程式輔助分析工具
本文說明多種寫入及執行程式碼的方式,可用來分析 BigQuery 中所代管的資料。
儘管 SQL 是一種功能強大的查詢語言,但是 Python、Java 或 R 等程式設計語言提供了語法和大量的內建統計功能,資料分析人員可能會認為這對於某些類型的資料分析而言更快速且更易於操作。
同樣地,儘管試算表已廣為使用,但其他程式設計環境 (如筆記本) 有時可提供更靈活的環境來進行複雜的資料分析和探索。
Colab Enterprise 筆記本
您可以在 BigQuery 中使用 Colab Enterprise 筆記本,透過 SQL、Python 和其他常見套件與 API,完成分析和機器學習 (ML) 工作流程。筆記本提供下列選項,可提升協作和管理效率:
- 使用 Identity and Access Management (IAM),與特定使用者和群組共用筆記本。
- 查看筆記本版本記錄。
- 還原或從筆記本的先前版本建立分支。
筆記本是 BigQuery Studio 程式碼資產,由 Dataform 提供支援,但筆記本不會顯示在 Dataform 中。儲存的查詢也是程式碼資產。 所有程式碼資產都會儲存在預設區域。更新預設區域後,之後建立的所有程式碼資產都會使用新的區域。
筆記本功能僅適用於 Google Cloud 控制台。
BigQuery 中的 Notebook 具有下列優點:
- BigQuery DataFrames 已整合至筆記本,無須設定。BigQuery DataFrames 是一種 Python API,可讓您使用 pandas DataFrame 和 scikit-learn API 大規模分析 BigQuery 資料。
- 採用 Gemini 生成式 AI 技術輔助開發程式碼。
- 自動完成 SQL 陳述式,與 BigQuery 編輯器相同。
- 可儲存、共用及管理筆記本版本。
- 您可以在工作流程的任何時間點,使用 matplotlib、 seaborn 和其他熱門程式庫將資料視覺化。
BigQuery DataFrames
BigQuery DataFrames 是一組開放原始碼 Python 程式庫,可讓您使用熟悉的 Python API,充分運用 BigQuery 資料處理功能。BigQuery DataFrames 會透過 SQL 轉換,將處理作業下推至 BigQuery,藉此實作 pandas 和 scikit-learn API。這種設計可讓您使用 BigQuery 探索及處理 TB 級資料,並透過 Python API 訓練機器學習模型。
BigQuery DataFrames 的優點如下:
- 透過透明的 SQL 轉換至 BigQuery 和 BigQuery ML API,實作超過 750 個 pandas 和 scikit-learn API。
- 延後執行查詢,提升效能。
- 使用 Python 使用者定義函式擴充資料轉換作業,以便在雲端處理資料。這些函式會自動部署為 BigQuery 遠端函式。
- 與 Vertex AI 整合,可使用 Gemini 模型生成文字。
其他程式輔助分析解決方案
BigQuery 也提供下列程式輔助分析解決方案。
Jupyter Notebook
Jupyter 是一種開放原始碼的網頁型應用程式,用來發布包含即時程式碼、文字說明和視覺化內容的筆記本。數據資料學家、機器學習專家和學生通常會使用這個平台,執行資料清理與轉換、數值模擬、統計建模、資料視覺化和機器學習等工作。
Jupyter Notebooks 以 IPython 核心 (一種功能強大的互動式殼層) 為基礎,可透過 BigQuery 的 IPython Magics 直接與 BigQuery 互動。或者,您也可以安裝任何可用的 BigQuery 用戶端程式庫,從 Jupyter Notebooks 執行個體存取 BigQuery。 您可以透過 GeoJSON 擴充功能,使用 Jupyter 筆記本將 BigQuery GIS 的資料視覺化。如要進一步瞭解 BigQuery 整合,請參閱在 Jupyter 筆記本中以視覺化方式呈現 BigQuery 資料一文的教學課程。
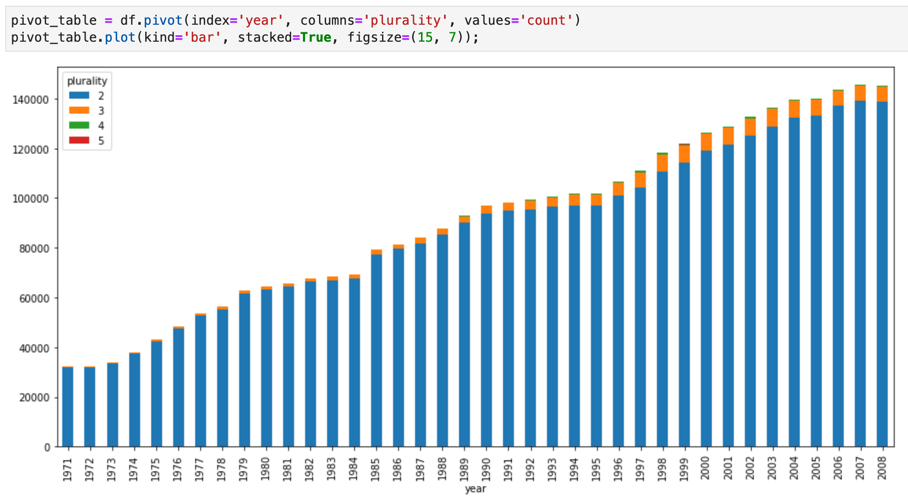
JupyterLab 是網頁式使用者介面,可用於管理文件和活動,例如 Jupyter 筆記本、文字編輯器、終端機和自訂元件。使用 JupyterLab,您可以利用分頁標籤和分割工具,在工作區中同時排列多項文件和活動。
您可以使用下列其中一項產品,在Google Cloud 上部署 Jupyter 筆記本和 JupyterLab 環境:
