Consultar estadísticas de rendimiento de las consultas
El gráfico de ejecución de una consulta es una representación visual de los pasos que sigue BigQuery para ejecutarla. En este documento se describe cómo usar el gráfico de ejecución de consultas para diagnosticar problemas y ver estadísticas del rendimiento de las consultas.
BigQuery ofrece un rendimiento de las consultas excelente, pero también es un sistema distribuido complejo con muchos factores internos y externos que pueden afectar a la velocidad de las consultas. La naturaleza declarativa de SQL también puede ocultar la complejidad de la ejecución de consultas. Esto significa que, cuando tus consultas se ejecutan más lentamente de lo previsto o más lentamente que en ejecuciones anteriores, puede ser difícil entender qué ha ocurrido.
El gráfico de ejecución de consultas proporciona una interfaz gráfica dinámica para inspeccionar el plan de consultas y los detalles del rendimiento de las consultas. Puedes consultar el gráfico de ejecución de consultas de cualquier consulta en curso o completada.
También puedes usar el gráfico de ejecución de consultas para obtener estadísticas sobre el rendimiento de las consultas. Las estadísticas de rendimiento proporcionan sugerencias para ayudarte a mejorar el rendimiento de las consultas. Como el rendimiento de las consultas tiene muchas facetas, las estadísticas de rendimiento solo pueden ofrecer una imagen parcial del rendimiento general de las consultas.
Permisos obligatorios
Para usar el gráfico de ejecución de consultas, debes tener los siguientes permisos:
bigquery.jobs.getbigquery.jobs.listAll
Estos permisos están disponibles a través de los siguientes roles predefinidos de gestión de identidades y accesos (IAM) de BigQuery:
roles/bigquery.adminroles/bigquery.resourceAdminroles/bigquery.resourceEditorroles/bigquery.resourceViewer
Estructura del gráfico de ejecución
El gráfico de ejecución de consultas ofrece una vista gráfica del plan de consultas en la consola. Cada cuadro representa una fase del plan de consulta, como las siguientes:
- Entrada: leer datos de una tabla o seleccionar columnas específicas
- Unión: combina datos de dos tablas en función de la condición
JOIN - Agregación: realiza cálculos como
SUM. - Ordenar: ordenar los resultados
Las fases se componen de pasos que describen las operaciones individuales que ejecuta cada trabajador en una fase. Puedes hacer clic en una fase para abrirla y ver sus pasos. Las fases también incluyen información sobre la hora relativa y absoluta.
Los nombres de las fases resumen los pasos que realizan. Por ejemplo, una fase con join en su nombre significa que el paso principal de la fase es una operación JOIN. Los nombres de las fases que terminan en + significan que
realizan pasos importantes adicionales. Por ejemplo, una fase con JOIN+ en su nombre significa que la fase realiza una operación de unión y otros pasos importantes.
Las líneas que conectan las fases representan el intercambio de datos intermedios entre las fases. BigQuery almacena los datos intermedios en la memoria de aleatorización mientras se ejecutan las fases. Los números de los bordes indican el número estimado de filas intercambiadas entre las fases. La cuota de memoria de barajado está relacionada con el número de ranuras asignadas a la cuenta. Si se supera la cuota de shuffle, la memoria de shuffle puede pasar al disco y provocar que el rendimiento de las consultas se ralentice considerablemente.
Ver estadísticas de rendimiento de las consultas
Consola
Sigue estos pasos para ver las estadísticas de rendimiento de las consultas:
Abre la página de BigQuery en la Google Cloud consola.
En el panel de la izquierda, haz clic en Explorador:

Si no ves el panel de la izquierda, haz clic en Ampliar panel de la izquierda para abrirlo.
En el panel Explorador, haz clic en Historial de trabajos.
Haz clic en Historial personal o en Historial del proyecto.
En la lista de tareas, busca la tarea de consulta que te interese. Haz clic en Acciones y elige Ver trabajo en el editor.
