Obtenir des insights sur les performances des requêtes
Le graphique d'exécution d'une requête est une représentation visuelle des étapes suivies par BigQuery pour exécuter la requête. Ce document explique comment utiliser le graphique d'exécution de requêtes pour diagnostiquer les problèmes de performances des requêtes et afficher les insights correspondants.
BigQuery offre des performances de requête élevées, mais il s'agit d'un système distribué complexe doté de nombreux facteurs internes et externes qui peuvent affecter la vitesse des requêtes. La nature déclarative du langage SQL peut également masquer la complexité de l'exécution des requêtes. Par conséquent, il peut être difficile de comprendre ce qui s'est passé lorsque les requêtes s'exécutent plus lentement que prévu ou que lors d'exécutions précédentes.
Le graphique d'exécution de requête fournit une interface graphique dynamique permettant d'inspecter le plan de requête et les détails des performances des requêtes. Vous pouvez examiner le graphique d'exécution de requête pour toute requête en cours d'exécution ou terminée.
Vous pouvez également utiliser le graphique d'exécution de requête pour obtenir des informations sur les performances des requêtes. Les insights sur les performances fournissent des suggestions d'optimisation pour vous aider à améliorer les performances des requêtes. Étant donné que les performances des requêtes possèdent plusieurs attributs, les insights sur les performances peuvent ne fournir qu'une idée partielle des performances globales des requêtes.
Autorisations requises
Pour utiliser le graphique d'exécution de requête, vous devez disposer des autorisations suivantes :
bigquery.jobs.getbigquery.jobs.listAll
Ces autorisations sont disponibles via les rôles IAM (Identity and Access Management) prédéfinis suivants :
roles/bigquery.adminroles/bigquery.resourceAdminroles/bigquery.resourceEditorroles/bigquery.resourceViewer
Structure du graphique d'exécution
Le graphique d'exécution de la requête fournit une vue graphique du plan de requête dans la console. Chaque boîte représente une étape du plan de requête, comme les suivantes :
- Entrée : lecture des données d'un tableau ou sélection de colonnes spécifiques
- Joindre : fusionner les données de deux tables en fonction de la condition
JOIN - Agrégation : effectuer des calculs tels que
SUM - Trier : ordonner les résultats
Les phases sont constituées d'étapes qui décrivent les opérations individuelles que chaque nœud de calcul d'une phase exécute. Vous pouvez cliquer sur une étape pour l'ouvrir et afficher ses étapes. Les étapes incluent également des informations sur la durée relative et absolue.
Les noms des étapes résument les actions qu'elles effectuent. Par exemple, une étape dont le nom contient join signifie que l'étape principale est une opération JOIN. Les noms d'étapes qui se terminent par + signifient qu'elles effectuent des étapes importantes supplémentaires. Par exemple, une étape dont le nom contient JOIN+ signifie qu'elle effectue une opération de jointure et d'autres étapes importantes.
Les lignes qui relient les étapes représentent l'échange de données intermédiaires entre les étapes. BigQuery stocke les données intermédiaires dans la mémoire de brassage pendant l'exécution des étapes. Les nombres sur les bords indiquent le nombre estimé de lignes échangées entre les étapes. Le quota de mémoire de shuffle est corrélé au nombre d'emplacements attribués au compte. Si le quota de brassage est dépassé, la mémoire de brassage peut déborder sur le disque et ralentir considérablement les performances des requêtes.
Afficher les informations sur les performances des requêtes
Console
Pour afficher des insights sur les performances des requêtes, procédez comme suit :
Ouvrez la page BigQuery dans la console Google Cloud .
Dans le panneau de gauche, cliquez sur Explorer :

Si le volet de gauche n'apparaît pas, cliquez sur Développer le volet de gauche pour l'ouvrir.
Dans le volet Explorateur, cliquez sur Historique des tâches.
Cliquez sur Historique personnel ou Historique du projet.
Dans la liste des jobs, identifiez celui qui vous intéresse. Cliquez sur Actions, puis sélectionnez Afficher le job dans l'éditeur.
