guia do editor será aberta.
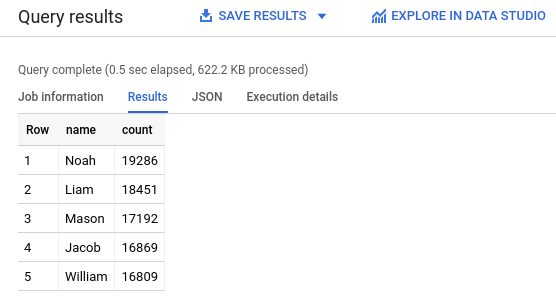
- No editor de consultas, cole o conteúdo abaixo. Essa consulta retorna os
cinco nomes masculinos mais comuns de bebês nascidos nos EUA em
2024.
SELECT name, count FROM `babynames.names_2024` WHERE assigned_sex_at_birth = 'M' ORDER BY count DESC LIMIT 5; - Clique em
Executar . Os resultados são exibidos na seção Resultados da consulta.
- No console do Google Cloud , abra a página do BigQuery. Acessar o BigQuery
- No painel à esquerda, clique em Explorer.
- No painel Explorer, clique em Conjuntos de dados e depois no conjunto
babynamesque você criou. - Expanda a opção Ver ações e clique em Excluir.
- Na caixa de diálogo Excluir conjunto de dados, confirme o comando de exclusão: digite a palavra
deletee clique em Excluir. - Saiba mais sobre como carregar dados no BigQuery em Introdução ao carregamento de dados.
- Para saber mais sobre como consultar dados, consulte Visão geral da análise do BigQuery.
- Para saber como carregar um arquivo JSON com dados aninhados e repetidos, consulte Como carregar dados JSON aninhados e repetidos.
- Saiba mais sobre como acessar o BigQuery de maneira programática na referência da API REST ou na página Bibliotecas de cliente do BigQuery.
Criar um conjunto de dados do BigQuery
Use o console do Google Cloud para criar um conjunto de dados que armazene os dados. Você cria o conjunto de dados no local multirregional dos EUA. Para informações sobre regiões e multirregiões do BigQuery, consulte Locais.
Fazer o download do arquivo que contém os dados de origem
Você está fazendo o download de um arquivo que tem aproximadamente 7 MB de dados com os nomes mais comuns de bebês. Ele é fornecido pela Administração da Previdência Social dos EUA.Para mais informações sobre os dados, consulte as Informações básicas sobre nomes populares da Administração da Previdência Social.
Carrega dados em uma tabela
Em seguida, carregue os dados em uma nova tabela.
name:string,assigned_sex_at_birth:string,count:integerVisualizar dados da tabela
Para visualizar os dados da tabela, siga estas etapas:
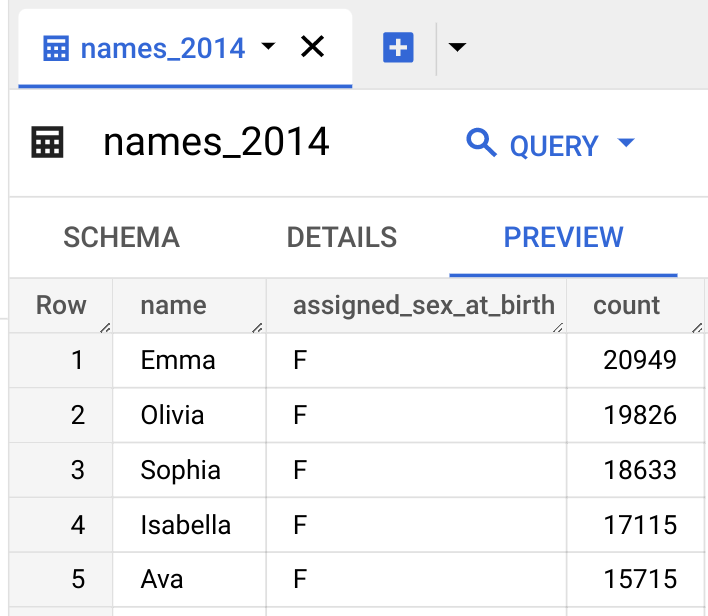
Consultar os dados da tabela
Em seguida, consulte a tabela.
Você consultou uma tabela em um conjunto de dados público e depois carregou os dados de amostra no BigQuery usando o console do Google Cloud .
Limpar
Para evitar cobranças na conta do Google Cloud pelos recursos usados nesta página, siga as etapas abaixo.