Incorporado nas tarefas de consulta, o BigQuery inclui informações de tempo e do plano de consulta de diagnóstico. Isto é semelhante às informações fornecidas por declarações como EXPLAIN noutros sistemas de bases de dados e analíticos. Estas informações podem ser obtidas das respostas da API de métodos como jobs.get.
Para consultas de execução prolongada, o BigQuery atualiza periodicamente estas estatísticas. Estas atualizações ocorrem independentemente da frequência com que o estado da tarefa é consultado, mas, normalmente, não ocorrem com uma frequência superior a cada 30 segundos. Além disso, as tarefas de consulta que não usam recursos de execução, como pedidos de teste ou resultados que podem ser publicados a partir de resultados em cache, não incluem as informações de diagnóstico adicionais, embora possam estar presentes outras estatísticas.
Contexto
Quando o BigQuery executa uma tarefa de consulta, converte a declaração SQL num gráfico de execução, dividido numa série de fases de consulta, que, por sua vez, são compostas por conjuntos mais detalhados de passos de execução. O BigQuery tira partido de uma arquitetura paralela altamente distribuída para executar estas consultas. As fases modelam as unidades de trabalho que muitos potenciais trabalhadores podem executar em paralelo. As fases comunicam entre si através de uma arquitetura de aleatorização distribuída rápida.
No plano de consulta, os termos unidades de trabalho e trabalhadores são usados para transmitir
informações especificamente sobre o paralelismo. Noutro local no BigQuery, pode encontrar o termo slot, que é uma representação abstrata de várias facetas da execução de consultas, incluindo recursos de computação, memória e E/S. As estatísticas de tarefas de nível superior fornecem a estimativa do custo da consulta individual através da estimativa da consulta com esta contabilidade abstrata.totalSlotMs
Outra propriedade importante da arquitetura de execução de consultas é que é dinâmica, o que significa que o plano de consulta pode ser modificado enquanto uma consulta está em execução. As fases introduzidas durante a execução de uma consulta são frequentemente usadas para melhorar a distribuição de dados entre os trabalhadores de consultas. Nos planos de consulta em que isto ocorre, estas fases são normalmente etiquetadas como Fases de repartição.
Além do plano de consulta, as tarefas de consulta também expõem uma cronologia de execução, que fornece uma contabilidade das unidades de trabalho concluídas, pendentes e ativas nos trabalhadores de consulta. Uma consulta pode ter várias fases com trabalhadores ativos em simultâneo, e a cronologia destina-se a mostrar o progresso geral da consulta.
Ver informações com a Google Cloud consola
Na Google Cloud consola, pode ver detalhes do plano de consulta de uma consulta concluída clicando no botão Detalhes da execução (junto ao botão Resultados).
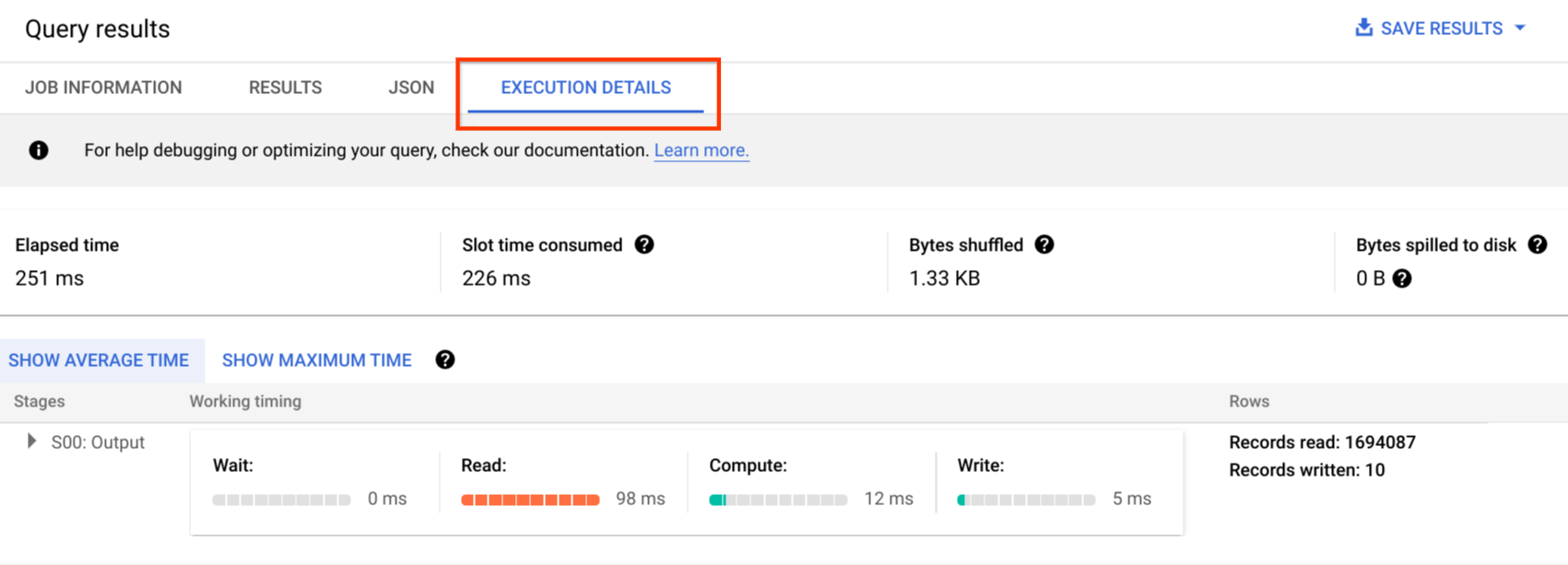
Informações do plano de consulta
Na resposta da API, os planos de consulta são representados como uma lista de fases de consulta. Cada item na lista mostra estatísticas de vista geral por etapa, informações detalhadas dos passos e classificações de tempo das etapas. Nem todos os detalhes são renderizados na consola Google Cloud , mas podem estar presentes nas respostas da API.