Sélectionnez l'onglet Graphique d'exécution pour afficher une représentation graphique de chaque étape de la requête :
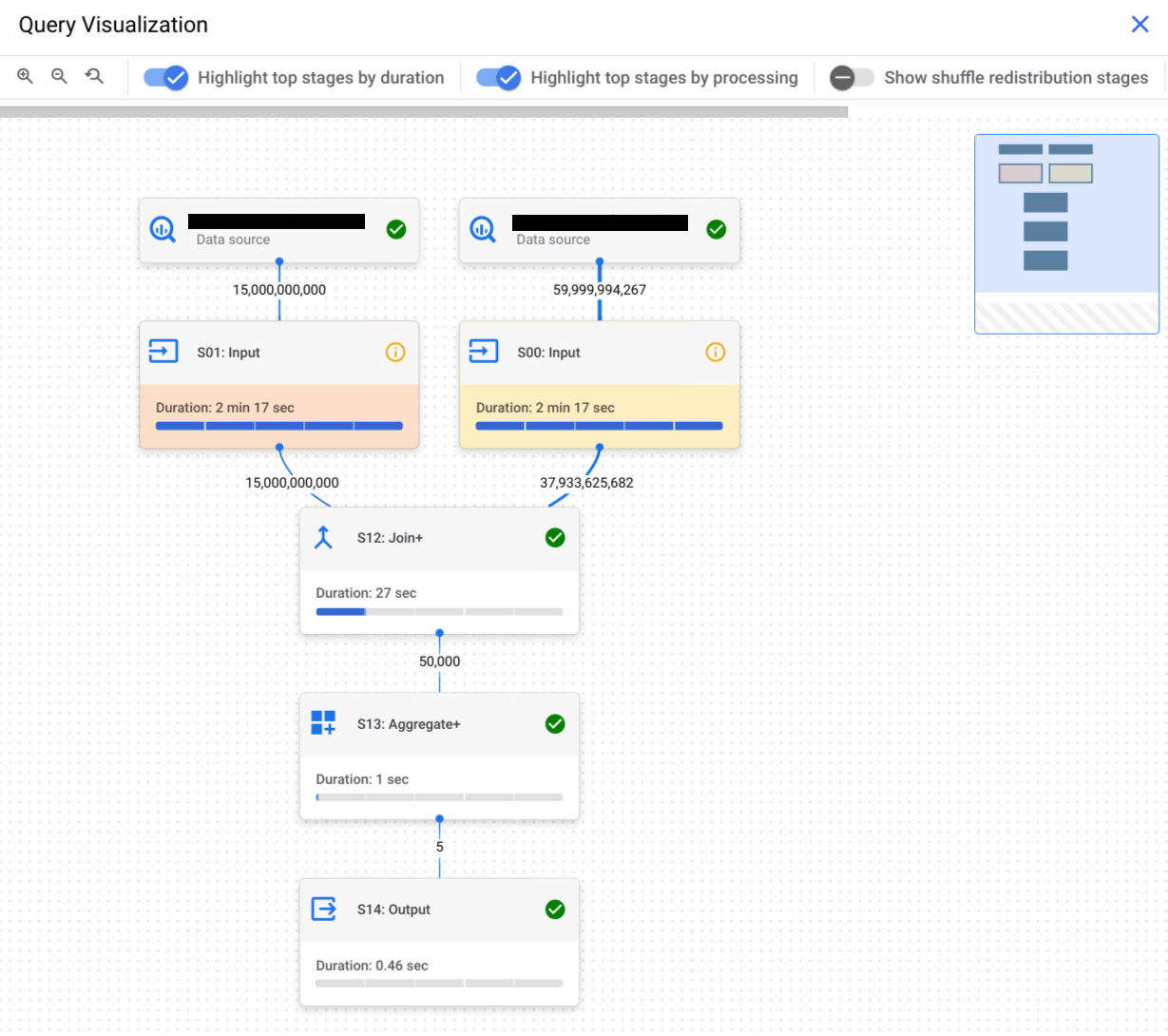
Pour déterminer si une phase de requête comporte des insights sur les performances, consultez l'icône qui s'affiche. Les phases comportant une icône d'information disposent d'insights sur les performances. Les phases comportant une icône représentant une coche n'en disposent pas pas.
Cliquez sur une étape pour ouvrir son volet, dans lequel vous pouvez voir les informations suivantes :
- Informations sur le plan de requête de l'étape.
- Les étapes exécutées dans l'étape.
