Ferramentas de análise programática
Este documento descreve várias formas de escrever e executar código para analisar dados geridos no BigQuery.
Embora o SQL seja uma linguagem de consulta avançada, as linguagens de programação, como Python, Java ou R, oferecem sintaxes e uma grande variedade de funções estatísticas incorporadas que os analistas de dados podem considerar mais expressivas e fáceis de manipular para determinados tipos de análise de dados.
Da mesma forma, embora as folhas de cálculo sejam amplamente usadas, outros ambientes de programação, como os blocos de notas, podem, por vezes, oferecer um ambiente mais flexível para fazer análises e explorações de dados complexas.
Blocos de notas do Colab Enterprise
Pode usar blocos de notas do Colab Enterprise no BigQuery para concluir fluxos de trabalho de análise e aprendizagem automática (AA) usando SQL, Python e outros pacotes e APIs comuns. Os notebooks oferecem uma colaboração e uma gestão melhoradas com as seguintes opções:
- Partilhe blocos de notas com utilizadores e grupos específicos através da gestão de identidade e de acesso (IAM).
- Reveja o histórico de versões do bloco de notas.
- Reverter ou criar ramificações a partir de versões anteriores do bloco de notas.
Os blocos de notas são recursos de código do BigQuery Studio baseados no Dataform, embora os blocos de notas não sejam visíveis no Dataform. As consultas guardadas também são recursos de código. Todos os recursos de código são armazenados numa região predefinida. A atualização da região predefinida altera a região de todos os recursos de código criados a partir desse momento.
As capacidades do bloco de notas só estão disponíveis na Google Cloud consola.
Os blocos de notas no BigQuery oferecem as seguintes vantagens:
- Os DataFrames do BigQuery estão integrados nos blocos de notas, não sendo necessária configuração. O BigQuery DataFrames é uma API Python que pode usar para analisar dados do BigQuery em grande escala através das APIs pandas DataFrame e scikit-learn.
- Desenvolvimento de código assistido com tecnologia de IA generativa do Gemini.
- Conclusão automática de declarações SQL, tal como no editor do BigQuery.
- Capacidade de guardar, partilhar e gerir versões de blocos de notas.
- A capacidade de usar matplotlib, seaborn e outras bibliotecas populares para visualizar dados em qualquer ponto do seu fluxo de trabalho.
- A capacidade de escrever e executar SQL numa célula que pode referenciar variáveis Python do seu bloco de notas.
- Visualização interativa de DataFrame que suporta agregação e personalização.
Pode começar a usar os notebooks com os modelos da galeria de notebooks. Para mais informações, consulte o artigo Crie um bloco de notas com a galeria de blocos de notas.
DataFrames do BigQuery
O BigQuery DataFrames é um conjunto de bibliotecas Python de código aberto que lhe permitem tirar partido do processamento de dados do BigQuery através de APIs Python familiares. O BigQuery DataFrames implementa as APIs pandas e scikit-learn ao transferir o processamento para o BigQuery através da conversão SQL. Esta arquitetura permite-lhe usar o BigQuery para explorar e processar terabytes de dados, bem como preparar modelos de ML, tudo com APIs Python.
Os DataFrames do BigQuery oferecem as seguintes vantagens:
- Mais de 750 APIs pandas e scikit-learn implementadas através da conversão transparente de SQL para as APIs BigQuery e BigQuery ML.
- Execução diferida de consultas para um desempenho melhorado.
- Extensão das transformações de dados com funções Python definidas pelo utilizador para lhe permitir processar dados na nuvem. Estas funções são implementadas automaticamente como funções remotas do BigQuery.
- Integração com a Vertex AI para lhe permitir usar modelos Gemini para geração de texto.
Outras soluções de análise programática
As seguintes soluções de análise programática também estão disponíveis no BigQuery.
Jupyter Notebooks
O Jupyter é uma aplicação Web de código aberto para publicar blocos de notas que contêm código ativo, descrições textuais e visualizações. Os cientistas de dados, os especialistas em aprendizagem automática e os estudantes usam frequentemente esta plataforma para tarefas como a limpeza e a transformação de dados, a simulação numérica, a modelagem estatística, a visualização de dados e a aprendizagem automática.
