使用查询队列
BigQuery 会自动确定可并发运行的查询数量,称为动态并发。如有更多查询,这些查询会排入队列,直到处理资源可用。本文档介绍如何控制最大并发数目标,以及如何为交互式查询和批量查询设置队列超时。
概览
BigQuery 会根据可用的计算资源动态确定可以并发运行的查询数量。可以并发运行的查询数量按每个按需项目或每个预留计算得出。其他查询会放入队列中,直到有足够的容量可用于开始执行查询。无论项目是按需使用还是使用预留,队列长度都限制为每个区域每个项目 1,000 个交互式查询和 20,000 个批量查询。以下示例显示了当计算的查询并发数量为 202 时按需项目的行为:
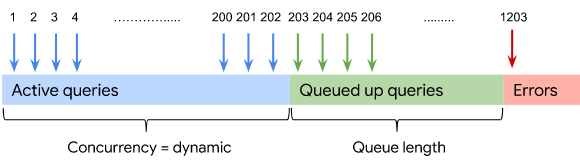
对于预留,您可以选择设置最大并发数目标(即预留中可以并发运行的查询数量上限),以确保为每个查询分配最小数量的槽。您无法为按需项目指定最大并发数目标;始终动态计算。
排队行为
BigQuery 会强制执行公平调度,以确保任何单个项目都不会使用预留中的所有槽。
并发数量份额最小的项目的查询会被首先移出队列。在执行期间,槽首先在项目之间均匀分发,然后在项目中的所有作业之间继续分发。
例如,假设您有一个预留分配给两个项目:A 和 B。BigQuery 为预留计算出的并发数量为 5。 项目 A 有四个正在并发运行的查询,项目 B 有一个正在运行的查询,其他查询会排入队列。来自项目 B 的查询将首先移出队列,即使该查询是在项目 A 的查询之后提交的也是如此。查询开始执行后,它会在共享预留中收到相等份额的槽。
除了并发查询总数之外,BigQuery 还会动态确定每个按需项目或预留可运行的并发批量查询数上限。如果并发运行的批量查询数量达到此上限,即使交互式查询提交得比较晚,也会得到优先处理。
当您删除预留时,所有排队的查询都会超时。当分配给某个预留的项目被重新分配给其他预留时,所有正在排队或运行的请求都会在旧预留中继续当前状态,而所有新请求都会转到新预留。从预留中移除分配给该预留的项目时,正在运行的查询会继续在该预留中运行,而新请求和排队的请求则使用按需模型执行。您可以选择取消个别正在运行或排队的查询作业。
控制队列超时
如需控制交互式查询或批量查询的队列超时,请使用 ALTER PROJECT SET OPTIONS 语句或 ALTER ORGANIZATION SET OPTIONS 语句设置项目或组织的默认配置中的 default_interactive_query_queue_timeout_ms 或 default_batch_query_queue_timeout_ms 字段。
如需查看项目中交互式查询或批量查询的队列超时,请查询 INFORMATION_SCHEMA.EFFECTIVE_PROJECT_OPTIONS 视图。
如需关闭队列,请将队列超时设置为 -1。如果达到查询并发数上限,则其他查询将失败并显示 ADMISSION_DENIED 错误。
设置最大并发数目标值
您可以在创建预留时手动设置最大并发数目标值。默认情况下,最大并发数目标为零,这意味着 BigQuery 会根据可用资源动态确定并发。否则,如果您设置了非零目标,则最大并发数目标会指定一个预留中并发运行的查询数量的上限,从而保证每个查询可运行的槽容量下限。
提高最大并发数目标不能保证同时执行更多查询。实际并发数取决于可用的计算资源,您可以通过向预留添加更多槽来增加可用的资源。
所需的角色
如需获得在新预留中设置并发数所需的权限,请让您的管理员为您授予维持承诺所有权的管理项目的 BigQuery Resource Editor (roles/bigquery.resourceEditor) IAM 角色。如需详细了解如何授予角色,请参阅管理对项目、文件夹和组织的访问权限。
此预定义角色包含在新预留中设置并发数所需的 bigquery.reservations.create 权限。
如需详细了解 BigQuery 中的 IAM 角色,请参阅预定义的角色和权限。
为预留设置最大并发数目标
从下列选项中选择一项:
控制台
在 Google Cloud 控制台中,前往 BigQuery 页面。
在导航菜单中,点击容量管理。
点击创建预留。
选择您的预留设置。
如需展开高级设置部分,请点击 展开箭头。
如需设置目标作业并发,请点击开启替换自动目标作业并发切换开关,然后输入目标作业并发。