- Toutes les informations sur les performances applicables.
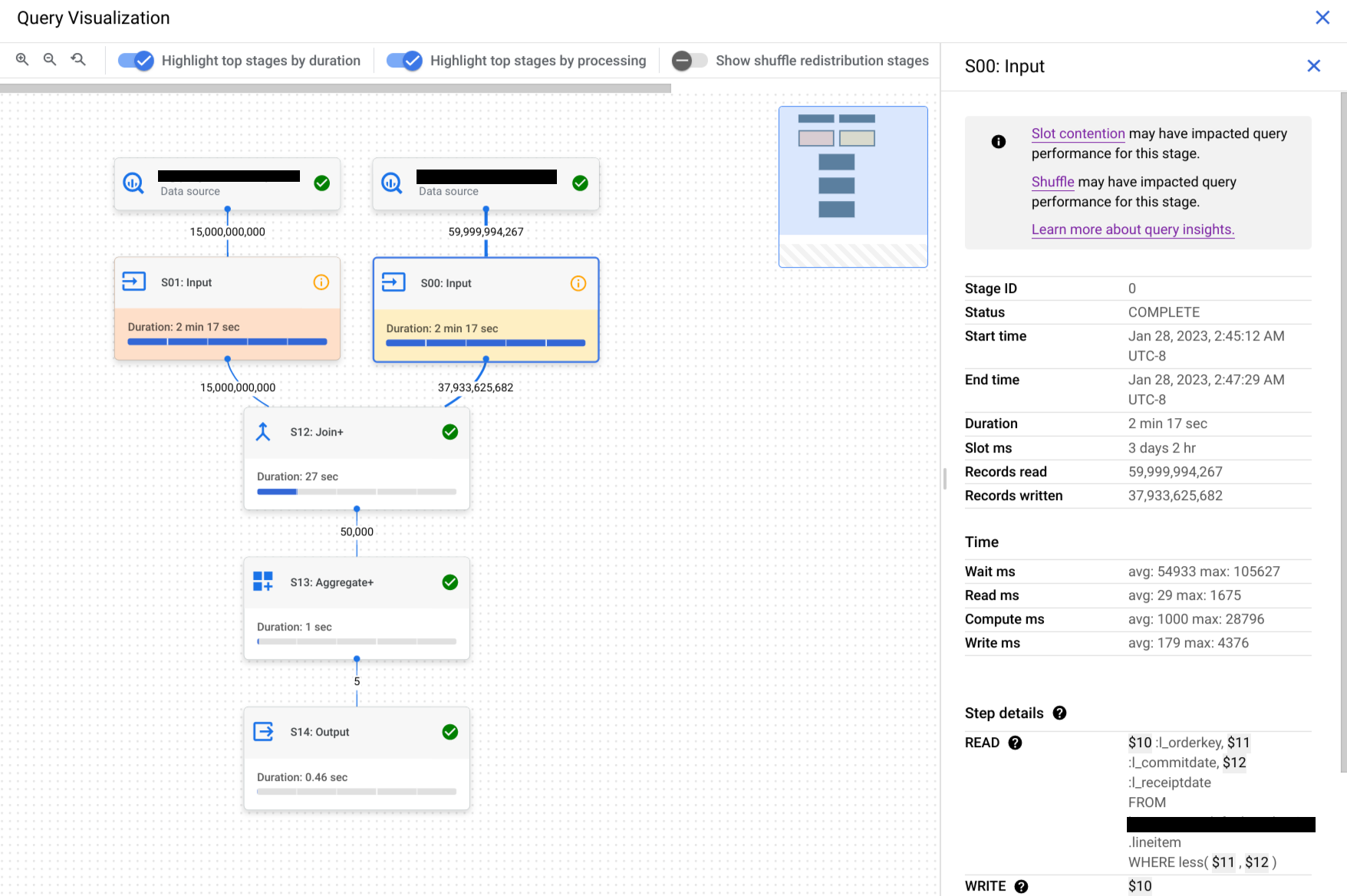
Facultatif : Si vous inspectez une requête en cours d'exécution, cliquez sur Sync (Synchroniser) pour mettre à jour le graphique d'exécution afin qu'il reflète l'état actuel de la requête.