Vista geral da fase
Os campos de vista geral de cada fase podem incluir o seguinte:
| Campo da API | Descrição |
|---|---|
id |
ID numérico exclusivo da fase. |
name |
Nome do resumo simples da fase. O ícone steps na fase fornece detalhes adicionais sobre os passos de execução. |
status |
Estado de execução da fase. Os estados possíveis incluem PENDING, RUNNING, COMPLETE, FAILED e CANCELLED. |
inputStages |
Uma lista dos IDs que formam o gráfico de dependência da fase. Por exemplo, uma fase JOIN precisa frequentemente de duas fases dependentes que preparam os dados no lado esquerdo e direito da relação JOIN. |
startMs |
Data/hora, em milissegundos de época, que representa quando o primeiro trabalhador na fase começou a execução. |
endMs |
Data/hora, em milissegundos de época, que representa quando o último trabalhador concluiu a execução. |
steps |
Lista mais detalhada dos passos de execução na fase. Consulte a secção seguinte para mais informações. |
recordsRead |
Tamanho da entrada da fase como número de registos, em todos os trabalhadores da fase. |
recordsWritten |
Tamanho da saída da fase como número de registos, em todos os trabalhadores da fase. |
parallelInputs |
Número de unidades de trabalho paralelizadas para a fase. Consoante a fase e a consulta, isto pode representar o número de segmentos colunares numa tabela ou o número de partições numa ordenação aleatória intermédia. |
completedParallelInputs |
Número de unidades de trabalho na fase que foram concluídas. Para algumas consultas, nem todas as entradas numa fase têm de ser concluídas para que a fase seja concluída. |
shuffleOutputBytes |
Representa o total de bytes escritos em todos os trabalhadores numa fase de consulta. |
shuffleOutputBytesSpilled |
As consultas que transmitem dados significativos entre fases podem ter de recorrer à transmissão baseada em disco. A estatística de bytes derramados comunica a quantidade de dados que foram derramados para o disco. Depende de um algoritmo de otimização, pelo que não é determinístico para nenhuma consulta específica. |
Classificação de tempo por etapa
As fases da consulta fornecem classificações de tempo das fases, de forma relativa e absoluta. Uma vez que cada fase de execução representa o trabalho realizado por um ou mais trabalhadores independentes, as informações são fornecidas em tempos médios e no pior cenário. Estes tempos representam o desempenho médio de todos os trabalhadores numa fase, bem como o desempenho do trabalhador mais lento de cauda longa para uma determinada classificação. Além disso, os tempos médios e máximos são discriminados em representações absolutas e relativas. Para estatísticas baseadas em rácios, os dados são fornecidos como uma fração do tempo mais longo gasto por qualquer trabalhador em qualquer segmento.
A Google Cloud consola apresenta a sincronização das fases através das representações de sincronização relativas.
As informações de tempo das fases são comunicadas da seguinte forma:
| Tempo relativo | Tempo absoluto | Numerador do rácio |
|---|---|---|
waitRatioAvg |
waitMsAvg |
Tempo que o trabalhador médio passou à espera de ser agendado. |
waitRatioMax |
waitMsMax |
Tempo que o trabalhador mais lento passou à espera de ser agendado. |
readRatioAvg |
readMsAvg |
Tempo que o trabalhador médio passou a ler os dados de entrada. |
readRatioMax |
readMsMax |
Tempo que o trabalhador mais lento passou a ler os dados de entrada. |
computeRatioAvg |
computeMsAvg |
Tempo que o trabalhador médio passou limitado pela CPU. |
computeRatioMax |
computeMsMax |
Tempo que o trabalhador mais lento passou limitado pela CPU. |
writeRatioAvg |
writeMsAvg |
Tempo que o trabalhador médio passou a escrever dados de saída. |
writeRatioMax |
writeMsMax |
Tempo que o trabalhador mais lento passou a escrever dados de saída. |
Vista geral do passo
Os passos contêm as operações que cada trabalhador numa fase executa, apresentadas como uma lista ordenada de operações. Cada operação de passo tem uma categoria, e algumas operações fornecem informações mais detalhadas. As categorias de operações presentes no plano de consulta incluem o seguinte:
| Categoria do passo | Descrição |
|---|---|
READ |
Uma leitura de uma ou mais colunas de uma tabela de entrada ou de uma ordenação aleatória intermédia. Apenas as primeiras dezasseis colunas lidas são devolvidas nos detalhes do passo. |
WRITE |
Uma gravação de uma ou mais colunas numa tabela de saída ou numa ordenação aleatória intermédia. Para resultados particionados HASH de uma fase, isto também inclui as colunas usadas como chave de partição. |
COMPUTE |
Avaliação de expressões e funções SQL. |
FILTER |
Usado pelas cláusulas WHERE, OMIT IF e HAVING. |
SORT |
ORDER BY que inclui as chaves das colunas e a ordem de ordenação. |
AGGREGATE |
Implementa agregações para cláusulas como GROUP BY ou COUNT, entre outras. |
LIMIT |
Implementa a cláusula LIMIT. |
JOIN |
Implementa associações para cláusulas como JOIN, entre outras; inclui o tipo de associação e, possivelmente, as condições de associação. |
ANALYTIC_FUNCTION |
Uma invocação de uma função de janela (também conhecida como "função analítica"). |
USER_DEFINED_FUNCTION |
Uma invocação de uma função definida pelo utilizador. |
Compreenda os detalhes dos passos
O BigQuery fornece detalhes dos passos que explicam o que cada passo fez numa fase. Compreender os passos numa fase é necessário para identificar a origem dos problemas de desempenho das consultas.