Os Jupyter Notebooks são criados com base no kernel IPython, um shell interativo avançado que pode interagir diretamente com o BigQuery através dos IPython Magics para o BigQuery. Em alternativa, também pode aceder ao BigQuery a partir das instâncias dos blocos de notas do Jupyter instalando qualquer uma das bibliotecas de clientes do BigQuery disponíveis. Pode visualizar dados do BigQuery GIS com blocos de notas Jupyter através da extensão GeoJSON. Para mais detalhes sobre a integração do BigQuery, consulte o tutorial Visualizar dados do BigQuery num bloco de notas do Jupyter.
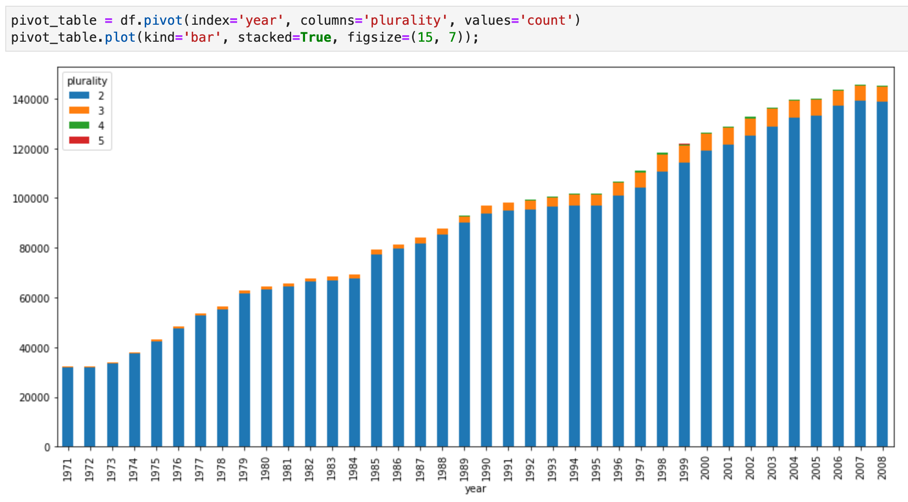
O JupyterLab é uma interface do utilizador baseada na Web para gerir documentos e atividades, como blocos de notas Jupyter, editores de texto, terminais e componentes personalizados. Com o JupyterLab, pode organizar vários documentos e atividades lado a lado na área de trabalho através de separadores e divisores.
Pode implementar blocos de notas Jupyter e ambientes JupyterLab no Google Cloud através de um dos seguintes produtos:
- Instâncias do Vertex AI Workbench, um serviço que oferece um ambiente JupyterLab integrado no qual os programadores de aprendizagem automática e os cientistas de dados podem usar algumas das mais recentes frameworks de ciência de dados e aprendizagem automática. O Vertex AI Workbench está integrado com outros Google Cloud produtos de dados, como o BigQuery, o que facilita a transição da ingestão de dados para a pré-processamento e exploração e, eventualmente, para a preparação e implementação de modelos. Para saber mais, consulte o artigo Introdução às instâncias do Vertex AI Workbench.
- O Dataproc é um serviço rápido, fácil de usar e totalmente gerido para executar clusters do Apache Spark e do Apache Hadoop de forma simples e económica. Pode instalar blocos de notas do Jupyter e o JupyterLab num cluster do Dataproc através do componente opcional do Jupyter. O componente fornece um kernel Python para executar código PySpark. Por predefinição, o Dataproc configura automaticamente os blocos de notas para serem guardados no Cloud Storage, o que torna os mesmos ficheiros de blocos de notas acessíveis a outros clusters. Quando migrar os seus blocos de notas existentes para o Dataproc, verifique se as dependências dos blocos de notas são abrangidas pelas versões do Dataproc suportadas. Se precisar de instalar software personalizado, considere criar a sua própria imagem do Dataproc, escrever as suas próprias ações de inicialização, ou especificar requisitos de pacotes Python personalizados. Para começar, consulte o tutorial sobre como instalar e executar um bloco de notas do Jupyter num cluster do Dataproc.
Apache Zeppelin
O Apache Zeppelin
é um projeto de código aberto que oferece blocos de notas baseados na Web para a análise de dados.
Pode implementar uma instância do Apache Zeppelin no
Dataproc
instalando o
componente opcional Zeppelin.