Facultatif : Pour mettre en évidence les principales phases sur le graphique en fonction de leur durée, cliquez sur Highlight top stages by duration (Mettre en évidence les principales phases par durée).

Facultatif : Pour mettre en évidence les principales phases sur le graphique en fonction de leur durée d'utilisation des emplacements, cliquez sur Highlight top stages by processing (Mettre en évidence les principales phases par traitement).

Facultatif : pour inclure les phases de redistribution du brassage sur le graphique, cliquez sur Show shuffle redistribution stages (Afficher les phases de redistribution du brassage).

Cette option permet d'afficher les phases de répartition et de réduction masquées dans le graphique d'exécution par défaut.
Des phases de répartition et de réduction sont introduites pendant l'exécution de la requête et permettent d'améliorer la distribution des données entre les nœuds de calcul qui traitent la requête. Étant donné que ces phases ne sont pas liées au texte de votre requête, elles sont masquées pour simplifier le plan de requête affiché.
Pour toute requête présentant des problèmes de régression des performances, les insights sur les performances sont également affichés dans l'onglet Job information (Informations sur le job) de la requête :
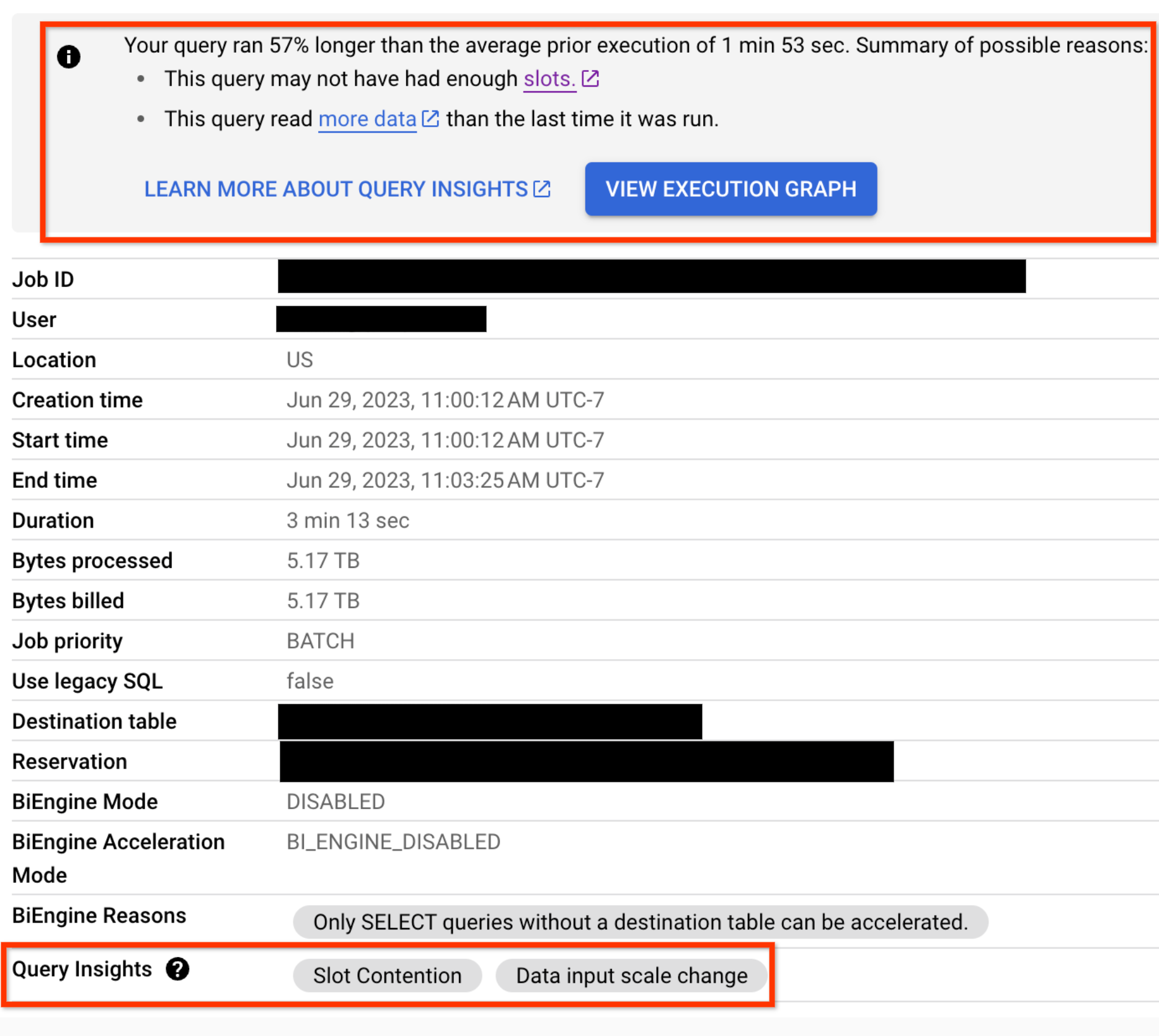
SQL
Dans la console Google Cloud , accédez à la page BigQuery.