Selecciona la pestaña Gráfico de ejecución para ver una representación gráfica de cada fase de la consulta:
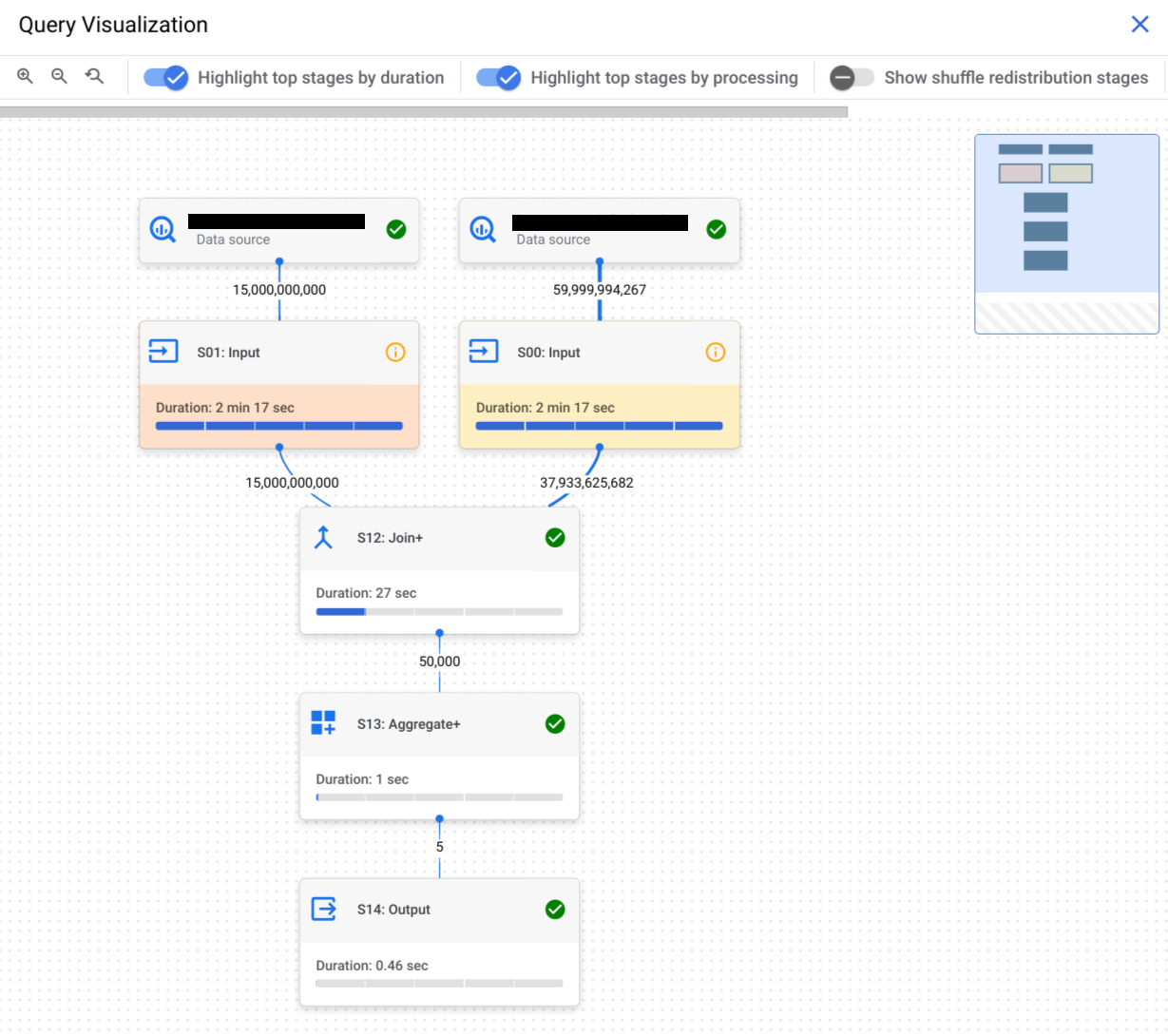
Para determinar si una fase de la consulta tiene estadísticas de rendimiento, fíjate en el icono que muestra. Las fases que tienen un icono de información ofrecen estadísticas de rendimiento. Las fases que tienen un icono de marca de verificación no lo tienen.