点击保存。
SQL
如需为新预留设置最大并发数目标,请使用 CREATE RESERVATION DDL 语句并设置 target_job_concurrency 字段。
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,输入以下语句:
CREATE RESERVATION `ADMIN_PROJECT_ID.LOCATION.RESERVATION_NAME` OPTIONS ( target_job_concurrency = CONCURRENCY);
请替换以下内容:
-
ADMIN_PROJECT_ID:拥有预留的项目 -
LOCATION:预留的位置,例如region-us -
RESERVATION_NAME:预留的名称 -
CONCURRENCY:最大并发数目标
-
点击 运行。
如需详细了解如何运行查询,请参阅运行交互式查询。
bq
如需为新预留设置最大并发数目标值,请运行 bq mk 命令:
bq mk \
--project_id=ADMIN_PROJECT_ID \
--location=LOCATION \
--target_job_concurrency=CONCURRENCY \
--reservation \
RESERVATION_NAME
请替换以下内容:
ADMIN_PROJECT_ID:拥有预留的项目LOCATION:预留的位置CONCURRENCY:最大并发数目标RESERVATION_NAME:预留的名称
API
如需在 BigQuery Reservation API 中设置最大并发数目标,请在预留资源中设置 concurrency 字段并调用 CreateReservationRequest 方法。
更新最大并发数目标值
您可以随时更新预留的并发数目标。 但是,提高目标值并不能保证可同时执行更多查询。实际并发数取决于可用的计算资源。 如果降低最大并发数目标,则当前正在运行的查询不会受到影响,并且排队的查询不会运行,直到并发查询的数量少于新目标值为止。
如果将最大并发数目标设置为 0,BigQuery 会根据可用资源动态确定并发(默认行为)。
所需的角色
如需获得更新预留的最大并发数目标所需的权限,请让您的管理员为您授予维持承诺所有权的管理项目的 BigQuery Resource Editor (roles/bigquery.resourceEditor) IAM 角色。如需详细了解如何授予角色,请参阅管理对项目、文件夹和组织的访问权限。
此预定义角色包含更新预留的最大并发数目标所需的 bigquery.reservations.update 权限。
如需详细了解 BigQuery 中的 IAM 角色,请参阅预定义的角色和权限。
更新预留的最大并发数目标
从下列选项中选择一项:
控制台
在 Google Cloud 控制台中,前往 BigQuery 页面。
在导航菜单中,点击容量管理。
点击槽预留标签页。
找到要更新的预留。
展开 操作选项。
点击修改。
如需展开高级设置部分,请点击 展开箭头。
如需设置目标作业并发,请点击开启替换自动目标作业并发切换开关,然后输入目标作业并发。
点击保存。
SQL
如需更新现有预留的最大并发数目标,请使用 ALTER RESERVATION DDL 语句,并设置 target_job_concurrency 字段。
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,输入以下语句:
ALTER RESERVATION `ADMIN_PROJECT_ID.LOCATION.RESERVATION_NAME` SET OPTIONS ( target_job_concurrency = CONCURRENCY);
请替换以下内容:
-
ADMIN_PROJECT_ID:拥有预留的项目 -
LOCATION:预留的位置,例如region-us -
RESERVATION_NAME:预留的名称 -
CONCURRENCY:最大并发数目标
-
点击 运行。
如需详细了解如何运行查询,请参阅运行交互式查询。
bq
如需更新现有预留的最大并发数目标,请运行 bq update 命令:
bq update \
--project_id=ADMIN_PROJECT_ID \