Para encontrar os detalhes dos passos de uma fase, siga estes passos:
No painel Resultados da consulta, clique em Gráfico de execução.
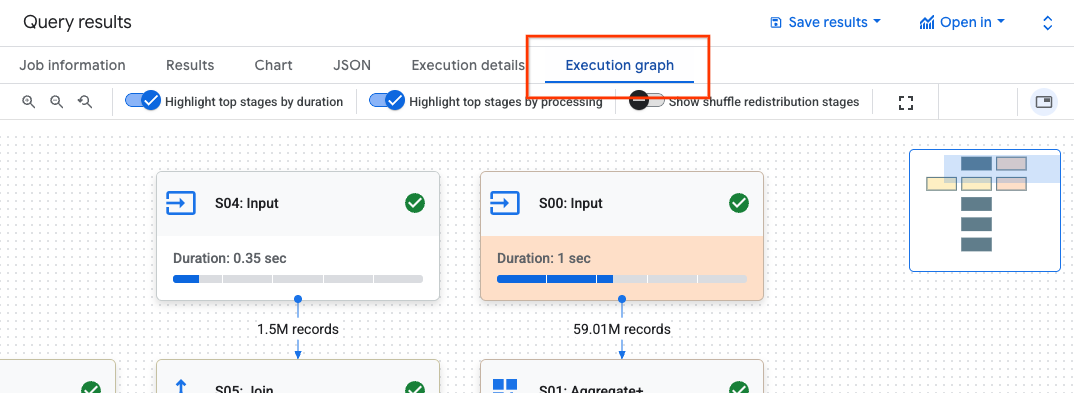
Clique na fase na qual tem interesse para abrir um painel com informações da fase.
No painel com informações da fase, aceda à secção Detalhes do passo.

Cada passo consiste em subpassos que descrevem o que o passo fez. Os subpassos usam variáveis para descrever as relações entre os passos. As variáveis começam com um sinal de dólar seguido de um número único.
Segue-se um exemplo dos detalhes dos passos de uma fase com variáveis partilhadas entre passos:
READ $30:l_orderkey, $31:l_quantity FROM lineitem AGGREGATE GROUP BY $100 := $30 $70 := SUM($31) WRITE $100, $70 TO __stage00_output BY HASH($100)
Os detalhes dos passos do exemplo fazem o seguinte:
A fase leu as colunas
l_orderkeyel_quantityda tabelalineitemusando as variáveis$30e$31, respetivamente.A fase agregada nas variáveis
$30e$31, armazenando agregações nas variáveis$100e$70, respetivamente.A fase escreveu os resultados das variáveis
$100e$70para serem misturadas. A fase usou$100para ordenar os resultados da fase de forma aleatória.
O BigQuery pode truncar os detalhes dos passos quando o gráfico de execução da consulta for suficientemente complexo para que o fornecimento de detalhes completos dos passos da fase cause problemas de tamanho do payload ao obter informações da consulta.
Compreenda os passos com o texto da consulta
Para receber apoio técnico durante a pré-visualização, envie um email para bq-query-inspector-feedback@google.com.
Compreender a relação entre os passos da fase e a consulta pode ser difícil. A secção Texto da consulta mostra como alguns passos se relacionam com o texto da consulta original.
A secção Texto da consulta realça diferentes partes do texto da consulta original e mostra os passos que mapeiam de volta para o texto da consulta imediatamente anterior ao texto da consulta original realçado. Apenas os passos imediatamente acima de uma parte realçada do texto da consulta original se aplicam ao texto da consulta realçado.
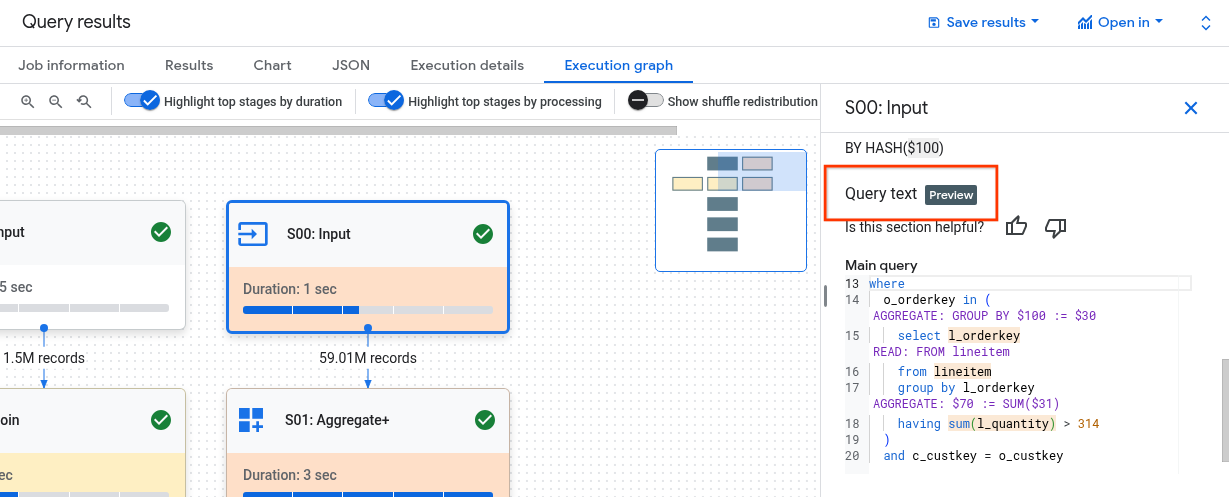
O exemplo de captura de ecrã mostra estes mapeamentos:
O passo
AGGREGATE: GROUP BY $100 := $30é mapeado de volta para o texto da consultaselect l_orderkey.O passo
READ: FROM lineitemé mapeado de volta para o texto da consultaselect ... from lineitem.O passo
AGGREGATE: $70 := SUM($31)é mapeado de volta para o texto da consultasum(l_quantity).