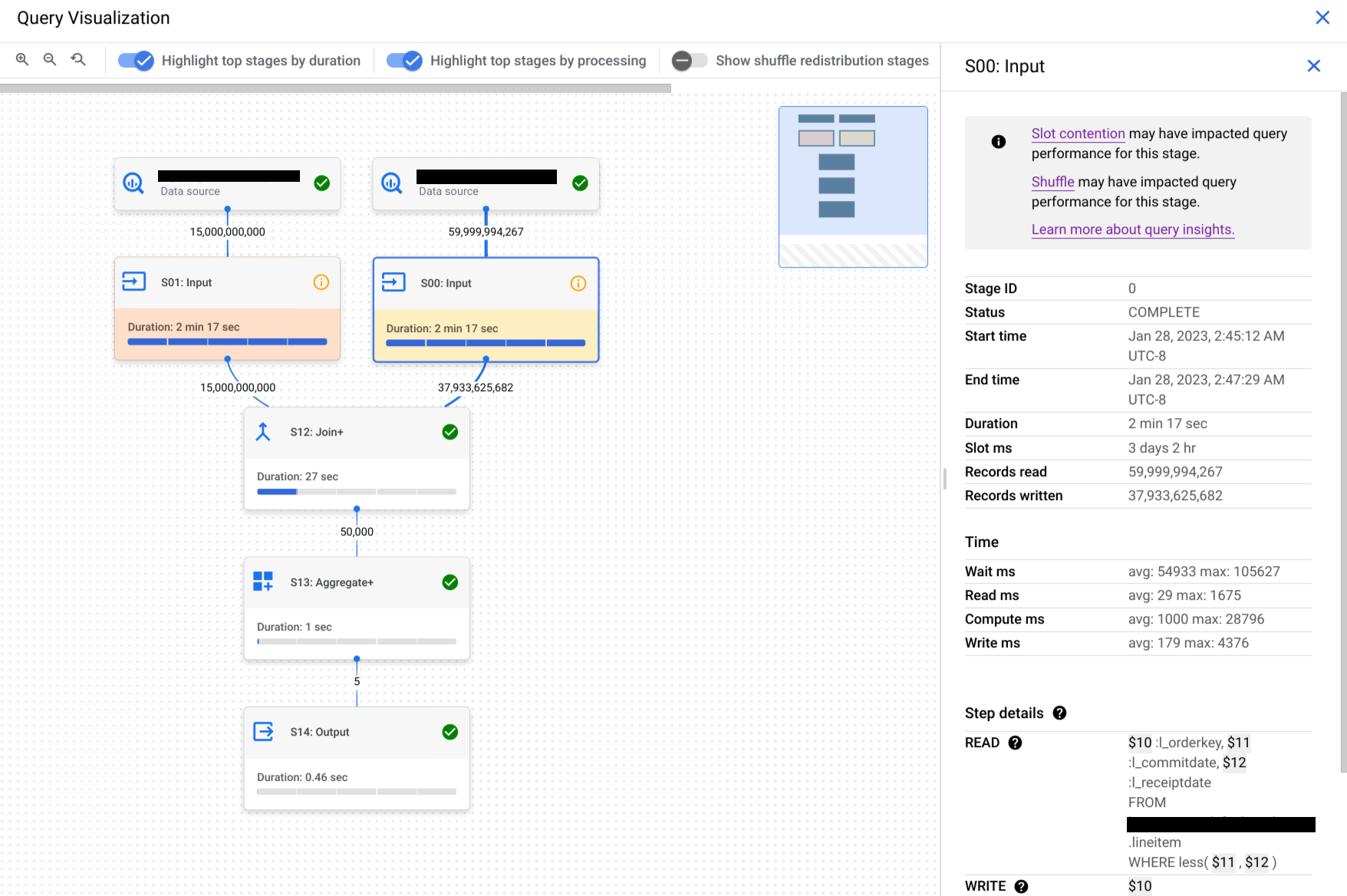
Haga clic en una fase para abrir el panel de detalles de la fase, donde podrá ver la siguiente información:
- Información del plan de consulta de la fase.
- Los pasos ejecutados en la fase.