--location=LOCATION \
--target_job_concurrency=CONCURRENCY \
--reservation \
RESERVATION_NAME
请替换以下内容:
ADMIN_PROJECT_ID:拥有预留的项目LOCATION:预留的位置CONCURRENCY:最大并发数目标RESERVATION_NAME:预留的名称
API
如需更新 BigQuery Reservations API 中的最大并发数目标,请在预留资源中设置 concurrency 字段并调用 UpdateReservationRequest 方法。
监控
如需了解哪些查询正在运行以及哪些查询已加入队列,请查看 INFORMATION_SCHEMA.JOBS_BY_* 和 INFORMATION_SCHEMA.JOBS_TIMELINE_BY_* 视图。对于正在运行的查询,将 state 字段设置为 RUNNING;对于已加入队列的查询,设置为 PENDING。
如需查看过去一天达到动态并发阈值时每秒运行的并发查询数,请运行以下查询:
SELECT t1.period_start, t1.job_count AS dynamic_concurrency_threshold FROM ( SELECT period_start, state, COUNT(DISTINCT job_id) AS job_count FROM `PROJECT_ID.REGION_ID`.INFORMATION_SCHEMA.JOBS_TIMELINE WHERE period_start BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 DAY) AND CURRENT_TIMESTAMP() AND reservation_id = "RESERVATION_ID" GROUP BY period_start, state) AS t1 JOIN ( SELECT period_start, state, COUNT(DISTINCT job_id) AS job_count FROM `PROJECT_ID.REGION_ID`.INFORMATION_SCHEMA.JOBS_TIMELINE WHERE state = "PENDING" AND period_start BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 DAY) AND CURRENT_TIMESTAMP() AND reservation_id = "RESERVATION_ID" GROUP BY period_start, state HAVING COUNT(DISTINCT job_id) > 0 ) AS t2 ON t1.period_start = t2.period_start WHERE t1.state = "RUNNING";
替换以下内容:
PROJECT_ID:运行查询的项目的名称REGION_ID:处理查询的位置RESERVATION_ID:运行查询的预留的名称
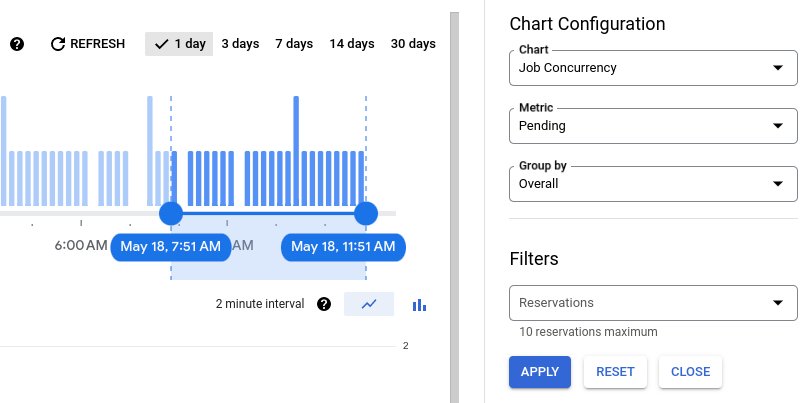
如需监控预留的查询队列长度,您可以使用 BigQuery 管理资源图表并选择作业并发图表和待处理指标。
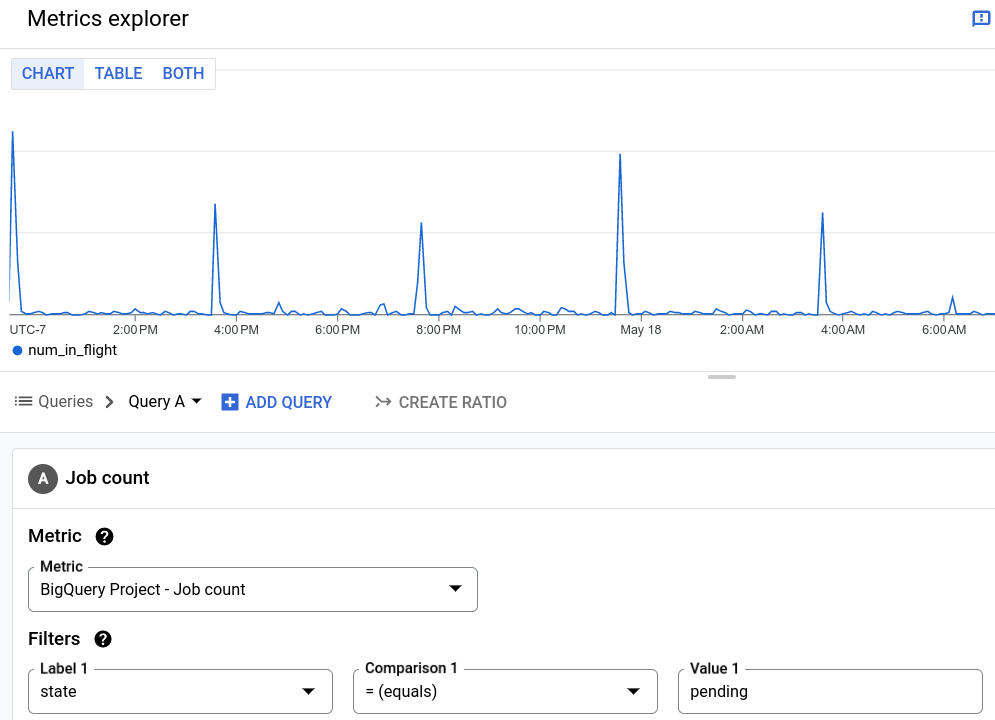
您还可以在 Cloud Monitoring 中监控队列长度,方法是查看作业计数指标并按待处理状态的作业数量过滤。
限制
- 每个按需项目一次最多可以将 1,000 个交互式查询和 20,000 个批量查询排入队列。超出此限制的查询会返回配额错误。 您不能申请提高这些限制。
- 在预留中,分配给该预留的每个项目一次最多可以将 1,000 个交互式查询和 20,000 个批量查询排入队列。超出此限制的查询会返回配额错误。 您不能申请提高这些限制。
- 默认情况下,尚未开始执行的查询作业在交互式查询后 6 小时后超时,在批量查询时超时 24 小时。
- 您无法为在按需项目中运行的查询设置最大并发数目标。
- 您无法为使用标准版预留运行的查询设置最大并发数目标。如需详细了解版本,请参阅 BigQuery 版本简介。
后续步骤
- 详细了解如何诊断和解决查询队列限制错误。