Nem todos os passos podem ser mapeados novamente para o texto da consulta.
Se uma consulta usar vistas e se os passos da fase tiverem mapeamentos para o texto da consulta de uma vista, a secção Texto da consulta mostra o nome da vista e o texto da consulta da vista com os respetivos mapeamentos. No entanto, se a visualização for eliminada ou se perder a bigquery.tables.get autorização do IAM para a visualização, a secção Texto da consulta não mostra os mapeamentos dos passos do palco para a visualização.
Interprete e otimize os passos
As secções seguintes explicam como interpretar os passos num plano de consulta e apresentam formas de otimizar as suas consultas.
READ passo
O passo READ significa que uma fase está a aceder aos dados para processamento. Os dados podem ser lidos diretamente das tabelas referenciadas numa consulta ou da memória de mistura.
Quando os dados de uma fase anterior são lidos, o BigQuery lê os dados da memória de mistura. A quantidade de dados analisados afeta o custo quando usa espaços disponíveis a pedido e afeta o desempenho quando usa reservas.
Potenciais problemas de desempenho
- Leitura grande de uma tabela não particionada: se a consulta só precisar de uma pequena parte dos dados, isto pode indicar que uma leitura da tabela é ineficiente. A partição pode ser uma boa estratégia de otimização.
- Análise de uma tabela grande com uma pequena taxa de filtro: isto sugere que o filtro não está a reduzir eficazmente os dados analisados. Pondere rever as condições do filtro.
- Bytes de mistura derramados no disco: isto sugere que os dados não estão a ser armazenados de forma eficaz através de técnicas de otimização, como o agrupamento, que pode manter dados semelhantes em clusters.
Otimizar
- Filtragem segmentada: use cláusulas
WHEREestrategicamente para filtrar dados irrelevantes o mais cedo possível na consulta. Isto reduz a quantidade de dados que têm de ser processados pela consulta. - Particionamento e agrupamento: o BigQuery usa o particionamento e o agrupamento de tabelas para localizar com eficiência segmentos de dados específicos.
Certifique-se de que as tabelas estão particionadas e agrupadas com base nos padrões de consulta típicos para minimizar os dados analisados durante os passos
READ. - Selecione colunas relevantes: evite usar declarações
SELECT *. Em alternativa, selecione colunas específicas ou useSELECT * EXCEPTpara evitar a leitura de dados desnecessários. - Vistas materializadas: as vistas materializadas podem pré-calcular e armazenar agregações usadas com frequência, o que pode reduzir a necessidade de ler tabelas base durante os passos
READpara consultas que usam essas vistas.
COMPUTE passo
No passo COMPUTE, o BigQuery realiza as seguintes ações nos seus dados:
- Avalia expressões nas cláusulas
SELECT,WHERE,HAVINGe outras da consulta, incluindo cálculos, comparações e operações lógicas. - Executa funções SQL integradas e funções definidas pelo utilizador.
- Filtra linhas de dados com base nas condições da consulta.
Otimizar
O plano de consulta pode revelar obstáculos no passo COMPUTE. Procure fases com cálculos extensos ou um número elevado de linhas processadas.
- Correlacione o passo
COMPUTEcom o volume de dados: se uma fase mostrar computação significativa e processar um grande volume de dados, pode ser um bom candidato para otimização. - Dados distorcidos: para fases em que o máximo de computação é significativamente superior à média de computação, isto indica que a fase passou uma quantidade desproporcionada de tempo a processar algumas divisões de dados. Considere analisar a distribuição dos dados para ver se existe assimetria dos dados.
- Considere os tipos de dados: use tipos de dados adequados para as suas colunas. Por exemplo, usar números inteiros, datas/horas e datas/horas com indicação de tempo em vez de strings pode melhorar o desempenho.
WRITE passo
WRITE passos ocorrem para os dados intermédios e o resultado final.
- Escrita na memória de classificação: numa consulta de várias fases, o passo
WRITEenvolve frequentemente o envio dos dados processados para outra fase para processamento adicional. Isto é típico da memória de mistura, que combina ou agrega dados de várias origens. Os dados escritos durante esta fase são normalmente um resultado intermédio e não o resultado final. - Resultado final: o resultado da consulta é escrito no destino ou numa tabela temporária.
Partição hash
Quando uma fase no plano de consulta escreve dados numa saída particionada por hash, o BigQuery escreve as colunas incluídas na saída e a coluna escolhida como chave de partição.
Otimizar
Embora o passo WRITE em si possa não ser otimizado diretamente, compreender o seu papel pode ajudar a identificar potenciais gargalos em fases anteriores:
- Minimize os dados escritos: foque-se na otimização das fases anteriores com a filtragem e a agregação para reduzir a quantidade de dados escritos durante este passo.
Particionamento: a escrita beneficia muito do particionamento de tabelas. Se os dados que escreve estiverem confinados a partições específicas, o BigQuery pode realizar escritas mais rápidas.