- Las estadísticas de rendimiento aplicables.
Opcional: Si estás inspeccionando una consulta en ejecución, haz clic en Sincronizar para actualizar el gráfico de ejecución de forma que refleje el estado actual de la consulta.

Opcional: Para destacar las fases principales por duración en el gráfico, haz clic en Destacar las fases principales por duración.

Opcional: Para destacar las fases principales por tiempo de asignación utilizado en el gráfico, haz clic en Destacar las fases principales por procesamiento.

Opcional: Para incluir las fases de redistribución aleatoria en el gráfico, haz clic en Mostrar fases de redistribución aleatoria.

Usa esta opción para mostrar las fases de repartición y coalescencia que están ocultas en el gráfico de ejecución predeterminado.
Las fases de repartición y coalescencia se introducen mientras se ejecuta la consulta y se usan para mejorar la distribución de datos entre los trabajadores que procesan la consulta. Como estas fases no están relacionadas con el texto de la consulta, se ocultan para simplificar el plan de consulta que se muestra.
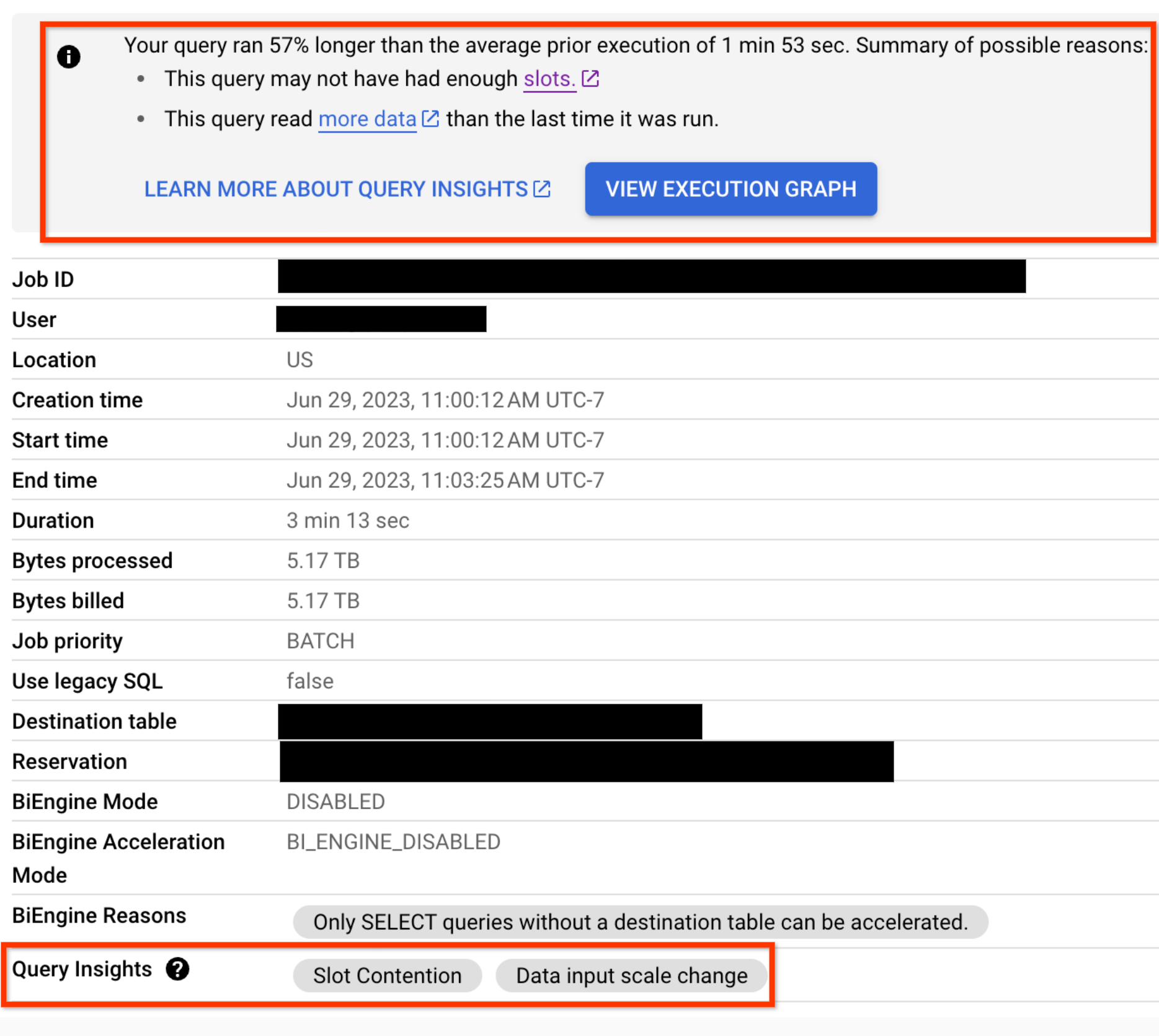
En el caso de las consultas que tengan problemas de regresión del rendimiento, también se mostrarán estadísticas de rendimiento en la pestaña Información del trabajo de la consulta:
SQL
En la Google Cloud consola, ve a la página BigQuery.