Dans l'éditeur de requête, saisissez l'instruction suivante :
SELECT `bigquery-public-data`.persistent_udfs.job_url( project_id || ':us.' || job_id) AS job_url, query_info.performance_insights FROM `region-REGION_NAME`.INFORMATION_SCHEMA.JOBS_BY_PROJECT WHERE DATE(creation_time) >= CURRENT_DATE - 30 -- scan 30 days of query history AND job_type = 'QUERY' AND state = 'DONE' AND error_result IS NULL AND statement_type != 'SCRIPT' AND EXISTS ( -- Only include queries which had performance insights SELECT 1 FROM UNNEST( query_info.performance_insights.stage_performance_standalone_insights ) WHERE slot_contention OR insufficient_shuffle_quota UNION ALL SELECT 1 FROM UNNEST( query_info.performance_insights.stage_performance_change_insights ) WHERE input_data_change.records_read_diff_percentage IS NOT NULL );
Cliquez sur Exécuter.
Pour en savoir plus sur l'exécution des requêtes, consultez Exécuter une requête interactive.
API
Vous pouvez obtenir des informations sur les performances des requêtes dans un format non graphique en appelant la méthode d'API jobs.list et en inspectant les informations JobStatistics2 renvoyées.
Interpréter les informations sur les performances des requêtes
Utilisez cette section pour en savoir plus sur la signification des insights de performances et sur la façon de les gérer.
Les insights sur les performances sont destinés à deux audiences :
Analystes : vous exécutez des requêtes dans un projet. Vous souhaitez savoir pourquoi une requête que vous avez déjà exécutée est plus lente que prévu et obtenir des conseils pour améliorer ses performances. Vous disposez des autorisations décrites dans Autorisations requises.
Administrateurs de lacs de données ou d'entrepôts de données : vous gérez les ressources et les réservations BigQuery de votre organisation. Vous disposez des autorisations associées au rôle Administrateur BigQuery.
Chacune des sections suivantes fournit des conseils sur la manière de traiter les insights sur les performances que vous recevez, en fonction de votre rôle.
Conflit d'emplacements
Lorsque vous exécutez une requête, BigQuery tente de diviser le travail nécessaire en tâches. Une tâche est une seule tranche de données d'entrée et de sortie d'une étape. Un seul emplacement récupère une tâche et exécute cette tranche de données pour l'étape. Idéalement, les emplacements BigQuery exécutent ces tâches en parallèle pour atteindre des performances élevées. Un conflit d'emplacements se produit lorsque votre requête dispose de nombreuses tâches prêtes à être exécutées, mais que BigQuery ne peut pas obtenir suffisamment d'emplacements disponibles pour les exécuter.
Que faire si vous êtes analyste ?
Réduisez les données que vous traitez dans votre requête en suivant les instructions de la section Réduire la quantité de données traitée dans les requêtes.
Que faire si vous êtes administrateur ?
Augmentez la disponibilité des emplacements ou réduisez leur utilisation en effectuant les actions suivantes :
- Si vous utilisez la tarification à la demande de BigQuery, vos requêtes utilisent un pool partagé d'emplacements. Envisagez de passer à la tarification basée sur la capacité pour l'analyse en achetant des réservations. Les réservations vous permettent de réserver des emplacements dédiés aux requêtes de votre organisation.