Se a declaração DML tiver uma cláusula
WHEREcom uma condição estática em relação a uma coluna de partição da tabela, o BigQuery só modifica as partições da tabela relevantes.Compromissos de desnormalização: por vezes, a desnormalização pode gerar conjuntos de resultados mais pequenos no passo
WRITEintermédio. No entanto, existem desvantagens, como o aumento da utilização do armazenamento e os desafios de consistência dos dados.
JOIN passo
No passo JOIN, o BigQuery combina dados de duas origens de dados.
As junções podem incluir condições de junção. As junções consomem muitos recursos. Quando une grandes quantidades de dados no BigQuery, as chaves de união são atribuídas aleatoriamente de forma independente para se alinharem na mesma posição, de modo que a união seja realizada localmente em cada posição.
O plano de consulta do passo JOIN revela normalmente os seguintes detalhes:
- Padrão de junção: indica o tipo de junção usado. Cada tipo define quantas linhas das tabelas unidas são incluídas no conjunto de resultados.
- Juntar colunas: estas são as colunas usadas para fazer corresponder linhas entre as fontes de dados. A escolha das colunas é fundamental para o desempenho da junção.
Junte padrões
- União de transmissão: quando uma tabela, normalmente a mais pequena, cabe na memória num único nó de trabalho ou espaço, o BigQuery pode transmiti-la a todos os outros nós para fazer a união de forma eficiente. Procure
JOIN EACH WITH ALLnos detalhes do passo. - Hash join: quando as tabelas são grandes ou um broadcast join não é adequado, pode ser usado um hash join. O BigQuery usa operações de hash e aleatorização para aleatorizar as tabelas esquerda e direita, de modo que as chaves correspondentes acabem no mesmo espaço para fazer uma união local. As junções de hash são uma operação dispendiosa, uma vez que os dados têm de ser movidos, mas permitem uma correspondência eficiente de linhas entre hashes. Procure
JOIN EACH WITH EACHnos detalhes do passo. - Junção automática: um antipadrão de SQL em que uma tabela é unida a si própria.
- Junção cruzada: um antipadrão de SQL que pode causar problemas de desempenho significativos porque gera dados de saída maiores do que as entradas.
- Junção enviesada: a distribuição de dados na chave de junção numa tabela está muito enviesada e pode originar problemas de desempenho. Procure casos em que o tempo de cálculo máximo é muito superior ao tempo de cálculo médio no plano de consulta. Para mais informações, consulte os artigos Junção de cardinalidade elevada e Desvio de partição.
Depuração
- Grande volume de dados: se o plano de consulta mostrar uma quantidade significativa de dados processados durante o passo
JOIN, investigue a condição de junção e as chaves de junção. Pondere filtrar ou usar chaves de junção mais seletivas. - Distribuição de dados enviesada: analise a distribuição de dados das chaves de junção. Se uma tabela estiver muito desequilibrada, explore estratégias como dividir a consulta ou pré-filtrar.
- Junções de elevada cardinalidade: as junções que produzem significativamente mais linhas do que o número de linhas de entrada à esquerda e à direita podem reduzir drasticamente o desempenho das consultas. Evite junções que produzam um número muito grande de linhas.
- Ordenação incorreta da tabela: certifique-se de que escolheu o tipo de junção adequado, como
INNERouLEFT, e ordenou as tabelas da maior para a menor com base nos requisitos da sua consulta.
Otimizar
- Chaves de junção seletivas: para chaves de junção, use
INT64em vez deSTRINGquando possível. As comparaçõesSTRINGsão mais lentas do que as comparaçõesINT64porque comparam cada caráter numa string. Os números inteiros só requerem uma única comparação. - Filtrar antes da união: aplique filtros de cláusulas
WHEREem tabelas individuais antes da união. Isto reduz a quantidade de dados envolvidos na operação de junção. - Evite funções em colunas de junção: evite chamar funções em colunas de junção. Em alternativa, padronize os dados das tabelas durante o processo de carregamento ou pós-carregamento através de pipelines SQL ELT. Esta abordagem elimina a necessidade de modificar dinamicamente as colunas de junção, o que permite junções mais eficientes sem comprometer a integridade dos dados.
- Evite junções automáticas: as junções automáticas são usadas frequentemente para calcular relações dependentes das linhas. No entanto, as auto-uniões podem quadruplicar potencialmente o número de linhas de saída, o que pode causar problemas de desempenho. Em vez de depender de junções automáticas, considere usar funções de janela (analíticas).
- Tabelas grandes primeiro: embora o otimizador de consultas SQL possa determinar que tabela deve estar em que lado da junção, ordene as tabelas unidas adequadamente. A prática recomendada é colocar primeiro a tabela maior, seguida da menor e, depois, por ordem decrescente de tamanho.
- Desnormalização: em alguns casos, a desnormalização estratégica das tabelas (adicionar dados redundantes) pode eliminar as junções por completo. No entanto, esta abordagem tem desvantagens em termos de armazenamento e consistência dos dados.
- Particionamento e clustering: o particionamento de tabelas com base em chaves de junção e o clustering de dados colocados podem acelerar significativamente as junções, permitindo que o BigQuery segmente partições de dados relevantes.
- Otimizar uniões desequilibradas: para evitar problemas de desempenho associados a uniões desequilibradas, pré-filtre os dados da tabela o mais cedo possível ou divida a consulta em duas ou mais consultas.
AGGREGATE passo
No passo AGGREGATE, o BigQuery agrega e agrupa os dados.
Depuração
- Detalhes da fase: verifique o número de linhas de entrada e de saída da agregação, bem como o tamanho da mistura, para determinar a redução de dados alcançada pela etapa de agregação e se a mistura de dados esteve envolvida.