En el editor de consultas, introduce la siguiente instrucción:
SELECT `bigquery-public-data`.persistent_udfs.job_url( project_id || ':us.' || job_id) AS job_url, query_info.performance_insights FROM `region-REGION_NAME`.INFORMATION_SCHEMA.JOBS_BY_PROJECT WHERE DATE(creation_time) >= CURRENT_DATE - 30 -- scan 30 days of query history AND job_type = 'QUERY' AND state = 'DONE' AND error_result IS NULL AND statement_type != 'SCRIPT' AND EXISTS ( -- Only include queries which had performance insights SELECT 1 FROM UNNEST( query_info.performance_insights.stage_performance_standalone_insights ) WHERE slot_contention OR insufficient_shuffle_quota UNION ALL SELECT 1 FROM UNNEST( query_info.performance_insights.stage_performance_change_insights ) WHERE input_data_change.records_read_diff_percentage IS NOT NULL );
Haz clic en Ejecutar.
Para obtener más información sobre cómo ejecutar consultas, consulta Ejecutar una consulta interactiva.
API
Para obtener estadísticas sobre el rendimiento de las consultas en un formato no gráfico, llama al método de la API jobs.list e inspecciona la información JobStatistics2 que se devuelve.
Interpretar las estadísticas de rendimiento de las consultas
En esta sección encontrarás más información sobre el significado de las estadísticas de rendimiento y cómo abordarlas.
Las estadísticas de rendimiento están dirigidas a dos tipos de usuarios:
Analistas: ejecutan consultas en un proyecto. Quieres saber por qué una consulta que has ejecutado antes se está ejecutando más lentamente de lo esperado y obtener consejos sobre cómo mejorar el rendimiento de una consulta. Tienes los permisos descritos en la sección Permisos necesarios.
Administradores de lagos de datos o almacenes de datos: gestionan los recursos y las reservas de BigQuery de su organización. Tiene los permisos asociados al rol Administrador de BigQuery.
En cada una de las siguientes secciones se explica qué puedes hacer para abordar una estadística de rendimiento que recibas, en función del rol que tengas.
Contención de ranuras
Cuando ejecutas una consulta, BigQuery intenta dividir el trabajo necesario en tareas. Una tarea es una porción de datos que se introduce y se genera en una fase. Un solo espacio recoge una tarea y ejecuta esa porción de datos de la fase. Lo ideal es que los slots de BigQuery ejecuten estas tareas en paralelo para conseguir un alto rendimiento. La contención de espacios se produce cuando tu consulta tiene muchas tareas listas para empezar a ejecutarse, pero BigQuery no puede obtener suficientes espacios disponibles para ejecutarlas.
Qué hacer si eres analista
Para reducir los datos que procesa en su consulta, siga las indicaciones que se describen en el artículo Reducir los datos procesados en las consultas.
Qué hacer si eres administrador
Para aumentar la disponibilidad de espacios o reducir el uso de espacios, sigue estos pasos:
- Si usas los precios bajo demanda de BigQuery, tus consultas usarán un grupo de ranuras compartido. Considera la posibilidad de pasarte a los precios de análisis basados en la capacidad comprando reservas. Las reservas te permiten reservar ranuras dedicadas para las consultas de tu organización.