Si vous utilisez des réservations BigQuery, assurez-vous que le nombre d'emplacements est suffisant dans la réservation attribuée au projet qui exécute la requête. La réservation peut ne pas avoir suffisamment d'emplacements dans les scénarios suivants :
- D'autres jobs consomment des emplacements de réservation. Vous pouvez utiliser les graphiques de ressources d'administration pour voir comment votre organisation utilise la réservation.
- La réservation ne dispose pas de suffisamment d'emplacements attribués pour exécuter les requêtes assez rapidement. L'estimateur d'emplacements vous permet d'obtenir une estimation de la taille de vos réservations afin de traiter efficacement les tâches de vos requêtes.
Pour résoudre ce problème, vous pouvez essayer l'une des solutions suivantes :
- Ajoutez d'autres emplacements (emplacements de référence ou emplacements de réservation maximum) à cette réservation.
- Créez une réservation supplémentaire et attribuez-la au projet qui exécute la requête.
- Répartir les requêtes utilisant les ressources de manière intensive, au fil du temps dans une réservation ou sur des réservations différentes.
Assurez-vous que les tables que vous interrogez sont mises en cluster. Le clustering permet de s'assurer que BigQuery peut lire rapidement les colonnes contenant des données corrélées.
Assurez-vous que les tables que vous interrogez sont partitionnées. Pour les tables non partitionnées, BigQuery lit l'intégralité de la table. Le partitionnement de vos tables vous permet de n'interroger que le sous-ensemble de tables qui vous intéresse.
Quota de brassage insuffisant
Avant d'exécuter votre requête, BigQuery divise sa logique en étapes. Les emplacements BigQuery exécutent les tâches pour chaque étape. Lorsqu'un emplacement termine l'exécution des tâches d'une étape, il stocke les résultats intermédiaires dans shuffle. Les étapes suivantes de votre requête lisent les données du shuffle pour poursuivre l'exécution de votre requête. Le quota de brassage est insuffisant lorsque vous avez plus de données à écrire que de capacité de brassage.
Que faire si vous êtes analyste ?
Comme pour le conflit d'emplacements, la réduction de la quantité de données traitées par vos requêtes peut réduire l'utilisation du brassage. Pour ce faire, suivez les instructions de la section Réduire la quantité de données traitée dans les requêtes.
Certaines opérations en SQL utilisent généralement une plus le brassage, en particulier les opérations JOIN et les clauses GROUP BY.
Dans la mesure du possible, la réduction de la quantité de données dans ces opérations peut réduire l'utilisation du brassage.
Que faire si vous êtes administrateur ?
Réduisez les conflits de quota de brassage en procédant comme suit :
- Comme pour les conflits d'emplacements, si vous utilisez la tarification à la demande de BigQuery, vos requêtes utilisent un pool partagé d'emplacements. Envisagez de passer à la tarification basée sur la capacité pour l'analyse en achetant des réservations. Les réservations vous offrent des emplacements dédiés et une capacité de brassage pour les requêtes de vos projets.
Si vous utilisez des réservations BigQuery, les emplacements sont fournis avec une capacité de shuffle dédiée. Si votre réservation exécute des requêtes qui utilisent le brassage de manière intensive, cela peut entraîner une capacité de brassage insuffisante pour les autres requêtes exécutées en parallèle. Vous pouvez identifier quelles tâches utilisent la capacité de brassage de manière intensive en interrogeant la colonne
period_shuffle_ram_usage_ratiode la vueINFORMATION_SCHEMA.JOBS_TIMELINE.Pour résoudre ce problème, vous pouvez essayer l'une ou plusieurs des solutions suivantes :
- Ajoutez d'autres emplacements à cette réservation.
- Créez une réservation supplémentaire et attribuez-la au projet qui exécute la requête.
- Répartir les requêtes utilisant le brassage de manière intensive, au fil du temps dans une réservation ou sur des réservations différentes.
Modification de l'échelle de saisie des données
Cet insight sur les performances indique que votre requête lit au moins 50 % de données en plus pour une table d'entrée donnée qu'à la dernière exécution de la requête. Vous pouvez utiliser l'historique des modifications de table pour voir si la taille de l'une des tables utilisées dans la requête a récemment augmenté.
Que faire si vous êtes analyste ?
Réduisez les données que vous traitez dans votre requête en suivant les instructions de la section Réduire la quantité de données traitée dans les requêtes.