- Tamanho da aleatorização: um tamanho da aleatorização grande pode indicar que uma quantidade significativa de dados foi movida entre nós de trabalho durante a agregação.
- Verifique a distribuição de dados: certifique-se de que os dados estão distribuídos uniformemente pelas partições. A distribuição de dados enviesada pode levar a cargas de trabalho desequilibradas no passo de agregação.
- Reveja as agregações: analise as cláusulas de agregação para confirmar se são necessárias e eficientes.
Otimizar
- Agrupamento: agrupe as tabelas em colunas usadas frequentemente em
GROUP BY,COUNTou outras cláusulas de agregação. - Particionamento: escolha uma estratégia de particionamento que esteja alinhada com os seus padrões de consulta. Considere usar tabelas particionadas por tempo de carregamento para reduzir a quantidade de dados analisados durante a agregação.
- Agregue mais cedo: se possível, faça agregações mais cedo no pipeline de consulta. Isto pode reduzir a quantidade de dados que têm de ser processados durante a agregação.
- Otimização da mistura: se a mistura for um gargalo, explore formas de a minimizar. Por exemplo, desnormalize tabelas ou use o clustering para colocar em conjunto dados relevantes.
Casos extremos
- Agregações DISTINCT: as consultas com agregações
DISTINCTpodem ser computacionalmente dispendiosas, especialmente em conjuntos de dados grandes. Considere alternativas comoAPPROX_COUNT_DISTINCTpara resultados aproximados. - Grande número de grupos: se a consulta produzir um grande número de grupos, pode consumir uma quantidade substancial de memória. Nesses casos, pondere limitar o número de grupos ou usar uma estratégia de agregação diferente.
REPARTITION passo
Ambas as técnicas REPARTITION e COALESCE são técnicas de otimização que o BigQuery aplica diretamente aos dados aleatórios na consulta.
REPARTITION: esta operação destina-se a reequilibrar a distribuição de dados nos nós de trabalho. Suponhamos que, após a mistura, um nó de trabalho acaba por ter uma quantidade desproporcionadamente grande de dados. O passoREPARTITIONredistribui os dados de forma mais uniforme, evitando que qualquer trabalhador individual se torne um obstáculo. Isto é particularmente importante para operações computacionais intensivas, como junções.COALESCE: este passo ocorre quando tem muitos pequenos conjuntos de dados após a mistura. O passoCOALESCEcombina estes contentores em contentores maiores, reduzindo a sobrecarga associada à gestão de vários pequenos fragmentos de dados. Isto pode ser especialmente benéfico quando se lida com conjuntos de resultados intermédios muito pequenos.
Se vir os passos REPARTITION ou COALESCE no seu plano de consulta, não significa necessariamente que exista um problema com a sua consulta. Muitas vezes, é um sinal de que o BigQuery está a otimizar proativamente a distribuição de dados para um melhor desempenho. No entanto, se vir estas operações repetidamente, pode indicar que os seus dados estão inerentemente distorcidos ou que a sua consulta está a causar uma reorganização excessiva dos dados.
Otimizar
Para reduzir o número de passos REPARTITION, experimente o seguinte:
- Distribuição de dados: certifique-se de que as tabelas estão particionadas e agrupadas de forma eficaz. Os dados bem distribuídos reduzem a probabilidade de desequilíbrios significativos após a mistura.
- Estrutura da consulta: analise a consulta para identificar potenciais origens de desequilíbrio dos dados. Por exemplo, existem filtros ou junções altamente seletivos que resultam no processamento de um pequeno subconjunto de dados num único trabalhador?
- Estratégias de junção: faça experiências com diferentes estratégias de junção para ver se resultam numa distribuição de dados mais equilibrada.
Para reduzir o número de passos COALESCE, experimente o seguinte:
- Estratégias de agregação: pondere realizar agregações mais cedo no pipeline de consulta. Isto pode ajudar a reduzir o número de pequenos conjuntos de resultados intermédios que podem causar passos
COALESCE. - Volume de dados: se estiver a trabalhar com conjuntos de dados muito pequenos,
COALESCEpode não ser uma preocupação significativa.
Não otimize em excesso. A otimização prematura pode tornar as suas consultas mais complexas sem gerar vantagens significativas.
Explicação das consultas federadas
As consultas federadas permitem-lhe enviar uma declaração de consulta a uma origem de dados externa através da função EXTERNAL_QUERY.
As consultas federadas estão sujeitas à técnica de otimização conhecida como SQL pushdowns, e o plano de consulta mostra as operações transferidas para a origem de dados externa, se existirem. Por exemplo, se executar a seguinte consulta:
SELECT id, name
FROM EXTERNAL_QUERY("<connection>", "SELECT * FROM company")
WHERE country_code IN ('ee', 'hu') AND name like '%TV%'
O plano de consulta mostra os seguintes passos da fase:
$1:id, $2:name, $3:country_code
FROM table_for_external_query_$_0(
SELECT id, name, country_code
FROM (
/*native_query*/
SELECT * FROM company
)
WHERE in(country_code, 'ee', 'hu')
)
WHERE and(in($3, 'ee', 'hu'), like($2, '%TV%'))
$1, $2
TO __stage00_output
Neste plano, table_for_external_query_$_0(...) representa a função EXTERNAL_QUERY. Entre parênteses, pode ver a consulta que a origem de dados externa executa. Com base nisso, pode reparar que:
- Uma origem de dados externa devolve apenas 3 colunas selecionadas.
- Uma origem de dados externa devolve apenas linhas para as quais
country_codeé'ee'ou'hu'. - O operador
LIKEnão é enviado por push e é avaliado pelo BigQuery.