Si usas reservas de BigQuery, asegúrate de que haya suficientes ranuras en la reserva asignada al proyecto que ejecutó la consulta. Es posible que la reserva no tenga suficientes espacios en los siguientes casos:
- Hay otras tareas que están consumiendo ranuras de reserva. Puedes usar los gráficos de recursos de administrador para ver cómo está usando tu organización la reserva.
- La reserva no tiene suficientes ranuras asignadas para ejecutar las consultas con la rapidez necesaria. Puedes usar el estimador de ranuras para obtener una estimación del tamaño que deben tener tus reservas para procesar de forma eficiente las tareas de tus consultas.
Para solucionarlo, puedes probar una de las siguientes soluciones:
- Añade más plazas (ya sean plazas de base o plazas máximas de reserva) a esa reserva.
- Crea una reserva adicional y asígnala al proyecto que ejecuta la consulta.
- Espacia las consultas que consumen muchos recursos, ya sea a lo largo del tiempo en una reserva o en diferentes reservas.
Asegúrate de que las tablas que vas a consultar estén agrupadas en clústeres. La agrupación en clústeres ayuda a BigQuery a leer rápidamente las columnas con datos correlacionados.
Asegúrate de que las tablas que vas a consultar tengan particiones. En el caso de las tablas sin particiones, BigQuery lee toda la tabla. Crear particiones en tus tablas te ayuda a asegurarte de que solo consultas el subconjunto de tablas que te interesa.
Cuota de aleatorización insuficiente
Antes de ejecutar una consulta, BigQuery divide la lógica de la consulta en fases. Las ranuras de BigQuery ejecutan las tareas de cada fase. Cuando una ranura completa la ejecución de las tareas de una fase, almacena los resultados intermedios en shuffle. Las fases posteriores de la consulta leen datos de la aleatorización para continuar con la ejecución de la consulta. El error de cuota de aleatorización insuficiente se produce cuando tienes más datos que deben escribirse en la aleatorización de los que tienes capacidad de aleatorización.
Qué hacer si eres analista
Al igual que con la contención de ranuras, reducir la cantidad de datos que procesa tu consulta puede reducir el uso de la aleatorización. Para ello, sigue las instrucciones que se indican en el artículo Reducir los datos procesados en las consultas.
Algunas operaciones de SQL tienden a hacer un uso más intensivo del aleatorio, especialmente las operaciones JOIN y las cláusulas GROUP BY.
Si es posible, reducir la cantidad de datos de estas operaciones puede reducir el uso de la aleatorización.
Qué hacer si eres administrador
Para reducir la contención de la cuota de aleatorización, haz lo siguiente:
- Al igual que con la contención de ranuras, si usas los precios bajo demanda de BigQuery, tus consultas usarán un grupo de ranuras compartido. Considera la posibilidad de pasarte a los precios de análisis basados en la capacidad comprando reservas. Las reservas te proporcionan ranuras y capacidad de Shuffle dedicadas para las consultas de tus proyectos.
Si usas reservas de BigQuery, las ranuras incluyen capacidad de aleatorización dedicada. Si tu reserva está ejecutando algunas consultas que hacen un uso intensivo de la aleatorización, es posible que otras consultas que se ejecuten en paralelo no obtengan suficiente capacidad de aleatorización. Para identificar las tareas que usan la capacidad de orden aleatorio de forma intensiva, consulta la columna
period_shuffle_ram_usage_ratiode la vistaINFORMATION_SCHEMA.JOBS_TIMELINE.Para solucionarlo, puedes probar una o varias de las siguientes soluciones:
- Añade más plazas a esa reserva.
- Crea una reserva adicional y asígnala al proyecto que ejecuta la consulta.
- Espacia las consultas que requieran muchos reordenamientos, ya sea a lo largo del tiempo en una reserva o en diferentes reservas.