- Vertex AI Workbench 執行個體:提供整合 JupyterLab 環境的服務,可讓機器學習開發人員和資料科學家使用部分最新的資料科學和機器學習架構。Vertex AI Workbench 已與 BigQuery 等其他 Google Cloud 資料產品整合,使用者可以輕鬆執行多項工作,包括擷取資料、預先處理和探索資料,以及最終的模型訓練和部署作業等。詳情請參閱 Vertex AI Workbench 執行個體簡介。
- Dataproc 是一項運作快速又簡單易用的全代管雲端服務,可讓您以更輕鬆且更具成本效益的方式執行 Apache Spark 和 Apache Hadoop 叢集。您可以使用 Jupyter 選用元件,在 Dataproc 叢集上安裝 Jupyter Notebooks 和 JupyterLab。 元件提供 Python 核心,用來執行 PySpark 程式碼。根據預設,Dataproc 會設定自動將筆記本儲存在 Cloud Storage 中,讓其他叢集可以存取相同的筆記本檔案。將現有筆記本遷移至 Dataproc 時,請檢查系統支援的 Dataproc 版本是否包含筆記本的依附元件。如要安裝自訂軟體,您可以考慮自行建立 Dataproc 映像檔、編寫自己的初始化動作或指定自訂 Python 套件需求。如要開始使用,請參閱在 Dataproc 叢集上安裝及執行 Jupyter Notebook 的教學課程。
Apache Zeppelin
Apache Zeppelin是一種開放原始碼的專案,提供網頁型的筆記本進行數據分析。您可以藉由安裝 Zeppelin 選用元件,在 Dataproc 上部署 Apache Zeppelin 執行個體。根據預設,筆記本會儲存在 Cloud Storage 中,即在叢集建立期間由使用者指定或系統自動建立的 Dataproc 暫存值區。建立叢集時,您可以新增 zeppelin:zeppelin.notebook.gcs.dir 屬性來變更筆記本位置。如要進一步瞭解如何安裝及設定 Apache Zeppelin,請參閱 Zeppelin 元件指南。如需範例,請參閱使用適用於 Apache Zeppelin 的 BigQuery Interpreter 分析 BigQuery 資料集。
Apache Hadoop、Apache Spark 和 Apache Hive
在遷移資料分析管道時,您可能需要遷移部分舊版的 Apache Hadoop、Apache Spark 或 Apache Hive 工作,這些工作需要直接處理資料倉儲中的資料。例如,您可以擷取用於機器學習工作負載的功能。
Dataproc 可讓您以經濟實惠的方式,有效率地部署全代管 Hadoop 和 Spark 叢集。Dataproc 會整合開放原始碼 BigQuery 連接器。這些連接器使用 BigQuery Storage API,直接從 BigQuery 透過 gRPC 串流資料。
將現有的 Hadoop 和 Spark 工作負載遷移至 Dataproc 時,您可以確認系統支援的 Dataproc 版本中是否包含工作負載依附元件。如要安裝自訂軟體,您可以考慮自行建立 Dataproc 映像檔、編寫自己的初始化動作或指定自訂 Python 套件需求。
如要開始使用,請參閱 Dataproc 快速入門導覽課程指南和 BigQuery 連接器程式碼範例。
Apache Beam
Apache Beam 是一個開放原始碼架構,提供豐富的時間區間設定和工作階段分析基元,以及各式來源與接收器連接器的生態系統,包括 BigQuery 適用的連接器。Apache Beam 可讓您在串流 (即時) 與批次 (舊有) 模式下轉換並擴充資料,而且可靠性和明確性完全相同。
Dataflow 是一項全代管服務,可大規模執行 Apache Beam 工作。Dataflow 的無伺服器方法能夠自動處理效能、資源調度、可用性、安全性和法規遵循相關作業,因此可以減輕您的營運工作負擔,讓您能專心設計程式,無須費心管理伺服器叢集。
您可以利用不同的方式提交 Dataflow 工作,例如透過指令列介面、Java SDK 或 Python SDK。
如要將資料查詢和資料管道從其他架構遷移至 Apache Beam 和 Dataflow,請參閱 Apache Beam 的程式設計模型一文,並瀏覽官方的 Dataflow 說明文件。
其他資源
BigQuery 提供大量的用戶端程式庫,支援多種程式設計語言,例如 Java、Go、Python、JavaScript、PHP 和 Ruby。部分資料分析架構 (例如 pandas) 提供可與 BigQuery 直接互動的外掛程式。如需實際範例,請參閱在 Jupyter 筆記本中以視覺化方式呈現 BigQuery 資料教學課程。
最後,如果您偏好在殼層環境中編寫程式,可以使用 bq 指令列工具。