Jointure à cardinalité élevée
Lorsqu'une requête contient une jointure avec des clés non uniques des deux côtés de la jointure, la taille de la table de sortie peut être considérablement plus grande que celle de l'une ou l'autre des tables d'entrée. Cet insight indique que le ratio entre les lignes de sortie et les lignes d'entrée est élevé et fournit des informations sur ces nombres de lignes.
Que faire si vous êtes analyste ?
Vérifiez les conditions de jointure pour vérifier que l'augmentation de la taille de la table de sortie est attendue. Évitez d'utiliser des jointures croisées.
Si vous devez utiliser une jointure croisée, essayez d'utiliser une clause GROUP BY pour pré-agréger les résultats ou utilisez une fonction de fenêtrage. Pour en savoir plus, consultez la section Réduire les données avant d'utiliser une jointure (JOIN).
Décalage de partition
Pour envoyer des commentaires ou demander de l'aide concernant cette fonctionnalité, envoyez un e-mail à l'adresse bq-query-inspector-feedback@google.com.
Une distribution asymétrique des données peut ralentir l'exécution des requêtes. Lorsqu'une requête est exécutée, BigQuery divise les données en petites partitions pour un traitement parallèle. Le biais se produit lorsque les données sont réparties de manière inégale entre ces partitions, souvent en raison de valeurs fréquentes dans les clés de jointure ou de regroupement, ce qui rend certaines partitions beaucoup plus volumineuses que d'autres. Étant donné qu'un seul emplacement traite une partition entière et ne peut pas partager le travail, une partition surdimensionnée peut ralentir le traitement, provoquer des erreurs de "ressources dépassées" et, dans les cas extrêmes, planter l'emplacement.
Lorsque vous exécutez une opération JOIN, BigQuery partitionne les données situées à gauche et à droite de la jointure en fonction des clés de jointure. Si une partition est trop volumineuse, BigQuery tente de rééquilibrer les données. Si le décalage est trop important pour être entièrement rééquilibré, un insight de décalage de partition est ajouté à l'étape JOIN dans le graphique d'exécution.
Identifier l'inclinaison de la partition
Utilisez l'onglet Graphique d'exécution dans BigQuery Studio pour identifier l'étape de la requête qui présente un déséquilibre de partition. L'insight est signalé sur la scène. À partir des détails de l'étape, vous pouvez déterminer la partie pertinente du texte de la requête et les tables en cours de traitement. Pour en savoir plus, consultez Comprendre les étapes avec le texte de la requête.
Exemple
La requête suivante joint les informations sur le dépôt à celles sur les fichiers. Un déséquilibre peut se produire si certains dépôts contiennent beaucoup plus de fichiers que d'autres.
SELECT r.repo_name, COUNT(f.path) AS file_count
FROM `bigquery-public-data.github_repos.sample_repos` AS r
JOIN `bigquery-public-data.github_repos.sample_files` AS f
ON r.repo_name = f.repo_name
WHERE r.watch_count > 10
GROUP BY r.repo_name
La clé de jointure est repo_name. Dans la table sample_repos, repo_name doit être unique. Toutefois, dans le tableau sample_files, repo_name peut apparaître plusieurs fois. Si quelques valeurs repo_name apparaissent de manière disproportionnée dans sample_files, cela crée un décalage des données.
Pour vérifier si un déséquilibre des données existe, analysez la distribution de la clé de jointure dans la table la plus grande (sample_files dans ce cas). Exécutez la requête suivante pour évaluer la distribution de repo_name :
SELECT repo_name, COUNT(*) AS occurrences
FROM `bigquery-public-data.github_repos.sample_files`
GROUP BY repo_name
ORDER BY occurrences DESC
Pour les très grandes tables, utilisez la fonction APPROX_TOP_COUNT pour estimer efficacement les valeurs les plus fréquentes.
SELECT APPROX_TOP_COUNT(repo_name, 100)
FROM `bigquery-public-data.github_repos.sample_files`
Si les nombres pour les valeurs les plus élevées sont beaucoup plus importants que les autres, cela indique une asymétrie des données.