Cambio de escala de entrada de datos
Si recibe esta información valiosa sobre el rendimiento, significa que su consulta está leyendo al menos un 50% más de datos de una tabla de entrada determinada que la última vez que ejecutó la consulta. Puede usar el historial de cambios de la tabla para ver si el tamaño de alguna de las tablas usadas en la consulta ha aumentado recientemente.
Qué hacer si eres analista
Para reducir los datos que procesa en su consulta, siga las indicaciones que se describen en el artículo Reducir los datos procesados en las consultas.
Combinación de alta cardinalidad
Cuando una consulta contiene una unión con claves no únicas en ambos lados de la unión, el tamaño de la tabla de salida puede ser considerablemente mayor que el tamaño de cualquiera de las tablas de entrada. Esta estadística indica que la proporción de filas de salida con respecto a las de entrada es alta y ofrece información sobre estos recuentos de filas.
Qué hacer si eres analista
Comprueba las condiciones de unión para confirmar que el aumento del tamaño de la tabla de salida es el esperado. Evita usar combinaciones cruzadas.
Si debes usar una combinación cruzada, prueba a usar una cláusula GROUP BY para preagregar resultados o usa una función de ventana. Para obtener más información, consulta Reducir los datos antes de usar una JOIN.
Desviación de partición
Para enviar comentarios o solicitar asistencia con esta función, envía un correo a bq-query-inspector-feedback@google.com.
Una distribución de datos sesgada puede provocar que las consultas se ejecuten lentamente. Cuando se ejecuta una consulta, BigQuery divide los datos en particiones pequeñas para procesarlos en paralelo. El sesgo se produce cuando los datos se distribuyen de forma desigual entre estas particiones, a menudo debido a valores que se repiten con frecuencia en las claves de unión o de agrupación, lo que hace que algunas particiones sean significativamente más grandes que otras. Como un solo espacio procesa una partición completa y no puede compartir el trabajo, una partición demasiado grande puede ralentizar el procesamiento, provocar errores de "recurso excedido" y, en casos extremos, bloquear el espacio.
Mientras ejecutas una operación JOIN, BigQuery particiona los datos de los lados izquierdo y derecho de la unión en función de las claves de unión. Si una partición es demasiado grande, BigQuery intenta reequilibrar los datos. Si la
asimetría es demasiado grave para reequilibrarse por completo, se añade una estadística de asimetría de partición a la
fase JOIN del gráfico de ejecución.
Identificar la asimetría de partición
Usa la pestaña Gráfico de ejecución de BigQuery Studio para ver en qué fase de la consulta se produce la asimetría de partición. La estadística se marca en el escenario. En los detalles de la fase, puedes determinar la parte pertinente del texto de la consulta y las tablas que se están procesando. Para obtener más información, consulta Interpretar los pasos con texto de consulta.
Ejemplo
La siguiente consulta combina información de repositorios con información de archivos. La asimetría puede producirse si algunos repositorios tienen muchos más archivos que otros.
SELECT r.repo_name, COUNT(f.path) AS file_count
FROM `bigquery-public-data.github_repos.sample_repos` AS r
JOIN `bigquery-public-data.github_repos.sample_files` AS f
ON r.repo_name = f.repo_name
WHERE r.watch_count > 10
GROUP BY r.repo_name
La clave de unión es repo_name. En la tabla sample_repos, se espera que repo_name sea único. Sin embargo, en la tabla sample_files, repo_name puede aparecer muchas veces. Si algunos valores de repo_name aparecen con una frecuencia desproporcionada en sample_files, se produce una asimetría de datos.
Para confirmar si hay un sesgo de datos, analiza la distribución de la clave de unión en la tabla más grande (sample_files en este caso). Ejecuta la siguiente consulta para evaluar la distribución de repo_name:
SELECT repo_name, COUNT(*) AS occurrences
FROM `bigquery-public-data.github_repos.sample_files`
GROUP BY repo_name
ORDER BY occurrences DESC
En el caso de las tablas muy grandes, usa la función APPROX_TOP_COUNT
para estimar de forma eficiente los valores más frecuentes.