Por predefinição, os blocos de notas são guardados no Cloud Storage no contentor de preparação do Dataproc, que é especificado pelo utilizador ou criado automaticamente quando o cluster é criado. Pode alterar a localização do bloco de notas adicionando a propriedade zeppelin:zeppelin.notebook.gcs.dir quando cria o cluster. Para mais informações sobre a instalação e a configuração do Apache Zeppelin,
consulte o
guia de componentes do Zeppelin.
Para ver um exemplo, consulte o artigo
Analisar conjuntos de dados do BigQuery com o intérprete do BigQuery para o Apache Zeppelin.
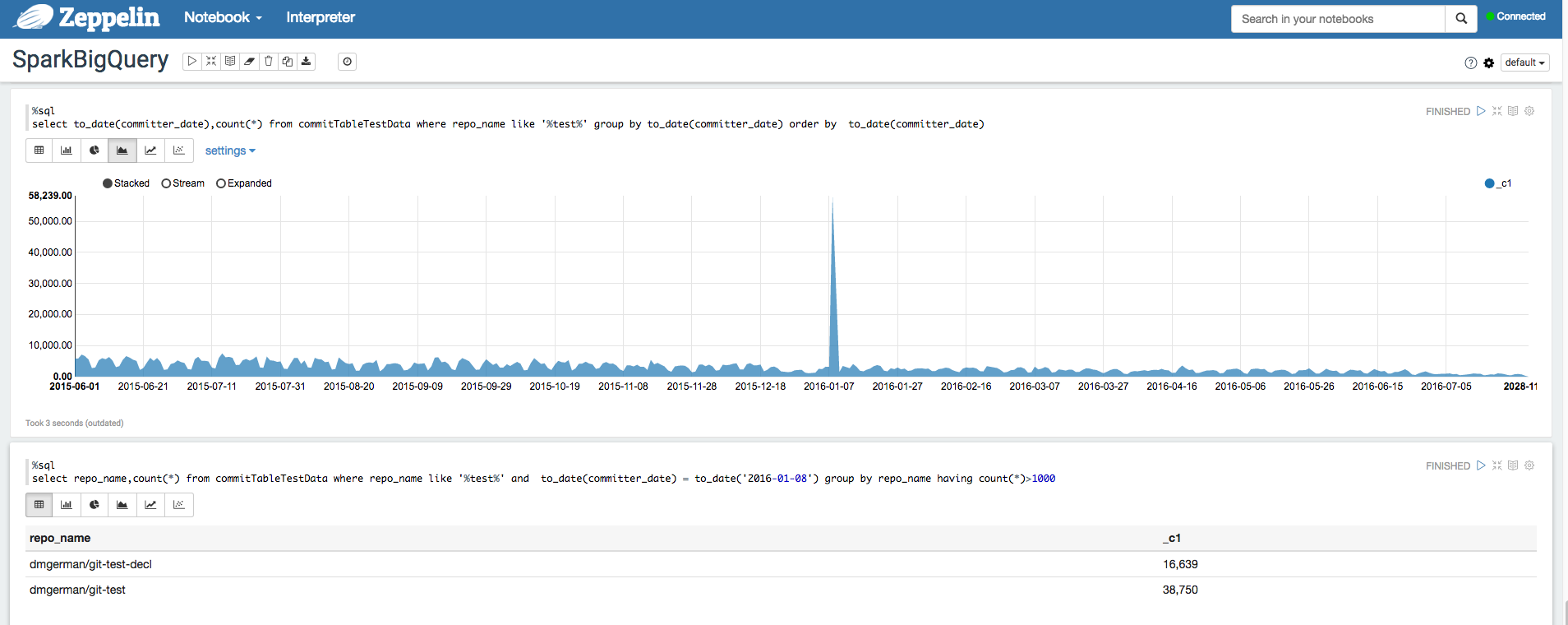
Apache Hadoop, Apache Spark e Apache Hive
Para parte da migração do pipeline de estatísticas de dados, pode querer migrar alguns trabalhos Apache Hadoop, Apache Spark> ou Apache Hive antigos que precisam de processar diretamente dados do seu data warehouse. Por exemplo, pode extrair funcionalidades para as suas cargas de trabalho de aprendizagem automática.
O Dataproc permite-lhe implementar clusters Hadoop e Spark totalmente geridos de forma eficiente e económica. O Dataproc integra-se com conetores do BigQuery de código aberto. Estes conetores usam a API BigQuery Storage, que faz stream de dados em paralelo diretamente do BigQuery através do gRPC.