Atténuer le décalage de partition
Vous pouvez utiliser les stratégies suivantes pour résoudre le problème de décalage des partitions :
- Filtrez vos données de manière anticipée. Réduisez la quantité de données traitées en appliquant des filtres le plus tôt possible dans votre requête. Cela peut réduire le nombre de lignes associées aux clés asymétriques avant qu'elles n'atteignent des opérations telles que
JOINouGROUP BY. Divisez la requête pour isoler les clés biaisées. Si le déséquilibre est dû à quelques valeurs clés spécifiques, comme le champ
repo_namedans l'exemple précédent, envisagez de fractionner la requête. Traitez les données des clés asymétriques séparément du reste des données, puis combinez les résultats à l'aide deUNION ALL.Exemple : isoler une clé fréquemment utilisée.
-- Query for the skewed key SELECT r.repo_name, COUNT(f.path) AS file_count FROM `bigquery-public-data.github_repos.sample_repos` AS r JOIN `bigquery-public-data.github_repos.sample_files` AS f ON r.repo_name = f.repo_name WHERE r.watch_count > 10 AND r.repo_name = 'popular_repo' GROUP BY r.repo_name UNION ALL -- Query for all other keys SELECT r.repo_name, COUNT(f.path) AS file_count FROM `bigquery-public-data.github_repos.sample_repos` AS r JOIN `bigquery-public-data.github_repos.sample_files` AS f ON r.repo_name = f.repo_name WHERE r.watch_count > 10 AND r.repo_name != 'popular_repo' GROUP BY r.repo_nameGérer les valeurs
NULLet par défaut : une cause fréquente d'asymétrie est un grand nombre de lignes avec des valeursNULLou des chaînes vides dans les colonnes clés. Si vous n'avez pas besoin de ces lignes pour l'analyse, filtrez-les à l'aide d'une clauseWHEREavantJOINouGROUP BY.Réorganiser les opérations : dans les requêtes comportant plusieurs jointures, l'ordre peut avoir de l'importance. Si possible, effectuez les jointures qui réduisent considérablement le nombre de lignes plus tôt dans la requête.
Utilisez des fonctions approximatives : pour les agrégations sur des données asymétriques, déterminez si un résultat approximatif est acceptable. Les fonctions telles que
APPROX_COUNT_DISTINCTsont plus tolérantes à l'égard de l'asymétrie des données que les fonctions exactes telles queCOUNT(DISTINCT).
Interpréter les informations sur la phase d'une requête
En plus d'utiliser les insights sur les performances des requêtes, vous pouvez également appliquer les instructions suivantes lorsque vous consultez les détails de l'étape de requête pour déterminer s'il y a un problème avec une requête :
- Si la valeur Wait ms (temps d'attente en ms) pour une ou plusieurs phases est élevée par rapport aux exécutions précédentes de la requête :
- Vérifiez si vous disposez de suffisamment d'emplacements pour répondre à votre charge de travail. Si ce n'est pas le cas, équilibrez la charge lorsque vous exécutez des requêtes nécessitant beaucoup de ressources afin qu'elles ne se concurrencent pas.
- Si la valeur Wait ms (temps d'attente en ms) est supérieure à celle attendue pour une seule phase, examinez la phase antérieure pour vérifier la présence éventuelle d'un goulot d'étranglement. Des éléments tels que des modifications importantes sur les données ou le schéma des tables impliquées dans la requête peuvent affecter les performances de la requête.
- Si la valeur Shuffle output bytes (Octets de sortie de brassage) d'une étape est élevée par rapport aux exécutions précédentes de la requête ou par rapport à une phase précédente, évaluez les étapes traitées dans cette phase pour savoir si l'une d'entre elles crée de grandes quantités de données de manière inattendue. Ce problème se produit généralement lorsqu'une étape traite une jointure
INNER JOINqui présente des clés en double de chaque côté de la jointure. Cela peut renvoyer une quantité de données inattendue. - Le graphique d'exécution permet d'afficher les principales phases par durée et par traitement. Déterminez la quantité de données qu'elles produisent et si elles sont comparables à la taille des tables référencées dans la requête. Si ce n'est pas le cas, examinez les étapes dans ces phases pour savoir si l'une d'entre elles peut produire une quantité inattendue de données intermédiaires.
Étapes suivantes
- Consultez les conseils d'optimisation des requêtes pour savoir comment améliorer les performances des requêtes.