SELECT APPROX_TOP_COUNT(repo_name, 100)
FROM `bigquery-public-data.github_repos.sample_files`
Si los recuentos de los valores principales son órdenes de magnitud mayores que otros, significa que hay un sesgo en los datos.
Mitigar la asimetría de las particiones
Puedes usar las siguientes estrategias para abordar el sesgo de partición:
- Filtra los datos al principio. Reduce la cantidad de datos que se procesan aplicando filtros lo antes posible en tu consulta. De esta forma, se puede reducir el número de filas asociadas a claves sesgadas antes de que lleguen a operaciones como
JOINoGROUP BY. Divide la consulta para aislar las teclas que no funcionan correctamente. Si la asimetría se debe a unos pocos valores de clave específicos, como el campo
repo_namedel ejemplo anterior, plantéate dividir la consulta. Procesa los datos de las claves sesgadas por separado del resto de los datos y, a continuación, combina los resultados conUNION ALL.Ejemplo: aislar una clave que se usa con frecuencia.
-- Query for the skewed key SELECT r.repo_name, COUNT(f.path) AS file_count FROM `bigquery-public-data.github_repos.sample_repos` AS r JOIN `bigquery-public-data.github_repos.sample_files` AS f ON r.repo_name = f.repo_name WHERE r.watch_count > 10 AND r.repo_name = 'popular_repo' GROUP BY r.repo_name UNION ALL -- Query for all other keys SELECT r.repo_name, COUNT(f.path) AS file_count FROM `bigquery-public-data.github_repos.sample_repos` AS r JOIN `bigquery-public-data.github_repos.sample_files` AS f ON r.repo_name = f.repo_name WHERE r.watch_count > 10 AND r.repo_name != 'popular_repo' GROUP BY r.repo_nameGestionar
NULLy los valores predeterminados: una causa habitual de la asimetría es un gran número de filas con valoresNULLo cadenas vacías en las columnas clave. Si no necesitas estas filas para el análisis, puedes excluirlas con una cláusulaWHEREantes deJOINoGROUP BY.Reordenar operaciones: en las consultas con varias uniones, el orden puede ser importante. Si es posible, realiza combinaciones que reduzcan significativamente el número de filas en una fase anterior de la consulta.
Usar funciones aproximadas: en las agregaciones de datos sesgados, plantéate si es aceptable un resultado aproximado. Las funciones como
APPROX_COUNT_DISTINCTtoleran más la asimetría de los datos que las funciones exactas, comoCOUNT(DISTINCT).
Interpretar la información de las fases de las consultas
Además de usar las estadísticas del rendimiento de las consultas, también puedes seguir estas directrices cuando revises los detalles de las fases de las consultas para determinar si hay algún problema con una consulta:
- Si el valor de Espera (ms) de una o varias fases es alto en comparación con las ejecuciones anteriores de la consulta:
- Comprueba si tienes suficientes espacios disponibles para tu carga de trabajo. Si no es así, equilibra la carga cuando ejecutes consultas que consuman muchos recursos para que no compitan entre sí.
- Si el valor de Espera (ms) es más alto que en una sola fase, consulta la fase anterior para ver si se ha introducido un cuello de botella. Los cambios sustanciales en los datos o el esquema de las tablas implicadas en la consulta pueden afectar al rendimiento de la consulta.
- Si el valor de Bytes de salida de la aleatorización de una fase es alto en comparación con las ejecuciones anteriores de la consulta o con una fase anterior, evalúa los pasos procesados en esa fase para ver si alguno crea cantidades de datos inesperadamente grandes. Una causa habitual de este problema es que un paso procese un
INNER JOINen el que haya claves duplicadas en ambos lados de la unión. Esto puede devolver una cantidad de datos inesperadamente grande. - Usa el gráfico de ejecución para ver las fases principales por duración y procesamiento. Ten en cuenta la cantidad de datos que generan y si es proporcional al tamaño de las tablas a las que se hace referencia en la consulta. Si no es así, revisa los pasos de esas fases para ver si alguno de ellos puede generar una cantidad inesperada de datos provisionales.
Siguientes pasos
- Consulta las directrices de optimización de consultas para obtener consejos sobre cómo mejorar el rendimiento de las consultas.