Quando migra as cargas de trabalho existentes do Hadoop e do Spark para o Dataproc, pode verificar se as dependências das cargas de trabalho estão cobertas pelas versões do Dataproc suportadas. Se precisar de instalar software personalizado, pode considerar criar a sua própria imagem do Dataproc, escrever as suas próprias ações de inicialização, ou especificar requisitos de pacotes Python personalizados.
Para começar, consulte os guias de início rápido do Dataproc e os exemplos de código do conetor do BigQuery.
Apache Beam
O Apache Beam é uma framework de código aberto que oferece um conjunto avançado de primitivas de análise de janelas e sessões, bem como um ecossistema de conetores de origens e destinos, incluindo um conetor para o BigQuery. O Apache Beam permite-lhe transformar e enriquecer dados nos modos de stream (tempo real) e de lote (histórico) com igual fiabilidade e expressividade.
O Dataflow é um serviço totalmente gerido para executar tarefas do Apache Beam em grande escala. A abordagem sem servidor do Dataflow remove a sobrecarga operacional com o desempenho, a escalabilidade, a disponibilidade, a segurança e a conformidade processados automaticamente para que se possa focar na programação em vez de gerir clusters de servidores.
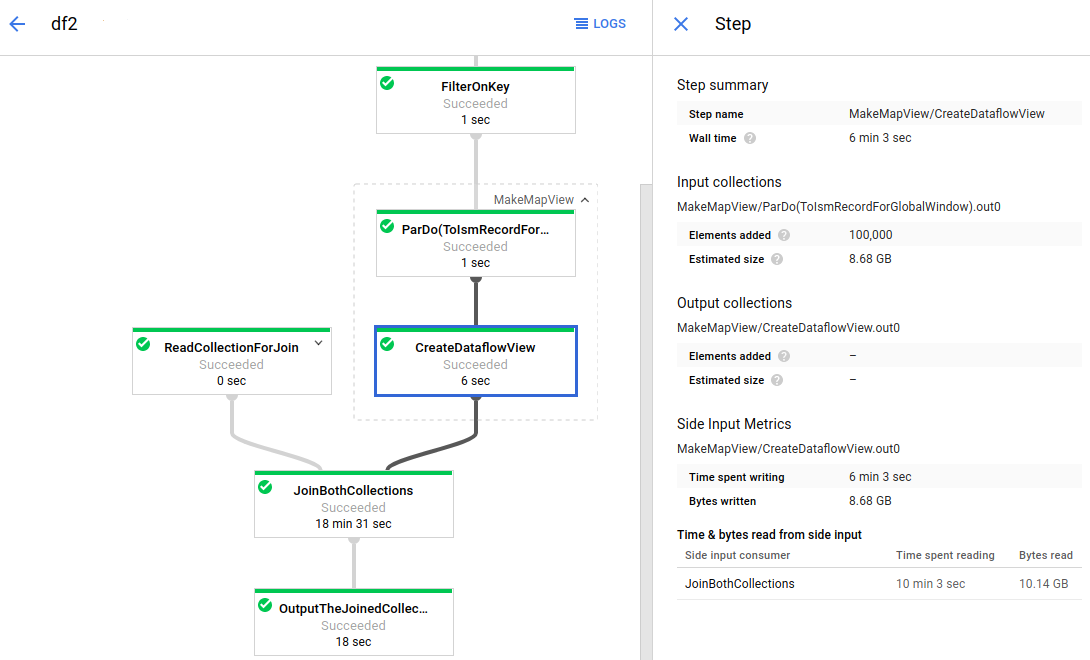
Pode enviar tarefas do Dataflow de diferentes formas, através da interface de linha de comandos, do SDK Java ou do SDK Python.
Se quiser migrar as suas consultas de dados e pipelines de outras frameworks para o Apache Beam e o Dataflow, leia acerca do modelo de programação do Apache Beam e explore a documentação oficial do Dataflow.
Outros recursos
O BigQuery oferece uma grande variedade de bibliotecas cliente em várias linguagens de programação, como Java, Go, Python, JavaScript, PHP e Ruby. Algumas estruturas de análise de dados, como o pandas, fornecem plug-ins que interagem diretamente com o BigQuery. Para ver alguns exemplos práticos, consulte o tutorial Visualize dados do BigQuery num bloco de notas do Jupyter.
Por último, se preferir escrever programas num ambiente de shell, pode usar a ferramenta de linhas de comando bq.