Para comparação, se não existirem pushdowns, o plano de consulta apresenta os seguintes passos da fase:
$1:id, $2:name, $3:country_code
FROM table_for_external_query_$_0(
SELECT id, name, description, country_code, primary_address, secondary address
FROM (
/*native_query*/
SELECT * FROM company
)
)
WHERE and(in($3, 'ee', 'hu'), like($2, '%TV%'))
$1, $2
TO __stage00_output
Desta vez, uma origem de dados externa devolve todas as colunas e todas as linhas da tabela company, e o BigQuery realiza a filtragem.
Metadados da Linha cronológica
A cronologia de consultas comunica o progresso em pontos específicos no tempo, fornecendo vistas instantâneas do progresso geral das consultas. A cronologia é representada como uma série de exemplos que comunicam os seguintes detalhes:
| Campo | Descrição |
|---|---|
elapsedMs |
Milissegundos decorridos desde o início da execução da consulta. |
totalSlotMs |
Uma representação cumulativa dos milissegundos de espaço usados pela consulta. |
pendingUnits |
Total de unidades de trabalho agendadas e a aguardar execução. |
activeUnits |
Total de unidades de trabalho ativas a serem processadas pelos trabalhadores. |
completedUnits |
O total de unidades de trabalho que foram concluídas durante a execução desta consulta. |
Um exemplo de consulta
A consulta seguinte conta o número de linhas no conjunto de dados público Shakespeare e tem uma segunda contagem condicional que restringe os resultados a linhas que fazem referência a "hamlet":
SELECT
COUNT(1) as rowcount,
COUNTIF(corpus = 'hamlet') as rowcount_hamlet
FROM `publicdata.samples.shakespeare`
Clique em Detalhes da execução para ver o plano de consulta:

Os indicadores de cores mostram as durações relativas de todos os passos em todas as fases.
Para saber mais sobre as etapas das fases de execução, clique em para expandir os detalhes da fase:
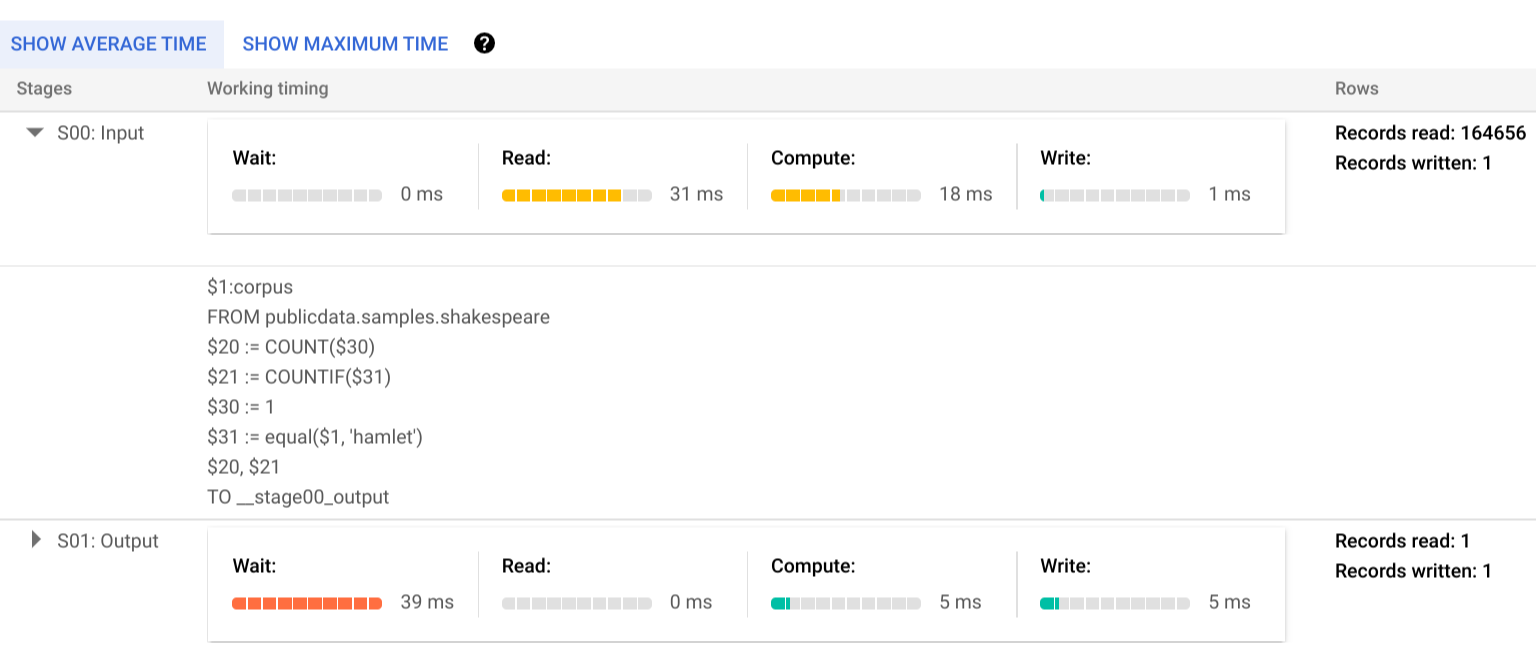
Neste exemplo, o tempo mais longo em qualquer segmento foi o tempo que o único trabalhador na fase 01 passou à espera que a fase 00 fosse concluída. Isto deve-se ao facto de a fase 01 depender da entrada da fase 00 e não poder ser iniciada até que a primeira fase escreva o respetivo resultado na mistura intermédia.
Relatório de erros
É possível que as tarefas de consulta falhem a meio da execução. Uma vez que as informações do plano são atualizadas periodicamente, pode observar onde ocorreu a falha no gráfico de execução. Na Google Cloud consola, as fases bem-sucedidas ou com falhas são etiquetadas com uma marca de verificação ou um ponto de exclamação junto ao nome da fase.
Para mais informações sobre a interpretação e a resolução de erros, consulte o guia de resolução de problemas.
Representação de exemplo da API
As informações do plano de consulta estão incorporadas nas informações de resposta da tarefa e pode
obtê-las chamando jobs.get.
Por exemplo, o seguinte excerto de uma resposta JSON para uma tarefa que devolve a consulta de hamlet de exemplo mostra o plano de consulta e as informações da cronologia.
"statistics": {
"creationTime": "1576544129234",
"startTime": "1576544129348",
"endTime": "1576544129681",
"totalBytesProcessed": "2464625",
"query": {
"queryPlan": [
{
"name": "S00: Input",
"id": "0",
"startMs": "1576544129436",
"endMs": "1576544129465",
"waitRatioAvg": 0.04,
"waitMsAvg": "1",
"waitRatioMax": 0.04,
"waitMsMax": "1",
"readRatioAvg": 0.32,
"readMsAvg": "8",
"readRatioMax": 0.32,
"readMsMax": "8",
"computeRatioAvg": 1,
"computeMsAvg": "25",
"computeRatioMax": 1,
"computeMsMax": "25",
"writeRatioAvg": 0.08,
"writeMsAvg": "2",
"writeRatioMax": 0.08,
"writeMsMax": "2",
"shuffleOutputBytes": "18",
"shuffleOutputBytesSpilled": "0",
"recordsRead": "164656",
"recordsWritten": "1",
"parallelInputs": "1",
"completedParallelInputs": "1",
"status": "COMPLETE",
"steps": [
{
"kind": "READ",
"substeps": [
"$1:corpus",
"FROM publicdata.samples.shakespeare"
]
},
{
"kind": "AGGREGATE",
"substeps": [
"$20 := COUNT($30)",
"$21 := COUNTIF($31)"
]
},
{
"kind": "COMPUTE",
"substeps": [
"$30 := 1",
"$31 := equal($1, 'hamlet')"
]
},
{
"kind": "WRITE",
"substeps": [
"$20, $21",
"TO __stage00_output"
]
}
]
},
{
"name": "S01: Output",
"id": "1",
"startMs": "1576544129465",
"endMs": "1576544129480",
"inputStages": [
"0"
],
"waitRatioAvg": 0.44,
"waitMsAvg": "11",
"waitRatioMax": 0.44,
"waitMsMax": "11",
"readRatioAvg": 0,
"readMsAvg": "0",
"readRatioMax": 0,
"readMsMax": "0",
"computeRatioAvg": 0.2,
"computeMsAvg": "5",
"computeRatioMax": 0.2,
"computeMsMax": "5",
"writeRatioAvg": 0.16,
"writeMsAvg": "4",
"writeRatioMax": 0.16,
"writeMsMax": "4",
"shuffleOutputBytes": "17",
"shuffleOutputBytesSpilled": "0",
"recordsRead": "1",
"recordsWritten": "1",
"parallelInputs": "1",
"completedParallelInputs": "1",
"status": "COMPLETE",
"steps": [
{
"kind": "READ",
"substeps": [
"$20, $21",
"FROM __stage00_output"
]
},
{
"kind": "AGGREGATE",
"substeps": [
"$10 := SUM_OF_COUNTS($20)",
"$11 := SUM_OF_COUNTS($21)"
]
},
{
"kind": "WRITE",
"substeps": [
"$10, $11",
"TO __stage01_output"
]
}
]
}
],
"estimatedBytesProcessed": "2464625",
"timeline": [
{
"elapsedMs": "304",
"totalSlotMs": "50",
"pendingUnits": "0",
"completedUnits": "2"
}
],
"totalPartitionsProcessed": "0",
"totalBytesProcessed": "2464625",
"totalBytesBilled": "10485760",
"billingTier": 1,
"totalSlotMs": "50",
"cacheHit": false,
"referencedTables": [
{
"projectId": "publicdata",
"datasetId": "samples",
"tableId": "shakespeare"
}
],
"statementType": "SELECT"
},
"totalSlotMs": "50"
},
Utilização de informações de execução
Os planos de consulta do BigQuery fornecem informações sobre como o serviço executa consultas, mas a natureza gerida do serviço limita se alguns detalhes são diretamente acionáveis. Muitas otimizações ocorrem automaticamente através da utilização do serviço, o que pode diferir de outros ambientes em que o ajuste, o aprovisionamento e a monitorização podem exigir pessoal dedicado e com conhecimentos.
Para ver técnicas específicas que podem melhorar a execução e o desempenho das consultas, consulte a documentação de práticas recomendadas. As estatísticas do plano de consulta e da cronologia podem ajudar a compreender se determinadas fases dominam a utilização de recursos. Por exemplo, uma fase JOIN que gera muito mais linhas de saída do que linhas de entrada pode indicar uma oportunidade de filtrar mais cedo na consulta.
Além disso, as informações da cronologia podem ajudar a identificar se uma determinada consulta é lenta isoladamente ou devido aos efeitos de outras consultas que competem pelos mesmos recursos. Se observar que o número de unidades ativas permanece limitado ao longo da duração da consulta, mas a quantidade de unidades de trabalho em fila permanece elevada, isto pode representar casos em que a redução do número de consultas simultâneas pode melhorar significativamente o tempo de execução geral de determinadas consultas.